dsindex / Etagger
reference tensorflow code for named entity tagging
Stars: ✭ 100
Projects that are alternatives of or similar to Etagger
Ncrfpp
NCRF++, a Neural Sequence Labeling Toolkit. Easy use to any sequence labeling tasks (e.g. NER, POS, Segmentation). It includes character LSTM/CNN, word LSTM/CNN and softmax/CRF components.
Stars: ✭ 1,767 (+1667%)
Mutual labels: cnn, ner, crf
Min nlp practice
Chinese & English Cws Pos Ner Entity Recognition implement using CNN bi-directional lstm and crf model with char embedding.基于字向量的CNN池化双向BiLSTM与CRF模型的网络,可能一体化的完成中文和英文分词,词性标注,实体识别。主要包括原始文本数据,数据转换,训练脚本,预训练模型,可用于序列标注研究.注意:唯一需要实现的逻辑是将用户数据转化为序列模型。分词准确率约为93%,词性标注准确率约为90%,实体标注(在本样本上)约为85%。
Stars: ✭ 107 (+7%)
Mutual labels: cnn, ner, crf
Rust Bert
Rust native ready-to-use NLP pipelines and transformer-based models (BERT, DistilBERT, GPT2,...)
Stars: ✭ 510 (+410%)
Mutual labels: ner, transformer
Bert Ner Pytorch
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
Stars: ✭ 654 (+554%)
Mutual labels: ner, crf
Nlp Experiments In Pytorch
PyTorch repository for text categorization and NER experiments in Turkish and English.
Stars: ✭ 35 (-65%)
Mutual labels: ner, transformer
Bert Bilstm Crf Ner
Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning And private Server services
Stars: ✭ 3,838 (+3738%)
Mutual labels: ner, crf
Bert Multitask Learning
BERT for Multitask Learning
Stars: ✭ 380 (+280%)
Mutual labels: ner, transformer
Meta Emb
Multilingual Meta-Embeddings for Named Entity Recognition (RepL4NLP & EMNLP 2019)
Stars: ✭ 28 (-72%)
Mutual labels: ner, transformer
Hscrf Pytorch
ACL 2018: Hybrid semi-Markov CRF for Neural Sequence Labeling (http://aclweb.org/anthology/P18-2038)
Stars: ✭ 284 (+184%)
Mutual labels: ner, crf
Torchcrf
An Inplementation of CRF (Conditional Random Fields) in PyTorch 1.0
Stars: ✭ 58 (-42%)
Mutual labels: ner, crf
Ner Lstm Crf
An easy-to-use named entity recognition (NER) toolkit, implemented the Bi-LSTM+CRF model in tensorflow.
Stars: ✭ 337 (+237%)
Mutual labels: ner, crf
Macropodus
自然语言处理工具Macropodus,基于Albert+BiLSTM+CRF深度学习网络架构,中文分词,词性标注,命名实体识别,新词发现,关键词,文本摘要,文本相似度,科学计算器,中文数字阿拉伯数字(罗马数字)转换,中文繁简转换,拼音转换。tookit(tool) of NLP,CWS(chinese word segnment),POS(Part-Of-Speech Tagging),NER(name entity recognition),Find(new words discovery),Keyword(keyword extraction),Summarize(text summarization),Sim(text similarity),Calculate(scientific calculator),Chi2num(chinese number to arabic number)
Stars: ✭ 309 (+209%)
Mutual labels: ner, crf
Tsai
Time series Timeseries Deep Learning Pytorch fastai - State-of-the-art Deep Learning with Time Series and Sequences in Pytorch / fastai
Stars: ✭ 407 (+307%)
Mutual labels: cnn, transformer
Bert seq2seq
pytorch实现bert做seq2seq任务,使用unilm方案,现在也可以做自动摘要,文本分类,情感分析,NER,词性标注等任务,支持GPT2进行文章续写。
Stars: ✭ 298 (+198%)
Mutual labels: ner, crf
Lm Lstm Crf
Empower Sequence Labeling with Task-Aware Language Model
Stars: ✭ 778 (+678%)
Mutual labels: ner, crf
Nlp Journey
Documents, papers and codes related to Natural Language Processing, including Topic Model, Word Embedding, Named Entity Recognition, Text Classificatin, Text Generation, Text Similarity, Machine Translation),etc. All codes are implemented intensorflow 2.0.
Stars: ✭ 1,290 (+1190%)
Mutual labels: ner, crf
keras-bert-ner
Keras solution of Chinese NER task using BiLSTM-CRF/BiGRU-CRF/IDCNN-CRF model with Pretrained Language Model: supporting BERT/RoBERTa/ALBERT
Stars: ✭ 7 (-93%)
Mutual labels: crf, ner
Nlp Interview Notes
本项目是作者们根据个人面试和经验总结出的自然语言处理(NLP)面试准备的学习笔记与资料,该资料目前包含 自然语言处理各领域的 面试题积累。
Stars: ✭ 207 (+107%)
Mutual labels: ner, transformer
ETagger: Entity Tagger
- pytorch implementations : ntagger
Description
personally, i'm interested in NER tasks. so, i decided to implement a sequence tagging model which consists of
- encoding
- basic embedding
- [x] 1) word embedding(glove), character convolutional embedding
- [x] 2) ELMo embedding, character convolutional embedding
- [x] 3) BERT embedding, character convolutional embedding
- BERT as feature-based
- etc embedding
- [x] pos embedding
- [x] chunk embedding
- highway network
- [x] applied on the concatenated input(ex, Glove + CNN(char) + BERT + POS)
- basic embedding
- contextual encoding
- [x] 1) multi-layer BiLSTM(normal LSTM, LSTMBlockFusedCell), BiQRNN
- [x] 2) Transformer(encoder)
- decoding
- [x] CRF decoder
there are so many repositories available for reference. i borrowed those codes as many as possible to use here.
- ner-lstm
- cnn-text-classification-tf/text_cnn.py
- transformer/modules.py
- sequence_tagging/ner_model.py
- tf_ner/masked_conv.py
- torchnlp/layers.py
- bilm-tf
- tensorflow-cmake
- medium-tffreeze-1.py
- medium-tffreeze-2.py
- bert_lstm_ner.py
- model.py
my main questions are :
- can this module perform at the level of state of the art?
- [x] the f1 score is near SOTA based on Glove(100)+ELMo+CNN(char)+BiLSTM+CRF
- 92.83% (best,
experiments 10, test 16), 92.45%(average, 10 runs, `experiments 10, test 15)
- 92.83% (best,
- [x] the f1 score is near SOTA based on Glove(100)+ELMo+CNN(char)+BiLSTM+CRF
- how to make it faster when it comes to using the BiLSTM?
- [x] the solution is LSTMBlockFusedCell().
- 3.13 times faster than LSTMCell() during training time.
- 1.26 times faster than LSTMCell() during inference time.
- [x] the solution is LSTMBlockFusedCell().
- can the Transformer have competing results against the BiLSTM? and how much faster?
- [x] contextual encoding by the Transformer encoder yields competing results.
- in case the sequence to sequence model like translation, the multi-head attention mechanism might be very powerful for alignments.
- however, for sequence tagging, the source of power is from point-wise feed forward net with wide range of kernel size. it is not from the multi-head attention only.
- if you are using kernel size 1, then the the performance will be very worse than you expect.
- it seems that point-wise feed forward net collects contextual information in the layer by layer manner.
- this is very similar with hierarchical convolutional neural network.
- i'd like to say
Attention is Not All you need
- [x] you can see the below evaluation results.
- multi-layer BiLSTM using LSTMBlockFusedCell() is slightly faster than the Transformer with 4 layers on GPU.
- moreover, the BiLSTM is 2 times faster on CPU environment(multi-thread) than on GPU.
- LSTMBlockFusedCell() is well optimized for multi-core CPU via multi-threading.
- i guess there might be an overhead when copying b/w GPU memory and main memory.
- the BiLSTM is 3 ~ 4 times faster than the Transformer version on 1 CPU(single-thread)
- during inference time, 1 layer BiLSTM on 1 CPU takes just 4.2 msec per sentence on average.
- [x] contextual encoding by the Transformer encoder yields competing results.
- how to use a trained model from C++? is it much faster?
- [x] freeze model, convert to memory mapped format and load it via tensorflow C++ API.
- 1 layer BiLSTM on multi CPU takes 2.04 msec per sentence on average.
- 1 layer BiLSTM on single CPU takes 2.68 msec per sentence on average.
- [x] freeze model, convert to memory mapped format and load it via tensorflow C++ API.
Pre-requisites
python >= 3.6
$ python -m venv python3.6
$ source /home/python3.6/bin/activate
or
* after installing conda
$ conda create -n python3.6 python=3.6
$ conda activate python3.6
tensorflow >= 1.10
* tensorflow < 2.0
$ python -m pip install tensorflow-gpu
* version matches
tensorflow 1.10, CUDA 9.0, cuDNN 7.12
(cuda-9.0-pkg/cuda-9.0/lib64, cudnn-9.0/lib64)
tensorflow 1.11, CUDA 9.0, cuDNN 7.31
(cuda-9.0-pkg/cuda-9.0/lib64, cudnn-9.0-v73/lib64)
tensorflow 1.11, CUDA 9.0, cuDNN 7.31, TensorRT 4.0
(cuda-9.0-pkg/cuda-9.0/lib64, cudnn-9.0-v73/lib64, TensorRT-4.0.1.6/lib)
requirements
$ python -m pip install -r requirements
tf_metrics
- install tf_metrics
$ git clone https://github.com/guillaumegenthial/tf_metrics.git
$ cd tf_metrics
$ python setup.py install
glove embedding
- download Glove6B
- download Glove840B
- unzip to 'embeddings' dir
$ cd etagger
$ mkdir embeddings
$ ls embeddings
glove.840B.300d.zip glove.6B.zip
$ unzip glove.840B.300d.zip
$ unzip glove.6B.zip
bilm
- install bilm-tf
$ cd bilm-tf
$ python setup.py install
- download ELMo weights and options
$ cd etagger
$ ls embeddings
embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_options.json embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_weights.hdf5
- test
* run `embvec.py` and test
$ python test_bilm.py
bert
- clone bert in the path of
etagger/bert
$ cd etagger
$ git clone https://github.com/google-research/bert.git
- download
cased_L-12_H-768_A-12,cased_L-24_H-1024_A-16,wwm_cased_L-24_H-1024_A-16
$ cd etagger
$ ls embeddings
cased_L-12_H-768_A-12 cased_L-24_H-1024_A-16 wwm_cased_L-24_H-1024_A-16
spacy [optional]
- if you want to analyze input string and see how it detects entities, then you need to install spacy lib.
$ python -m pip install spacy
$ python -m spacy download en
tensorflow_qrnn [optional]
- if you want to use QRNN, install tensorflow_qrnn.
* before install qrnn, remove `TENSORFLOW_BUILD_DIR` path from `LD_LIBRARY_PATH`
$ python -m pip install qrnn
* test
cd tensorflow_qrnn/test
$ python test_fo_pool.py
How to run
convert word embedding to pickle
* merge train.txt, dev.txt to train-dev.txt
$ cat data/train.txt data/dev.txt > data/train-dev.txt
* for Glove
$ python embvec.py --emb_path embeddings/glove.6B.100d.txt --wrd_dim 100 --train_path data/train-dev.txt > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.6B.200d.txt --wrd_dim 200 --train_path data/train-dev.txt > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.6B.300d.txt --wrd_dim 300 --train_path data/train-dev.txt > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.840B.300d.txt --wrd_dim 300 --train_path data/train-dev.txt --lowercase False > embeddings/vocab.txt
* for ELMo
$ python embvec.py --emb_path embeddings/glove.6B.100d.txt --wrd_dim 100 --train_path data/train-dev.txt --elmo_vocab_path embeddings/elmo_vocab.txt --elmo_options_path embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_options.json --elmo_weight_path embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_weights.hdf5 > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.6B.300d.txt --wrd_dim 300 --train_path data/train-dev.txt --elmo_vocab_path embeddings/elmo_vocab.txt --elmo_options_path embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_options.json --elmo_weight_path embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_weights.hdf5 > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.840B.300d.txt --wrd_dim 300 --train_path data/train-dev.txt --lowercase False --elmo_vocab_path embeddings/elmo_vocab.txt --elmo_options_path embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_options.json --elmo_weight_path embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_weights.hdf5 > embeddings/vocab.txt
* for BERT
$ python embvec.py --emb_path embeddings/glove.6B.100d.txt --wrd_dim 100 --train_path data/train-dev.txt --bert_config_path embeddings/cased_L-12_H-768_A-12/bert_config.json --bert_vocab_path embeddings/cased_L-12_H-768_A-12/vocab.txt --bert_do_lower_case False --bert_init_checkpoint embeddings/cased_L-12_H-768_A-12/bert_model.ckpt --bert_max_seq_length 180 --bert_dim 768 > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.6B.100d.txt --wrd_dim 100 --train_path data/train-dev.txt --bert_config_path embeddings/cased_L-24_H-1024_A-16/bert_config.json --bert_vocab_path embeddings/cased_L-24_H-1024_A-16/vocab.txt --bert_do_lower_case False --bert_init_checkpoint embeddings/cased_L-24_H-1024_A-16/bert_model.ckpt --bert_max_seq_length 180 > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.6B.300d.txt --wrd_dim 300 --train_path data/train-dev.txt --bert_config_path embeddings/cased_L-24_H-1024_A-16/bert_config.json --bert_vocab_path embeddings/cased_L-24_H-1024_A-16/vocab.txt --bert_do_lower_case False --bert_init_checkpoint embeddings/cased_L-24_H-1024_A-16/bert_model.ckpt --bert_max_seq_length 180 > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.840B.300d.txt --wrd_dim 300 --train_path data/train-dev.txt --lowercase False --bert_config_path embeddings/cased_L-24_H-1024_A-16/bert_config.json --bert_vocab_path embeddings/cased_L-24_H-1024_A-16/vocab.txt --bert_do_lower_case False --bert_init_checkpoint embeddings/cased_L-24_H-1024_A-16/bert_model.ckpt --bert_max_seq_length 180 > embeddings/vocab.txt
$ python embvec.py --emb_path embeddings/glove.6B.100d.txt --wrd_dim 100 --train_path data/train-dev.txt --bert_config_path embeddings/wwm_cased_L-24_H-1024_A-16/bert_config.json --bert_vocab_path embeddings/wwm_cased_L-24_H-1024_A-16/vocab.txt --bert_do_lower_case False --bert_init_checkpoint embeddings/wwm_cased_L-24_H-1024_A-16/bert_model.ckpt --bert_max_seq_length 180 > embeddings/vocab.txt
* for BERT+ELMo
$ python embvec.py --emb_path embeddings/glove.6B.100d.txt --wrd_dim 100 --train_path data/train-dev.txt --bert_config_path embeddings/cased_L-24_H-1024_A-16/bert_config.json --bert_vocab_path embeddings/cased_L-24_H-1024_A-16/vocab.txt --bert_do_lower_case False --bert_init_checkpoint embeddings/cased_L-24_H-1024_A-16/bert_model.ckpt --bert_max_seq_length 180 --elmo_vocab_path embeddings/elmo_vocab.txt --elmo_options_path embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_options.json --elmo_weight_path embeddings/elmo_2x4096_512_2048cnn_2xhighway_5.5B_weights.hdf5 > embeddings/vocab.txt
train
* for Glove, ELMo
$ python train.py --emb_path embeddings/glove.6B.100d.txt.pkl --wrd_dim 100 --batch_size 20 --epoch 70
$ python train.py --emb_path embeddings/glove.6B.300d.txt.pkl --wrd_dim 300 --batch_size 20 --epoch 70
$ python train.py --emb_path embeddings/glove.840B.300d.txt.pkl --wrd_dim 300 --batch_size 20 --epoch 70
* for BERT, BERT+ELMo
$ python train.py --emb_path embeddings/glove.6B.100d.txt.pkl --wrd_dim 100 --batch_size 16 --epoch 70
$ python train.py --emb_path embeddings/glove.6B.300d.txt.pkl --wrd_dim 300 --batch_size 16 --epoch 70
$ python train.py --emb_path embeddings/glove.840B.300d.txt.pkl --wrd_dim 300 --batch_size 16 --epoch 70
$ rm -rf runs;
$ screen -S tensorboard
$ tensorboard --logdir runs/summaries/ --port 6008
* ctrl+a+c
inference(bucket)
$ python inference.py --mode bucket --emb_path embeddings/glove.6B.100d.txt.pkl --wrd_dim 100 --restore checkpoint/ner_model < data/test.txt > pred.txt
$ python inference.py --mode bucket --emb_path embeddings/glove.6B.300d.txt.pkl --wrd_dim 300 --restore checkpoint/ner_model < data/test.txt > pred.txt
$ python inference.py --mode bucket --emb_path embeddings/glove.840B.300d.txt.pkl --wrd_dim 300 --restore checkpoint/ner_model < data/test.txt > pred.txt
$ perl etc/conlleval < pred.txt
inference(line)
$ python inference.py --mode line --emb_path embeddings/glove.6B.100d.txt.pkl --wrd_dim 100 --restore checkpoint/ner_model
...
Obama left office in January 2017 with a 60% approval rating and currently resides in Washington, D.C.
Obama NNP O O B-PER
left VBD O O O
office NN O O O
in IN O O O
January NNP O B-DATE O
2017 CD O I-DATE O
with IN O O O
a DT O O O
60 CD O B-PERCENT O
% NN O I-PERCENT O
approval NN O O O
rating NN O O O
and CC O O O
currently RB O O O
resides VBZ O O O
in IN O O O
Washington NNP O B-GPE B-LOC
, , O I-GPE O
D.C. NNP O B-GPE B-LOC
The Beatles were an English rock band formed in Liverpool in 1960.
The DT O O O
Beatles NNPS O B-PERSON B-MISC
were VBD O O O
an DT O O O
English JJ O B-LANGUAGE B-MISC
rock NN O O O
band NN O O O
formed VBN O O O
in IN O O O
Liverpool NNP O B-GPE B-LOC
in IN O O O
1960 CD O B-DATE O
. . O I-DATE O
inference(bucket) using frozen model, tensorRT, C++
* create virtual env `python -m venv python3.6_tfsrc` and activate it.
$ python -m venv python3.6_tfsrc
$ source /home/python3.6_tfsrc/bin/activate
* install bazel ( https://github.com/bazelbuild/bazel/releases , https://www.tensorflow.org/install/source#linux )
* ex) bazel 0.15.0 for tensorflow 1.11.0, tensorflow 1.12.0
$ ./bazel-${bazel-version}-installer-linux-x86_64.sh --user
$ source /data1/index.shin/.bazel/bin/bazel-complete.bash
* build tensorflow from source.
$ git clone https://github.com/tensorflow/tensorflow.git tensorflow-src-cpu
$ cd tensorflow-src-cpu
* you should checkout the same version of pip used for training.
$ git checkout r1.11
* modify a source file for memory mapped graph(convert_graphdef_memmapped_format)
./tensorflow/core/platform/posix/posix_file_system.cc: mmap(nullptr, st.st_size, PROT_READ, MAP_PRIVATE, fd, 0); in 'NewReadOnlyMemoryRegionFromFile'
MAP_PRIVATE -> MAP_SHARED
* configure without CUDA
$ ./configure
* build pip package (for FMA, AVX and SSE optimization, see https://medium.com/@sometimescasey/building-tensorflow-from-source-for-sse-avx-fma-instructions-worth-the-effort-fbda4e30eec3 ).
$ python -m pip install --upgrade pip
$ python -m pip install --upgrade setuptools
$ python -m pip install keras_applications --no-deps
$ python -m pip install keras_preprocessing --no-deps
$ bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package
$ bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
* install pip package
$ python -m pip uninstall tensorflow
$ python -m pip install /tmp/tensorflow_pkg/tensorflow-1.11.0-cp36-cp36m-linux_x86_64.whl
* build libraries and binaries we need.
$ bazel build --config=opt //tensorflow:libtensorflow.so
$ bazel build --config=opt //tensorflow:libtensorflow_cc.so
$ bazel build --config=opt //tensorflow:libtensorflow_framework.so
$ bazel build --config=opt //tensorflow/python/tools:optimize_for_inference
$ bazel build --config=opt //tensorflow/tools/quantization:quantize_graph
$ bazel build --config=opt //tensorflow/contrib/util:convert_graphdef_memmapped_format
$ bazel build --config=opt //tensorflow/tools/graph_transforms:transform_graph
* copy libraries to dist directory, export dist and includes directory.
$ export TENSORFLOW_SOURCE_DIR='/home/tensorflow-src-cpu'
$ export TENSORFLOW_BUILD_DIR='/home/tensorflow-dist-cpu'
$ cp -rf ${TENSORFLOW_SOURCE_DIR}/bazel-bin/tensorflow/*.so ${TENSORFLOW_BUILD_DIR}/
* for LSTMBlockFusedCell()
$ rnn_path=`python -c "import tensorflow; print(tensorflow.contrib.rnn.__path__[0])"`
$ rnn_ops_lib=${rnn_path}/python/ops/_lstm_ops.so
$ cp -rf ${rnn_ops_lib} ${TENSORFLOW_BUILD_DIR}
$ export LD_LIBRARY_PATH=${TENSORFLOW_BUILD_DIR}:$LD_LIBRARY_PATH
* for QRNN [optional]
$ qrnn_path=`python -c "import tensorflow as tf; print(tf.__path__[0])"`
$ qrnn_lib=${qrnn_path}/../qrnn_lib.cpython-36m-x86_64-linux-gnu.so
$ cp -rf ${qrnn_lib} ${TENSORFLOW_BUILD_DIR}
-
.bashrcsample
# tensorflow so, header dist
export TENSORFLOW_SOURCE_DIR='/home/tensorflow-src-cpu'
export TENSORFLOW_BUILD_DIR='/home/tensorflow-dist-cpu'
# for loading _lstm_ops.so, qrnn_lib.cpython-36m-x86_64-linux-gnu.so
export LD_LIBRARY_PATH=${TENSORFLOW_BUILD_DIR}:$LD_LIBRARY_PATH
- test build sample model and inference by C++
$ cd /home/etagger
* build and save sample model
$ cd inference
$ python train_example.py
* inference using python
$ python python/inference_example.py
* inference using c++
* edit etagger/inference/cc/CMakeLists.txt
find_package(TensorFlow 1.11 EXACT REQUIRED)
$ cd etagger/inference/cc
$ mkdir build
$ cd build
* cmake >= 3.11, set DPYTHON_EXECUTABLE as absolute path
$ cmake .. -DPYTHON_EXECUTABLE=/usr/local/bin/python3.6m
$ make
$ cd ../..
$ ./cc/build/inference_example
- test build iris model, freezing and inference by C++
$ cd /home/etagger
* build and save iris model
$ cd inference
$ python train_iris.py
* freeze graph
$ python freeze.py --model_dir exported --output_node_names logits --frozen_model_name iris_frozen.pb
* inference using python
$ python python/inference_iris.py
* inference using C++
* edit etagger/inference/cc/CMakeLists.txt
find_package(TensorFlow 1.11 EXACT REQUIRED)
* cmake >= 3.11, set DPYTHON_EXECUTABLE as absolute path
$ cd etagger/inference/cc
$ mkdir build
$ cd build
$ cmake .. -DPYTHON_EXECUTABLE=/usr/local/bin/python3.6m
$ make
$ cd ../..
$ ./cc/build/inference_iris
- export etagger model, freezing and inference by C++
$ cd inference
* let's assume that we have a saved model :
* <note> BiLSTM, LSTMBlockFusedCell()
* : if you can't find `BlockLSTM` when using import_meta_graph()
* : similar issue => https://stackoverflow.com/questions/50298058/restore-trained-tensorflow-model-keyerror-blocklstm
: how to fix? => https://github.com/tensorflow/tensorflow/issues/23369
: what about C++? => https://stackoverflow.com/questions/50475320/executing-frozen-tensorflow-graph-that-uses-tensorflow-contrib-resampler-using-c
we can load '_lstm_ops.so' for LSTMBlockFusedCell().
* restore the model to check list of operations, placeholders and tensors for mapping. and export it another place.
$ python export.py --restore ../checkpoint/ner_model --export exported/ner_model --export-pb exported
* freeze graph
$ python freeze.py --model_dir exported --output_node_names logits_indices,sentence_lengths --frozen_model_name ner_frozen.pb
* freeze graph for bert
$ python freeze.py --model_dir exported --output_node_names logits_indices,sentence_lengths,bert_embeddings_subgraph --frozen_model_name ner_frozen.pb
$ ln -s ../embeddings embeddings
$ ln -s ../data data
* inference using python
$ python python/inference.py --emb_path embeddings/glove.6B.100d.txt.pkl --wrd_dim 100 --frozen_path exported/ner_frozen.pb < ../data/test.txt > pred.txt
$ python python/inference.py --emb_path embeddings/glove.6B.300d.txt.pkl --wrd_dim 300 --frozen_path exported/ner_frozen.pb < ../data/test.txt > pred.txt
$ python python/inference.py --emb_path embeddings/glove.840B.300d.txt.pkl --wrd_dim 300 --frozen_path exported/ner_frozen.pb < ../data/test.txt > pred.txt
* you may need to modify build_input_feed_dict() in 'python/inference.py' for emb_class='bert'.
* since some of input tensor might not exist in the frozen graph. ex) 'input_data_chk_ids'
* inference using python with optimized graph_def via tensorRT (only for GPU)
$ python python/inference_trt.py --emb_path embeddings/glove.6B.100d.txt.pkl --wrd_dim 100 --frozen_path exported/ner_frozen.pb < ../data/test.txt > pred.txt
$ python python/inference_trt.py --emb_path embeddings/glove.6B.300d.txt.pkl --wrd_dim 300 --frozen_path exported/ner_frozen.pb < ../data/test.txt > pred.txt
$ python python/inference_trt.py --emb_path embeddings/glove.840B.300d.txt.pkl --wrd_dim 300 --frozen_path exported/ner_frozen.pb < ../data/test.txt > pred.txt
* inspect `pred.txt` whether the predictions are same.
$ perl ../etc/conlleval < pred.txt
* for inference by C++, i implemented emb_class='glove' only.
* inference using C++
$ ./cc/build/inference exported/ner_frozen.pb embeddings/vocab.txt < ../data/test.txt > pred.txt
* inspect `pred.txt` whether the predictions are same.
$ perl ../etc/conlleval < pred.txt
- optimizing graph for inference, convert it to memory mapped format and inference by C++
$ cd inference
* optimize graph for inference
# not working properly
$ ${TENSORFLOW_SOURCE_DIR}/bazel-bin/tensorflow/python/tools/optimize_for_inference --input=exported/ner_frozen.pb --output=exported/ner_frozen.pb.optimized --input_names=is_train,sentence_length,input_data_pos_ids,input_data_chk_ids,input_data_word_ids,input_data_wordchr_ids --output_names=logits_indices,sentence_lengths
* quantize graph
# not working properly
$ ${TENSORFLOW_SOURCE_DIR}/bazel-bin/tensorflow/tools/quantization/quantize_graph --input=exported/ner_frozen.pb --output=exported/ner_frozen.pb.rounded --output_node_names=logits_indices,sentence_lengths --mode=weights_rounded
* transform graph
$ ${TENSORFLOW_SOURCE_DIR}/bazel-bin/tensorflow/tools/graph_transforms/transform_graph --in_graph=exported/ner_frozen.pb --out_graph=exported/ner_frozen.pb.transformed --inputs=is_train,sentence_length,input_data_pos_ids,input_data_chk_ids,input_data_word_ids,input_data_wordchr_ids --outputs=logits_indices,sentence_lengths --transforms='strip_unused_nodes merge_duplicate_nodes round_weights(num_steps=256) sort_by_execution_order'
* convert to memory mapped format
$ ${TENSORFLOW_SOURCE_DIR}/bazel-bin/tensorflow/contrib/util/convert_graphdef_memmapped_format --in_graph=exported/ner_frozen.pb --out_graph=exported/ner_frozen.pb.memmapped
or
$ ${TENSORFLOW_SOURCE_DIR}/bazel-bin/tensorflow/contrib/util/convert_graphdef_memmapped_format --in_graph=exported/ner_frozen.pb.transformed --out_graph=exported/ner_frozen.pb.memmapped
* inference using C++
$ ./cc/build/inference exported/ner_frozen.pb.memmapped embeddings/vocab.txt 1 < ../data/test.txt > pred.txt
* inspect `pred.txt` whether the predictions are same.
$ perl ../etc/conlleval < pred.txt
* inspect the memory mapped graph is opened with MAP_SHARED
$ cat /proc/pid/maps
7fae40522000-7fae4a000000 r--s 00000000 08:11 749936602 /root/etagger/inference/exported/ner_frozen.pb.memmapped
...
- python wrapper for C
$ cd inference/cc/wrapper
* edit inferency.py : so_path = os.path.dirname(os.path.abspath(__file__)) + '/../build' + '/' + 'libetagger.so'
$ python inference.py --frozen_graph_fn ../../exported/ner_frozen.pb --vocab_fn ../../../embeddings/vocab.txt < ../../../data/test.txt.sentences > pred.txt
or
$ python inference.py --frozen_graph_fn ../../exported/ner_frozen.pb.memmapped --vocab_fn ../../../embeddings/vocab.txt --is_memmapped=True < ../../../data/test.txt.sentences > pred.txt
web api
- inference api using frozen model
$ cd inference/python/www
$ ./stop.sh
$ ./start.sh
- web
- demo : http://host:8898
- api : http://host:8898/etagger?q=
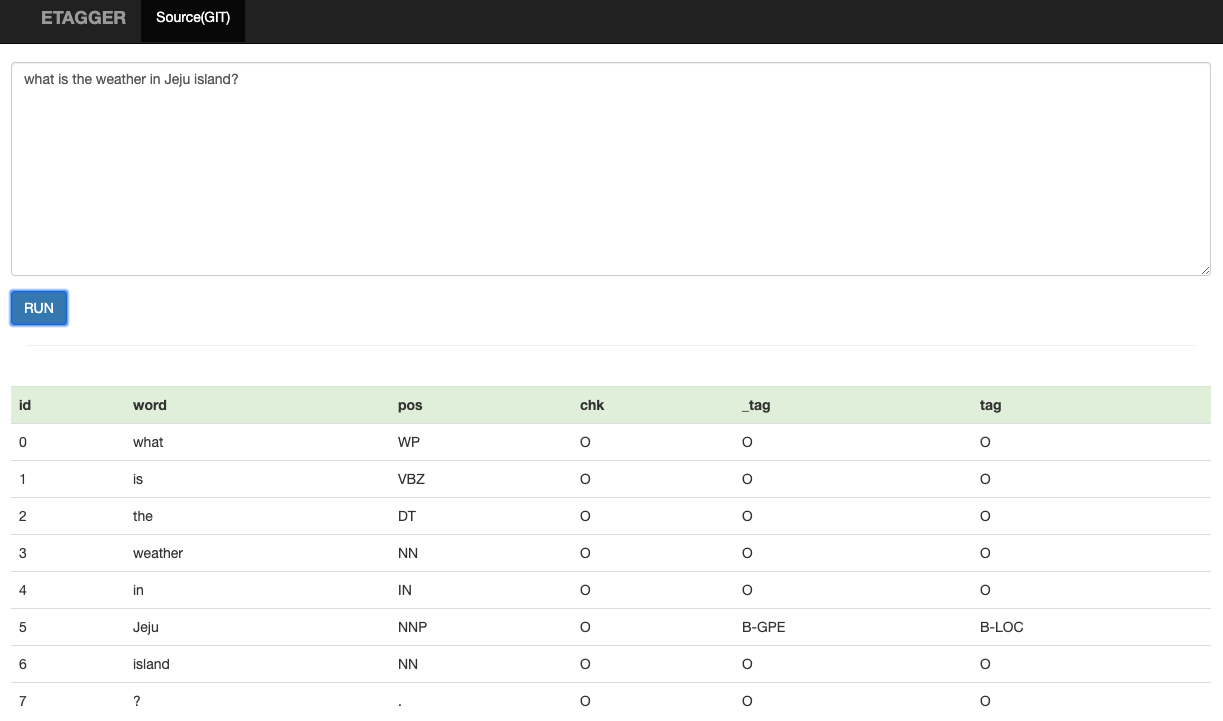

- inference api using memmapped model, C++, C/python wrapper


$ cd inference/cc/www
$ ./stop.sh
$ ./start.sh
Evaluation, Dev note, References, Etc
- read more
- recent evaluation results
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].