h2oai / Mli Resources
Programming Languages
Projects that are alternatives of or similar to Mli Resources
Machine Learning Interpretability (MLI)
Machine learning algorithms create potentially more accurate models than linear models, but any increase in accuracy over more traditional, better-understood, and more easily explainable techniques is not practical for those who must explain their models to regulators or customers. For many decades, the models created by machine learning algorithms were generally taken to be black-boxes. However, a recent flurry of research has introduced credible techniques for interpreting complex, machine-learned models. Materials presented here illustrate applications or adaptations of these techniques for practicing data scientists.
Want to contribute your own content? Just make a pull request.
Want to use the content in this repo? Just cite the H2O.ai machine learning interpretability team or the original author(s) as appropriate.
Contents
- Practical MLI Examples
- Testing Explanations
- Webinars/Videos
- Booklets
- Conference Presentations
- Miscellaneous Resources
- References
Practical MLI examples
(A Dockerfile is provided that will construct a container with all necessary dependencies to run the examples here.)
- Decision tree surrogate models
- LIME (practical samples variant)
- LOCO (NA variant)
- Partial dependence and individual conditional expectation (ICE)
- Sensitivity analysis
- Monotonic models with XGBoost
- Diabetes data set use case (Diabetes use case has different Dockerfile in seperate repo.)
Installation of Examples
Dockerfile
A Dockerfile is provided to build a docker container with all necessary packages and dependencies. This is the easiest way to use these examples if you are on Mac OS X, *nix, or Windows 10. To do so:
- Install and start docker. From a terminal:
- Create a directory for the Dockerfile.
$ mkdir anaconda_py36_h2o_xgboost_graphviz - Fetch the Dockerfile from the mli-resources repo.
$ curl https://raw.githubusercontent.com/h2oai/mli-resources/master/anaconda_py36_h2o_xgboost_graphviz/Dockerfile > anaconda_py36_h2o_xgboost_graphviz/Dockerfile - Build a docker image from the Dockefile. For this and other docker commands below, you may need to use
sudo.$ docker build --no-cache anaconda_py36_h2o_xgboost_graphviz - Display docker image IDs. You are probably interested in the most recently created image.
$ docker images - Start the docker image and the Jupyter notebook server.
$ docker run -i -t -p 8888:8888 <image_id> /bin/bash -c "/opt/conda/bin/conda install jupyter -y --quiet && /opt/conda/bin/jupyter notebook --notebook-dir=/mli-resources --ip='*' --port=8888 --no-browser --allow-root" - List docker containers.
$ docker ps - Copy the sample data into the Docker container. Refer to GetData.md to obtain datasets needed for notebooks.
$ docker cp path/to/train.csv <container_id>:/mli-resources/data/train.csv - Navigate to the port Jupyter directs you to on your machine. It will likely include a token.
Manual
Install:
- Anaconda Python 5.1.0 from the Anaconda archives.
- Java.
- The latest stable h2o Python package.
- Git.
- XGBoost with Python bindings.
- GraphViz.
Anaconda Python, Java, Git, and GraphViz must be added to your system path.
From a terminal:
- Clone the mli-resources repository with examples.
$ git clone https://github.com/h2oai/mli-resources.git $ cd mli-resources- Copy the sample data into the mli-resources repo directory. Refer to GetData.md to obtain datasets needed for notebooks.
$ cp path/to/train.csv ./data - Start the Jupyter notebook server.
$ jupyter notebook - Navigate to the port Jupyter directs you to on your machine.
Additional Code Examples
The notebooks in this repo have been revamped and refined many times. Other versions with different, and potentially interesting, details are available at these locations:
Testing Explanations
One way to test generated explanations for accuracy is with simulated data with known characteristics. For instance, models trained on totally random data with no relationship between a number of input variables and a prediction target should not give strong weight to any input variable nor generate compelling local explanations or reason codes. Conversely, you can use simulated data with a known signal generating function to test that explanations accurately represent that known function. Detailed examples of testing explanations with simulated data are available here. A summary of these results are available here.
Webinars/Videos
- Interpretable Machine Learning Meetup - Washington DC
- Machine Learning Interpretability with Driverless AI
- Interpretability in conversation with Patrick Hall and Sameer Singh
- NYC Big Data Science Meetup I (less technical)
- NYC Big Data Science Meetup II (more technical)
- H2O Driverless AI machine learning interpretability software walk-through (accompanies cheatsheet below)
- H2O World SF 2019: Human-Centered ML
- O'Reilly Media Interactive Notebooks (Requires O'Reilly Safari Membership):
- Enhancing transparency in machine learning models with Python and XGBoost
- Increase transparency and accountability in your machine learning project with Python
- Explain your predictive models to business stakeholders with LIME, Python, and H2O
- Testing machine learning models for accuracy, trustworthiness, and stability with Python and H2O
Booklets
- An Introduction to Machine Learning Interpretability
- Machine Learning Interpretability with H2O Driverless AI Booklet
Conference Presentations
- Practical Techniques for Interpreting Machine Learning Models - 2018 FAT* Conference Tutorial
- Driverless AI Hands-On Focused on Machine Learning Interpretability - H2O World 2017
- Interpretable AI: Not Just For Regulators! - Strata NYC 2017
- JSM 2018 Slides
- ODSC 2018 Slides
- H2O World SF 2019: Human-Centered ML
Miscellaneous Resources
- Ideas on Interpreting Machine Learning - SlideShare
- Predictive modeling: Striking a balance between accuracy and interpretability
- Testing machine learning explanation techniques
- Interpreting Machine Learning Models: An Overview
-
H2O Driverless AI MLI cheatsheet (accompanies walk-through video above)

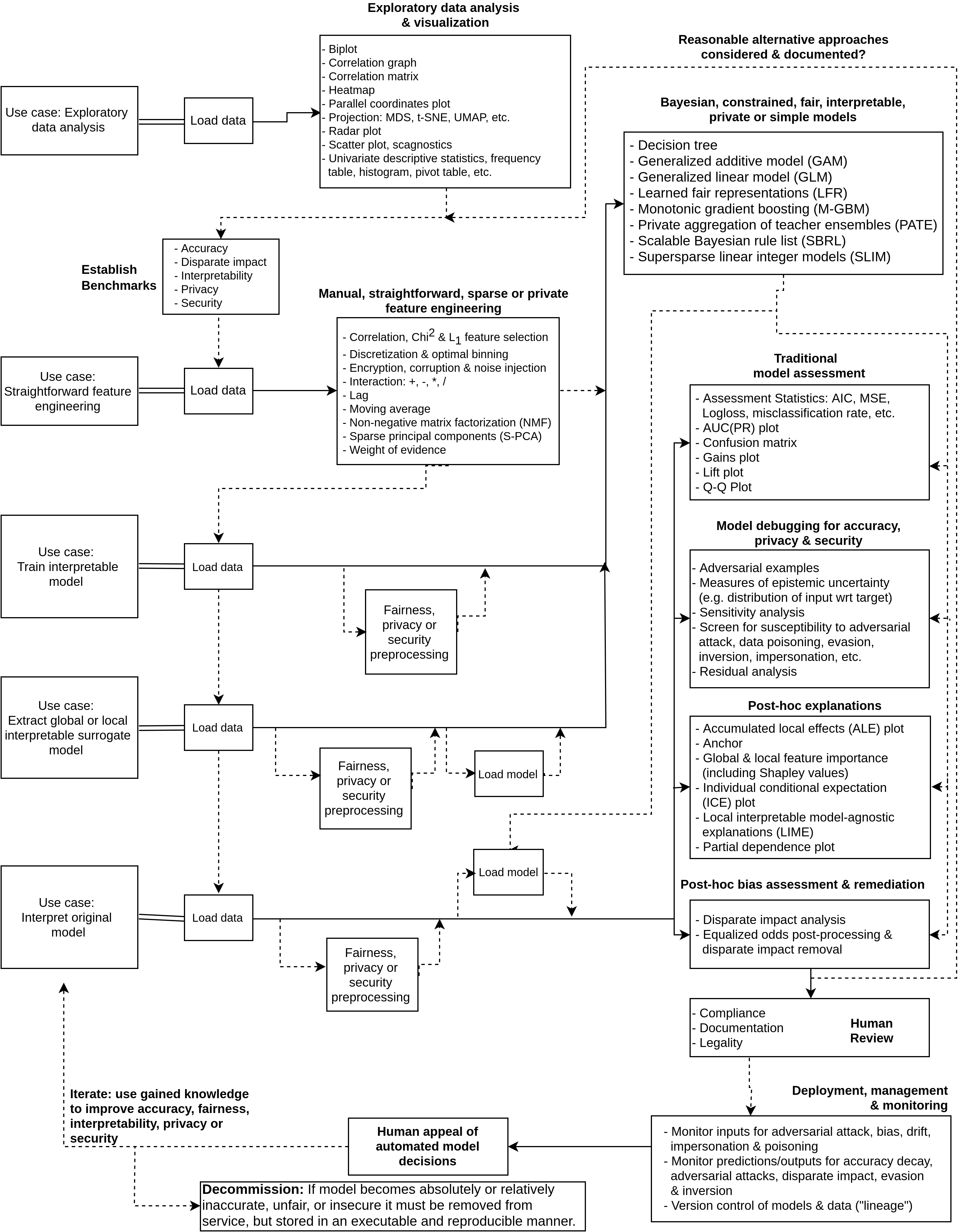
- Imperfect, incomplete, but one-page blueprint for human-friendly machine learning: PNG, draw.io XML


General References
- Towards A Rigorous Science of Interpretable Machine Learning
- Ideas for Machine Learning Interpretability
- Fairness, Accountability, and Transparency in Machine Learning (FAT/ML) Scholarship
- Explaining Explanations: An Approach to Evaluating Interpretability of Machine Learning
- A Survey Of Methods For Explaining Black Box Models
- Trends and Trajectories for Explainable, Accountable and Intelligible Systems: An HCI Research Agenda
- Interpretable Machine Learning by Christoph Molnar
- On the Art and Science of Machine Learning Explanations (JSM 2018 Proceedings paper)
- Toward Dispelling Unhelpful Explainable Machine Learning (ML) Misconceptions (Preprint/WIP)
- The Mythos of Model Interpretability
- Challenges for Transparency
- Explaining by Removing: A Unified Framework for Model Explanation