Yord / Pxi
Programming Languages
Projects that are alternatives of or similar to Pxi
🧚pxi (pixie) is a small, fast, and magical command-line data processor similar to jq, mlr, and awk.



![]()
![]()
![]()
![]()
Installation
Installation is done using npm.
$ npm i -g pxi
Try pxi --help to see if the installation was successful.
Features
- 🧚 Small: Pixie does one thing and does it well (processing data with JavaScript).
- ⚡️ Fast:
pxiis as fast asgawk, 3x faster thanjqandmlr, and 15x faster thanfx. - ✨ Magical: It is trivial to write your own
spellsplugins. - 😸 Playful: Opt-in to more data formats by installing plugins.
- 🎉 Versatile: Use Ramda, Lodash and any other JavaScript library to process data on the command-line.
- ❤️ Loving: Pixie is made with love and encourages a positive and welcoming environment.
Getting Started
Pixie reads in big structured text files, transforms them with JavaScript functions, and writes them back to disk.
The usage examples in this section are based on the following large JSONL file.
Inspect the examples by clicking on them!
$ head -5 2019.jsonl # 2.6GB, 31,536,000 lines
{"time":1546300800,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":0}
{"time":1546300801,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":1}
{"time":1546300802,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":2}
{"time":1546300803,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":3}
{"time":1546300804,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":4}
Execute any JavaScript function:
$ pxi "json => json.time" < 2019.jsonl
$ pxi "({time}) => time" < 2019.jsonl
You may use JavaScript arrow functions, destructuring, spreading, and any other feature of your current NodeJS version.
1546300800
1546300801
1546300802
1546300803
1546300804
Convert between JSON, CSV, SSV, and TSV:
$ pxi --from json --to csv < 2019.jsonl > 2019.csv
$ pxi --deserializer json --serializer csv < 2019.jsonl > 2019.csv
$ pxi -d json -s csv < 2019.jsonl > 2019.csv
Users may extend pixie with (third-party) plugins for many more data formats.
See the .pxi module section on how to do that and the plugins section for a list.
Pixie deserializes data into JSON, applies functions, and serializes JSON to another format.
It offers the telling aliases --from and --to alternative to --deserializer and --serializer.
time,year,month,day,hours,minutes,seconds
1546300800,2019,1,1,0,0,0
1546300801,2019,1,1,0,0,1
1546300802,2019,1,1,0,0,2
1546300803,2019,1,1,0,0,3
Use Ramda, Lodash or any other JavaScript library:
$ pxi "o(obj => _.omit(obj, ['seconds']), evolve({time: parseInt}))" --from csv < 2019.csv
Pixie may use any JavaScript library, including Ramda and Lodash.
Read the .pxi module section to learn more.
{"time":1546300800,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0"}
{"time":1546300801,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0"}
{"time":1546300802,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0"}
{"time":1546300803,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0"}
{"time":1546300804,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0"}
Process data streams from REST APIs and other sources and pipe pixie's output to other commands:
$ curl -s "https://swapi.co/api/films/" |
pxi 'json => json.results' --with flatMap --keep '["episode_id", "title"]' |
sort
Pixie follows the unix philosophy: It does one thing (processing structured data), and does it well. It is written to work together with other programs and it handles text streams because that is a universal interface.
{"episode_id":1,"title":"The Phantom Menace"}
{"episode_id":2,"title":"Attack of the Clones"}
{"episode_id":3,"title":"Revenge of the Sith"}
{"episode_id":4,"title":"A New Hope"}
{"episode_id":5,"title":"The Empire Strikes Back"}
{"episode_id":6,"title":"Return of the Jedi"}
{"episode_id":7,"title":"The Force Awakens"}
Use pixie's ssv deserializer to work with command line output:
$ ls -ahl / | pxi '([,,,,size,,,,file]) => ({size, file})' --from ssv
Pixie's space-separated values deserializer makes it very easy to work with the output of other commands. Array destructuring is especially helpful in this area.
{"size":"704B","file":"."}
{"size":"704B","file":".."}
{"size":"1.2K","file":"bin"}
{"size":"4.4K","file":"dev"}
{"size":"11B","file":"etc"}
{"size":"25B","file":"home"}
{"size":"64B","file":"opt"}
{"size":"192B","file":"private"}
{"size":"2.0K","file":"sbin"}
{"size":"11B","file":"tmp"}
{"size":"352B","file":"usr"}
{"size":"11B","file":"var"}
See the usage section below for more examples.
Introductory Blogposts
For a quick start, read the following blog posts:
🧚 Pixie
Pixie's philosophy is to provide a small, extensible frame for processing large files and streams with JavaScript functions. Different data formats are supported through plugins. JSON, CSV, SSV, and TSV are supported by default, but users can customize their pixie installation by picking and choosing from more available (including third-party) plugins.
Pixie works its magic by chunking, deserializing, applying functions, and serializing data. Expressed in code, it works like this:
function pxi (data) { // Data is passed to pxi from stdin.
const chunks = chunk(data) // The data is chunked.
const jsons = deserialize(chunks) // The chunks are deserialized into JSON objects.
const jsons2 = apply(f, jsons) // f is applied to each object and new JSON objects are returned.
const string = serialize(jsons2) // The new objects are serialized to a string.
process.stdout.write(string) // The string is written to stdout.
}
For example, chunking, deserializing, and serializing JSON is provided by the pxi-json plugin.
Plugins
The following plugins are available:
| Chunkers | Deserializers | Appliers | Serializers | pxi |
|
|---|---|---|---|---|---|
pxi-dust |
line |
map, flatMap, filter
|
string |
✓ | |
pxi-json |
jsonObj |
json |
json |
✓ | |
pxi-dsv |
csv, tsv, ssv, dsv
|
csv, tsv, ssv, dsv
|
✓ | ||
pxi-sample |
sample |
sample |
sample |
sample |
✕ |
The last column states which plugins come preinstalled in pxi.
Refer to the .pxi Module section to see how to enable more plugins and how to develop plugins.
New experimental pixie plugins are developed i.a. in the pxi-sandbox repository.
Performance
pxi is very fast and beats several similar tools in performance benchmarks.
Times are given in CPU time (seconds), wall-clock times may deviate by ± 1s.
The benchmarks were run on a 13" MacBook Pro (2019) with a 2,8 GHz Quad-Core i7 and 16GB memory.
Feel free to run the benchmarks on your own machine
and if you do, please open an issue to report your results!
| Benchmark | Description | pxi |
gawk |
jq |
mlr |
fx |
|---|---|---|---|---|---|---|
| JSON 1 | Select an attribute on small JSON objects | 11s | 15s | 46s | – | 284s |
| JSON 2 | Select an attribute on large JSON objects | 20s | 20s | 97s | – | 301s |
| JSON 3 | Pick a single attribute on small JSON objects | 15s | 21s | 68s | 91s | 368s |
| JSON 4 | Pick a single attribute on large JSON objects | 26s | 27s | 130s | 257s† | 420s |
| JSON to CSV 1 | Convert a small JSON to CSV format | 15s | – | 77s | 60s | – |
| JSON to CSV 2 | Convert a large JSON to CSV format | 38s | – | 264s | 237s† | – |
| CSV 1 | Select a column from a small csv file | 11s | 8s | 37s | 23s | – |
| CSV 2 | Select a column from a large csv file | 19s | 9s | 66s | 72s | – |
| CSV to JSON 1 | Convert a small CSV to JSON format | 15s | – | – | 120s | – |
| CSV to JSON 2 | Convert a large CSV to JSON format | 42s | – | – | 352s | – |
† mlr appears to load the whole file instead of processing it in chunks if reading JSON.
This is why it fails on large input files.
So in these benchmarks, the first 20,000,000 lines are processed first, followed by the remaining 11,536,000 lines.
The times of both runs are summed up.
pxi and gawk notably beat
jq, mlr, and fx in every benchmark.
However, due to its different data processing approach, pxi is more versatile than gawk
and is e.g. able to transform data formats into another.
For a more detailed interpretation, open this box.
pxi and gawk differ greatly in their approaches to transforming data:
While gawk manipulates strings, pxi parses data according to a format, builds an internal JSON representation,
manipulates this JSON, and serializes it to a different format.
Surprisingly, they perform equally well in the benchmarks,
with pxi being a little faster in JSON and gawk in CSV.
However, the more attributes JSON objects have and the more columns CSV files have,
the faster gawk gets compared to pxi, because it does not need to build an internal data representation.
On the other hand, while pxi is able to perform complex format transformations,
gawk is unable to do it because of its different approach.
jq and mlr share pxi's data transformation approach, but focus on different formats:
While jq specializes in transforming JSON, mlr's focus is CSV.
Although pxi does not prefer one format over the other,
it beats both tools in processing speed on their preferred formats.
fx and pxi are very similar in that both are written in JavaScript and use JavaScript as their processing language.
However, although fx specializes in just the JSON format, pxi is at least 15x faster in all benchmarks.
All tools differ in their memory needs.
Since pxi and fx are written in an interpreted language, they need approx. 70 MB due to their runtime.
Since gawk and jq are compiled binaries, they only need approx. 1MB.
mlr needs the most memory (up to 11GB), since it appears to load the whole file before processing it in some cases.
Usage
The examples in this section are based on the following big JSONL file.
Inspect the examples by clicking on them!
$ head -5 2019.jsonl # 2.6GB, 31,536,000 lines
{"time":1546300800,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":0}
{"time":1546300801,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":1}
{"time":1546300802,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":2}
{"time":1546300803,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":3}
{"time":1546300804,"year":2019,"month":1,"day":1,"hours":0,"minutes":0,"seconds":4}
Select the time:
$ pxi "json => json.time" < 2019.jsonl
Go ahead and use JavaScript's arrow functions.
1546300800
1546300801
1546300802
1546300803
1546300804
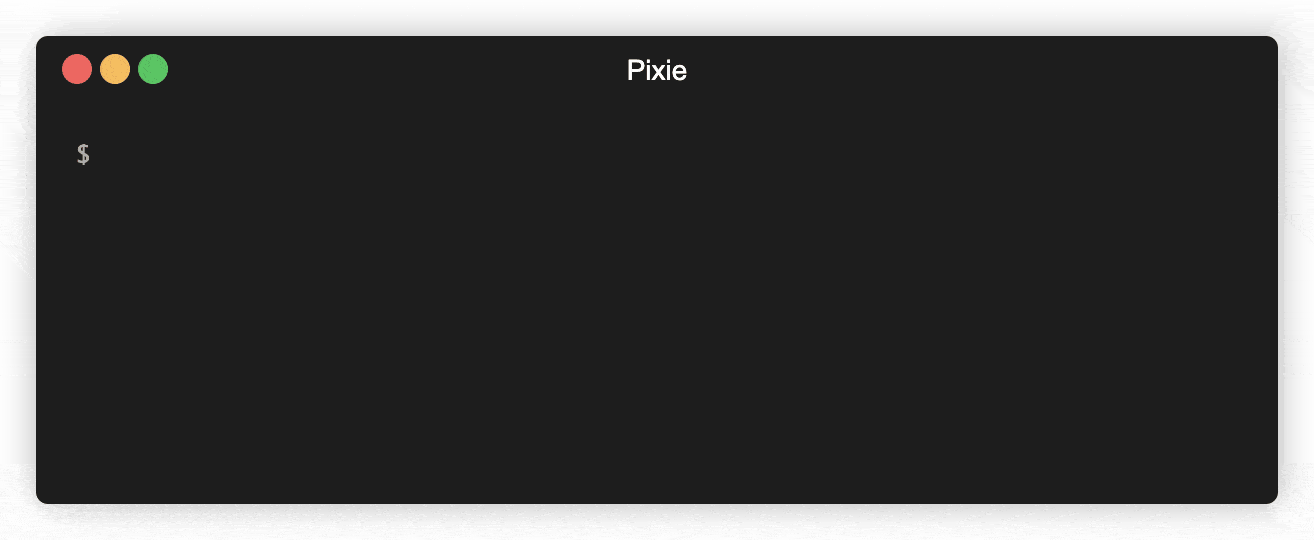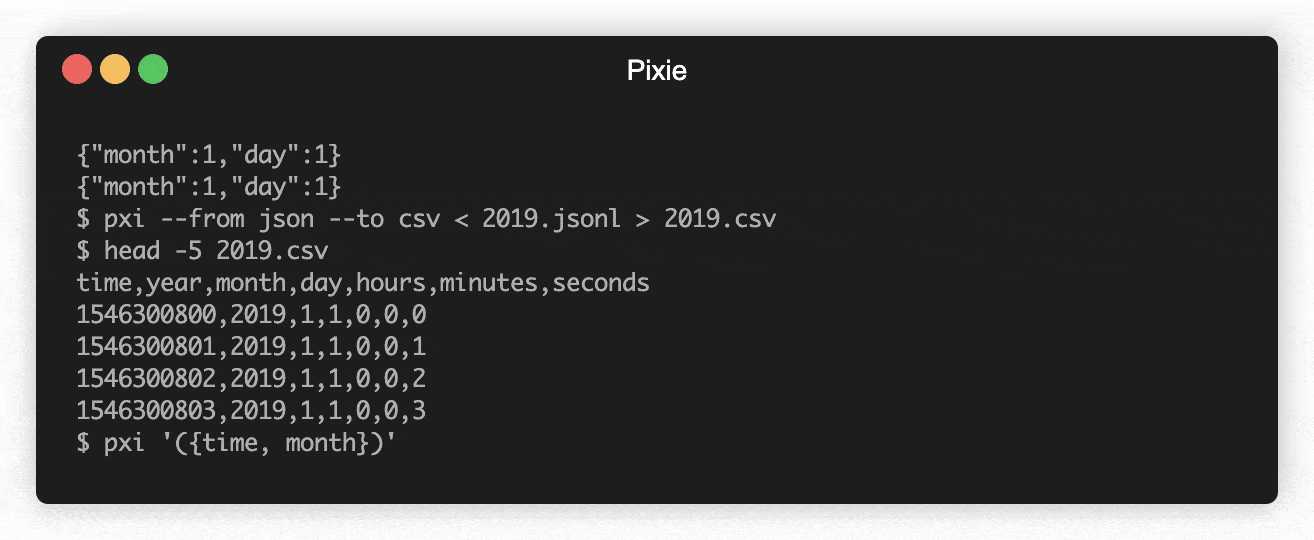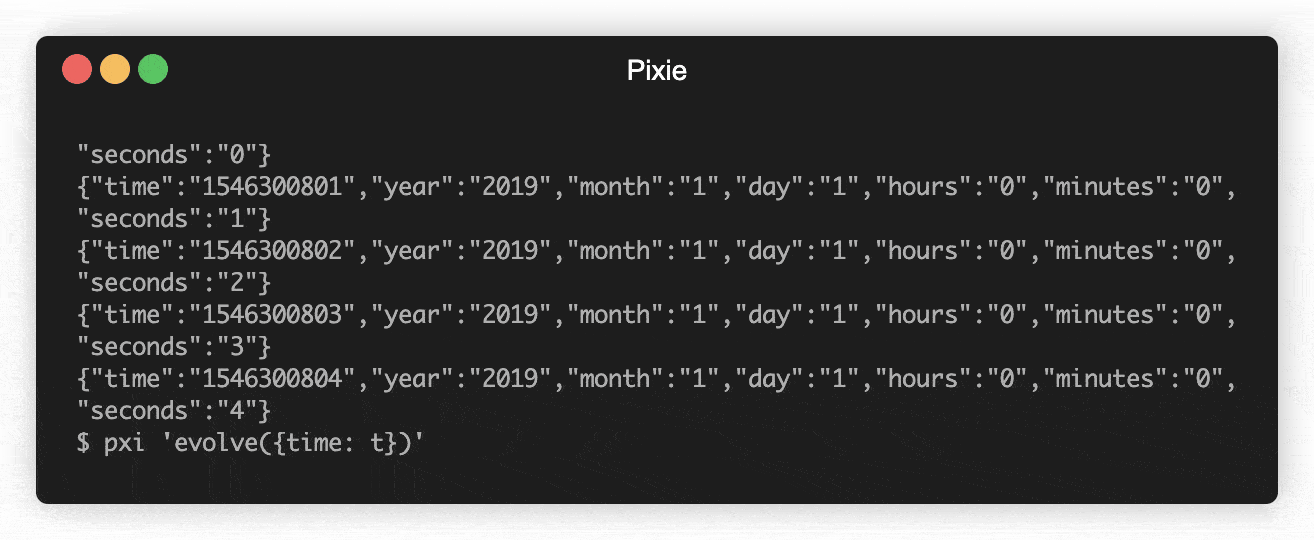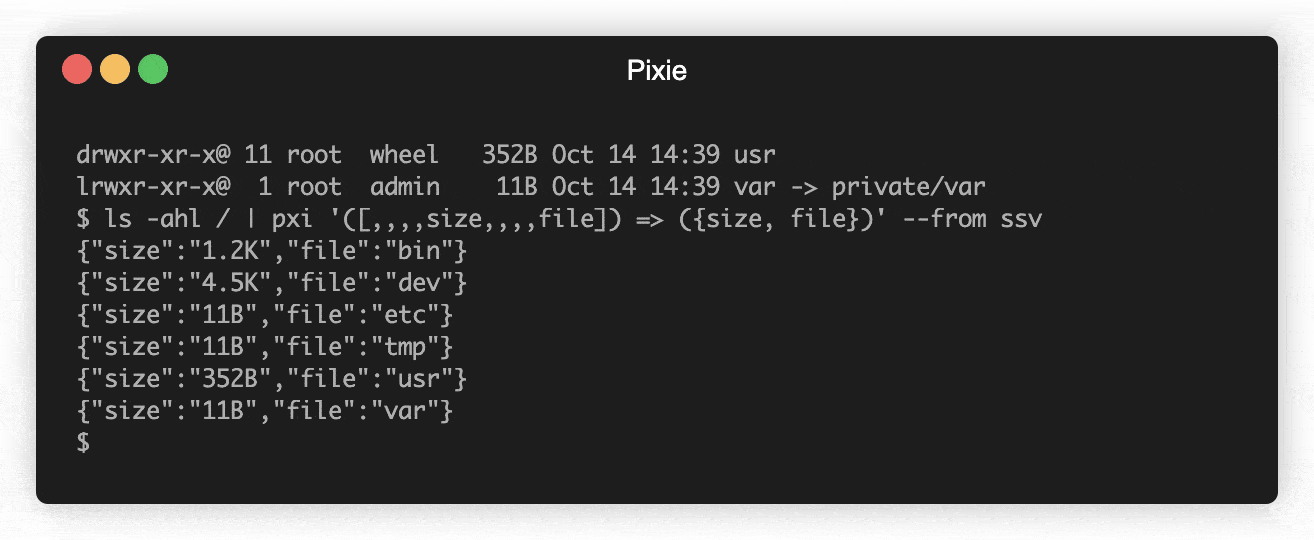
Select month and day:
$ pxi '({month, day}) => ({month, day})' < 2019.jsonl
Use destructuring and spread syntax.
{"month":1,"day":1}
{"month":1,"day":1}
{"month":1,"day":1}
{"month":1,"day":1}
{"month":1,"day":1}
Convert JSON to CSV:
$ pxi --from json --to csv < 2019.jsonl > 2019.csv
Pixie has deserializers (--from) and serializers (--to) for various data formats, including JSON and CSV.
JSON is the default deserializer and serializer, so no need to type --from json and --to json.
time,year,month,day,hours,minutes,seconds
1546300800,2019,1,1,0,0,0
1546300801,2019,1,1,0,0,1
1546300802,2019,1,1,0,0,2
1546300803,2019,1,1,0,0,3
1546300804,2019,1,1,0,0,4
Convert JSON to CSV, but keep only time and month:
$ pxi '({time, month}) => [time, month]' --to csv < 2019.jsonl
Serializers can be freely combined with functions.
1546300800,1
1546300801,1
1546300802,1
1546300803,1
1546300804,1
Rename time to timestamp and convert CSV to TSV:
$ pxi '({time, ...rest}) => ({timestamp: time, ...rest})' --from csv --to tsv < 2019.csv
Read in CSV format. Use destructuring to select all attributes other than time. Rename time to timestamp and keep all other attributes unchanged. Write in TSV format.
timestamp year month day hours minutes seconds
1546300800 2019 1 1 0 0 0
1546300801 2019 1 1 0 0 1
1546300802 2019 1 1 0 0 2
1546300803 2019 1 1 0 0 3
1546300804 2019 1 1 0 0 4
Convert CSV to JSON:
$ pxi --deserializer csv --serializer json < 2019.csv
--from and --to are aliases for --deserializer and --serializer that are used to convert between formats.
{"time":"1546300800","year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"0"}
{"time":"1546300801","year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"1"}
{"time":"1546300802","year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"2"}
{"time":"1546300803","year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"3"}
{"time":"1546300804","year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"4"}
Convert CSV to JSON and cast time to integer:
$ pxi '({time, ...rest}) => ({time: parseInt(time), ...rest})' -d csv < 2019.csv
Deserializing from CSV does not automatically cast strings to other types. This is intentional, since some use cases may need casting, and others don't. If you need a key to be an integer, you need to explicitly transform it.
{"time":1546300800,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"0"}
{"time":1546300801,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"1"}
{"time":1546300802,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"2"}
{"time":1546300803,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"3"}
{"time":1546300804,"year":"2019","month":"1","day":"1","hours":"0","minutes":"0","seconds":"4"}
Use Ramda (or Lodash):
$ pxi 'evolve({year: parseInt, month: parseInt, day: parseInt})' -d csv < 2019.csv
Pixie may use any JavaScript library, including Ramda and Lodash.
The .pxi module section tells you how to install them.
{"time":"1546300800","year":2019,"month":1,"day":1,"hours":"0","minutes":"0","seconds":"0"}
{"time":"1546300801","year":2019,"month":1,"day":1,"hours":"0","minutes":"0","seconds":"1"}
{"time":"1546300802","year":2019,"month":1,"day":1,"hours":"0","minutes":"0","seconds":"2"}
{"time":"1546300803","year":2019,"month":1,"day":1,"hours":"0","minutes":"0","seconds":"3"}
{"time":"1546300804","year":2019,"month":1,"day":1,"hours":"0","minutes":"0","seconds":"4"}
Select only May the 4th:
$ pxi '({month, day}) => month == 5 && day == 4' --applier filter < 2019.jsonl
Appliers determine how functions are applied.
The default applier is map, which applies the function to each element.
Here, we use the filter applier that keeps only elements for which the function yields true.
{"time":1556928000,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":0}
{"time":1556928001,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":1}
{"time":1556928002,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":2}
{"time":1556928003,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":3}
{"time":1556928004,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":4}
Use more than one function:
$ pxi '({month}) => month == 5' '({day}) => day == 4' -a filter < 2019.jsonl
Functions are applied in the given order on an element to element basis. In this case, each element is first checked for the month, then for the day.
{"time":1556928000,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":0}
{"time":1556928001,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":1}
{"time":1556928002,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":2}
{"time":1556928003,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":3}
{"time":1556928004,"year":2019,"month":5,"day":4,"hours":0,"minutes":0,"seconds":4}
Keep only certain keys and pretty-print JSON:
$ pxi --keep '["time"]' --spaces 2 < 2019.jsonl > pretty.jsonl
The --keep attribute takes a stringified JSON array and narrows each element to only the keys in it.
Using --spaces with any value other than 0 formats the serialized JSON using the provided number as spaces.
{
"time": 1546300800
}
{
"time": 1546300801
}
{
"time": 1546300802
}
{
"time": 1546300803
}
{
"time": 1546300804
}
Deserialize JSON that is not given line by line:
$ pxi --by jsonObj < pretty.jsonl
The --chunker or --by attribute defines how data is turned into chunks that are deserialized.
The default chunker is line which treats each line as a chunk.
In cases where JSON is not given line by line, e.g. if it is pretty-printed, the jsonObj chunker helps.
{"time":1546300800}
{"time":1546300801}
{"time":1546300802}
{"time":1546300803}
{"time":1546300804}
Suppose you have to access a web API:
$ curl -s "https://swapi.co/api/people/"
The returned JSON is one big mess and needs to be tamed.
{"count":87,"next":"...","results":[{"name":"Luke Skywalker","height":"172","mass":"77" [...]
Use pixie to organize the response:
$ curl -s "https://swapi.co/api/people/" |
pxi "json => json.results" --with flatMap --keep '["name","height","mass"]'
Here, the --with alias for --applier is used.
The function selects the results array.
If it were applied with map, it would return the whole array as an element.
But since we use the flatMap applier, each array item is returned as an element, instead.
The --keep attribute specifies, which keys to keep from the returned objects:
{"name":"Luke Skywalker","height":"172","mass":"77"}
{"name":"C-3PO","height":"167","mass":"75"}
{"name":"R2-D2","height":"96","mass":"32"}
{"name":"Darth Vader","height":"202","mass":"136"}
{"name":"Leia Organa","height":"150","mass":"49"}
{"name":"Owen Lars","height":"178","mass":"120"}
{"name":"Beru Whitesun lars","height":"165","mass":"75"}
{"name":"R5-D4","height":"97","mass":"32"}
{"name":"Biggs Darklighter","height":"183","mass":"84"}
{"name":"Obi-Wan Kenobi","height":"182","mass":"77"}
Compute all Star Wars character's BMI:
$ curl -s "https://swapi.co/api/people/" |
pxi "json => json.results" -a flatMap -K '["name","height","mass"]' |
pxi "ch => (ch.bmi = ch.mass / (ch.height / 100) ** 2, ch)" -K '["name","bmi"]'
We use pixie to compute each character's BMI.
The default chunker line and the default applier map are suitable to apply a BMI-computing function to each line.
Before serializing to the default format JSON, we only keep the name and bmi fields.
The map applier supports mutating function inputs, which might be a problem for other appliers, so be careful.
{"name":"Luke Skywalker","bmi":26.027582477014604}
{"name":"C-3PO","bmi":26.89232313815483}
{"name":"R2-D2","bmi":34.72222222222222}
{"name":"Darth Vader","bmi":33.33006567983531}
{"name":"Leia Organa","bmi":21.77777777777778}
{"name":"Owen Lars","bmi":37.87400580734756}
{"name":"Beru Whitesun lars","bmi":27.548209366391188}
{"name":"R5-D4","bmi":34.009990434690195}
{"name":"Biggs Darklighter","bmi":25.082863029651524}
{"name":"Obi-Wan Kenobi","bmi":23.24598478444632}
Identify all obese Star Wars characters:
$ curl -s "https://swapi.co/api/people/" |
pxi "json => json.results" -a flatMap -K '["name","height","mass"]' |
pxi "ch => (ch.bmi = ch.mass / (ch.height / 100) ** 2, ch)" -K '["name","bmi"]' |
pxi "ch => ch.bmi >= 30" -a filter -K '["name"]'
Finally, we use the filter applier to identify obese characters and keep only their names.
{"name":"R2-D2"}
{"name":"Darth Vader"}
{"name":"Owen Lars"}
{"name":"R5-D4"}
As it turns out, Anakin could use some training.
Select PID and CMD from ps:
$ ps | pxi '([pid, tty, time, cmd]) => ({pid, cmd})' --from ssv
Pixie supports space-separated values, which is perfect for processing command line output.
{"pid":"42978","cmd":"-zsh"}
{"pid":"42988","cmd":"-zsh"}
{"pid":"43006","cmd":"-zsh"}
{"pid":"43030","cmd":"-zsh"}
{"pid":"43067","cmd":"-zsh"}
Select file size and filename from ls:
$ ls -ahl / | pxi '([,,,,size,,,,file]) => ({size, file})' --from ssv
Array destructuring is especially useful when working with space-separated values.
{"size":"704B","file":"."}
{"size":"704B","file":".."}
{"size":"1.2K","file":"bin"}
{"size":"4.4K","file":"dev"}
{"size":"11B","file":"etc"}
{"size":"25B","file":"home"}
{"size":"64B","file":"opt"}
{"size":"192B","file":"private"}
{"size":"2.0K","file":"sbin"}
{"size":"11B","file":"tmp"}
{"size":"352B","file":"usr"}
{"size":"11B","file":"var"}
Allow JSON objects and lists in CSV:
$ echo '{"a":1,"b":[1,2,3]}\n{"a":2,"b":{"c":2}}' |
pxi --to csv --no-fixed-length --allow-list-values
Pixie can be told to allow JSON encoded lists and objects in CSV files. Note, how pixie takes care of quoting and escaping those values for you.
a,b
1,"[1,2,3]"
2,"{""c"":2}"
Decode JSON values in CSV:
$ echo '{"a":1,"b":[1,2,3]}\n{"a":2,"b":{"c":2}}' |
pxi --to csv --no-fixed-length --allow-list-values |
pxi --from csv 'evolve({b: JSON.parse})'
JSON values are treated as strings and are not automatically parsed. This is intentional, as pixie tries to keep as much out of your way as possible. They can be transformed back into JSON by applying JSON.parse in a function.
{"a":"1","b":[1,2,3]}
{"a":"2","b":{"c":2}}
.pxi Module
Users may extend and modify pxi by providing a .pxi module.
If you wish to do that, create a ~/.pxi/index.js file and insert the following base structure:
module.exports = {
plugins: [],
context: {},
defaults: {}
}
The following sections will walk you through all capabilities of .pxi modules.
If you want to skip over the details and instead see sample code, visit pxi-pxi!
Writing Plugins
You may write pixie plugins in ~/.pxi/index.js.
Writing your own extensions is straightforward:
const sampleChunker = {
name: 'sample',
desc: 'is a sample chunker.',
func: ({verbose}) => (data, prevLines, noMoreData) => (
// * Turn data into an array of chunks
// * Count lines for better error reporting throughout pxi
// * Collect error reports: {msg: String, line: Number, info: String}
// If verbose > 0, include line in error reports
// If verbose > 1, include info in error reports
// * Return errors, chunks, lines, the last line, and all unchunked data
{err: [], chunks: [], lines: [], lastLine: 0, rest: ''}
)
}
const sampleDeserializer = {
name: 'sample',
desc: 'is a sample deserializer.',
func: ({verbose}) => (chunks, lines) => (
// * Deserialize chunks to jsons
// * Collect error reports: {msg: String, line: Number, info: Chunk}
// If verbose > 0, include line in error reports
// If verbose > 1, include info in error reports
// * Return errors and deserialized jsons
{err: [], jsons: []}
)
}
const sampleApplier = {
name: 'sample',
desc: 'is a sample applier.',
func: (functions, {verbose}) => (jsons, lines) => (
// * Turn jsons into other jsons by applying all functions
// * Collect error reports: {msg: String, line: Number, info: Json}
// If verbose > 0, include line in error reports
// If verbose > 1, include info in error reports
// * Return errors and serialized string
{err: [], jsons: []}
)
}
const sampleSerializer = {
name: 'sample',
desc: 'is a sample serializer.',
func: ({verbose}) => jsons => (
// * Turn jsons into a string
// * Collect error reports: {msg: String, line: Number, info: Json}
// If verbose > 0, include line in error reports
// If verbose > 1, include info in error reports
// * Return errors and serialized string
{err: [], str: ''}
)
}
The name is used by pixie to select your extension,
the desc is displayed in the options section of pxi --help, and
the func is called by pixie to transform data.
The sample extensions are bundled to the sample plugin, as follows:
const sample = {
chunkers: [sampleChunker],
deserializers: [sampleDeserializer],
appliers: [sampleApplier],
serializers: [sampleSerializer]
}
Extending Pixie with Plugins
Plugins can come from two sources:
They are either written by the user, as shown in the previous section, or they are installed in ~/.pxi/ as follows:
$ npm install pxi-sample
If a plugin was installed, it has to be imported into ~/.pxi/index.js:
const sample = require('pxi-sample')
Regardless of whether a plugin was defined by a user or installed from npm,
all plugins are added to the .pxi module the same way:
module.exports = {
plugins: [sample],
context: {},
defaults: {}
}
pxi --help should now list the sample plugin extensions in the options section.
🙊 Adding plugins may break the
pxicommand line tool! If this happens, just remove the plugin from the list andpxishould work normal again. Use this feature responsibly.
Including Libraries like Ramda or Lodash
Libraries like Ramda and Lodash are of immense help when writing functions to transform JSON objects and many heated discussions have been had, which of these libraries is superior. Since different people have different preferences, pixie lets the user decide which library to use.
First, install your preferred libraries in ~/.pxi/:
$ npm install ramda
$ npm install lodash
Next, add the libraries to ~/.pxi/index.js:
const R = require('ramda')
const L = require('lodash')
module.exports = {
plugins: [],
context: Object.assign({}, R, {_: L}),
defaults: {}
}
You may now use all Ramda functions without prefix, and all Lodash functions with prefix _:
$ pxi "prop('time')" < 2019.jsonl
$ pxi "json => _.get(json, 'time')" < 2019.jsonl
🙉 Using Ramda and Lodash in your functions may have a negative impact on performance! Use this feature responsibly.
Including Custom JavaScript Functions
Just as you may extend pixie with third-party libraries like Ramda and Lodash,
you may add your own functions.
This is as simple as adding them to the context in ~/.pxi/index.js:
const getTime = json => json.time
module.exports = {
plugins: [],
context: {getTime},
defaults: {}
}
After adding it to the context, you may use your function:
$ pxi "json => getTime(json)" < 2019.jsonl
$ pxi "getTime" < 2019.jsonl
Changing pxi Defaults
You may globally change default chunkers, deserializers, appliers, and serializers in ~/.pxi/index.js, as follows:
module.exports = {
plugins: [],
context: {},
defaults: {
chunker: 'sample',
deserializer: 'sample',
appliers: 'sample',
serializer: 'sample',
noPlugins: false
}
}
🙈 Defaults are assigned globally and changing them may break existing
pxiscripts! Use this feature responsibly.
id Plugin
pxi includes the id plugin that comes with the following extensions:
| Description | |
|---|---|
id chunker |
Returns each data as a chunk. |
id deserializer |
Returns all chunks unchanged. |
id applier |
Does not apply any functions and returns the JSON objects unchanged. |
id serializer |
Applies Object.prototype.toString to the input and joins without newlines. |
Comparison to Related Tools
pxi |
jq |
mlr |
fx |
gawk |
|
|---|---|---|---|---|---|
| Self-description | Small, fast, and magical command-line data processor similar to awk, jq, and mlr. | Command-line JSON processor | Miller is like awk, sed, cut, join, and sort for name-indexed data such as CSV, TSV, and tabular JSON | Command-line tool and terminal JSON viewer | The awk utility interprets a special-purpose programming language that makes it possible to handle simple data-reformatting jobs with just a few lines of code |
| Focus | Transforming data with user provided functions and converting between formats | Transforming JSON with user provided functions | Transforming CSV with user provided functions and converting between formats | Transforming JSON with user provided functions | Language for simple data reformatting tasks |
| License | MIT | MIT | BSD-3-Clause | MIT | GPL-3.0-only |
| Performance | (performance is given relative to pxi) |
jq is >3x slower than pxi
|
mlr is >3x slower than pxi
|
fx is >15x slower than pxi
|
pxi is as performant as gawk when processing JSON and CSV |
| Processing Language | JavaScript and all JavaScript libraries | jq language | Predefined verbs and custom put/filter DSL | JavaScript and all JavaScript libraries | awk language |
| Extensibility | (Third-party) Plugins, any JavaScript library, custom functions | (Third-party) Modules written in jq | Running arbitrary shell commands | Any JavaScript library, custom functions | gawk dynamic extensions |
| Similarities |
pxi and jq both heavily rely on JSON |
pxi and mlr both convert back and forth between CSV and JSON |
pxi and fx both apply JavaScript functions to JSON streams |
pxi and gawk both transform data |
|
| Differences |
pxi and jq use different processing languages |
While pxi uses a programming language for data processing, mlr uses a custom put/filter DSL, also, mlr reads in the whole file while pxi processes it in chunks |
pxi supports data formats other than JSON, and fx provides a terminal JSON viewer |
While pxi functions transform a JSON into another JSON, gawk does not have a strict format other than transforming strings into other strings |
Reporting Issues
Please report issues in the tracker!
Contributing
We are open to, and grateful for, any contributions made by the community. By contributing to pixie, you agree to abide by the code of conduct. Please read the contributing guide.
License
pxi is MIT licensed.