my8100 / Scrapyd Cluster On Heroku
Licence: gpl-3.0
Set up free and scalable Scrapyd cluster for distributed web-crawling with just a few clicks. DEMO 👉
Stars: ✭ 106
Programming Languages
python
139335 projects - #7 most used programming language
Projects that are alternatives of or similar to Scrapyd Cluster On Heroku
Scrapy Training
Scrapy Training companion code
Stars: ✭ 157 (+48.11%)
Mutual labels: scrapy, web-scraping
IMDB-Scraper
Scrapy project for scraping data from IMDB with Movie Dataset including 58,623 movies' data.
Stars: ✭ 37 (-65.09%)
Mutual labels: web-scraping, scrapy
City Scrapers
Scrape, standardize and share public meetings from local government websites
Stars: ✭ 220 (+107.55%)
Mutual labels: scrapy, web-scraping
scrapy-wayback-machine
A Scrapy middleware for scraping time series data from Archive.org's Wayback Machine.
Stars: ✭ 92 (-13.21%)
Mutual labels: web-scraping, scrapy
Scrapple
A framework for creating semi-automatic web content extractors
Stars: ✭ 464 (+337.74%)
Mutual labels: scrapy, web-scraping
Netflix Clone
Netflix like full-stack application with SPA client and backend implemented in service oriented architecture
Stars: ✭ 156 (+47.17%)
Mutual labels: scrapy, web-scraping
OLX Scraper
📻 An OLX Scraper using Scrapy + MongoDB. It Scrapes recent ads posted regarding requested product and dumps to NOSQL MONGODB.
Stars: ✭ 15 (-85.85%)
Mutual labels: web-scraping, scrapy
Juno crawler
Scrapy crawler to collect data on the back catalog of songs listed for sale.
Stars: ✭ 150 (+41.51%)
Mutual labels: scrapy, web-scraping
awake-action
Keep your free servers, clusters, dynos awaken (ex: heroku, mongodb, etc.)
Stars: ✭ 152 (+43.4%)
Mutual labels: heroku, cluster
restaurant-finder-featureReviews
Build a Flask web application to help users retrieve key restaurant information and feature-based reviews (generated by applying market-basket model – Apriori algorithm and NLP on user reviews).
Stars: ✭ 21 (-80.19%)
Mutual labels: web-scraping, scrapy
scraping-ebay
Scraping Ebay's products using Scrapy Web Crawling Framework
Stars: ✭ 79 (-25.47%)
Mutual labels: web-scraping, scrapy
Faster Than Requests
Faster requests on Python 3
Stars: ✭ 639 (+502.83%)
Mutual labels: scrapy, web-scraping
Scrapy Fake Useragent
Random User-Agent middleware based on fake-useragent
Stars: ✭ 520 (+390.57%)
Mutual labels: scrapy, web-scraping
Scrapy Craigslist
Web Scraping Craigslist's Engineering Jobs in NY with Scrapy
Stars: ✭ 54 (-49.06%)
Mutual labels: scrapy, web-scraping
Teleport
Certificate authority and access plane for SSH, Kubernetes, web apps, databases and desktops
Stars: ✭ 10,602 (+9901.89%)
Mutual labels: cluster
Yoke
Postgres high-availability cluster with auto-failover and automated cluster recovery.
Stars: ✭ 1,360 (+1183.02%)
Mutual labels: cluster
Reddit Bot
🤖 Making a Reddit Bot using Python, Heroku and Heroku Postgres.
Stars: ✭ 99 (-6.6%)
Mutual labels: heroku
Rod
A Devtools driver for web automation and scraping
Stars: ✭ 1,392 (+1213.21%)
Mutual labels: web-scraping
Pulsar
Turn large Web sites into tables and charts using simple SQLs.
Stars: ✭ 100 (-5.66%)
Mutual labels: web-scraping
🔤 English | 🀄️ 简体中文
How to set up Scrapyd cluster on Heroku
Demo
Network topology
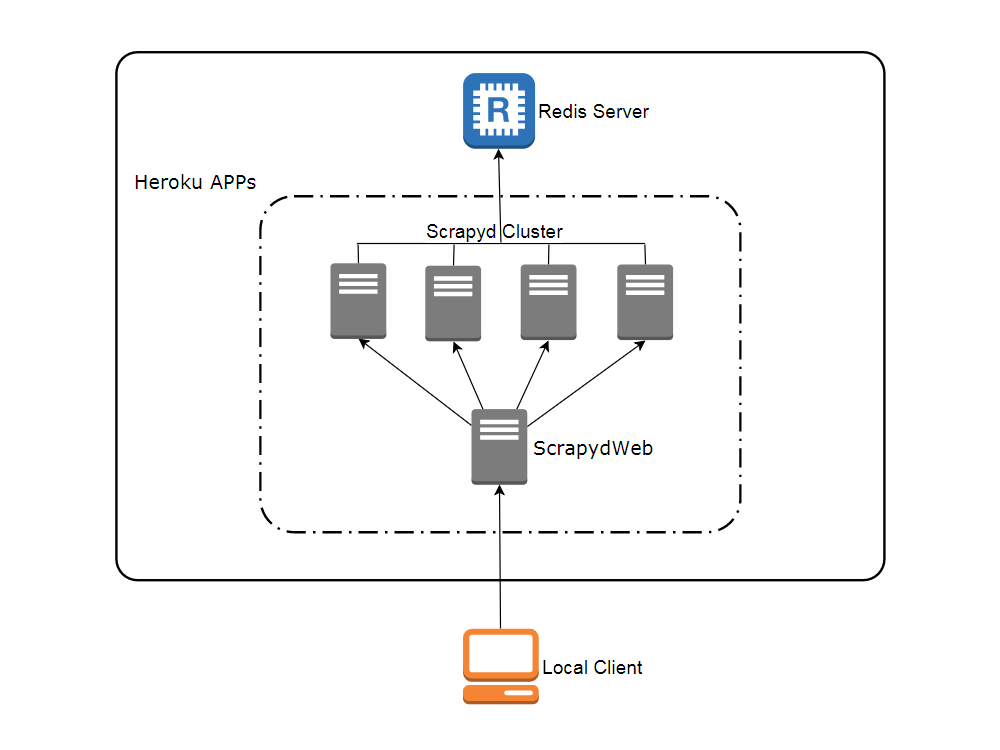
Create accounts
View contents
- Heroku
Visit heroku.com to create a free account, with which you can create and run up to 5 apps.
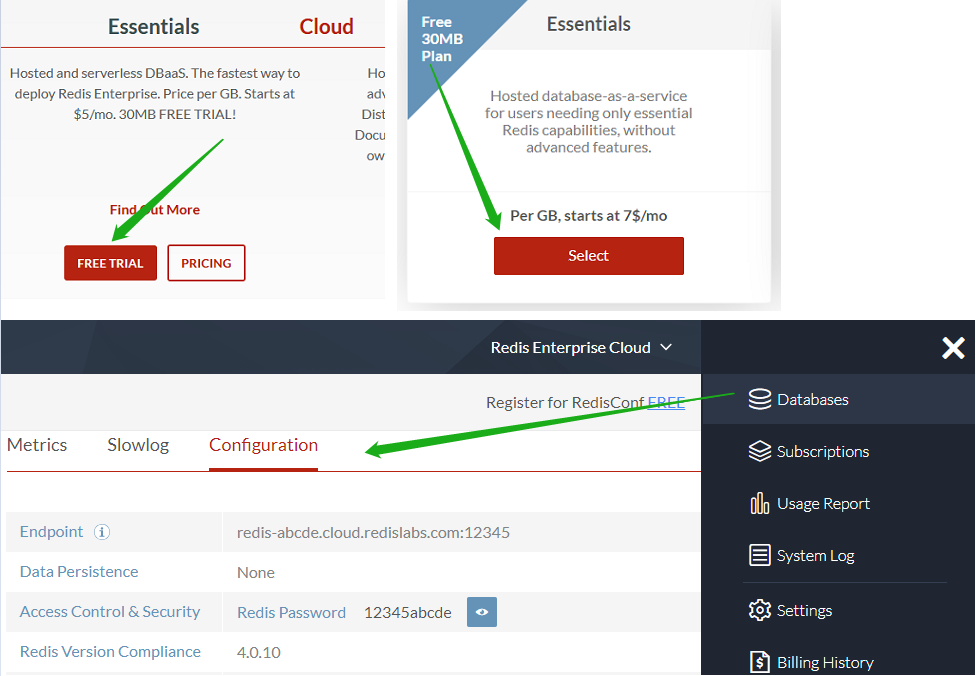
- Redis Labs (optional)
Visit redislabs.com to create a free account, which provides 30MB storage and can be used by scrapy-redis for distributed crawling.
Deploy Heroku apps in the browser
View contents
- Visit my8100/scrapyd-cluster-on-heroku-scrapyd-app to deploy the Scrapyd app. (Don't forget to update the host, port and password of your Redis server in the form)
- Repeat step 1 to deploy up to 4 Scrapyd apps, assuming theri names are
svr-1,svr-2,svr-3andsvr-4 - Visit my8100/scrapyd-cluster-on-heroku-scrapydweb-app-git to deploy the ScrapydWeb app named
myscrapydweb - (optional) Click the Reveal Config Vars button on dashboard.heroku.com/apps/myscrapydweb/settings to add more Scrapyd server accordingly, e.g.
SCRAPYD_SERVER_2as the KEY andsvr-2.herokuapp.com:80#group2as the VALUE. - Visit myscrapydweb.herokuapp.com
- Jump to the Deploy and run distributed spiders section below and move on.
Custom deployment
View contents
Install tools
- Git
- Heroku CLI
-
Python client for Redis: Simply run the
pip install rediscommand.
Download config files
Open a new terminal:
git clone https://github.com/my8100/scrapyd-cluster-on-heroku
cd scrapyd-cluster-on-heroku
Log in to Heroku
# Or run 'heroku login -i' to login with username/password
heroku login
# outputs:
# heroku: Press any key to open up the browser to login or q to exit:
# Opening browser to https://cli-auth.heroku.com/auth/browser/12345-abcde
# Logging in... done
# Logged in as [email protected]
Set up Scrapyd cluster
- New Git repo
cd scrapyd
git init
# explore and update the files if needed
git status
git add .
git commit -a -m "first commit"
git status
- Deploy Scrapyd app
heroku apps:create svr-1
heroku git:remote -a svr-1
git remote -v
git push heroku master
heroku logs --tail
# Press ctrl+c to stop logs outputting
# Visit https://svr-1.herokuapp.com
-
Add environment variables
- Timezone
# python -c "import tzlocal; print(tzlocal.get_localzone())" heroku config:set TZ=US/Eastern # heroku config:get TZ- Redis account (optional, see settings.py in the scrapy_redis_demo_project.zip)
heroku config:set REDIS_HOST=your-redis-host heroku config:set REDIS_PORT=your-redis-port heroku config:set REDIS_PASSWORD=your-redis-password -
Repeat step 2 and step 3 to get the rest Scrapyd apps ready:
svr-2,svr-3andsvr-4
Set up ScrapydWeb app
- New Git repo
cd ..
cd scrapydweb
git init
# explore and update the files if needed
git status
git add .
git commit -a -m "first commit"
git status
- Deploy ScrapydWeb app
heroku apps:create myscrapydweb
heroku git:remote -a myscrapydweb
git remote -v
git push heroku master
-
Add environment variables
- Timezone
heroku config:set TZ=US/Eastern- Scrapyd servers (see scrapydweb_settings_vN.py in the scrapydweb directory)
heroku config:set SCRAPYD_SERVER_1=svr-1.herokuapp.com:80 heroku config:set SCRAPYD_SERVER_2=svr-2.herokuapp.com:80#group1 heroku config:set SCRAPYD_SERVER_3=svr-3.herokuapp.com:80#group1 heroku config:set SCRAPYD_SERVER_4=svr-4.herokuapp.com:80#group2
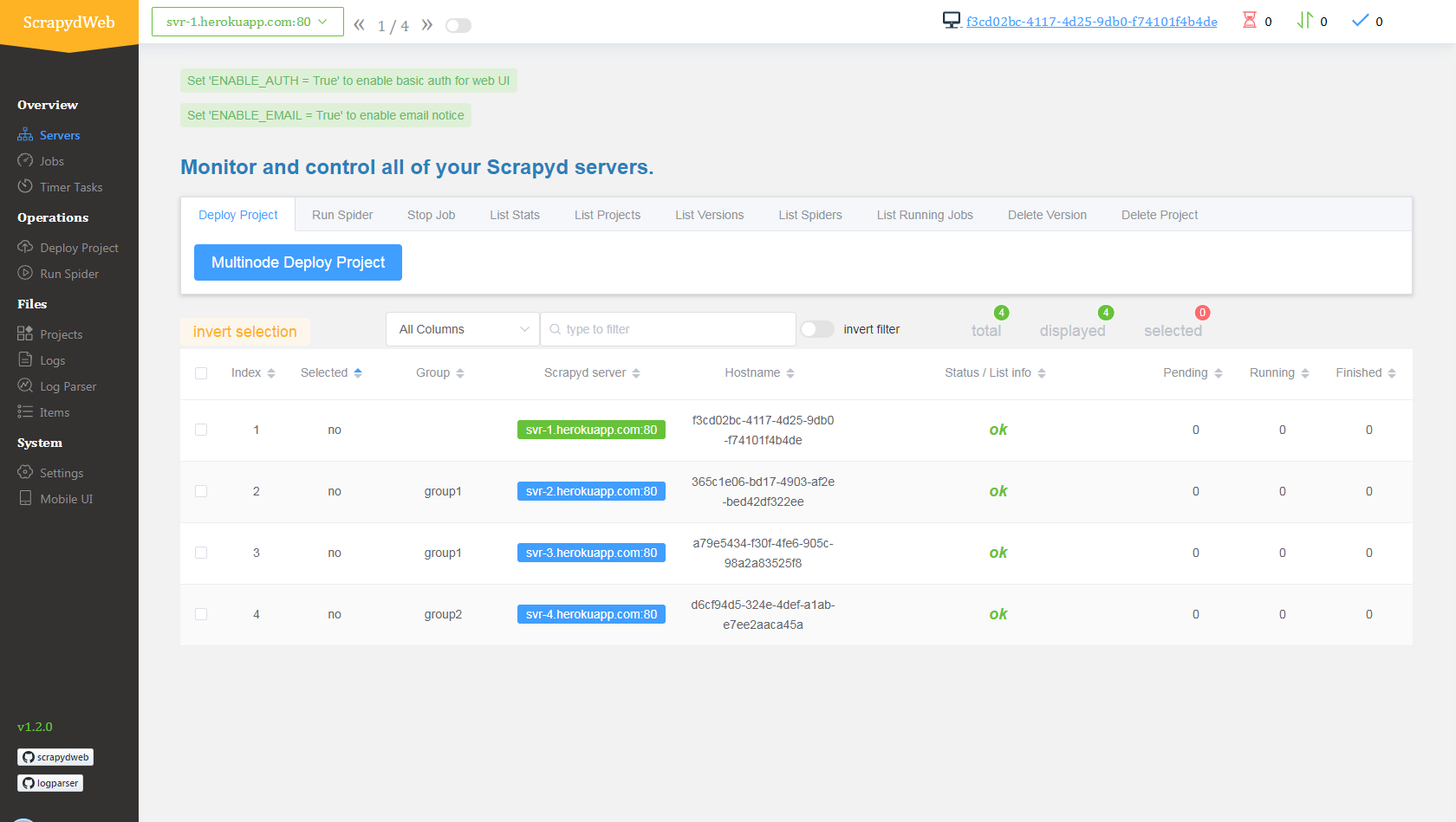
Deploy and run distributed spiders
View contents
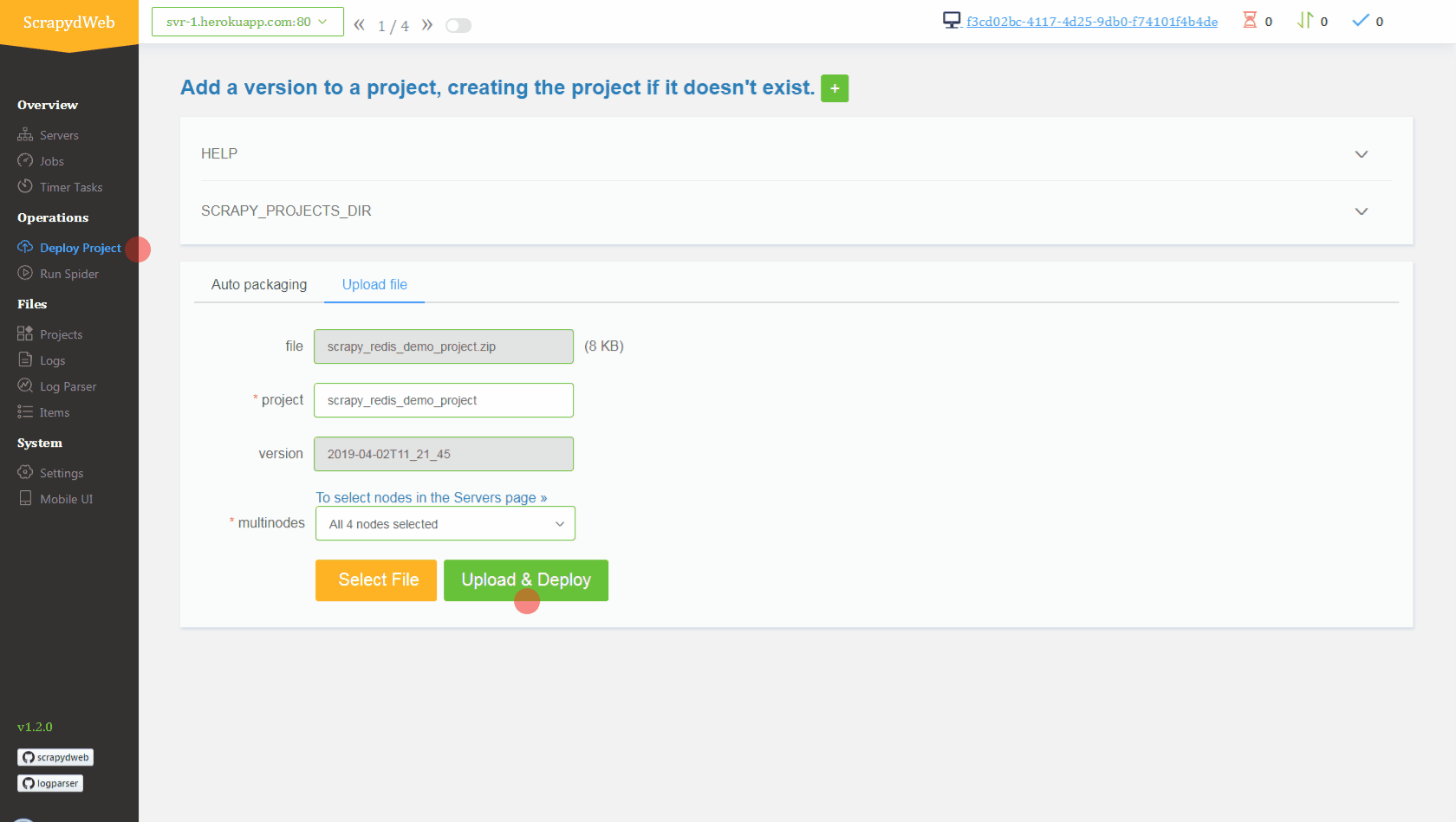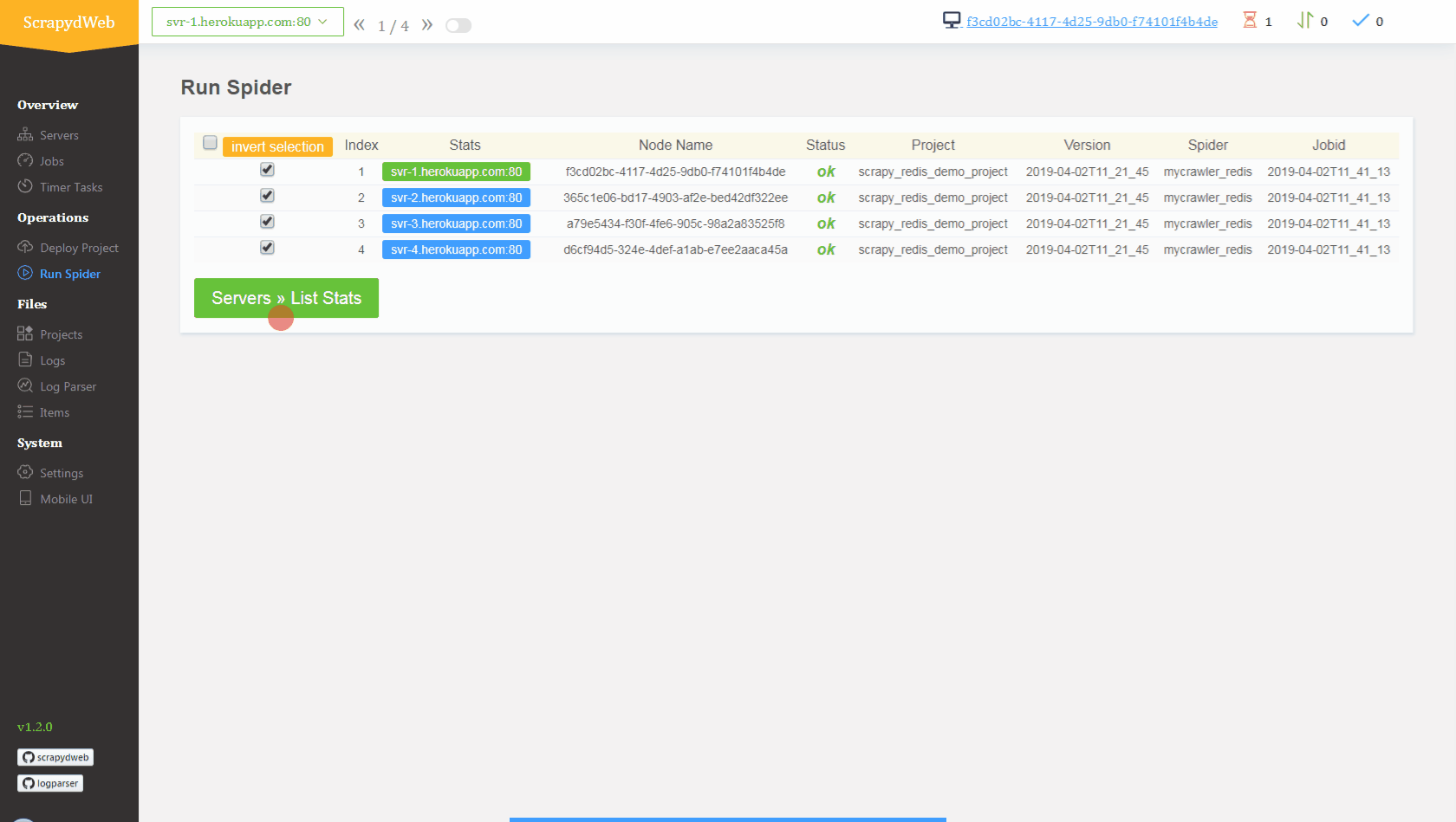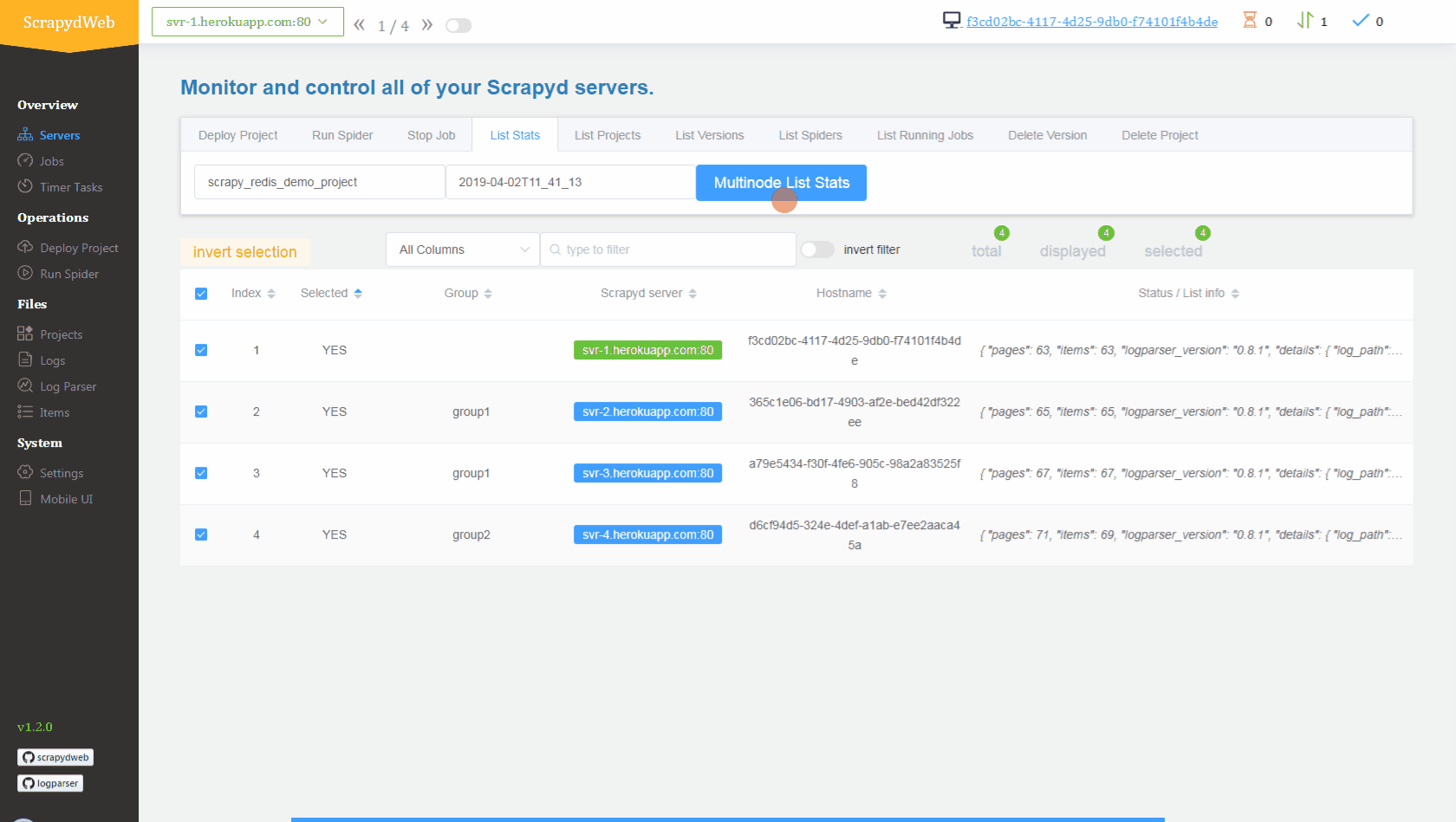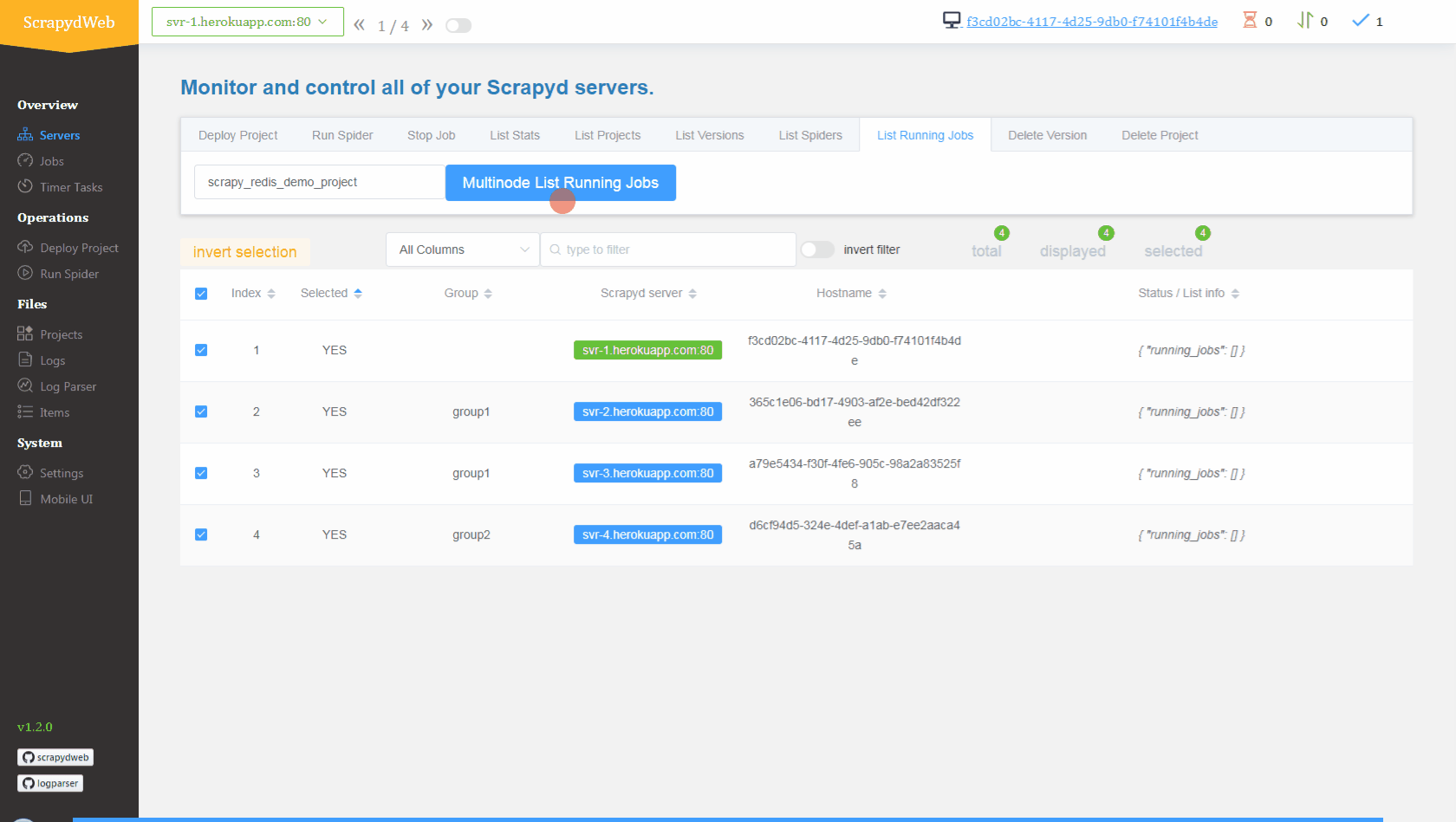
- Simply upload the compressed file scrapy_redis_demo_project.zip which resides in the scrapyd-cluster-on-heroku directory
- Push seed URLs into
mycrawler:start_urlsto fire crawling and check out the scraped items
In [1]: import redis # pip install redis
In [2]: r = redis.Redis(host='your-redis-host', port=your-redis-port, password='your-redis-password')
In [3]: r.delete('mycrawler_redis:requests', 'mycrawler_redis:dupefilter', 'mycrawler_redis:items')
Out[3]: 0
In [4]: r.lpush('mycrawler:start_urls', 'http://books.toscrape.com', 'http://quotes.toscrape.com')
Out[4]: 2
# wait for a minute
In [5]: r.lrange('mycrawler_redis:items', 0, 1)
Out[5]:
[b'{"url": "http://quotes.toscrape.com/", "title": "Quotes to Scrape", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}',
b'{"url": "http://books.toscrape.com/index.html", "title": "All products | Books to Scrape - Sandbox", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}']
Conclusion
View contents
- Pros
- Free
- Scalable (with the help of ScrapydWeb)
- Cons
- Heroku apps would be restarted (cycled) at least once per day and any changes to the local filesystem will be deleted, so you need the external database to persist data. Check out devcenter.heroku.com for more info.
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].