goruck / Smart Zoneminder
Programming Languages
Labels
Projects that are alternatives of or similar to Smart Zoneminder
smart-zoneminder
smart-zoneminder enables fast and accurate object detection, face recognition and upload of ZoneMinder alarm images to an S3 archive where they are made accessible by voice via Alexa.
The use of object detection remotely via Rekognition or locally via a TensorFlow-based CNN dramatically reduces the number of false alarms and provides for robust scene and object detection. Face recognition via ageitgey's Python API to dlib can be used to identify people detected in the alarm images, alternatively people can be recognized by another TensorFlow-based CNN. Alexa allows a user to ask to see an image or a video corresponding to an alarm and to get information on what caused the alarm and when it occurred.
The local processing of the machine learning workloads employed by this project can be configured to run on GPU or TPU hardware.
smart-zoneminder in its default configuration stores about three weeks of continuous video at the edge and one year of alarm images in the cloud. It costs as little as $8 per year per camera to operate.
Table of Contents
- Usage Examples
- Project Requirements
- System Architecture
- Edge Setup and Configuration
- Cloud Setup and Configuration
- Results
- License
- Contact
- Acknowledgements
- Appendix
Usage Examples
Here are a few of the things you can do with smart-zoneminder.
Note that in all the examples below if the user makes the request to an Alexa device without a screen then the skill will make an attempt to verbalize the response to the user as clearly as possible.
Ask Alexa to show the last alarm from a camera due to a person or thing
General form:
"Alexa, ask zone minder to show {Location} alarm of {PersonOrThing}"
If the user does not provide a location then the most recent alarm will be shown from any camera and if a specific person or thing is not given then an alarm caused by any person will be shown. Location can be any camera name defined in the configuration and PersonOrThing can be the name of any person defined in the configuration, 'stranger' for any person not defined or any label given in the COCO dataset. The user can see a video corresponding to the alarm by asking Alexa to "show video clip."
Specific example 1:
User: "Alexa, ask zone minder to show front porch alarm"
Alexa: "Showing last alarm from front porch camera on 2018-10-30 18:25"

Specific example 2:
User: "Alexa ask zone minder for back garage alarm of stranger"
Alexa: "Alarm from back garage caused by stranger on 2018-10-29 13:10"

Ask Alexa to show alarms from a camera due to a person or thing starting from some time ago
General form:
"Alexa, ask zone minder to show {Location} alarms of {PersonOrThing} from {SomeTimeAgo} ago"
If the user does not provide a location then the last alarm will be shown from all cameras (this can also be triggered by simply asking Alexa to "show all"). If a specific person or thing is not given then an alarm caused by any person will be shown. Location can be any camera name defined in the configuration and PersonOrThing can be the name of any person defined in the configuration, 'stranger' for any person not defined or any label given in the COCO dataset. If a duration was not given by {SomeTimeAgo} then the last alarms will be shown starting from three days ago. In all cases the number of alarms shown will not exceed 64 on the screen due to an Alexa service limitation. The user can scroll though the alarms by either touch or voice and can see a video clip corresponding to the alarm by asking Alexa to "show video clip".
Specific example 1:
User: "Alexa, ask zone minder to show front porch alarms"
Alexa: "Showing oldest alarms first from front porch camera"

Specific example 2:
User: "Alexa, ask zone minder to show alarms of Lindo"
Alexa: "Showing latest alarms from all cameras caused by Lindo"

Specific example 3:
User: "Alexa, ask zone minder to show backyard alarms of Polly"
Alexa: "Showing oldest alarms first from backyard for Polly"

Ask Alexa to play a video of a last alarm from a camera
Note: smart-zoneminder currently does not support live streaming of camera feeds. I recommend that you use alexa-ip-cam for streaming your cameras feeds live on Echo devices.
General form:
"Alexa, show {Location} video clip"
If the user does not provide a camera location then the last video clip of any alarm will be displayed.
Specific example:
User: "Alexa, ask zone minder to show front porch video clip"
Alexa: "Showing most recent video clip from front porch alarm."
Result: Video of last alarm clip from this camera will play on an Echo device with a screen.
Ask Alexa a series of commands to view alarms and videos
The skill can handle series commands that, for example, allow the user to view an alarm and then view a video clip containing that alarm. Here are some videos of these examples.
Specific example 1:
User commands: (1) Ask Alexa to show all events; (2) view a particular alarm; (3) view a video containing that alarm; (4) go back and select another alarm.
Click on image below to see video of Alexa response:
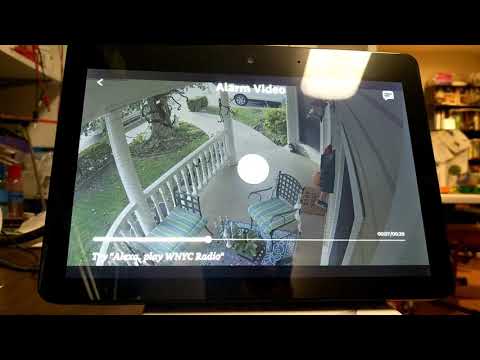
Specific example 2:
User commands: (1) Ask Alexa to show last alarm; (2) show last alarm from back garage; (3) show a video clip of that alarm.
Click on image below to see video of Alexa response:
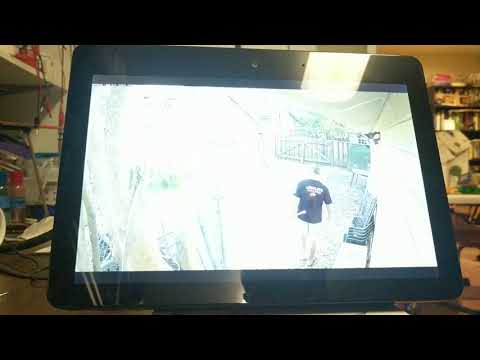
Specific example 3:
User commands: (1) Ask Alexa to show front porch alarms of Lindo; (2) scroll to find an alarm; (3) select an alarm; (4) view video clip of alarm; (5) go back to list of alarms; (6) select another alarm; (7) view video clip of alarm; (8) go back; (9) select another alarm; (10) view video clip of alarm; (11) exit.
Click on image below to see video of Alexa response:

Send Emails of Alarms
smart-zoneminder can email alarms based on the face detected in the image. Below are examples of alarm emails sent to a mobile device with filter criterion set to any of my family members.


Alexa Notifications
As soon as the Alexa Skills Kit supports notifications they will be added.
Project Requirements
My high level goals and associated requirements for this project are shown below.
-
Quickly archive Zoneminder alarm frames to the cloud in order to safeguard against malicious removal of on-site server. This lead to the requirement of a ten second or less upload time to a secure AWS S3 bucket. Although ZoneMinder has a built-in ftp-based filter it was sub-optimal for this application as explained below.
-
Significantly reduce false positives from ZoneMinder's pixel-based motion detection. This lead to the requirement to use a higher-level object and person detection algorithm based on Amazon Rekognition remotely or TensorFlow locally (this is configurable).
-
Determine if a person detected in an Alarm image is familiar or not. This lead to the requirement to perform real-time face recognition on people detected in ZoneMinder images.
-
Make it easy and intuitive to access ZoneMinder information. This lead to the requirement to use voice to interact with ZoneMinder, implemented by an Amazon Alexa Skill. This includes proactive notifications, e.g., the Alexa service telling you that an alarm has occurred and why. For example, when an unknown person was seen by a camera or when a known person was seen. Another example is time-, object- and person-based voice search.
-
Have low implementation and operating costs. This lead to the requirement to leverage existing components where possible and make economical use of the AWS services. This also led to the option of using local TensorFlow based object detection since using Rekognition at scale is not inexpensive wrt the goals of this project. An operating cost of less than $10 per year is the goal.
-
Be competitive with smart camera systems out in the market from Nest, Amazon, and others that use image recognition and Alexa.
-
Learn about, and show others how to use, TensorFlow, Face Recognition, ZoneMinder, Alexa, AWS and leveraging both edge and cloud compute.
System Architecture
The figure below shows the smart-zoneminder system architecture.

The figure below shows a high-level view of the edge compute architecure.

Image Processing Pipeline
The figure below shows the smart-zoneminder image processing pipeline.

Edge Setup and Configuration
A Linux server and a Google Coral Dev Board are the hardware used for local compute and storage in this project. Object and face/person recognition can be run on either the server or the Coral dev board. See tpu-servers for installation and configuration instructions associated with the Google Coral dev board software components. Some details regarding the server hardware used in this project can be found in the appendix. The rest of this section describes the Linux server components and how to install and configure them.
ZoneMinder
You need to have ZoneMinder installed on a local linux machine to use smart-zoneminder. I'm using version 1.30.4 which is installed on machine running Ubuntu 18.04. I followed Ubuntu Server 18.04 64-bit with Zoneminder 1.30.4 the easy way to install ZoneMinder.
I have the monitor function set to Mocord which means that the camera streams will be continuously recorded, with motion being marked as an alarm within an event (which is a 600 second block of continuously recorded video). ZoneMinder stores the camera streams as JPEGs for each video frame in the event. I chose this mode because I wanted to have a record of all the video as well as the alarms. ZoneMinder does provide for a means ("filters") to upload an event to an external server when certain conditions are met, such as an alarm occurring. Its possible to use such a filter instead of the uploader I created but I didn't want to upload 600 s worth of images every time an alarm occurred and the filter would have been slow, worse case being almost 600 s if an alarm happened at the start of an event.
Its very important to configure ZoneMinder's motion detection properly to limit the number of false positives in order to minimize cloud costs, most critically AWS Rekognition. Even though the Rekognition Image API has a free tier that allows 5,000 images per month to be analyzed its very easy for a single camera to see many thousands of alarm frames per month in a high traffic area and every alarm frame is a JPEG that is sent to the cloud to be processed via the Rekognition Image API. There are many guides on the Internet to help configure ZoneMinder motion detection. I found Understanding ZoneMinder's Zoning system for Dummies to be very useful but it takes some trial and error to get it right given each situation is so different. Zoneminder is configured to analyze the feeds for motion at 5 FPS which also helps to limit Rekognition costs but it comes at the expense of possibly missing a high speed object moving through the camera's FOV (however unlikely in my situation). Since I was still concerned about Rekognition costs I also included the option to run local TensorFlow-based object detection instead. This comes at the expense of slightly higher detection times (with my current HW which uses a Nvidia Geforce GTX 1080Ti GPU for TensorFlow) but completely avoids Rekogntion costs.
If set to use remote object detection via Rekognition smart-zoneminder can be configured to either send all or some alarm frames (as specified by the frameSkip parameter in the uploader's config file) detected by ZoneMinder's motion detector to the cloud. This is expensive. Clearly there are more optimal ways to process the alarms locally in terms of more advanced motion detection algorithms and exploiting the temporal coherence between alarm frames that would limit cloud costs without some of the current restrictions. This is an area for future study by the project.
I have seven 1080p PoE cameras being served by my ZoneMinder setup. The cameras are sending MJPEG over RTSP to ZoneMinder at 5 FPS. I've configured the cameras' shutter to minimize motion blur at the expense of noise in low light situations since I found Rekognition's accuracy is more affected by the former. The object detection in TensorFlow seems more robust in this regard.
Some of the components interface with ZoneMinder's MySql database and image store and make assumptions about where those are in the filesystem. I've tried to pull these dependencies out into configuration files where feasible but if you heavily customize ZoneMinder its likely some path in the component code will need to be modified that's not in a configuration file.
TensorFlow
This project uses TensorFlow (with GPU support) for local object detection. I followed Installing TensorFlow on Ubuntu as a guide to install it on my local machine and I used a Python Virtual environment. After I installed TensorFlow I installed the object detection API using Step by Step TensorFlow Object Detection API Tutorial and this as guides. I'm currently using the rfcn_resnet101_coco model which can be found in the TensorFlow detection model zoo. See the Appendix for model benchmarking and selection.
dlib, face_recognition, scikit-learn and OpenCV
ageitgey's face_recognition API is used for face detection and for knn-based recognition. I followed the linux installation guide to install the API and dlib with GPU support on my local machine in a Python virtual environment. scikit-learn is used to train an SVM for more robust face recognition from the face encodings generated by dlib. I installed scikit-learn via pip per these instructions. OpenCV is used to preprocess the image for face recognition, I used OpenCV 3 Tutorials, Resources, and Guides to install OpenCV 3.4.2 with GPU support on my local machine. A high-level overview of how the face recognition works can be found here and here.
Apache
If you installed ZoneMinder successfully then apache should be up and running but a few modifications are required for this project. The Alexa VideoApp Interface that is used to display clips of alarm videos requires the video file to be hosted at an Internet-accessible HTTPS endpoint. HTTPS is required, and the domain hosting the files must present a valid, trusted SSL certificate. Self-signed certificates cannot be used. Since the video clip is generated on the local server Apache needs to serve the video file in this manner. This means that you need to setup a HTTPS virtual host with a publicly accessible directory on your local machine. Note that you can also leverage this to access the ZoneMinder web interface in a secure manner externally. Here are the steps I followed to configure Apache to use HTTPS and serve the alarm video clip.
- Get a hostname via a DDNS or DNS provider. I used noip.
- Get a SSL cert from a CA. I used Let's Encrypt and the command at my local machine
certbot -d [hostname] --rsa-key-size 4096 --manual --preferred-challenges dns certonly. It will ask you to verify domain ownership by creating a special DNS record at your provider. - Follow How To Create a SSL Certificate on Apache for Debian 8 except instead of using self-signed certs use the certs generated above.
- Create a directory to hold the generated alarm clip and make the permissions for g and o equal to rx. I created this directory at /var/www/loginto.me/public and there
toucha file called alarm-video.mp4 and give it rx permissions of u,g, and o. This will allow the generator to write a video by that name to this directory. - Configure Apache to allow the public directory to be accessed and configure Apache to allow the CGI to be used. You should allow the CGI script only to be accessed externally via HTTPS and only with a password. You can copy the configuration file in apache/smart-zoneminder.conf to your Apache config-available directory, modify it to your needs and enable it in Apache.
- Restart Apache.
- Allow external access to Apache by opening the right port on your firewall.
MongoDB
I use a local mongo database to store how every alarm frame was processed by the system. Its important to record the information locally since depending on what options are set not all alarm frames and their associated metadata will be uploaded to AWS S3. The mongo logging can be toggled on or off by a configuration setting. See How to Install MongoDB on Ubuntu 18.04 for instructions on how to install mongo on your system.
Alarm Uploader (zm-s3-upload)
The Alarm Uploader, zm-s3-upload, is a node.js application running on the local server that continually monitors ZoneMinder's database for new alarm frames images and if found either directly sends them to an S3 bucket or first runs local object detection and or face recognition on the image and marks them as having been uploaded.
There are several important configuration parameters associated with object and face recognition that are set at runtime by the values in zm-s3-upload-config.json . Local object detection is enabled by setting the runLocalObjDet flag to "true" and face recognition is enabled by setting the runFaceDetRec flag to "true". Additionally, object and face detection can be run on the Google Coral dev board instead of the server, this is configured by the objDetZerorpcPipe and faceDetZerorpcPipe settings, respectively. Note you can run any server-Coral combination of local object and face detection.
The Alarm Uploader attaches metadata to the alarm frame image such as alarm score, event ID, frame number, date, and others. The metadata is used later on by the cloud services to process the image. The Alarm Uploader will concurrently upload alarm frames to optimize overall upload time. The default value is ten concurrent uploads. Upload speed will vary depending on your Internet bandwidth, image size and other factors but typically frames will be uploaded to S3 in less than a few hundred milliseconds.
The Alarm Uploader can be configured to skip alarm frames to minimize processing time, upload bandwidth and cloud storage. This is controlled by the frameSkip parameter in the configuration json.
The Alarm Uploader is run as a Linux service using systemd.
Please see the Alarm Uploader's README for installation instructions.
Local Object Detection (obj-detect)
The Object Detection Server, obj_det_server, runs the Tensorflow object detection inference engine using Python APIs and employs zerorpc to communicate with the Alarm Uploader. One of the benefits of using zerorpc is that the object detection server can easily be run on another machine, apart from the machine running ZoneMinder. Another benefit is that the server when started will load into memory the model and initialize it, thus saving time when an inference is actually run. The server can optionally skip inferences on consecutive ZoneMinder Alarm frames to minimize processing time which obviously assumes the same object is in every frame. The Object Detection Server is run as a Linux service using systemd.
I benchmarked a few Tensorflow object detection models on the machine running smart-zoneminder in order to pick the best model in terms of performance and accuracy. See the Appendix for this analysis.
Please see the Object Detection Server's README for installation instructions.
Face Recognition (face-det-rec)
The Face Detection and Recognition Server, face_detect_server.py, runs the dlib face detection and recognition engine using Python APIs and employs zerorpc to communicate with the Alarm Uploader. One of the benefits of using zerorpc is that the object detection server can easily be run on another machine, apart from the machine running ZoneMinder (e.g. when using the tpu version of this program). Face Detection and Recognition Server is run as a Linux service using systemd.
There are a number of parameters in this module that can be adjusted to optimize face detection and recognition accuracy and attendant compute. You may need to adjust these parameters to suit your configuration. These are summarized below.
| Parameter | Default Value | Note |
|---|---|---|
| MIN_SVM_PROBA | 0.8 | Minimum probability for a valid face returned by the SVM classifier. |
| NUMBER_OF_TIMES_TO_UPSAMPLE | 1 | Factor to scale image when looking for faces. |
| FACE_DET_MODEL | cnn | Can be either 'cnn' or 'hog'. cnn works much better but uses more memory and is slower. |
| NUM_JITTERS | 100 | How many times to re-sample when calculating face encoding |
| FOCUS_MEASURE_THRESHOLD | 200 | Images with Variance of Laplacian less than this are declared blurry. |
MIN_SVM_PROBA sets the minimum probablity that will be declared a valid face from the svm-based classifier. FOCUS_MEASURE_THRESHOLD sets the threshold for a Variance of Laplacian measurement of the image, if below this threshold the image is declared to be too blurry for face recognition to take place.
Please see the Face Recognition's README for installation instructions.
Person Classification (person-class)
The Person Classification Server, person_classifier_server.py, runs a TensorFlow deep convolutional neural network (CNN)-based person classifier using Python APIs and employees zerorpc to communicate with the Alarm Uploader. One of the benefits of using zerorpc is that the server can easily be run on another machine, apart from the machine running ZoneMinder. The Person Classification Server is run as a Linux service using systemd.
This server uses a fine-tuned CNN to classify that a person object detected by obj-detect is member of my family or a stranger. It is an alternative to face-det-rec and so one or the other must be run but not both.
Note that face-det-rec includes shallow learning methods (SVM or XGBoost classifiers) in the final stage of a pipeline to recognize faces in alarm images. CNNs have been shown to outperform shallow learning methods for many computer vision tasks given sufficient training data; this was the main motivation for developing person-class.
Please see the Person Classification Server's README for installation instructions.
Alarm Clip Generator (gen-vid)
The Alarm Clip Generator, gen-vid, is a python script run in Apache's CGI on the local server that generates an MP4 video of an alarm event given its Event ID, starting Frame ID and ending Frame ID. The script is initiated via the CGI by the Alexa skill handler and the resulting video is played back on an Echo device with a screen upon a user's request.
ZoneMinder does offer a streaming video API that can be used to view the event with the alarm frames via a web browser. However the Alexa VideoApp Interface that's used to playback the alarm clip requires very specific formats which are not supported by the ZoneMinder streaming API. Additionally I wanted to show only the alarm frames and not the entire event which also isn't supported by the Zoneminder API. Also its possible to create the video clip completely on the cloud from the alarm images stored in DynamoDB, however gaps would likely exist in videos created this way because there's no guarantee that ZoneMinder's motion detection would pick up all frames. So I decided to create gen-vid but it does come at the expense of complexity and user perceived latency since a long alarm clip takes some time to generate on my local machine. I'll be working to reduce this latency.
Please see the Alarm Clip Generator's README for installation instructions. Apache must be setup to enable the CGI, see above.
Cloud Setup and Configuration
The sections below describe the cloud-side components and how to install and configure them. You'll need an Amazon Developers account to use the Alexa skills I developed for this project since I haven't published them. You'll also need an Amazon AWS account to run the skill's handler, the other lambda functions required for this project and DynamoDB and S3.
DynamoDB
smart-zoneminder uses a DynamoDB table to store information about the alarm frame images uploaded to S3. This table needs to be created either through the AWS cli or the console. Here's how to do it via the console.
-
Open the DynamoDB console at https://console.aws.amazon.com/dynamodb/. Make sure you are using the AWS Region that you will later create smart-zoneminder's lambda functions.
-
Choose Create Table.
-
In the Create DynamoDB table screen, do the following:
- In the Table name field, type ZmAlarmFrames.
- For the Primary key, in the Partition key field, type ZmCameraName. Set the data type to String.
- Choose Add sort key.
- In the Sort Key field type ZmEventDateTime. Set the data type to String.
When the settings are as you want them, choose Create.
S3
You'll need an S3 bucket where your images can be uploaded for processing and archived. You can create the bucket either through the AWS cli or the console, here's how to do it via the console.
Thanks to Paul Branston for great suggestions to set secure S3 permissions. Also see this blog for additional related information.
- Sign in to the AWS Management Console and open the Amazon S3 console at https://console.aws.amazon.com/s3/.
- Choose Create bucket.
- In the Bucket name field type zm-alarm-frames.
- For Region, choose the region where you want the bucket to reside. This should be the same as the DynamoDB and lambda functions region.
- Choose Create.
- The bucket will need two root directories, /upload and /archive. Choose Create folder to make these.
- Directly under the /archive directory, create the /alerts and /falsepositives subdirectories, again by using choosing Create folder.
- Now you need to limit access to the bucket, so start by log into to the AWS IAM AWS console.
- Create a new user.
- Set a password for the new user. Your user will also have an AWS access and secret key created. API clients (e.g., zm-s2-upload) need to use these keys and will have the same permissions as the user would in the AWS console. Save the AWS access key and the secret key which will be used in a step below.
- Add permissions so that only this user has access to the bucket. My permissions to do that are shown below.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:ListAllMyBuckets",
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::zm-alarm-frames",
"arn:aws:s3:::zm-alarm-frames/*"
]
}
]
}
Note that the Alexa devices require a public URI for all images and videos that these devices display. You can either point the URI to the S3 bucket or to the the server on the local network containing the ZoneMinder image store. The lambda handler for the Alexa skill can be configured to point to either the S3 bucket or the local network for image access by changing the USE_LOCAL_PATH constant.
In the case of pointing the URI to the S3 bucket (USE_LOCAL_PATH = false) the Alexa skill handler will use signed s3 urls with an expiration time. This is the recommended approach.
Alternatively, you can serve the ZoneMinder event files locally (USE_LOCAL_PATH = true) and point a public URI to the files that the Alexa devices on your local network can access. The latency of this approach is slightly lower but comes at the expense of configuring the Apache server for this purpose and creates the potential for the DynamoDB database to be out of synch with the images stored locally since the database is only guaranteed to reflect the S3 store. If you want to enabled local access, follow the steps below.
- Setup a DNS entry for the Apache server's private IP address on your LAN. I used GoDaddy but any DNS host should work, just create an A record for the Apache server's IP address and give it a hostname. Putting Private IP's into public DNS is discouraged, but since this is for personal use its fine.
- Get an SSL cert and use Domain Name Validation to secure the domain. I used LetsEncrypt.
- Create a site configuration file for an Apace Virtual Host for the domain and create a Directory entry to serve the ZoneMinder event files. Here's mine.
Alias /nvr /nvr
<Directory "/nvr">
DirectoryIndex disabled
Options Indexes FollowSymLinks
AuthType None
Require all granted
</Directory>
Trigger Image Processing (s3-trigger-image-processing)
The Trigger Image Processing component (s3-trigger-image-processing) is an AWS Lambda Function that monitors the S3 bucket "upload" directory for new ZoneMinder alarm image files uploaded by the Edge Compute and triggers their processing by calling the step function. There are several AWS Lambda Functions that process the alarm frames. These are described below and are in the aws-lambda folder.
Please see the function's README for installation instructions.
State Machine and Alarm Image Processing
A state machine orchestrates calls to the AWS Lambda Functions associated with ZoneMinder alarm frame cloud processing. The State Machine is implemented by an AWS Step Function which is defined by step-smart-zoneminder.json in the aws-step-function directory. The State Machine's state transition diagram is shown below.

Please see the State Machine's README for installation instructions.
Rekognition (rekognition-image-assessment)
This in an AWS Lambda function sends images from s3 to Amazon Rekognition for object detection. Recognition returns labels associated with the object's identity and are passed to the rekognition-evaluate-labels function for further processing.
Please see the function's README for installation instructions.
Evaluate Rekognition Labels (rekognition-evaluate-labels)
This is an AWS Lambda function that evaluates whether or not the image's labels contains a person. This information is used to determine false positives (no person in image) vs true positives and is passed on to the s3-archive image function to appropriately archive the image.
Please see the function's README for installation instructions.
Archive S3 Image (s3-archive-image)
This is an AWS Lambda function that uses the evaluated Rekognition or Tensorflow object detection labels to move alarm frame images from the S3 upload folder to either the falsepositives folder (no person or object was found in the image) or the alerts folder (a person or object was found).
Please see the function's README for installation instructions.
Store DynamoDB Metadata (ddb-store-metadata)
This is an AWS Lambda function that stores metadata about the alarm frames that were archived by s3-archive-image into a DynamoDB table.
Please see the function's README for installation instructions.
Email Alarm Notifications (nodemailer-send-notification)
This is an AWS Lambda function that emails alarm frames if person in image matches a user defined face name. This is normally the last task in the state machine.
Please see the function's README for installation instructions.
Error Handler (error-handler)
This is an AWS Lambda function that deals with any error conditions generated by the Lambda functions associated with alarm frame processing.
Please see the function's README for installation instructions.
Alexa Skill
The skill.json file in the aws-ask folder defines the Alexa skill that the user interacts with to control smart-zoneminder.
Please see the README for installation instructions.
Alexa Skill Handler (alexa-smart-zoneminder)
This is an AWS Lambda function which implements the skill handler for the Alexa skill described above.
Please see the function's README for installation instructions.
Results
Results as measured against the project goals and requirements are summarized in this section.
Quickly archive Zoneminder alarm frames to the cloud in order to safeguard against malicious removal of on-site server
Requirement: ten second or less upload time to a secure AWS S3 bucket.
I define overall processing and upload time to be measured from when a camera's motion detect is triggered to when the resulting images have been uploaded to an S3 bucket. The upload time will be a function of my uplink bandwidth which is currently 11 Mbps. The default configuration is set to record 1080p frames which when decoded to jpeg result in image sizes averaging about 350 kB and ten images are uploaded concurrently. The number of concurrent uploads is controlled by the MAXCONCURRENTUPLOAD parameter in the Alarm Uploader configuration file. Upload only times are typically around 2.5 seconds for ten frames on my system.
The actual compute processing time is dominated by local object and face recognition since ZoneMinder itself does relatively little processing except for simple pixel-based motion detection and mpeg to jpeg decoding. The latter may require more cycles on systems with less compute then what I'm using or have more cameras or with higher resolution.
In addition to the upload and processing time there is a latency caused by the Alarm Uploader polling ZoneMinder's MySQL database for new images. This polling latency is set by the checkForAlarmsInterval parameter in the Alarm Uploader's configuration file and has a default value of 5 s which is a tradeoff between database activity and latency. The worse case is when a new alarm image shows up in the database immediately after its been polled. Clearly some alarms will show up in the database just before the poll which reduces the effective latency on average and some images will be false positives or won't have a face detected so this is really a worse case condition.
I evaluated and measured performance on several configurations as follows. All assume the worse case condition of no false positives, i.e., a person is detected in each image and a face is detected on each person.
-
For object detection with the rfcn_resnet101_coco network and dlib-based face recognition (this is the worse case condition tested) running on the server these processing steps together take about 2 s for ten images. In this case the total end to end time for ten images is 5 s (wcs polling latency) + 2 s (wcs object and face recognition processing time) + 2.5 s (upload time) = 9.5 s or about 1 fps.
-
For object detection with the ssd_mobilenet_v2_coco network and dlib-based face recognition running on the server these processing steps together take about 1.5 s for ten images. In this case the total end to end time for ten images is 5 s (wcs polling latency) + 1.5 s (wcs object and face recognition processing time) + 2.5 s (upload time) = 9 s or about 1.1 fps.
-
For object detection with the MobileNet SSD v2 (COCO) network as well as MobileNet SSD v2 (Faces)-based face recognition running on the Coral Dev Board these processing steps together take about 5.3 s for ten images. In this case the total end to end time for ten images is 5 s (wcs polling latency) + 5.3 s (wcs object and face recognition processing time) + 2.5 s (upload time) = 12.8 s or about 0.8 fps.
In summary the < 10 s requirement is being fulfilled in the server configuration but not when using Coral under worse case conditions.
Significantly reduce false positives from ZoneMinder's pixel-based motion detection
Requirement: use a higher-level object and person detection algorithm based on Amazon Rekognition remotely or Tensorflow locally (this is configurable).
Subjectively, object detection with any of the models tested is highly accurate and works well in most camera lighting conditions including when the camera's IR illuminators are active. My guess is that its over 99% accurate with the resnet101 model. I plan to modify the test script view-mongo-images.py to allow ground truth tagging of images to get a quantitative measure.
I'm very happy with the resnet101-based model running on the server as well as the mobilenet-based model running on the Coral system although its accuracy is noticeably lower. I plan to use retrain both these models with local images to further improve accuracy. The test script view-mongo-images.py can be used to collect the required images.
Determine if a person detected in an Alarm image is familiar or not
Requirement: perform real-time face recognition on people detected in ZoneMinder images.
Subjectively, face detection with the models tested is fairly accurate and works well in most camera lighting conditions including when the camera's IR illuminators are active. My guess is that its over 90% accurate with the dlib models and an svm face classifier. I plan to modify the test script view-mongo-images.py to allow ground truth tagging of images to get a quantitative measure.
I'm not satisfied with the current level of face recognition accuracy and improving it will be a focus of current work for the project. Face recognition on the Coral system using the "stock" models is particularly challenged, the accuracy of it is much less than with dlib which runs very slowly on the Coral system. To address some of these issues I have developed an alternative to the face recognizer, a CNN-based person classifier which is described above. This classifier can be run on either server hardware or the edge TPU.
Make it easy and intuitive to access ZoneMinder information
Requirement: Use voice to interact with ZoneMinder, implemented by an Amazon Alexa Skill.
The Alexa skill developed for this project works well although long DynamoDB queries at time can give a less than satisfying user perception of latency. I can improve this by paying for Global Search Indexes for additional keys.
Have low implementation and operating costs
Requirement: leverage existing components where possible and make economical use of the AWS services. This also led to the option of using local Tensorflow based object detection since using Rekognition at scale is not inexpensive wrt the goals of this project. An operating cost of less than $10 per year is the goal.
The project makes good use of existing components on both the edge and cloud sides and all software components are freely available in the public domain. The server hardware is mid end and will cost around $700 new. The Coral dev board can currently be bought for $129. The operating costs consists of month AWS service charges and electricity service for the server and Coral dev board.
Running my server using 100 Watts on average for 24 hours a day @ $0.10 per kWh costs about $87/year in electricity costs. Running the Coral dev board using 10 Watts on average for 24 hours a day @ $0.10 per kWh costs about $8.7/year in electricity costs. Clearly to have a hope of meeting the $10/year goal one has to use the Coral system!
The AWS cloud costs will mainly consist of S3, Rekognition (if using remote detection) and Step Function service usage. Although this project uses Lambda, DynamoDB and other services their usage is normally so low they fall into the free tier. At scale this will not be the case but on a relative basis S3, Rekognition and Step Function services will dominate the operating cost.
Over a year of usage the system has been uploading about 10GB/month of images from seven cameras to S3 with an average image size around 300 kB. I'm using STANDARD-IA storage which costs $0.0125 per GB-Month. This works out to about $0.13/month or about $1.5/year. Very frugal!
Step function costs have been averaging about $4/month for about 164,000 state transitions per month.
I found that remote object detection using Recognition costs about $35/month with the typical activity seen by my seven cameras which generated about 40,000 images/month for Recognition to analyze. I have not yet implemented face recognition in the cloud so these costs only include object detection. With face recognition these cloud costs could potentially double. This is very expensive even compared to the case of running the server for object detection locally!
The annual cost to operate smart-zoneminder for seven 1080p cameras is summarized by the table below. This assumes one year's worth of alarm images stored in the cloud.
| Configuration/Annual Cost | Step Fn ($) | S3 ($) | Rekognition ($) | Electricity ($) | Total ($) | Total/Camera ($) |
|---|---|---|---|---|---|---|
| Server (Remote Detection) | 48 | 1.5 | 420 | 88 | 558 | 80 |
| Server (Local Detection) | 48 | 1.5 | 0 | 88 | 138 | 20 |
| Coral (Local Detection) | 48 | 1.5 | 0 | 8.7 | 58 | 8.3 |
On a per camera basis only the local Coral option meets $10/year operating cost goal. More work needs to be done to lower the operating costs, in particular the flexibility affording by the Step Functions may not be worth the costs at least with the granularity of the current Lambda functions. From this data, one thing is clear using Rekognition as the primary detector at scale is very expensive and most deployments need to consider edge-based detection, at least partially.
Be competitive with smart camera systems out in the market from Nest, Amazon, and others that use image recognition and Alexa
smart-zoneminder in its default configuration for seven 1080p cameras stores about three weeks of continuous video at the edge and one year of alarm images in the cloud with object and face recognition, real-time notifications and full integration with Alexa including voice search. With Google Coral based detection the cost is about $8 per month per camera.
Nest Aware, Cloud Cam, Ring Protect Plus and others are excellent solutions. All of these solutions support audio which currently smart-zoneminder does not. Compared with smart-zoneminder the closest in capabilities seems to be Nest Aware given its object and face recognition features but is expensive (currently $30/month for the first camera). Ring's plan is relatively inexpensive (currently $10/month unlimited cameras) but looks to be comparatively simple in capabilities (no object or face detection).
All of these solutions are very expensive compared to smart-zoneminder.
License
Everything here is licensed under the MIT license.
Contact
For questions or comments about this project please contact the author goruck (Lindo St. Angel) at {lindostangel} AT {gmail} DOT {com}.
Acknowledgements
The alarm uploader was inspired by Brian Roy's Zoneminder-Alert-Image-Upload-to-Amazon-S3. The general approach of triggering an AWS Step function by an image uploaded to S3 to be analyzed by Rekognition was modeled after Mark West's smart-security-camera.
Thank you Brian and Mark!
Appendix
Machine Learning Platform Installation on Linux Server
The instructions to install the Nvidia drivers and CUDA libraries, TensorFlow-GPU, OpenCV, dlib, face_recognition, scikit-learn, XGBoost, zerorpc and a Python virtual environment are shown below. This is required to run all machine learning-related code in this project on the Linux server. See tpu-servers for installation instructions to install the same on the edge tpu.
Tested on Ubuntu 18.04 with CUDA 10.1.
Install CUDA with apt
See this for complete installation details.
Install opencv 4.2.0 w/CUDA support
Make and cd to installation directory
$ INSTALL_DIR=/tmp/opencv_compile
$ mkdir $INSTALL_DIR
$ cd $INSTALL_DIR
Update repo
$ sudo apt update
Install basic dependencies
$ sudo apt install python3-dev python3-pip python3-numpy \
build-essential cmake git libgtk2.0-dev pkg-config \
libavcodec-dev libavformat-dev libswscale-dev libtbb2 libtbb-dev \
libjpeg-dev libpng-dev libtiff-dev libdc1394-22-dev protobuf-compiler \
libgflags-dev libgoogle-glog-dev libblas-dev libhdf5-serial-dev \
liblmdb-dev libleveldb-dev liblapack-dev libsnappy-dev libprotobuf-dev \
libopenblas-dev libgtk2.0-dev libboost-dev libboost-all-dev \
libeigen3-dev libatlas-base-dev libne10-10 libne10-dev liblapacke-dev
Download source
$ sudo apt update
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.2.0.zip
$ unzip opencv.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.2.0.zip
$ unzip opencv_contrib.zip
$ rm -i *.zip
Configure OpenCV using cmake
$ cd opencv-4.2.0
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D WITH_CUDA=ON \
-D ENABLE_FAST_MATH=1 \
-D CUDA_FAST_MATH=1 \
-D CUDA_ARCH_BIN=6.1 \
-D WITH_CUBLAS=1 \
-D INSTALL_PYTHON_EXAMPLES=OFF \
-D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib-4.2.0/modules \
-D BUILD_EXAMPLES=OFF ..
Compile and install
$ make -j 4
$ sudo make install
$ sudo ldconfig
Move and rename binding (for Python3 only)
$ sudo cp /usr/local/lib/python3.6/dist-packages/cv2/python-3.6/cv2.cpython-36m-x86_64-linux-gnu.so \
/usr/local/lib/python3.6/site-packages/cv2.so
Test
$ python3
Python 3.6.9 (default, Nov 7 2019, 10:44:02)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'4.2.0'
>>>
Remove install directory (optional)
$ cd ~
$ sudo rm -rf $INSTALL_DIR
Install dlib w/CUDA support
Make and cd to installation directory
$ INSTALL_DIR=/tmp/dlib_compile
$ mkdir $INSTALL_DIR
$ cd $INSTALL_DIR
Update repo
$ sudo apt update
Install dependencies if needed
$ sudo apt-get install build-essential cmake
Clone dlib repo.
$ git clone https://github.com/davisking/dlib.git
Build and install.
$ cd dlib
$ python3 setup.py install \
--set DLIB_NO_GUI_SUPPORT=YES \
--set DLIB_USE_CUDA=YES
Test...
$ python3
Python 3.6.9 (default, Nov 7 2019, 10:44:02)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlib
>>> dlib.__version__
'19.19.99'
>>>
Remove install directory (optional)
$ cd ~
$ sudo rm -rf $INSTALL_DIR
Python virtual environment setup
Install virtualenvwrapper
See https://virtualenvwrapper.readthedocs.io/en/latest/index.html#.
$ pip3 install virtualenvwrapper
Pin to Python3 and set defaults (add to ~/.bashrc)
$ export WORKON_HOME=$HOME/.virtualenvs
$ export VIRTUALENV_PYTHON=/usr/bin/python3
$ export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
$ source /usr/local/bin/virtualenvwrapper.sh
Create Python virtual environment called "szm"
$ mkvirtualenv szm
(szm) $ deactivate
$
Link cv2.so to szm Python3 virtual environment
$ cd ~/.virtualenvs/szm/lib/python3.6/site-packages/
$ ln -s /usr/local/lib/python3.6/site-packages/cv2.so cv2.so
Switch to szm Python virtual environment
$ workon szm
(szm) $
Now install required Python packages below...
Install face_recognition
# Install
(szm) $ pip3 install face_recognition
# Test...
(szm) $ python3
Python 3.6.9 (default, Nov 7 2019, 10:44:02)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import face_recognition
>>> face_recognition.__version__
'1.2.3'
>>> exit()
Install zerorpc
# Install
$ pip3 install zerorpc
# Test...
(szm) $ python3
Python 3.6.9 (default, Nov 7 2019, 10:44:02)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import zerorpc
>>> exit()
Install scikit-learn
# Install
(szm) $ pip3 install scikit-learn
# Test...
(szm) $ python3
Python 3.6.9 (default, Nov 7 2019, 10:44:02)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import sklearn
>>> sklearn.__version__
'0.22.1'
>>> exit()
Install XGBoost
# Install - see https://xgboost.readthedocs.io/en/latest/build.html
$ pip3 install xgboost
# Test...
(szm) $ python3
Python 3.6.9 (default, Nov 7 2019, 10:44:02)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import xgboost
>>> xgboost.__version__
'0.90'
>>> exit()
Install TensorFlow
# Install
(szm) $ pip3 install tensorflow
# Test...
(szm) $ python3
Python 3.6.9 (default, Nov 7 2019, 10:44:02)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow
>>> tensorflow.__version__
'2.1.0'
>>> gpus = tensorflow.config.experimental.list_physical_devices('GPU') # test that GPU is being used
2020-02-08 18:42:47.687771: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1
2020-02-08 18:42:48.007147: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-08 18:42:48.007443: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1555] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GTX 1080 Ti computeCapability: 6.1
coreClock: 1.683GHz coreCount: 28 deviceMemorySize: 10.92GiB deviceMemoryBandwidth: 451.17GiB/s
2020-02-08 18:42:48.009844: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
2020-02-08 18:42:48.009979: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10
2020-02-08 18:42:48.011510: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10
2020-02-08 18:42:48.024092: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10
2020-02-08 18:42:48.075393: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10
2020-02-08 18:42:48.082163: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10
2020-02-08 18:42:48.082272: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
2020-02-08 18:42:48.082413: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-08 18:42:48.082798: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-08 18:42:48.083054: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1697] Adding visible gpu devices: 0
>>> gpus
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
>>> exit()
Install misc packages
(szm) $ pip3 install pandas matplotlib
Deactivate virtual environment
(szm) $ deactivate
$
Note that the Python packages used by the installation are listed in the file ml_requirements.txt and can be used to install all packages by pip3 install -r /path/to/ml-requirements.txt.
Object Detection Performance and Model Selection
I benchmarked Tensorflow object detection model performance on the machine running smart-zoneminder. The benchmarking configuration and results are shown below. For a good overview of the Tensorflow object detection models see Deep Learning for Object Detection: A Comprehensive Review.
Hardware Configuration
- Intel Core i5-3570K 3.4GHz CPU
- Main system memory 16 GiB RAM
- NVidia GeForce GTX 1080 Ti (compute capability: 6.1)
Software Configuration
- Ubuntu 18.04.1 LTS
- Tensorflow-gpu Version 1.8.0
- TensorRT Version 4.0.1.6
- NVidia Driver Version 396.54
- CUDA Version 9.0
- CuDNN Version 7.0.5
Benchmarking Configuration
I used the benchmarking capability in TensorRT / TensorFlow Object Detection because I wanted to evaluate model performance with TensorRT optimizations (in the results below no TensorRT optimizations were used). This code uses the COCO API to fetch the images and annotations used for the benchmarking and was configured by the json shown below.
"optimization_config": {
"use_trt": false,
"remove_assert": false
},
"benchmark_config": {
"images_dir": "dataset/val2014",
"annotation_path": "dataset/annotations/instances_val2014.json",
"batch_size": 1,
"image_shape": [600, 600],
"num_images": 4096
}
Results
| Model | Avg Latency (ms) | Avg Throughput (fps) | COCO mAP |
|---|---|---|---|
| rfcn_resnet101_coco | 48 | 21 | 0.28 |
| ssd_inception_v2_coco | 17 | 60 | 0.27 |
| ssd_mobilenet_v2_coco | 14 | 74 | 0.24 |
| ssd_mobilenet_v1_coco | 11 | 92 | 0.22 |
Based on these results the ssd_inception_v2_coco model seems to be a good tradeoff between performance and accuracy on my machine but in practice I found rfcn_resnet101_coco to be more accurate and used it for this project. Others with less capable hardware will likely find ssd_inception_v2_coco to be acceptable.
The performance using the Google Coral dev board can be found here which shows that for MobileNet v1 an inference takes 2.2 ms using the TPU (image size of 224x224).
Face Detection and Recognition Tuning
The face detection and recognition accuracy vs compute can be adjusted by a few parameters found in config.json. These are:
- numFaceImgUpsample
- faceDetModel
- numJitters
- focusMeasureThreshold
- minSvmProba
To aid in the optimization of these parameters I developed the view-mongo-images.py program that allows you to step through the mongodb database written to by zm-s3-uploader.js to quickly see the effect of changing parameter values.
The program can also generate images and metadata in the Pascal VOC format that can be used to retrain an existing model, see Making a Custom Object Detector using a Pre-trained Model in Tensorflow and How To Train an Object Detection Classifier for Multiple Objects Using TensorFlow (GPU) on Windows 10.
An example image generated by view-mongo-images.py is shown below.

Sample console output from zm-s3-upload
info: Waiting for new alarm frame(s)...
info: 4 un-uploaded frames found in 0 s 2.6 ms.
info: Running with local object detection enabled.
info: Running with local face det / rec enabled.
info: Processing 4 alarm frame(s)...
info: No objects detected in /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01658-capture.jpg
info: False positives will NOT be uploaded.
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01659-capture.jpg
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01660-capture.jpg.
info: Image labels: { Confidence: 99.4522213935852,
Name: 'person',
Box:
{ ymin: 70.53511530160904,
xmin: 929.5820617675781,
ymax: 411.35162115097046,
xmax: 1106.6095733642578 },
Face: null }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01661-capture.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01660-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1660-18-5-33-410.jpg
info: Wrote 4 doc(s) to mongodb.
info: 4 / 4 image(s) processed in 0 s 822.9 ms (4.9 fps).
info: 1 image(s) analyzed and uploaded.
info: 1 image(s) analyzed but not uploaded (false positives).
info: 2 image(s) skipped analysis.
info: Waiting for new alarm frame(s)...
info: 4 un-uploaded frames found in 0 s 2.0 ms.
info: Running with local object detection enabled.
info: Running with local face det / rec enabled.
info: Processing 4 alarm frame(s)...
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01662-capture.jpg.
info: Image labels: { Confidence: 99.92679953575134,
Name: 'person',
Box:
{ ymin: 60.17618536949158,
xmin: 935.4948806762695,
ymax: 451.8808078765869,
xmax: 1139.0485382080078 },
Face: null }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01663-capture.jpg
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01664-capture.jpg.
info: Image labels: { Confidence: 99.92903470993042,
Name: 'person',
Box:
{ ymin: 64.19369325041771,
xmin: 980.7666778564453,
ymax: 457.5006365776062,
xmax: 1182.9373168945312 },
Face: null }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01665-capture.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01662-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1662-18-5-33-770.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01664-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1664-18-5-34-150.jpg
info: Wrote 4 doc(s) to mongodb.
info: 4 / 4 image(s) processed in 1 s 199.5 ms (3.3 fps).
info: 2 image(s) analyzed and uploaded.
info: 2 image(s) skipped analysis.
info: Waiting for new alarm frame(s)...
info: 6 un-uploaded frames found in 0 s 1.9 ms.
info: Running with local object detection enabled.
info: Running with local face det / rec enabled.
info: Processing 6 alarm frame(s)...
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01666-capture.jpg.
info: Image labels: { Confidence: 99.90187883377075,
Name: 'person',
Box:
{ ymin: 81.60609126091003,
xmin: 985.4228210449219,
ymax: 537.035139799118,
xmax: 1188.4705352783203 },
Face: 'lindo_st_angel' }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01667-capture.jpg
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01668-capture.jpg.
info: Image labels: { Confidence: 99.9535322189331,
Name: 'person',
Box:
{ ymin: 93.94017040729523,
xmin: 967.1494674682617,
ymax: 557.0506739616394,
xmax: 1194.9910354614258 },
Face: null }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01669-capture.jpg
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01670-capture.jpg.
info: Image labels: { Confidence: 99.87404942512512,
Name: 'person',
Box:
{ ymin: 132.87222236394882,
xmin: 986.6911697387695,
ymax: 644.4615697860718,
xmax: 1224.5182800292969 },
Face: 'lindo_st_angel' }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01671-capture.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01666-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1666-18-5-34-560.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01668-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1668-18-5-35-980.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01670-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1670-18-5-35-440.jpg
info: Wrote 6 doc(s) to mongodb.
info: 6 / 6 image(s) processed in 1 s 811.3 ms (3.3 fps).
info: 3 image(s) analyzed and uploaded.
info: 3 image(s) skipped analysis.
info: Waiting for new alarm frame(s)...
info: 8 un-uploaded frames found in 0 s 2.7 ms.
info: Running with local object detection enabled.
info: Running with local face det / rec enabled.
info: Processing 8 alarm frame(s)...
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01672-capture.jpg.
info: Image labels: { Confidence: 99.72984194755554,
Name: 'person',
Box:
{ ymin: 142.51379549503326,
xmin: 1019.4163513183594,
ymax: 764.7018671035767,
xmax: 1282.328109741211 },
Face: 'lindo_st_angel' }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01673-capture.jpg
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01674-capture.jpg.
info: Image labels: { Confidence: 99.80520009994507,
Name: 'person',
Box:
{ ymin: 181.97490513324738,
xmin: 1066.486930847168,
ymax: 798.1501507759094,
xmax: 1333.9923477172852 },
Face: 'lindo_st_angel' }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01675-capture.jpg
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01676-capture.jpg.
info: Image labels: { Confidence: 99.86151456832886,
Name: 'person',
Box:
{ ymin: 217.81068742275238,
xmin: 1162.7293395996094,
ymax: 797.7429270744324,
xmax: 1429.9959182739258 },
Face: null }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01677-capture.jpg
info: Processed /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01678-capture.jpg.
info: Image labels: { Confidence: 99.86981153488159,
Name: 'person',
Box:
{ ymin: 246.54372811317444,
xmin: 1176.1318588256836,
ymax: 837.6794958114624,
xmax: 1562.0167922973633 },
Face: null }
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01679-capture.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01672-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1672-18-5-35-780.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01674-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1674-18-5-36-260.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01676-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1676-18-5-36-530.jpg
info: The file: /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/00/00/01678-capture.jpg will be saved to: PlayroomDoor/2019-4-21/hour-18/New_Event-ID_823154-Frame_1678-18-5-37-990.jpg
info: Wrote 8 doc(s) to mongodb.
info: 8 / 8 image(s) processed in 2 s 372.9 ms (3.4 fps).
info: 4 image(s) analyzed and uploaded.
info: 4 image(s) skipped analysis.
info: Waiting for new alarm frame(s)...
info: 15 un-uploaded frames found in 0 s 3.7 ms.
info: Running with local object detection enabled.
info: Running with local face det / rec enabled.
info: Processing 10 alarm frame(s)...
info: No objects detected in /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/10/00/00027-capture.jpg
info: False positives will NOT be uploaded.
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/10/00/00028-capture.jpg
info: No objects detected in /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/10/00/00029-capture.jpg
info: False positives will NOT be uploaded.
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/10/00/00030-capture.jpg
info: No objects detected in /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/10/00/00031-capture.jpg
info: False positives will NOT be uploaded.
info: Skipped processing of /nvr/zoneminder/events/PlayroomDoor/19/04/21/18/10/00/00032-capture.jpg
info: No objects detected in /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00038-capture.jpg
info: False positives will NOT be uploaded.
info: Skipped processing of /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00039-capture.jpg
info: Processed /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00040-capture.jpg.
info: Image labels: { Confidence: 99.42518472671509,
Name: 'person',
Box:
{ ymin: 699.8572540283203,
xmin: 509.47105407714844,
ymax: 1065.4301977157593,
xmax: 946.2566757202148 },
Face: null }
info: Skipped processing of /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00042-capture.jpg
info: The file: /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00040-capture.jpg will be saved to: BackPorch/2019-4-21/hour-18/New_Event-ID_823163-Frame_40-18-10-8-000.jpg
info: Wrote 10 doc(s) to mongodb.
info: 10 / 15 image(s) processed in 1 s 54.5 ms (9.5 fps).
info: Processing 5 alarm frame(s)...
info: Processed /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00043-capture.jpg.
info: Image labels: { Confidence: 98.44893217086792,
Name: 'person',
Box:
{ ymin: 734.0281248092651,
xmin: 520.920524597168,
ymax: 1073.876130580902,
xmax: 816.9968032836914 },
Face: null }
info: Skipped processing of /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00044-capture.jpg
info: No objects detected in /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00045-capture.jpg
info: False positives will NOT be uploaded.
info: Skipped processing of /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00047-capture.jpg
info: No objects detected in /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00048-capture.jpg
info: False positives will NOT be uploaded.
info: The file: /nvr/zoneminder/events/BackPorch/19/04/21/18/10/00/00043-capture.jpg will be saved to: BackPorch/2019-4-21/hour-18/New_Event-ID_823163-Frame_43-18-10-8-580.jpg
info: Wrote 5 doc(s) to mongodb.
info: 15 / 15 image(s) processed in 1 s 867.8 ms (8.0 fps).
info: 2 image(s) analyzed and uploaded.
info: 6 image(s) analyzed but not uploaded (false positives).
info: 7 image(s) skipped analysis.
info: Waiting for new alarm frame(s)...