tim232385 / Webvideobot
Licence: mit
Web crawler.
Stars: ✭ 214
Programming Languages
java
68154 projects - #9 most used programming language
Projects that are alternatives of or similar to Webvideobot
Ncov2019 data crawler
疫情数据爬虫,2019新型冠状病毒数据仓库,轨迹数据,同乘数据,报道
Stars: ✭ 175 (-18.22%)
Mutual labels: crawler, spider
Goribot
[Crawler/Scraper for Golang]🕷A lightweight distributed friendly Golang crawler framework.一个轻量的分布式友好的 Golang 爬虫框架。
Stars: ✭ 190 (-11.21%)
Mutual labels: crawler, spider
Gain
Web crawling framework based on asyncio.
Stars: ✭ 2,002 (+835.51%)
Mutual labels: crawler, spider
Spoon
🥄 A package for building specific Proxy Pool for different Sites.
Stars: ✭ 173 (-19.16%)
Mutual labels: crawler, spider
Yispider
一款分布式爬虫平台,帮助你更好的管理和开发爬虫。 内置一套爬虫定义规则(模版),可使用模版快速定义爬虫,也可当作框架手动开发爬虫。(兴趣使然的项目,用的不爽了就更新)
Stars: ✭ 158 (-26.17%)
Mutual labels: crawler, spider
Marmot
💐Marmot | Web Crawler/HTTP protocol Download Package 🐭
Stars: ✭ 186 (-13.08%)
Mutual labels: crawler, spider
Lianjia Beike Spider
链家网和贝壳网房价爬虫,采集北京上海广州深圳等21个中国主要城市的房价数据(小区,二手房,出租房,新房),稳定可靠快速!支持csv,MySQL, MongoDB,Excel, json存储,支持Python2和3,图表展示数据,注释丰富 ,点星支持,仅供学习参考,请勿用于商业用途,后果自负。
Stars: ✭ 2,257 (+954.67%)
Mutual labels: crawler, spider
Colly
Elegant Scraper and Crawler Framework for Golang
Stars: ✭ 15,535 (+7159.35%)
Mutual labels: crawler, spider
Scrapingoutsourcing
ScrapingOutsourcing专注分享爬虫代码 尽量每周更新一个
Stars: ✭ 164 (-23.36%)
Mutual labels: crawler, spider
Querylist
🕷️ The progressive PHP crawler framework! 优雅的渐进式PHP采集框架。
Stars: ✭ 2,392 (+1017.76%)
Mutual labels: crawler, spider
Linkedin Profile Scraper
🕵️♂️ LinkedIn profile scraper returning structured profile data in JSON. Works in 2020.
Stars: ✭ 171 (-20.09%)
Mutual labels: crawler, spider
Python3 Spider
Python爬虫实战 - 模拟登陆各大网站 包含但不限于:滑块验证、拼多多、美团、百度、bilibili、大众点评、淘宝,如果喜欢请start ❤️
Stars: ✭ 2,129 (+894.86%)
Mutual labels: crawler, spider
Abot
Cross Platform C# web crawler framework built for speed and flexibility. Please star this project! +1.
Stars: ✭ 1,961 (+816.36%)
Mutual labels: crawler, spider
Zhihu Crawler People
A simple distributed crawler for zhihu && data analysis
Stars: ✭ 182 (-14.95%)
Mutual labels: crawler, spider
Fooproxy
稳健高效的评分制-针对性- IP代理池 + API服务,可以自己插入采集器进行代理IP的爬取,针对你的爬虫的一个或多个目标网站分别生成有效的IP代理数据库,支持MongoDB 4.0 使用 Python3.7(Scored IP proxy pool ,customise proxy data crawler can be added anytime)
Stars: ✭ 195 (-8.88%)
Mutual labels: crawler, spider
![]()
Web Vedeo Bot
![]()
![]()
- Easy install, all dependencies are already included, just need to have a java environment.

Environment, Architecture
-
Java1.8
-
Crawler4j
-
Spring Boot x H2 Db
How to use
git clone https://github.com/tim232385/WebVideoBot.git
cd WebVideoBot
java -jar PornBot.jar
**DOWNLOAD_VIDEO default is N** See Default Configuration

Database Description
http://localhost:8000/h2-console/
JDBC URL: jdbc:h2:~/porn/porn-db
User Name: sa
Password: empty
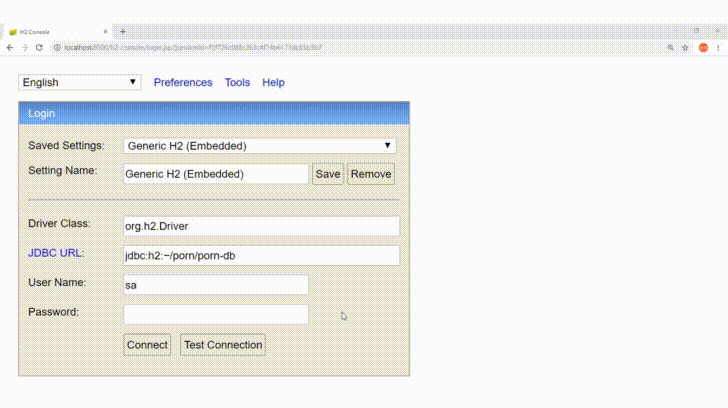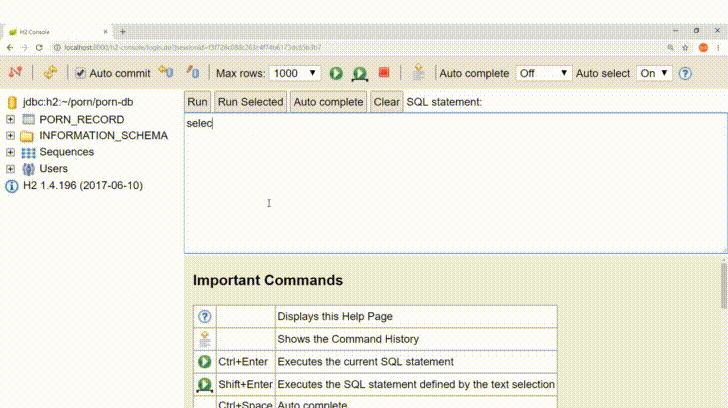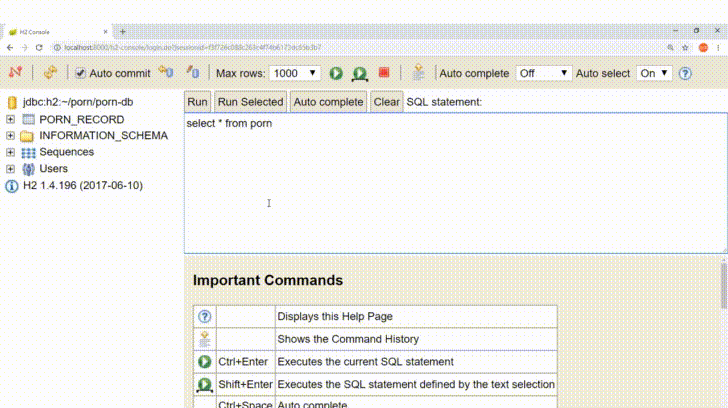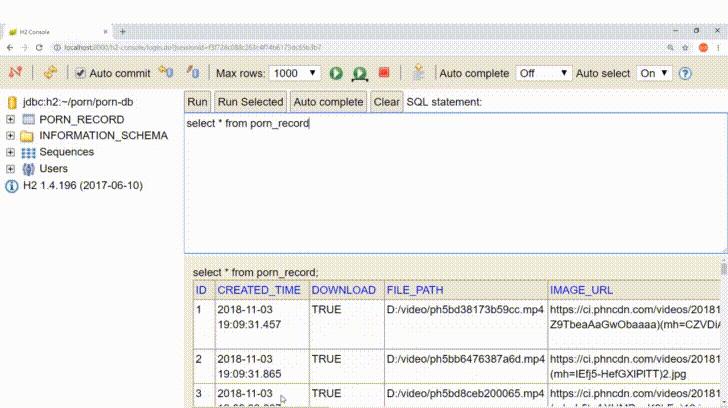
Record Table:
Table_Name :PORN_RECORD
viewKey :The website's video unique key.
imageUrl :Image url of video.
linkUrl :Video jump to Website`s link
videoUrl :Video adrress.
videoTitle :Title of video.
videoDuration :Video click count.
videoQuality :Defualt quality - 240, 480, 960, 1280p.
download :Has been downloaded. True or false.
createdTime :The record created time.
filePath :The video downloaded path.
Configuration
FILE_PATH :Video download path.
VIDEO_DOWNLOAD_SIZE :Maximum download size of the video.(Byte)
MAX_PAGE_SIZE :Crawling page size.
CONCURRENT_THREAD_SIZE :Muilti-threads request amount.
START_URL :Crawling url.
DOWNLOAD_VIDEO :Download video. Y or N.
[See Default Configuration](https://github.com/tim232385/PornBot/blob/master/config.properties
Stargazers over time

Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].