Language-Adversarial Training for Cross-Lingual Text Classification
This repo contains the source code for our TACL journal paper:
Adversarial Deep Averaging Networks for Cross-Lingual Sentiment Classification
Xilun Chen,
Yu Sun,
Ben Athiwaratkun,
Claire Cardie,
Kilian Weinberger
Transactions of the Association for Computational Linguistics (TACL)
paper (arXiv),
bibtex (arXiv),
paper (TACL),
bibtex,
talk@EMNLP2018
Introduction
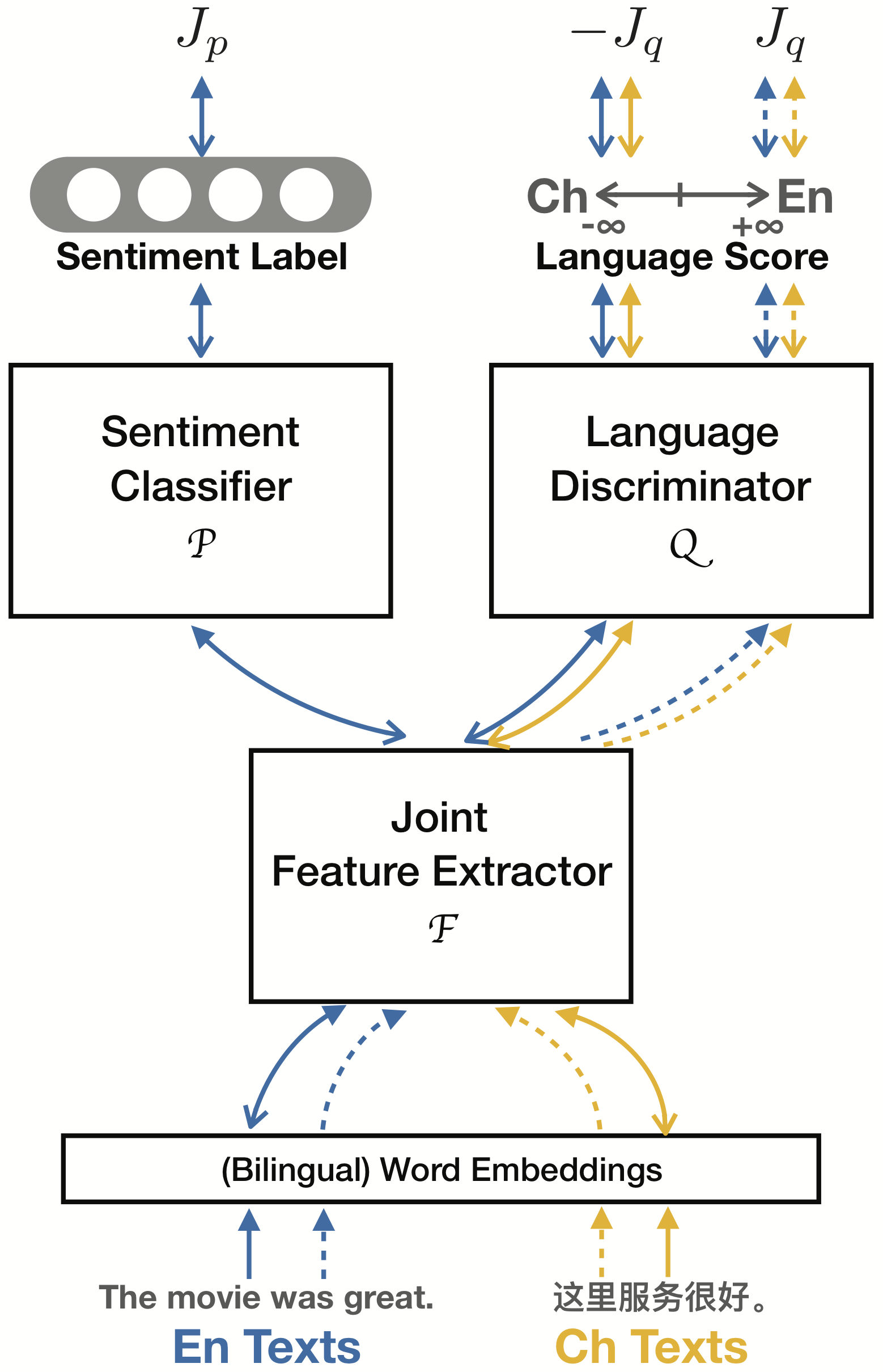
ADAN transfers the knowledge learned from labeled data on a resource-rich source language to low-resource languages where only unlabeled data exists. It achieves cross-lingual model transfer via learning language-invariant features extracted by Language-Adversarial Training.
Requirements
- Python 3.6
- PyTorch 0.4
- PyTorchNet (for confusion matrix)
- scipy
- tqdm (for progress bar)
File Structure
.
├── README.md
└── code
├── data_prep (data processing scripts)
│ ├── chn_hotel_dataset.py (processing the Chinese Hotel Review dataset)
│ └── yelp_dataset.py (processing the English Yelp Review dataset)
├── layers.py (lower-level helper modules)
├── models.py (higher-level modules)
├── options.py (hyper-parameters aka. all the knobs you may want to turn)
├── train.py (main file to train the model)
├── utils.py (helper functions)
└── vocab.py (vocabulary)
Dataset
The datasets can be downloaded separately here.
To support new datasets, simply write a new script under data_prep similar to the current ones and update train.py to correctly load it.
Run Experiments
python train.py --model_save_file {path_to_save_the_model}By default, the code uses CNN as the feature extractor. To use the LSTM (with dot attention) feature extractor:
python train.py --model lstm --F_layers 2 --model_save_file {path_to_save_the_model}