heronsystems / Adeptrl
Licence: gpl-3.0
Reinforcement learning framework to accelerate research
Stars: ✭ 173
Programming Languages
python
139335 projects - #7 most used programming language
Projects that are alternatives of or similar to Adeptrl
Reaver
Reaver: Modular Deep Reinforcement Learning Framework. Focused on StarCraft II. Supports Gym, Atari, and MuJoCo.
Stars: ✭ 499 (+188.44%)
Mutual labels: artificial-intelligence, reinforcement-learning, actor-critic
Mlds2018spring
Machine Learning and having it Deep and Structured (MLDS) in 2018 spring
Stars: ✭ 124 (-28.32%)
Mutual labels: reinforcement-learning, actor-critic
Pytorch Rl
Tutorials for reinforcement learning in PyTorch and Gym by implementing a few of the popular algorithms. [IN PROGRESS]
Stars: ✭ 121 (-30.06%)
Mutual labels: reinforcement-learning, actor-critic
Pytorch sac
PyTorch implementation of Soft Actor-Critic (SAC)
Stars: ✭ 174 (+0.58%)
Mutual labels: reinforcement-learning, actor-critic
A2c
A Clearer and Simpler Synchronous Advantage Actor Critic (A2C) Implementation in TensorFlow
Stars: ✭ 169 (-2.31%)
Mutual labels: reinforcement-learning, actor-critic
Reinforcement Learning An Introduction
Python Implementation of Reinforcement Learning: An Introduction
Stars: ✭ 11,042 (+6282.66%)
Mutual labels: artificial-intelligence, reinforcement-learning
Ravens
Train robotic agents to learn pick and place with deep learning for vision-based manipulation in PyBullet. Transporter Nets, CoRL 2020.
Stars: ✭ 133 (-23.12%)
Mutual labels: artificial-intelligence, reinforcement-learning
Rlai Exercises
Exercise Solutions for Reinforcement Learning: An Introduction [2nd Edition]
Stars: ✭ 97 (-43.93%)
Mutual labels: artificial-intelligence, reinforcement-learning
Java Deep Learning Cookbook
Code for Java Deep Learning Cookbook
Stars: ✭ 156 (-9.83%)
Mutual labels: artificial-intelligence, reinforcement-learning
Awesome Ai
A curated list of artificial intelligence resources (Courses, Tools, App, Open Source Project)
Stars: ✭ 161 (-6.94%)
Mutual labels: artificial-intelligence, reinforcement-learning
Elf
An End-To-End, Lightweight and Flexible Platform for Game Research
Stars: ✭ 2,057 (+1089.02%)
Mutual labels: artificial-intelligence, reinforcement-learning
Hierarchical Actor Critic Hac Pytorch
PyTorch implementation of Hierarchical Actor Critic (HAC) for OpenAI gym environments
Stars: ✭ 116 (-32.95%)
Mutual labels: reinforcement-learning, actor-critic
Reinforcement Learning Cheat Sheet
Reinforcement Learning Cheat Sheet
Stars: ✭ 104 (-39.88%)
Mutual labels: artificial-intelligence, reinforcement-learning
Reinforcementlearning Atarigame
Pytorch LSTM RNN for reinforcement learning to play Atari games from OpenAI Universe. We also use Google Deep Mind's Asynchronous Advantage Actor-Critic (A3C) Algorithm. This is much superior and efficient than DQN and obsoletes it. Can play on many games
Stars: ✭ 118 (-31.79%)
Mutual labels: reinforcement-learning, actor-critic
Chemgan Challenge
Code for the paper: Benhenda, M. 2017. ChemGAN challenge for drug discovery: can AI reproduce natural chemical diversity? arXiv preprint arXiv:1708.08227.
Stars: ✭ 98 (-43.35%)
Mutual labels: artificial-intelligence, reinforcement-learning
Toycarirl
Implementation of Inverse Reinforcement Learning Algorithm on a toy car in a 2D world problem, (Apprenticeship Learning via Inverse Reinforcement Learning Abbeel & Ng, 2004)
Stars: ✭ 128 (-26.01%)
Mutual labels: artificial-intelligence, reinforcement-learning
Awesome Ml Courses
Awesome free machine learning and AI courses with video lectures.
Stars: ✭ 2,145 (+1139.88%)
Mutual labels: artificial-intelligence, reinforcement-learning
Pytorch sac ae
PyTorch implementation of Soft Actor-Critic + Autoencoder(SAC+AE)
Stars: ✭ 94 (-45.66%)
Mutual labels: reinforcement-learning, actor-critic
Papers Literature Ml Dl Rl Ai
Highly cited and useful papers related to machine learning, deep learning, AI, game theory, reinforcement learning
Stars: ✭ 1,341 (+675.14%)
Mutual labels: artificial-intelligence, reinforcement-learning
Flappy Es
Flappy Bird AI using Evolution Strategies
Stars: ✭ 140 (-19.08%)
Mutual labels: artificial-intelligence, reinforcement-learning

adept is a reinforcement learning framework designed to accelerate research by abstracting away engineering challenges associated with deep reinforcement learning. adept provides:
- multi-GPU training
- a modular interface for using custom networks, agents, and environments
- baseline reinforcement learning models and algorithms for PyTorch
- built-in tensorboard logging, model saving, reloading, evaluation, and rendering
- proven hyperparameter defaults
This code is early-access, expect rough edges. Interfaces subject to change. We're happy to accept feedback and contributions.
Read More
Documentation
- Architecture Overview
- ModularNetwork Overview
- Resume training
- Evaluate a model
- Render environment
Examples
- Custom Network (stub | example)
- Custom SubModule (stub | example)
- Custom Agent (stub | example)
- Custom Environment (stub | example)
Installation
git clone https://github.com/heronsystems/adeptRL
cd adeptRL
pip install -e .[all]
From docker:
Quickstart
Train an Agent
Logs go to /tmp/adept_logs/ by default. The log directory contains the
tensorboard file, saved models, and other metadata.
# Local Mode (A2C)
# We recommend 4GB+ GPU memory, 8GB+ RAM, 4+ Cores
python -m adept.app local --env BeamRiderNoFrameskip-v4
# Distributed Mode (A2C, requires NCCL)
# We recommend 2+ GPUs, 8GB+ GPU memory, 32GB+ RAM, 4+ Cores
python -m adept.app distrib --env BeamRiderNoFrameskip-v4
# IMPALA (requires ray, resource intensive)
# We recommend 2+ GPUs, 8GB+ GPU memory, 32GB+ RAM, 4+ Cores
python -m adept.app actorlearner --env BeamRiderNoFrameskip-v4
# To see a full list of options:
python -m adept.app -h
python -m adept.app help <command>
Use your own Agent, Environment, Network, or SubModule
"""
my_script.py
Train an agent on a single GPU.
"""
from adept.scripts.local import parse_args, main
from adept.network import NetworkModule, SubModule1D
from adept.agent import AgentModule
from adept.env import EnvModule
class MyAgent(AgentModule):
pass # Implement
class MyEnv(EnvModule):
pass # Implement
class MyNet(NetworkModule):
pass # Implement
class MySubModule1D(SubModule1D):
pass # Implement
if __name__ == '__main__':
import adept
adept.register_agent(MyAgent)
adept.register_env(MyEnv)
adept.register_network(MyNet)
adept.register_submodule(MySubModule1D)
main(parse_args())
- Call your script like this:
python my_script.py --agent MyAgent --env env-id-1 --custom-network MyNet - You can see all the args here or how to implement the stubs in the examples section above.
Features
Scripts
Local (Single-node, Single-GPU)
- Best place to start if you're trying to understand code.
Distributed (Multi-node, Multi-GPU)
- Uses NCCL backend to all-reduce gradients across GPUs without a parameter server or host process.
- Supports NVLINK and InfiniBand to reduce communication overhead
- InfiniBand untested since we do not have a setup to test on.
Importance Weighted Actor Learner Architectures, IMPALA (Single Node, Multi-GPU)
- Our implementation uses GPU workers rather than CPU workers for forward passes.
- On Atari we achieve ~4k SPS = ~16k FPS with two GPUs and an 8-core CPU.
- "Note that the shallow IMPALA experiment completes training over 200 million frames in less than one hour."
- IMPALA official experiments use 48 cores.
- Ours: 2000 frame / (second * # CPU core) DeepMind: 1157 frame / (second * # CPU core)
- Does not yet support multiple nodes or direct GPU memory transfers.
Agents
Networks
- Modular Network Interface: supports arbitrary input and output shapes up to 4D via a SubModule API.
- Stateful networks (ie. LSTMs)
- Batch normalization (paper)
Environments
- OpenAI Gym Atari
Performance
- ~ 3,000 Steps/second = 12,000 FPS (Atari)
- Local Mode
- 64 environments
- GeForce 2080 Ti
- Ryzen 2700x 8-core
- Used to win a
Doom competition
(Ben Bell / Marv2in)
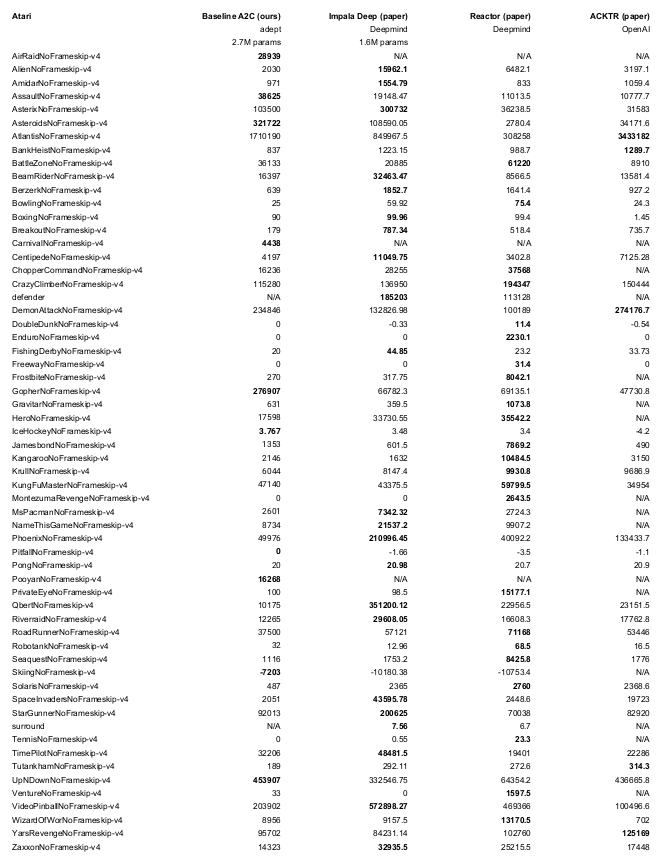
- Trained for 50M Steps / 200M Frames
- Up to 30 no-ops at start of each episode
- Evaluated on different seeds than trained on
- Architecture: Four Convs (F=32) followed by an LSTM (F=512)
- Reproduce with
python -m adept.app local --logdir ~/local64_benchmark --eval -y --nb-step 50e6 --env <env-id>

Acknowledgements
We borrow pieces of OpenAI's gym and baselines code. We indicate where this is done.
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].