hbaniecki / Adversarial Explainable Ai
Licence: cc-by-sa-4.0
💡 A curated list of adversarial attacks on model explanations
Stars: ✭ 56
Projects that are alternatives of or similar to Adversarial Explainable Ai
Adaptsegnet
Learning to Adapt Structured Output Space for Semantic Segmentation, CVPR 2018 (spotlight)
Stars: ✭ 654 (+1067.86%)
Mutual labels: adversarial-learning
Alibi
Algorithms for monitoring and explaining machine learning models
Stars: ✭ 924 (+1550%)
Mutual labels: interpretability
Awesome Graph Representation Learning
A curated list of awesome graph representation learning.
Stars: ✭ 44 (-21.43%)
Mutual labels: adversarial-learning
Tf Explain
Interpretability Methods for tf.keras models with Tensorflow 2.x
Stars: ✭ 780 (+1292.86%)
Mutual labels: interpretability
Advertorch
A Toolbox for Adversarial Robustness Research
Stars: ✭ 826 (+1375%)
Mutual labels: adversarial-learning
Symbolic Metamodeling
Codebase for "Demystifying Black-box Models with Symbolic Metamodels", NeurIPS 2019.
Stars: ✭ 29 (-48.21%)
Mutual labels: interpretability
Awesome Federated Learning
Federated Learning Library: https://fedml.ai
Stars: ✭ 624 (+1014.29%)
Mutual labels: interpretability
Contrastiveexplanation
Contrastive Explanation (Foil Trees), developed at TNO/Utrecht University
Stars: ✭ 36 (-35.71%)
Mutual labels: interpretability
Neural Structured Learning
Training neural models with structured signals.
Stars: ✭ 790 (+1310.71%)
Mutual labels: adversarial-learning
Taadpapers
Must-read Papers on Textual Adversarial Attack and Defense
Stars: ✭ 800 (+1328.57%)
Mutual labels: adversarial-learning
Lab
[CVPR 2018] Look at Boundary: A Boundary-Aware Face Alignment Algorithm
Stars: ✭ 956 (+1607.14%)
Mutual labels: adversarial-learning
Gvb
Code of Gradually Vanishing Bridge for Adversarial Domain Adaptation (CVPR2020)
Stars: ✭ 52 (-7.14%)
Mutual labels: adversarial-learning
Ad examples
A collection of anomaly detection methods (iid/point-based, graph and time series) including active learning for anomaly detection/discovery, bayesian rule-mining, description for diversity/explanation/interpretability. Analysis of incorporating label feedback with ensemble and tree-based detectors. Includes adversarial attacks with Graph Convolutional Network.
Stars: ✭ 641 (+1044.64%)
Mutual labels: interpretability
Advanced Gradient Obfuscating
Take further steps in the arms race of adversarial examples with only preprocessing.
Stars: ✭ 28 (-50%)
Mutual labels: adversarial-learning
Text nn
Text classification models. Used a submodule for other projects.
Stars: ✭ 55 (-1.79%)
Mutual labels: interpretability
Handwriting recogition using adversarial learning
[CVPR 2019] "Handwriting Recognition in Low-resource Scripts using Adversarial Learning ”, IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019.
Stars: ✭ 52 (-7.14%)
Mutual labels: adversarial-learning
A2cl Pt
Adversarial Background-Aware Loss for Weakly-supervised Temporal Activity Localization (ECCV 2020)
Stars: ✭ 34 (-39.29%)
Mutual labels: adversarial-learning
Adversarial Explainable AI
A curated list of Adversarial Explainable AI (XAI) resources, inspired by awesome-adversarial-machine-learning and awesome-interpretable-machine-learning. Due to the novelty of the field, this list is very much in the making. Contributions are welcome - send a pull request or contact me @hbaniecki.

There are various adversarial attacks on machine learning models; hence, ways of defending, e.g. by using XAI techniques. Nowadays, attacks on model explanations come to light, so does the defense to such adversary.
Veritas Vincit
Papers
Introduction
-
Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI
A. Barredo-Arrieta et al. Information Fusion 2019
In the last few years, Artificial Intelligence (AI) has achieved a notable momentum that, if harnessed appropriately, may deliver the best of expectations over many application sectors across the field. For this to occur shortly in Machine Learning, the entire community stands in front of the barrier of explainability, an inherent problem of the latest techniques brought by sub-symbolism (e.g. ensembles or Deep Neural Networks) that were not present in the last hype of AI (namely, expert systems and rule based models). Paradigms underlying this problem fall within the so-called eXplainable AI (XAI) field, which is widely acknowledged as a crucial feature for the practical deployment of AI models. The overview presented in this article examines the existing literature and contributions already done in the field of XAI, including a prospect toward what is yet to be reached. For this purpose we summarize previous efforts made to define explainability in Machine Learning, establishing a novel definition of explainable Machine Learning that covers such prior conceptual propositions with a major focus on the audience for which the explainability is sought. Departing from this definition, we propose and discuss about a taxonomy of recent contributions related to the explainability of different Machine Learning models, including those aimed at explaining Deep Learning methods for which a second dedicated taxonomy is built and examined in detail. This critical literature analysis serves as the motivating background for a series of challenges faced by XAI, such as the interesting crossroads of data fusion and explainability. Our prospects lead toward the concept of Responsible Artificial Intelligence, namely, a methodology for the large-scale implementation of AI methods in real organizations with fairness, model explainability and accountability at its core. Our ultimate goal is to provide newcomers to the field of XAI with a thorough taxonomy that can serve as reference material in order to stimulate future research advances, but also to encourage experts and professionals from other disciplines to embrace the benefits of AI in their activity sectors, without any prior bias for its lack of interpretability.
General
-
Towards Robust Interpretability with Self-Explaining Neural Networks
D. Alvarez-Melis & T. Jaakkola Advances in Neural Information Processing Systems 2018
Most recent work on interpretability of complex machine learning models has focused on estimating a-posteriori explanations for previously trained models around specific predictions. Self-explaining models where interpretability plays a key role already during learning have received much less attention. We propose three desiderata for explanations in general -- explicitness, faithfulness, and stability -- and show that existing methods do not satisfy them. In response, we design self-explaining models in stages, progressively generalizing linear classifiers to complex yet architecturally explicit models. Faithfulness and stability are enforced via regularization specifically tailored to such models. Experimental results across various benchmark datasets show that our framework offers a promising direction for reconciling model complexity and interpretability. -
Sanity Checks for Saliency Maps
J. Adebayo et al. Advances in Neural Information Processing Systems 2018
Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, and debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings. -
On Relating Explanations and Adversarial Examples
A. Ignatiev et al. Advances in Neural Information Processing Systems 2019
The importance of explanations (XP's) of machine learning (ML) model predictions and of adversarial examples (AE's) cannot be overstated, with both arguably being essential for the practical success of ML in different settings. There has been recent work on understanding and assessing the relationship between XP's and AE's. However, such work has been mostly experimental and a sound theoretical relationship has been elusive. This paper demonstrates that explanations and adversarial examples are related by a generalized form of hitting set duality, which extends earlier work on hitting set duality observed in model-based diagnosis and knowledge compilation. Furthermore, the paper proposes algorithms, which enable computing adversarial examples from explanations and vice-versa. -
Robustness in Machine Learning Explanations: Does It Matter?
L. Hancox-Li Conference on Fairness, Accountability, and Transparency 2020
The explainable AI literature contains multiple notions of what an explanation is and what desiderata explanations should satisfy. One implicit source of disagreement is how far the explanations should reflect real patterns in the data or the world. This disagreement underlies debates about other desiderata, such as how robust explanations are to slight perturbations in the input data. I argue that robustness is desirable to the extent that we’re concerned about finding real patterns in the world. The import of real patterns differs according to the problem context. In some contexts, non-robust explanations can constitute a moral hazard. By being clear about the extent to which we care about capturing real patterns, we can also determine whether the Rashomon Effect is a boon or a bane.
Attacks on XAI
-
Interpretation of Neural Networks Is Fragile
A. Ghorbani et al. AAAI Conference on Artificial Intelligence 2019
In order for machine learning to be trusted in many applications, it is critical to be able to reliably explain why the machine learning algorithm makes certain predictions. For this reason, a variety of methods have been developed recently to interpret neural network predictions by providing, for example, feature importance maps. For both scientific robustness and security reasons, it is important to know to what extent can the interpretations be altered by small systematic perturbations to the input data, which might be generated by adversaries or by measurement biases. In this paper, we demonstrate how to generate adversarial perturbations that produce perceptively indistinguishable inputs that are assigned the same predicted label, yet have very different interpretations. We systematically characterize the robustness of interpretations generated by several widely-used feature importance interpretation methods (feature importance maps, integrated gradients, and DeepLIFT) on ImageNet and CIFAR-10. In all cases, our experiments show that systematic perturbations can lead to dramatically different interpretations without changing the label. We extend these results to show that interpretations based on exemplars (e.g. influence functions) are similarly susceptible to adversarial attack. Our analysis of the geometry of the Hessian matrix gives insight on why robustness is a general challenge to current interpretation approaches. -
Fairwashing: the risk of rationalization
U. Aivodji et al. International Conference on Machine Learning 2019
Black-box explanation is the problem of explaining how a machine learning model – whose internal logic is hidden to the auditor and generally complex – produces its outcomes. Current approaches for solving this problem include model explanation, outcome explanation as well as model inspection. While these techniques can be beneficial by providing interpretability, they can be used in a negative manner to perform fairwashing, which we define as promoting the false perception that a machine learning model respects some ethical values. In particular, we demonstrate that it is possible to systematically rationalize decisions taken by an unfair black-box model using the model explanation as well as the outcome explanation approaches with a given fairness metric. Our solution, LaundryML, is based on a regularized rule list enumeration algorithm whose objective is to search for fair rule lists approximating an unfair black-box model. We empirically evaluate our rationalization technique on black-box models trained on real-world datasets and show that one can obtain rule lists with high fidelity to the black-box model while being considerably less unfair at the same time. -
The (Un)reliability of Saliency Methods
P. J. Kindermans et al. Explainable AI: Interpreting, Explaining and Visualizing Deep Learning 2019
Saliency methods aim to explain the predictions of deep neural networks. These methods lack reliability when the explanation is sensitive to factors that do not contribute to the model prediction. We use a simple and common pre-processing step which can be compensated for easily—adding a constant shift to the input data—to show that a transformation with no effect on how the model makes the decision can cause numerous methods to attribute incorrectly. In order to guarantee reliability, we believe that the explanation should not change when we can guarantee that two networks process the images in identical manners. We show, through several examples, that saliency methods that do not satisfy this requirement result in misleading attribution. The approach can be seen as a type of unit test; we construct a narrow ground truth to measure one stated desirable property. As such, we hope the community will embrace the development of additional tests. -
Fooling Neural Network Interpretations via Adversarial Model Manipulation
J. Heo et al. Advances in Neural Information Processing Systems 2019
We ask whether the neural network interpretation methods can be fooled via adversarial model manipulation, which is defined as a model fine-tuning step that aims to radically alter the explanations without hurting the accuracy of the original models, e.g., VGG19, ResNet50, and DenseNet121. By incorporating the interpretation results directly in the penalty term of the objective function for fine-tuning, we show that the state-of-the-art saliency map based interpreters, e.g., LRP, Grad-CAM, and SimpleGrad, can be easily fooled with our model manipulation. We propose two types of fooling, Passive and Active, and demonstrate such foolings generalize well to the entire validation set as well as transfer to other interpretation methods. Our results are validated by both visually showing the fooled explanations and reporting quantitative metrics that measure the deviations from the original explanations. We claim that the stability of neural network interpretation method with respect to our adversarial model manipulation is an important criterion to check for developing robust and reliable neural network interpretation method. -
Explanations can be manipulated and geometry is to blame
A. K. Dombrowski et al. Advances in Neural Information Processing Systems 2019
Explanation methods aim to make neural networks more trustworthy and interpretable. In this paper, we demonstrate a property of explanation methods which is disconcerting for both of these purposes. Namely, we show that explanations can be manipulated arbitrarily by applying visually hardly perceptible perturbations to the input that keep the network's output approximately constant. We establish theoretically that this phenomenon can be related to certain geometrical properties of neural networks. This allows us to derive an upper bound on the susceptibility of explanations to manipulations. Based on this result, we propose effective mechanisms to enhance the robustness of explanations.
-
You Shouldn't Trust Me: Learning Models Which Conceal Unfairness From Multiple Explanation Methods
B. Dimanov et al. European Conference on Artificial Intelligence 2020
Transparency of algorithmic systems has been discussed as a way for end-users and regulators to develop appropriate trust in machine learning models. One popular approach, LIME [26], even suggests that model explanations can answer the question “Why should I trust you?” Here we show a straightforward method for modifying a pre-trained model to manipulate the output of many popular feature importance explanation methods with little change in accuracy, thus demonstrating the danger of trusting such explanation methods. We show how this explanation attack can mask a model’s discriminatory use of a sensitive feature, raising strong concerns about using such explanation methods to check model fairness. -
Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods
D. Slack et al. AAAI/ACM Conference on AI, Ethics, and Society 2020
As machine learning black boxes are increasingly being deployed in domains such as healthcare and criminal justice, there is growing emphasis on building tools and techniques for explaining these black boxes in an interpretable manner. Such explanations are being leveraged by domain experts to diagnose systematic errors and underlying biases of black boxes. In this paper, we demonstrate that post hoc explanations techniques that rely on input perturbations, such as LIME and SHAP, are not reliable. Specifically, we propose a novel scaffolding technique that effectively hides the biases of any given classifier by allowing an adversarial entity to craft an arbitrary desired explanation. Our approach can be used to scaffold any biased classifier in such a way that its predictions on the input data distribution still remain biased, but the post hoc explanations of the scaffolded classifier look innocuous. Using extensive evaluation with multiple real world datasets (including COMPAS), we demonstrate how extremely biased (racist) classifiers crafted by our framework can easily fool popular explanation techniques such as LIME and SHAP into generating innocuous explanations which do not reflect the underlying biases. -
“How do I fool you?": Manipulating User Trust via Misleading Black Box Explanations
H. Lakkaraju & O. Bastani AAAI/ACM Conference on AI, Ethics, and Society 2020
As machine learning black boxes are increasingly being deployed in critical domains such as healthcare and criminal justice, there has been a growing emphasis on developing techniques for explaining these black boxes in a human interpretable manner. There has been recent concern that a high-fidelity explanation of a black box ML model may not accurately reflect the biases in the black box. As a consequence, explanations have the potential to mislead human users into trusting a problematic black box. In this work, we rigorously explore the notion of misleading explanations and how they influence user trust in black box models. Specifically, we propose a novel theoretical framework for understanding and generating misleading explanations, and carry out a user study with domain experts to demonstrate how these explanations can be used to mislead users. Our work is the first to empirically establish how user trust in black box models can be manipulated via misleading explanations. -
Faking Fairness via Stealthily Biased Sampling
K. Fukuchi et al. AAAI Conference on Artificial Intelligence 2020
Auditing fairness of decision-makers is now in high demand. To respond to this social demand, several fairness auditing tools have been developed. The focus of this study is to raise an awareness of the risk of malicious decision-makers who fake fairness by abusing the auditing tools and thereby deceiving the social communities. The question is whether such a fraud of the decision-maker is detectable so that the society can avoid the risk of fake fairness. In this study, we answer this question negatively. We specifically put our focus on a situation where the decision-maker publishes a benchmark dataset as the evidence of his/her fairness and attempts to deceive a person who uses an auditing tool that computes a fairness metric. To assess the (un)detectability of the fraud, we explicitly construct an algorithm, the stealthily biased sampling, that can deliberately construct an evil benchmark dataset via subsampling. We show that the fraud made by the stealthily based sampling is indeed difficult to detect both theoretically and empirically. -
Sanity Checks for Saliency Metrics
R. Tomsett et al. AAAI Conference on Artificial Intelligence 2020
Saliency maps are a popular approach to creating post-hoc explanations of image classifier outputs. These methods produce estimates of the relevance of each pixel to the classification output score, which can be displayed as a saliency map that highlights important pixels. Despite a proliferation of such methods, little effort has been made to quantify how good these saliency maps are at capturing the true relevance of the pixels to the classifier output (i.e. their “fidelity”). We therefore investigate existing metrics for evaluating the fidelity of saliency methods (i.e. saliency metrics). We find that there is little consistency in the literature in how such metrics are calculated, and show that such inconsistencies can have a significant effect on the measured fidelity. Further, we apply measures of reliability developed in the psychometric testing literature to assess the consistency of saliency metrics when applied to individual saliency maps. Our results show that saliency metrics can be statistically unreliable and inconsistent, indicating that comparative rankings between saliency methods generated using such metrics can be untrustworthy. -
Fairwashing Explanations with Off-Manifold Detergent
C. J. Anderset et al. International Conference on Machine Learning 2020
Explanation methods promise to make black-box classifiers more transparent. As a result, it is hoped that they can act as proof for a sensible, fair and trustworthy decision-making process of the algorithm and thereby increase its acceptance by the end-users. In this paper, we show both theoretically and experimentally that these hopes are presently unfounded. Specifically, we show that, for any classifier g, one can always construct another classifier g' which has the same behavior on the data (same train, validation, and test error) but has arbitrarily manipulated explanation maps. We derive this statement theoretically using differential geometry and demonstrate it experimentally for various explanation methods, architectures, and datasets. Motivated by our theoretical insights, we then propose a modification of existing explanation methods which makes them significantly more robust. -
Black Box Attacks on Explainable Artificial Intelligence(XAI) methods in Cyber Security
A. Kuppa & N. A. Le-Khac International Joint Conference on Neural Networks 2020
Cybersecurity community is slowly leveraging Machine Learning (ML) to combat ever evolving threats. One of the biggest drivers for successful adoption of these models is how well domain experts and users are able to understand and trust their functionality. As these black-box models are being employed to make important predictions, the demand for transparency and explainability is increasing from the stakeholders. Explanations supporting the output of ML models are crucial in cyber security, where experts require far more information from the model than a simple binary output for their analysis. Recent approaches in the literature have focused on three different areas: (a) creating and improving explainability methods which help users better understand the internal workings of ML models and their outputs; (b) attacks on interpreters in white box setting; (c) defining the exact properties and metrics of the explanations generated by models. However, they have not covered, the security properties and threat models relevant to cybersecurity domain, and attacks on explainable models in black box settings. In this paper, we bridge this gap by proposing a taxonomy for Explainable Artificial Intelligence (XAI) methods, covering various security properties and threat models relevant to cyber security domain. We design a novel black box attack for analyzing the consistency, correctness and confidence security properties of gradient based XAI methods. We validate our proposed system on 3 security-relevant data-sets and models, and demonstrate that the method achieves attacker's goal of misleading both the classifier and explanation report and, only explainability method without affecting the classifier output. Our evaluation of the proposed approach shows promising results and can help in designing secure and robust XAI methods. -
Interpretable Deep Learning under Fire
X. Zhang et al. USENIX Security Symposium 2020
Providing explanations for deep neural network (DNN) models is crucial for their use in security-sensitive domains. A plethora of interpretation models have been proposed to help users understand the inner workings of DNNs: how does a DNN arrive at a specific decision for a given input? The improved interpretability is believed to offer a sense of security by involving human in the decision-making process. Yet, due to its data-driven nature, the interpretability itself is potentially susceptible to malicious manipulations, about which little is known thus far. Here we bridge this gap by conducting the first systematic study on the security of interpretable deep learning systems (IDLSes). We show that existing IDLSes are highly vulnerable to adversarial manipulations. Specifically, we present ADV2, a new class of attacks that generate adversarial inputs not only misleading target DNNs but also deceiving their coupled interpretation models. Through empirical evaluation against four major types of IDLSes on benchmark datasets and in security-critical applications (e.g., skin cancer diagnosis), we demonstrate that with ADV2 the adversary is able to arbitrarily designate an input's prediction and interpretation. Further, with both analytical and empirical evidence, we identify the prediction-interpretation gap as one root cause of this vulnerability -- a DNN and its interpretation model are often misaligned, resulting in the possibility of exploiting both models simultaneously. Finally, we explore potential countermeasures against ADV2, including leveraging its low transferability and incorporating it in an adversarial training framework. Our findings shed light on designing and operating IDLSes in a more secure and informative fashion, leading to several promising research directions. -
Remote explainability faces the bouncer problem
E. Le Merrer & G. Tredan Nature Machine Intelligence 2020
The concept of explainability is envisioned to satisfy society’s demands for transparency about machine learning decisions. The concept is simple: like humans, algorithms should explain the rationale behind their decisions so that their fairness can be assessed. Although this approach is promising in a local context (for example, the model creator explains it during debugging at the time of training), we argue that this reasoning cannot simply be transposed to a remote context, where a model trained by a service provider is only accessible to a user through a network and its application programming interface. This is problematic, as it constitutes precisely the target use case requiring transparency from a societal perspective. Through an analogy with a club bouncer (who may provide untruthful explanations upon customer rejection), we show that providing explanations cannot prevent a remote service from lying about the true reasons leading to its decisions. More precisely, we observe the impossibility of remote explainability for single explanations by constructing an attack on explanations that hides discriminatory features from the querying user. We provide an example implementation of this attack. We then show that the probability that an observer spots the attack, using several explanations for attempting to find incoherences, is low in practical settings. This undermines the very concept of remote explainability in general.

Defense from attacks on XAI
-
Adversarial Explanations for Understanding Image Classification Decisions and Improved NN Robustness
W. Woods et al. Nature Machine Intelligence 2019
For sensitive problems, such as medical imaging or fraud detection, Neural Network (NN) adoption has been slow due to concerns about their reliability, leading to a number of algorithms for explaining their decisions. NNs have also been found vulnerable to a class of imperceptible attacks, called adversarial examples, which arbitrarily alter the output of the network. Here we demonstrate both that these attacks can invalidate prior attempts to explain the decisions of NNs, and that with very robust networks, the attacks themselves may be leveraged as explanations with greater fidelity to the model. We show that the introduction of a novel regularization technique inspired by the Lipschitz constraint, alongside other proposed improvements, greatly improves an NN's resistance to adversarial examples. On the ImageNet classification task, we demonstrate a network with an Accuracy-Robustness Area (ARA) of 0.0053, an ARA 2.4x greater than the previous state of the art. Improving the mechanisms by which NN decisions are understood is an important direction for both establishing trust in sensitive domains and learning more about the stimuli to which NNs respond. -
On the (In)fidelity and Sensitivity of Explanations
C. K. Yeh et al. Advances in Neural Information Processing Systems 2019
We consider objective evaluation measures of saliency explanations for complex black-box machine learning models. We propose simple robust variants of two notions that have been considered in recent literature: (in)fidelity, and sensitivity. We analyze optimal explanations with respect to both these measures, and while the optimal explanation for sensitivity is a vacuous constant explanation, the optimal explanation for infidelity is a novel combination of two popular explanation methods. By varying the perturbation distribution that defines infidelity, we obtain novel explanations by optimizing infidelity, which we show to out-perform existing explanations in both quantitative and qualitative measurements. Another salient question given these measures is how to modify any given explanation to have better values with respect to these measures. We propose a simple modification based on lowering sensitivity, and moreover show that when done appropriately, we could simultaneously improve both sensitivity as well as fidelity. -
A simple defense against adversarial attacks on heatmap explanations
L. Rieger & L. K. Hansen ICML Workshop on Human Interpretability in Machine Learning 2020
With machine learning models being used for more sensitive applications, we rely on interpretability methods to prove that no discriminating attributes were used for classification. A potential concern is the so-called "fair-washing" - manipulating a model such that the features used in reality are hidden and more innocuous features are shown to be important instead. In our work we present an effective defence against such adversarial attacks on neural networks. By a simple aggregation of multiple explanation methods, the network becomes robust against manipulation. This holds even when the attacker has exact knowledge of the model weights and the explanation methods used.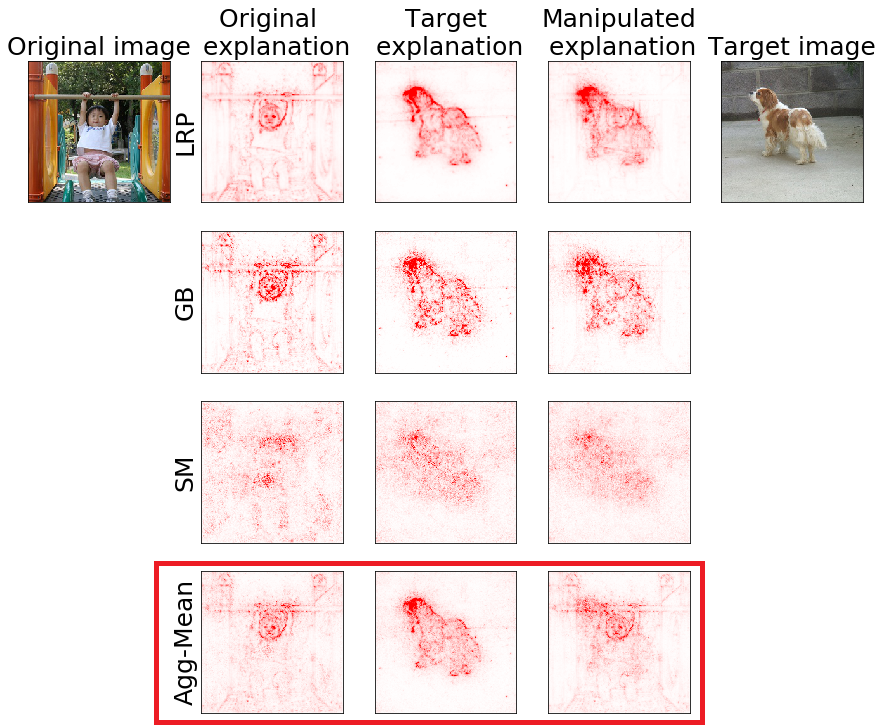
-
Proper Network Interpretability Helps Adversarial Robustness in Classification
A. Boopathy et al. International Conference on Machine Learning 2020
Recent works have empirically shown that there exist adversarial examples that can be hidden from neural network interpretability (namely, making network interpretation maps visually similar), or interpretability is itself susceptible to adversarial attacks. In this paper, we theoretically show that with a proper measurement of interpretation, it is actually difficult to prevent prediction-evasion adversarial attacks from causing interpretation discrepancy, as confirmed by experiments on MNIST, CIFAR-10 and Restricted ImageNet. Spurred by that, we develop an interpretability-aware defensive scheme built only on promoting robust interpretation (without the need for resorting to adversarial loss minimization). We show that our defense achieves both robust classification and robust interpretation, outperforming state-of-theart adversarial training methods against attacks of large perturbation in particular. -
Smoothed Geometry for Robust Attribution
Z. Wang et al. Advances in Neural Information Processing Systems 2020
Feature attributions are a popular tool for explaining the behavior of Deep Neural Networks (DNNs), but have recently been shown to be vulnerable to attacks that produce divergent explanations for nearby inputs. This lack of robustness is especially problematic in high-stakes applications where adversarially-manipulated explanations could impair safety and trustworthiness. Building on a geometric understanding of these attacks presented in recent work, we identify Lipschitz continuity conditions on models' gradient that lead to robust gradient-based attributions, and observe that smoothness may also be related to the ability of an attack to transfer across multiple attribution methods. To mitigate these attacks in practice, we propose an inexpensive regularization method that promotes these conditions in DNNs, as well as a stochastic smoothing technique that does not require re-training. Our experiments on a range of image models demonstrate that both of these mitigations consistently improve attribution robustness, and confirm the role that smooth geometry plays in these attacks on real, large-scale models. -
Aggregating explanation methods for stable and robust explainability
L. Rieger & L. K. Hansen arXiv preprint v5 2020
Despite a growing literature on explaining neural networks, no consensus has been reached on how to explain a neural network decision or how to evaluate an explanation. Our contributions in this paper are twofold. First, we investigate schemes to combine explanation methods and reduce model uncertainty to obtain a single aggregated explanation. We provide evidence that the aggregation is better at identifying important features, than on individual methods. Adversarial attacks on explanations is a recent active research topic. As our second contribution, we present evidence that aggregate explanations are much more robust to attacks than individual explanation methods.

Other
-
A Benchmark for Interpretability Methods in Deep Neural Networks
S. Hooker et al. Advances in Neural Information Processing Systems 2019
We propose an empirical measure of the approximate accuracy of feature importance estimates in deep neural networks. Our results across several large-scale image classification datasets show that many popular interpretability methods produce estimates of feature importance that are not better than a random designation of feature importance. Only certain ensemble based approaches---VarGrad and SmoothGrad-Squared---outperform such a random assignment of importance. The manner of ensembling remains critical, we show that some approaches do no better then the underlying method but carry a far higher computational burden. -
Evaluating Explanation Methods for Deep Learning in Security
A. Warnecke et al. IEEE European Symposium on Security and Privacy 2020
Deep learning is increasingly used as a building block of security systems. Unfortunately, neural networks are hard to interpret and typically opaque to the practitioner. The machine learning community has started to address this problem by developing methods for explaining the predictions of neural networks. While several of these approaches have been successfully applied in the area of computer vision, their application in security has received little attention so far. It is an open question which explanation methods are appropriate for computer security and what requirements they need to satisfy. In this paper, we introduce criteria for comparing and evaluating explanation methods in the context of computer security. These cover general properties, such as the accuracy of explanations, as well as security-focused aspects, such as the completeness, efficiency, and robustness. Based on our criteria, we investigate six popular explanation methods and assess their utility in security systems for malware detection and vulnerability discovery. We observe significant differences between the methods and build on these to derive general recommendations for selecting and applying explanation methods in computer security. -
Evaluating and Aggregating Feature-based Model Explanations
U. Bhatt et al. International Joint Conference on Artificial Intelligence 2020
A feature-based model explanation denotes how much each input feature contributes to a model's output for a given data point. As the number of proposed explanation functions grows, we lack quantitative evaluation criteria to help practitioners know when to use which explanation function. This paper proposes quantitative evaluation criteria for feature-based explanations: low sensitivity, high faithfulness, and low complexity. We devise a framework for aggregating explanation functions. We develop a procedure for learning an aggregate explanation function with lower complexity and then derive a new aggregate Shapley value explanation function that minimizes sensitivity. -
Debugging Tests for Model Explanations
J. Adebayo et al. Advances in Neural Information Processing Systems 2020
We investigate whether post-hoc model explanations are effective for diagnosing model errors–model debugging. In response to the challenge of explaining a model’s prediction, a vast array of explanation methods have been proposed. Despite increasing use, it is unclear if they are effective. To start, we categorize bugs, based on their source, into: data, model, and test-time contamination bugs. For several explanation methods, we assess their ability to: detect spurious correlation artifacts (data contamination), diagnose mislabeled training examples (data contamination), differentiate between a (partially) re-initialized model and a trained one (model contamination), and detect out-of-distribution inputs (test-time contamination). We find that the methods tested are able to diagnose a spurious background bug, but not conclusively identify mislabeled training examples. In addition, a class of methods, that modify the back-propagation algorithm are invariant to the higher layer parameters of a deep network; hence, ineffective for diagnosing model contamination. We complement our analysis with a human subject study, and find that subjects fail to identify defective models using attributions, but instead rely, primarily, on model predictions. Taken together, our results provide guidance for practitioners and researchers turning to explanations as tools for model debugging. -
Can We Trust Your Explanations? Sanity Checks for Interpreters in Android Malware Analysis
M. Fan et al. arXiv preprint v1 2020
With the rapid growth of Android malware, many machine learning-based malware analysis approaches are proposed to mitigate the severe phenomenon. However, such classifiers are opaque, non-intuitive, and difficult for analysts to understand the inner decision reason. For this reason, a variety of explanation approaches are proposed to interpret predictions by providing important features. Unfortunately, the explanation results obtained in the malware analysis domain cannot achieve a consensus in general, which makes the analysts confused about whether they can trust such results. In this work, we propose principled guidelines to assess the quality of five explanation approaches by designing three critical quantitative metrics to measure their stability, robustness, and effectiveness. Furthermore, we collect five widely-used malware datasets and apply the explanation approaches on them in two tasks, including malware detection and familial identification. Based on the generated explanation results, we conduct a sanity check of such explanation approaches in terms of the three metrics. The results demonstrate that our metrics can assess the explanation approaches and help us obtain the knowledge of most typical malicious behaviors for malware analysis.
Software
...
...
Further related
Attacks on AI using XAI
-
On the Privacy Risks of Model Explanations
R. Shokri et al. arXiv preprint v5 2020
Privacy and transparency are two key elements of trustworthy machine learning. Model explanations can provide more insight into a model's decisions on input data. This, however, can impose a significant privacy risk to the model's training set. We analyze whether an adversary can exploit model explanations to infer sensitive information about the model's training set. We investigate this research problem primarily using membership inference attacks: inferring whether a data point belongs to the training set of a model given its explanations. We study this problem for three popular types of model explanations: backpropagation-based, perturbation-based and example-based attribution methods. We devise membership inference attacks based on these model explanations, and extensively test them on a variety of datasets. We show that both backpropagation- and example-based explanations can leak a significant amount of information about individual data points in the training set. More importantly, we design reconstruction attacks against example-based model explanations, and use them to recover significant parts of the training set. Finally, we discuss the resistance of perturbation-based attribution methods to existing attack models; interestingly, their resistance to such attacks is related to a crucial shortcoming of such model explanations uncovered by recent works.
Defense from attacks on AI using XAI
-
When Explainability Meets Adversarial Learning: Detecting Adversarial Examples using SHAP Signatures
G. Fidel et al. International Joint Conference on Neural Networks 2020
State-of-the-art deep neural networks (DNNs) are highly effective in solving many complex real-world problems. However, these models are vulnerable to adversarial perturbation attacks, and despite the plethora of research in this domain, to this day, adversaries still have the upper hand in the cat and mouse game of adversarial example generation methods vs. detection and prevention methods. In this research, we present a novel detection method that uses Shapley Additive Explanations (SHAP) values computed for the internal layers of a DNN classifier to discriminate between normal and adversarial inputs. We evaluate our method by building an extensive dataset of adversarial examples over the popular CIFAR-10 and MNIST datasets, and training a neural network-based detector to distinguish between normal and adversarial inputs. We evaluate our detector against adversarial examples generated by diverse state-of-the-art attacks and demonstrate its high detection accuracy and strong generalization ability to adversarial inputs generated with different attack methods. -
Explainable AI for Inspecting Adversarial Attacks on Deep Neural Networks
Z. Klawikowska et al. International Conference on Artificial Intelligence and Soft Computing 2020
Deep Neural Networks (DNN) are state of the art algorithms for image classification. Although significant achievements and perspectives, deep neural networks and accompanying learning algorithms have some important challenges to tackle. However, it appears that it is relatively easy to attack and fool with well-designed input samples called adversarial examples. Adversarial perturbations are unnoticeable for humans. Such attacks are a severe threat to the development of these systems in critical applications, such as medical or military systems. Hence, it is necessary to develop methods of counteracting these attacks. These methods are called defense strategies and aim at increasing the neural model’s robustness against adversarial attacks. In this paper, we reviewed the recent findings in adversarial attacks and defense strategies. We also analyzed the effects of attacks and defense strategies applied, using the local and global analyzing methods from the family of explainable artificial intelligence. - Contributions are welcome
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].