Audio-Classification-using-CNN-MLP
Multi class audio classification using Deep Learning (CNN, MLP)
Citation
If you find this project helpful, please cite as below:
@software{vishal_sharma_2020_3988690,
author = {Vishal Sharma},
title = {{vishalshar/Audio-Classification-using-CNN-MLP:
first release}},
month = Aug,
year = 2020,
publisher = {Zenodo},
version = {v1.0.0},
doi = {10.5281/zenodo.3988690},
url = {https://doi.org/10.5281/zenodo.3988690}
}
Project Objectives:
The objective of this project is to build a multi class classifier to identify sound of a bee, cricket or noise.
Dataset Description:
Given dataset contains total of 9,914 audio sample, where 3,300 belongs to Bee, 3,500 belongs to Cricket and 3,114 belongs to noise. Each audio sample is approximately about 2 sec long and has 44,100 amplitude samples/sec. Given dataset was merged and experiments were performed on 80%-20% split.
| Bee | Cricket | Noise | Total | |
|---|---|---|---|---|
| Train | 2,402 | 3,000 | 2,180 | 7,582 |
| Test | 898 | 500 | 934 | 2,332 |
| 3,300 | 3,500 | 3,114 | 9,914 |
Audio Data Preprocessing:
Audio dataset given has very high frame rate, on an average every file had 80,000 frames (amplitude/sec). With frames/sec being so high we have a lot of data and it needs some preprocessing. Reduction of audio frame rate and length was performed using interpolation technique. The audio sample was reduced to 15k sample and total length of 22,000 (approximately 1/4 reduction of the given audio).

Using ANN
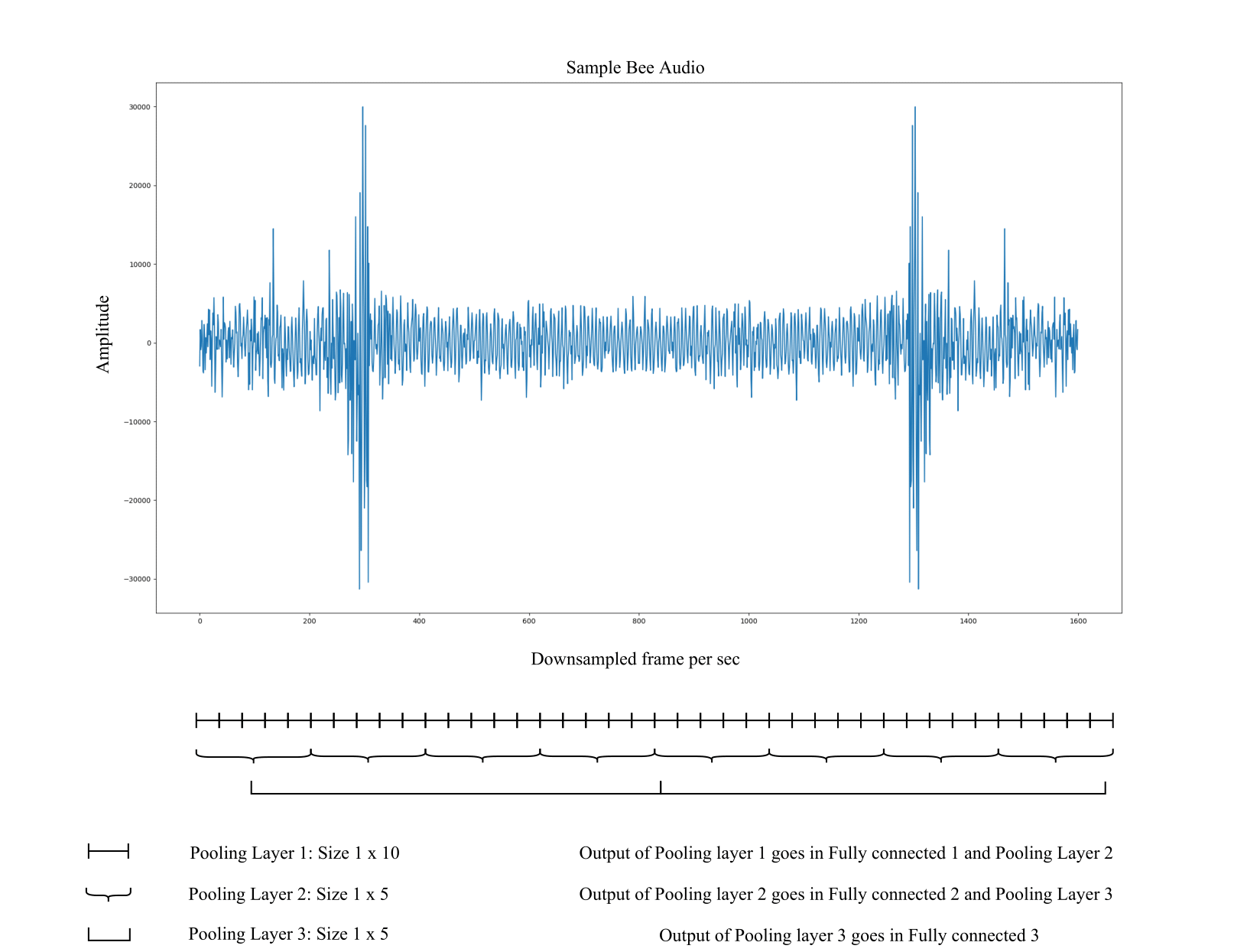
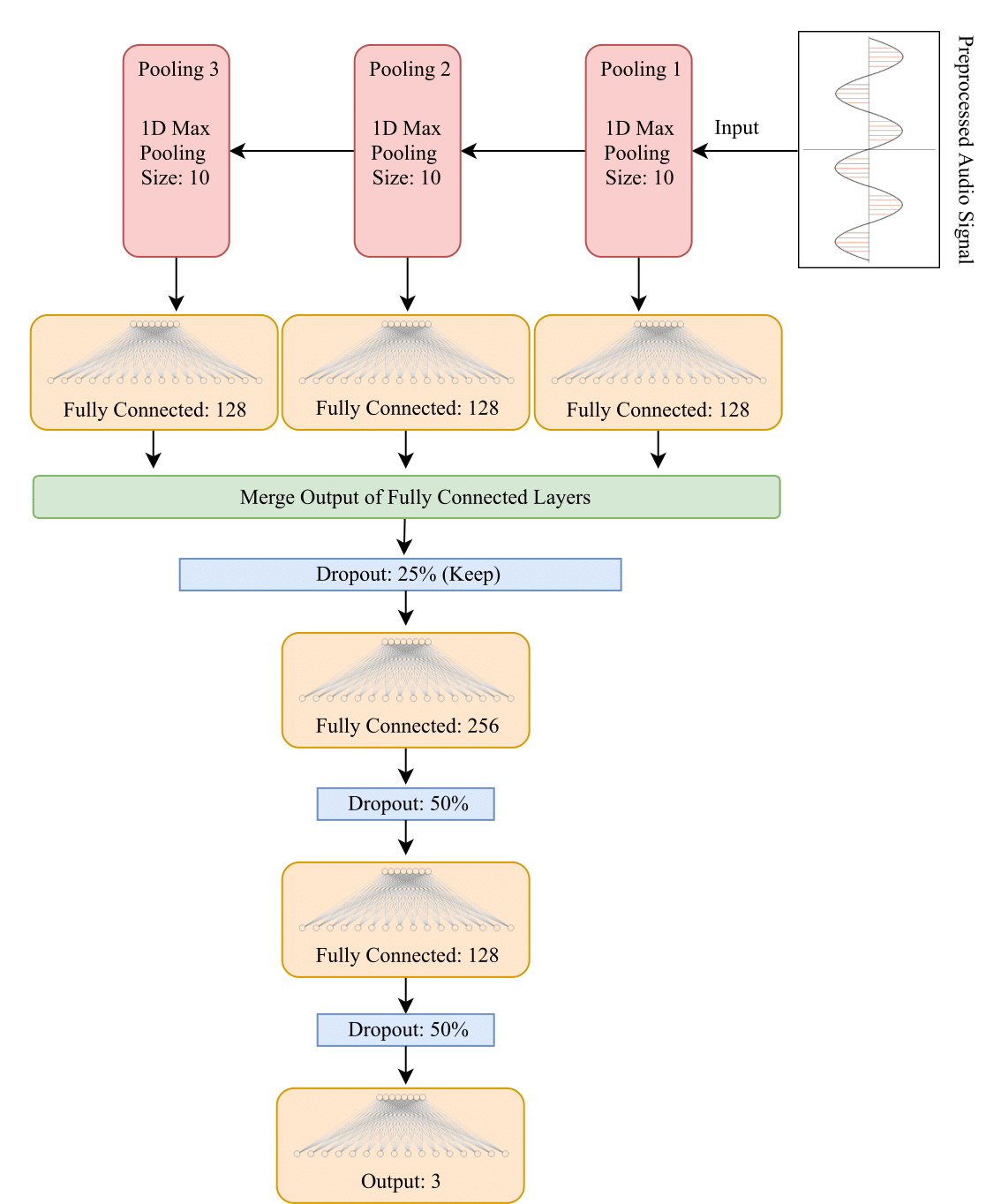
During initial experiments ANN was not performing good and later after several experiments a Multi Layer Perceptron (MLP) model was build based on intuition of CNN. Before we feed audio data in network it was max pooled in 3 different layers and output of pooled layers was given input to the fully connected layers as shows in below figure. To merge features extracted from different pooling layers output of fully connected layer was merged.
Core Idea:
Sample Bee Audio and expected feature extraction using pooling layers and merging fully connected layers
Performance:
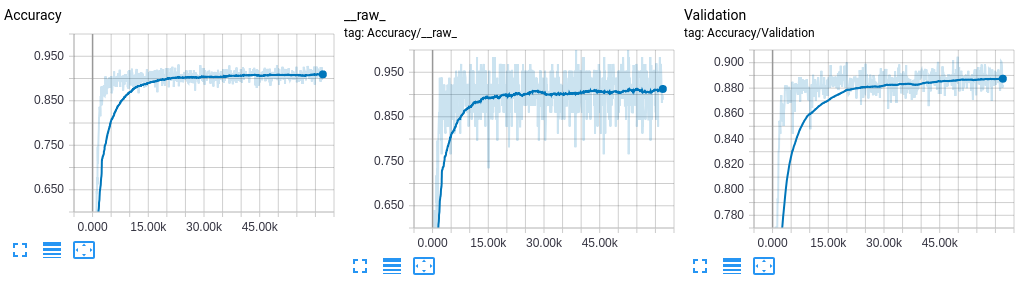
Training was done for 500 epochs using Adaptive Moment Estimation (adam) as optimizer with learning rate of 0.0005. Figure 9 displays accuracy during training.
| Training | Testing | |
|---|---|---|
| Accuracy | 91.11% | 88.25% |
Citation
If you find this project helpful, please cite as below:
@software{vishal_sharma_2020_3988690,
author = {Vishal Sharma},
title = {{vishalshar/Audio-Classification-using-CNN-MLP:
first release}},
month = aug,
year = 2020,
publisher = {Zenodo},
version = {v1.0.0},
doi = {10.5281/zenodo.3988690},
url = {https://doi.org/10.5281/zenodo.3988690}
}
Accuracy
Using CNN
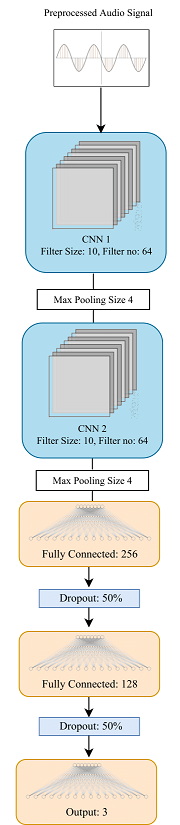
A network using Convolution layers was used to build classifier, network architecture is shown in Fig 6. The number of filters for both convolution was 64 and filter_size was 10 and 3 for respective layers followed by 3 fully connected layers, details about activation function used is in code. Max pooling was used after each convolution layer. During training over fitting was observed, to handle that dropout of 50% (keep) was used after first two fully connected layers and also ‘L2’ regularization was added to both layers. Input length was fixed as 22,000 with 1 channel. During training it was also observed, without downsampling data model was not able to generalize well between bee and noise data. Adding downsampling technique helped the model in generalization.
Performance:
Training was done for 500 epochs using Adaptive Moment Estimation (adam) as optimizer with learning rate of 0.0001.
| Training | Testing | |
|---|---|---|
| Accuracy | 99.88% | 99.45% |