Enterprise Data Warehousing is a key workload for all types of customers - from small startups through to the largest enterprises. It differs from a Data Lake solution in several key ways, but is most commonly run alongside a Data Lake to support fast end user queries on well understood data. Key characteristics of an Enterprise Data Warehousing workload include:
- Data sources are typically highly structured, and most commonly from application databases
- Query response times are expected to be less than 1 second for most queries
- Data access is primarily performed via SQL
- Data volumes are expected to be tens or hundreds of Terabytes, with the largest systems at Petabyte scale
- Data in the warehouse should be as up-to-date as possible, but in many cases may only be refreshed on an hourly or nightly basis
- Data transformation may be performed within the warehouse, both from source to target models, as well as for data cleansing, governance, and standardisation
There are also typically some constraints to an Enterprise Data Warehouse, which may or may not apply to your use case:
- Data must typically be modelled before loading into the data warehouse, though flexibility of the data model can be a key differentiator between services
- Data warehouses are typically not exposed to application front ends, websites, or mobile apps for consumption by an unlimited number of users
Amazon Redshift is a fast, fully managed parallel data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. It allows you to run complex analytic queries against petabytes of structured data, using sophisticated query optimization, columnar storage on high-performance local disks, and massively parallel query execution. When combined with other AWS purpose-built services for analytics, you can implement a scalable and powerful Enterprise Data Warehouse that meets the demands of a vareity of different types of users.
This repository provides you with an overview of the most common data, deployment, and reference architectures that we see built by customers with the Redshift service. Redshift is extremely flexible, and able to be run both within VPC and in EC2 Classic networking environments. These reference architectures only assume that you run the service within VPC, which offers significant security, simplicity, and performance benefits over non-VPC deployments. We start with data architectures that work well for analytics, then cover simple deployment models, and then move to other types of use cases and data integrations.
Data Architectures
Star Schema
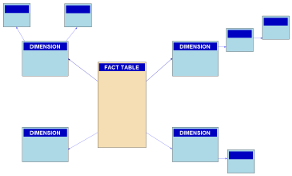 |
Star schema offers a powerful ability to perform multi-dimensional analysis of vast structured datasets. Star schemas are simple to use with a variety of industry standard data tools, and are extremely performant on Redshift. |
ODS & Aggregation Models
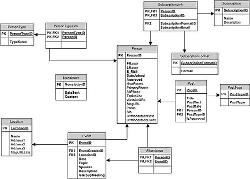 |
Many Enterprise Data Warehouses copy all source application databases onto a single platform where reporting can be easily done across system lines, and where simple aggregations of business data can be calculated. This architecture shows you how to build an 'all-your-data-in-one-place' model. |
Deployment Architectures
Because AWS Services are designed to work together, most AWS services are consistent in how they are deployed, and you don't have to make many architectural decisions to ge the service online. However, you do have to decide how to structure your Virtual Private Cloud (VPC) network, and where services reside within it. The following architectures provide common patterns for how customers deploy an Enterprise Data Warehouse within their networking environment to achieve their goals for security, connectivity, and performance.
Simple, Single DW with Public Routing
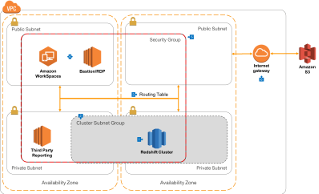 |
This the most basic architecture that we recommend to be used with Amazon Redshift. It uses direct public routing, or alternatively can offer routing via SSH proxies. Click the thumbnail for more information. |
Single DW with Private (DirectConnect) Routing
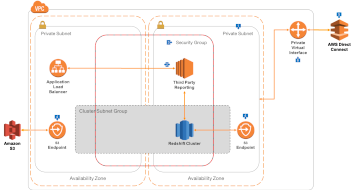 |
This is perhaps the most common deployment architecture for Redshift clusters - deployed within private subnets in VPC that are only accessible over private, leased lines, through DirectConnect. |
Architectures for Scaling
Redshift supports horizontal scaling by adding and removing nodes from a cluster. It providers the Workload Management System to provide workload prioritisation and control. In some cases, you may wish to provide multiple clusters across your user base to provide for specific SLA's or isolation characteristics.
Multiple Business Line Warehouses
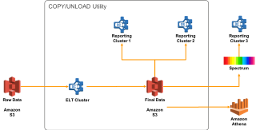 |
It's extremely common that you want to expose Data Warehouse data to different types of customers, and often the customers have unique data sets that also include common reference data. This architecture shows how you can use a centralised ETL cluster and then use export/import or Redshift Spectrum to create targeted Data Warehouses or Marts for a variety of use cases. |
Redshift Spectrum based Multi-Warehouse
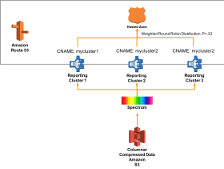 |
Similar to the idea of having separate clusters for different business units within your business, this architecture shows how you can share data among an unlimited number of different clusters via Redshift Spectrum, while also enabling services like Amazon Athena and AWS Glue. |
Low Latency Hybrid Warehousing
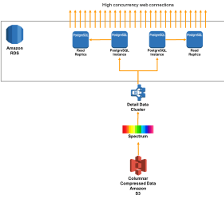 |
In some cases, you'll want to expose data from the Data Warehouse to applications and websites that require many thousands of concurrent users with millisecond latency. In these cases, it can be useful to use Amazon Aurora Postgres as a 'cache' of business metrics in front of a given Redshift Data Warehouse. |
Data Warehousing Workflow Integration
Amazon Redshift can integrate with a variety of other AWS services for the purposes of data ingestion, reporting & visualisation, or workflow and process management. The following architectures can enable this integration.
Data Loading with Kinesis Firehose
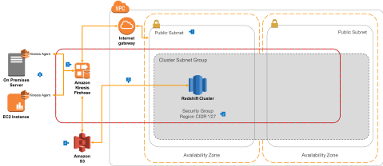 |
Data to be ingested into a data warehouse is often file based, but can also be based on streaming sources such as application logs. Kinesis Firehose provides powerful integration to load this data automatically into your data lake and data warehouse |
Connecting with AWS Lambda
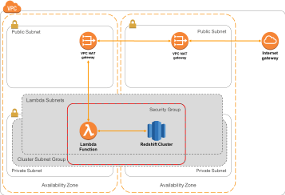 |
AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume - there is no charge when your code is not running. AWS Lambda can be used as a powerful workflow or compute engine with data, and connecting to Redshift is simple and easy. |
Data Visualisation with Quicksight
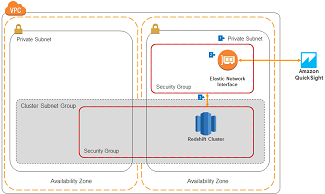 |
Amazon Quicksight is a powerful data visualisation and business intelligence service that is serverless, and fully managed in the cloud. It provides the ability to create your first visualisation in as little as 60 seconds, and provides simple integration with a variety of AWS analytics services, including Redshift. |
License Summary
This sample code is made available under a modified MIT license. See the LICENSE file.