


 Bias Detector
Bias Detector
Bias Detector is a python package for detecting gender/race bias in binary classification models.
Based on first and last name/zip code the package analyzes the probability of the user belonging to different genders/races. Then, the model predictions per gender/race are compared using various bias metrics.
Using this package you will be able to gain insight into whether your model is biased or not, and if so, how much bias was found.
The Bias Detector is based on statistical data from the US, and therefore it performs best with US originated data. However, it is possible to optimize the package for other countries by adding the relevant statistical information. If you have such data, you can open a Pull Request to add it to the package.
If you have any questions please let us know. You can learn more about our research here.
Supported Metrics
There are many metrics which can possibly be used to detect Bias, we currently support the following three:
- Statistical Parity - tests whether the probability of 2 groups to be classified as belonging to the positive class by the model is equal.
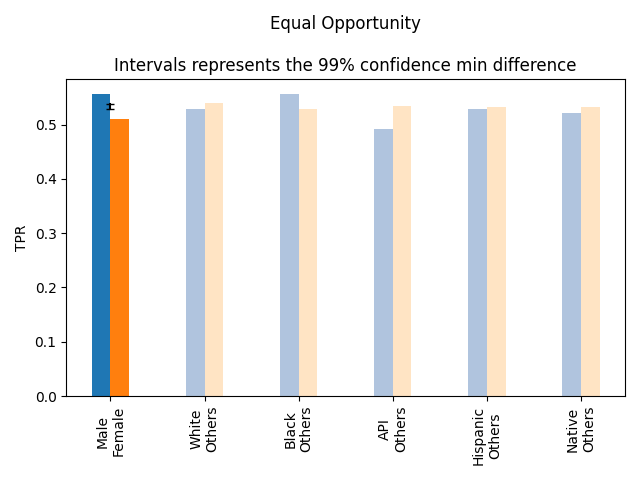
- Equal Opportunity - tests whether the True Positive Rates of 2 groups are equal (how likely is the model to predict correctly the positive class for each group).
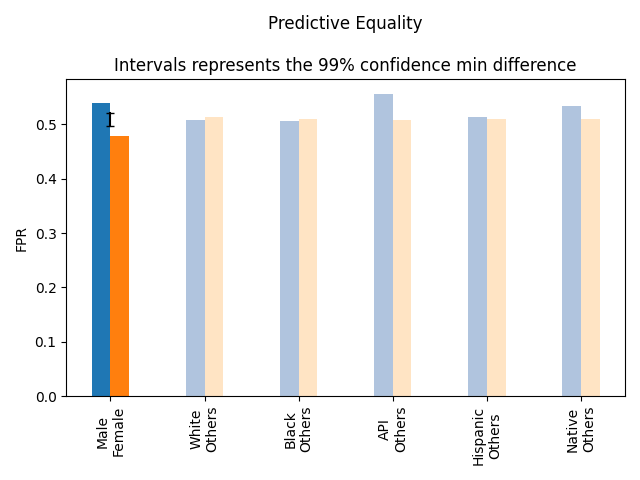
- Predictive Equality - tests whether there False Positive Rates of 2 groups are equal (how likely is the model to predict incorrectly the positive class for each group).
Usage
Install the package
!pip install bias-detector
Create a bias detector instance:
from bias_detector.BiasDetector import BiasDetector
bias_detector = BiasDetector(country='US')
Generate bias report:
bias_report = bias_detector.get_bias_report(first_names=first_names, last_names=last_names, zip_codes=zip_codes, y_true=y_true, y_pred=y_pred)
Visualize the bias report:
bias_report.plot_summary()

bias_report.print_summary()
- Statistical Parity: We observed the following statistically significant differences (𝛼=0.01):
- P(pred=1|Male)-P(pred=1|Female)=0.55-0.49=0.053±0.026 (p-value=1e-07)
- Equal Opportunity: We observed the following statistically significant differences (𝛼=0.01):
- TPRMale-TPRFemale=0.56-0.51=0.047±0.036 (p-value=0.00097)
- Predictive Equality: We observed the following statistically significant differences (𝛼=0.01):
- FPRMale-FPRFemale=0.54-0.48=0.06±0.036 (p-value=2e-05)
bias_report.plot_groups()
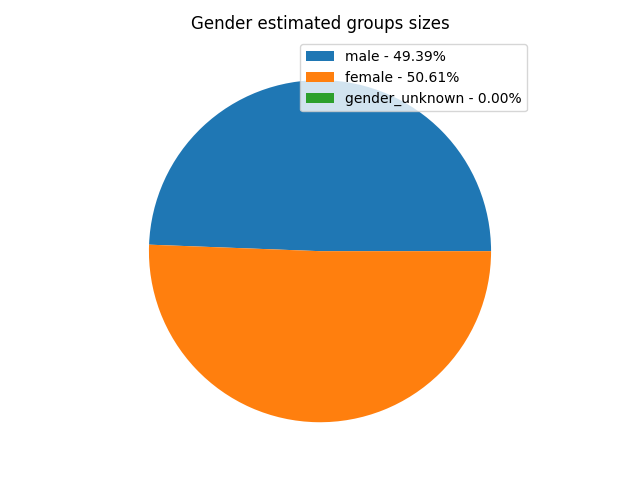
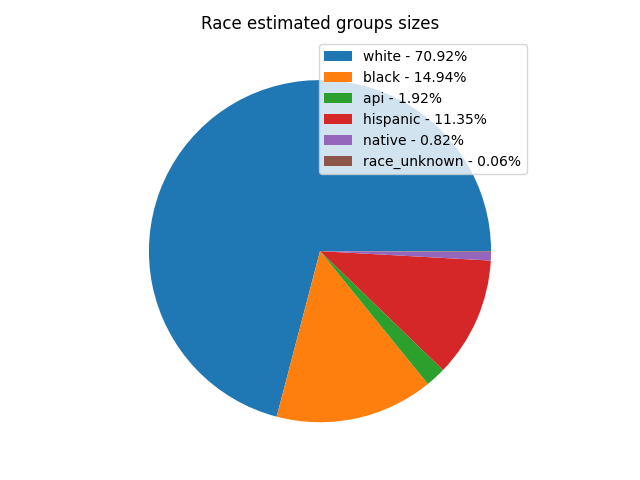
Show gender/race correlation with model features:
bias_detector.get_features_groups_correlation(first_names=first_names, last_names=last_names, zip_codes=zip_codes, features=features)
Sample output from the Titanic demo:
| male_correlation | female_correlation | white_correlation | black_correlation | api_correlation | hispanic_correlation | native_correlation | |
|---|---|---|---|---|---|---|---|
| ticket_class | -0.243730 | 0.010038 | -0.122978 | -0.152287 | 0.128161 | -0.003452 | -0.029846 |
| age | 0.234712 | -0.168692 | 0.165937 | -0.059513 | -0.044503 | -0.058893 | 0.036010 |
| num_of_siblings_or_spouses_aboard | 0.027651 | 0.025737 | 0.029292 | 0.066896 | -0.061708 | -0.072092 | 0.138135 |
| num_of_parents_or_children_aboard | 0.057575 | 0.042770 | 0.048623 | 0.099354 | -0.064993 | -0.100496 | 0.064185 |
| fare | 0.053703 | 0.071300 | 0.076330 | 0.061158 | -0.001893 | -0.067631 | 0.058121 |
| embarked_Cherbourg | -0.073627 | -0.013599 | -0.093890 | -0.075407 | -0.007720 | 0.124144 | -0.020478 |
| embarked_Queenstown | -0.019206 | 0.169752 | 0.110737 | -0.049664 | -0.049379 | 0.011407 | -0.054550 |
| embarked_Southampton | 0.082538 | -0.090631 | 0.011149 | 0.100265 | 0.038108 | -0.116438 | 0.050909 |
| sex_female | -0.327044 | 0.615262 | 0.047330 | 0.073640 | -0.051959 | 0.074259 | 0.011737 |
| sex_male | 0.327044 | -0.615262 | -0.047330 | -0.073640 | 0.051959 | -0.074259 | -0.011737 |
Fuzzy extraction of first/last names from emails:
bias_detector.fuzzily_get_emails_full_names(emails)
This method will return a DataFrame with first_name and last_name columns fuzzily extracted from the users emails. Note that the accuracy of this method varies between emails and data sets.
Sample output for synthetic emails:
| first_name | last_name | |
|---|---|---|
| [email protected] | holley | beverly |
| [email protected] | adrienne | brewer |
| [email protected] | craig | reed |
| [email protected] | henry | battaglia |
| [email protected] | paget | |
| [email protected] | briana | |
| [email protected] | pena | |
| [email protected] | jacka | |
| [email protected] | mattie | |
| [email protected] | patricia | calder |
Contributing
See CONTRIBUTING.md.
References
- Elhanan Mishraky, Aviv Ben Arie, Yair Horesh, Shir Meir Lador, 2021. Bias Detection by Using Name Disparity Tables Across Protected Groups, DOI: 10.1016/j.jrt.2021.100020
- Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, Aram Galstyan, 2019. A Survey on Bias and Fairness in Machine Learning.
- Moritz Hardt, Eric Price, Nathan Srebro, 2016. Equality of Opportunity in Supervised Learning.
- Ioan Voicu (2018) Using First Name Information to Improve Race and Ethnicity Classification, Statistics and Public Policy, 5:1, 1-13, DOI: 10.1080/2330443X.2018.1427012