myungsub / Cain
Source code for AAAI 2020 paper "Channel Attention Is All You Need for Video Frame Interpolation"
Stars: ✭ 166
Programming Languages
python
139335 projects - #7 most used programming language
Projects that are alternatives of or similar to Cain
Quickdraw Appendix
Dataset of 25k penises: an appendix to the Quick, Draw! Dataset
Stars: ✭ 153 (-7.83%)
Mutual labels: dataset
Weihanli.npoi
NPOI Extensions, excel/csv importer/exporter for IEnumerable<T>/DataTable, fluentapi(great flexibility)/attribute configuration
Stars: ✭ 157 (-5.42%)
Mutual labels: dataset
Dspp Keras
Protein order and disorder data for Keras, Tensor Flow and Edward frameworks with automated update cycle made for continuous learning applications.
Stars: ✭ 160 (-3.61%)
Mutual labels: dataset
Evoskeleton
Official project website for the CVPR 2020 paper (Oral Presentation) "Cascaded Deep Monocular 3D Human Pose Estimation With Evolutionary Training Data"
Stars: ✭ 154 (-7.23%)
Mutual labels: dataset
Gta Im Dataset
[ECCV-20] 3D human scene interaction dataset: https://people.eecs.berkeley.edu/~zhecao/hmp/index.html
Stars: ✭ 157 (-5.42%)
Mutual labels: dataset
Pytorch Nlp
Basic Utilities for PyTorch Natural Language Processing (NLP)
Stars: ✭ 1,996 (+1102.41%)
Mutual labels: dataset
Music Dance Video Synthesis
(ACM MM 20 Oral) PyTorch implementation of Self-supervised Dance Video Synthesis Conditioned on Music
Stars: ✭ 150 (-9.64%)
Mutual labels: dataset
Pandas Datareader
Extract data from a wide range of Internet sources into a pandas DataFrame.
Stars: ✭ 2,183 (+1215.06%)
Mutual labels: dataset
Rt gene
RT-GENE: Real-Time Eye Gaze and Blink Estimation in Natural Environments
Stars: ✭ 157 (-5.42%)
Mutual labels: dataset
Nlp bahasa resources
A Curated List of Dataset and Usable Library Resources for NLP in Bahasa Indonesia
Stars: ✭ 158 (-4.82%)
Mutual labels: dataset
Isic Archive Downloader
A script to download the ISIC Archive of lesion images
Stars: ✭ 153 (-7.83%)
Mutual labels: dataset
Snape
Snape is a convenient artificial dataset generator that wraps sklearn's make_classification and make_regression and then adds in 'realism' features such as complex formating, varying scales, categorical variables, and missing values.
Stars: ✭ 155 (-6.63%)
Mutual labels: dataset
Motion Sense
MotionSense Dataset for Human Activity and Attribute Recognition ( time-series data generated by smartphone's sensors: accelerometer and gyroscope)
Stars: ✭ 159 (-4.22%)
Mutual labels: dataset
Awesome Biomechanics
A curated, public list collecting resources for biomechanics and human motion: datasets, processing tools, software for simulation, educational videos, lectures, etc.
Stars: ✭ 154 (-7.23%)
Mutual labels: dataset
Sweetie Data
This repo contains logstash of various honeypots
Stars: ✭ 163 (-1.81%)
Mutual labels: dataset
Maskedface Net
MaskedFace-Net is a dataset of human faces with a correctly and incorrectly worn mask based on the dataset Flickr-Faces-HQ (FFHQ).
Stars: ✭ 152 (-8.43%)
Mutual labels: dataset
Omr Datasets
Collection of datasets used for Optical Music Recognition
Stars: ✭ 158 (-4.82%)
Mutual labels: dataset
Venmo Data
Venmo trasaction dataset for data analysis/visualization/anything
Stars: ✭ 164 (-1.2%)
Mutual labels: dataset
Whylogs Java
Profile and monitor your ML data pipeline end-to-end
Stars: ✭ 164 (-1.2%)
Mutual labels: dataset
Reuters Full Data Set
Full dataset of Reuters composed of 8,551,441 news titles, links and timestamps (Jan 2007 - Aug 2016). Generate your own up to today!
Stars: ✭ 159 (-4.22%)
Mutual labels: dataset
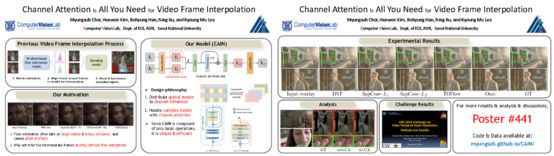
Channel Attention Is All You Need for Video Frame Interpolation
Myungsub Choi, Heewon Kim, Bohyung Han, Ning Xu, Kyoung Mu Lee
2nd place in [AIM 2019 ICCV Workshop] - Video Temporal Super-Resolution Challenge
Project | Paper-AAAI (Download the paper [here] in case the AAAI link is broken) | Poster

Directory Structure
project
│ README.md
| run.sh - main script to train CAIN model
| run_noca.sh - script to train CAIN_NoCA model
| test_custom.sh - script to run interpolation on custom dataset
| eval.sh - script to evaluate on SNU-FILM benchmark
| main.py - main file to run train/val
| config.py - check & change training/testing configurations here
| loss.py - defines different loss functions
| utils.py - misc.
└───model
│ │ common.py
│ │ cain.py - main model
| | cain_noca.py - model without channel attention
| | cain_encdec.py - model with additional encoder-decoder
└───data - implements dataloaders for each dataset
│ | vimeo90k.py - main training / testing dataset
| | video.py - custom data for testing
│ └───symbolic links to each dataset
| | ...
Dependencies
Current version is tested on:
- Ubuntu 18.04
- Python==3.7.5
- numpy==1.17
- PyTorch==1.3.1, torchvision==0.4.2, cudatoolkit==10.1
- tensorboard==2.0.0 (If you want training logs)
- opencv==3.4.2
- tqdm==4.39.0
# Easy installation (using Anaconda environment)
conda create -n cain
conda activate cain
conda install python=3.7
conda install pip numpy
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
conda install tqdm opencv tensorboard
Model

Dataset Preparation
- We use Vimeo90K Triplet dataset for training + testing.
- After downloading the full dataset, make symbolic links in
data/folder :ln -s /path/to/vimeo_triplet_data/ ./data/vimeo_triplet
- Then you're done!
- After downloading the full dataset, make symbolic links in
- For more thorough evaluation, we built SNU-FILM (SNU Frame Interpolation with Large Motion) benchmark.
- Download links can be found in the project page.
- Also make symbolic links after download :
ln -s /path/to/SNU-FILM_data/ ./data/SNU-FILM
- Done!
Usage
Training / Testing with Vimeo90K dataset
- First make symbolic links in
data/folder :ln -s /path/to/vimeo_triplet_data/ ./data/vimeo_triplet - For training:
CUDA_VISIBLE_DEVICES=0 python main.py --exp_name EXPNAME --batch_size 16 --test_batch_size 16 --dataset vimeo90k --model cain --loss 1*L1 --max_epoch 200 --lr 0.0002 - Or, just run
./run.sh - For testing performance on Vimeo90K dataset, just add
--mode testoption - For testing on SNU-FILM dataset, run
./eval.sh- Testing mode (choose from ['easy', 'medium', 'hard', 'extreme']) can be modified by changing
--test_modeoption ineval.sh.
- Testing mode (choose from ['easy', 'medium', 'hard', 'extreme']) can be modified by changing
Interpolating with custom video
- Download pretrained models from [Here]
- Prepare frame sequences in
data/frame_seq - run
test_custom.sh
Results

Video
Citation
If you find this code useful for your research, please consider citing the following paper:
@inproceedings{choi2020cain,
author = {Choi, Myungsub and Kim, Heewon and Han, Bohyung and Xu, Ning and Lee, Kyoung Mu},
title = {Channel Attention Is All You Need for Video Frame Interpolation},
booktitle = {AAAI},
year = {2020}
}
Acknowledgement
Many parts of this code is adapted from:
We thank the authors for sharing codes for their great works.
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].