CogNet: a large-scale, high-quality cognate database for 338 languages
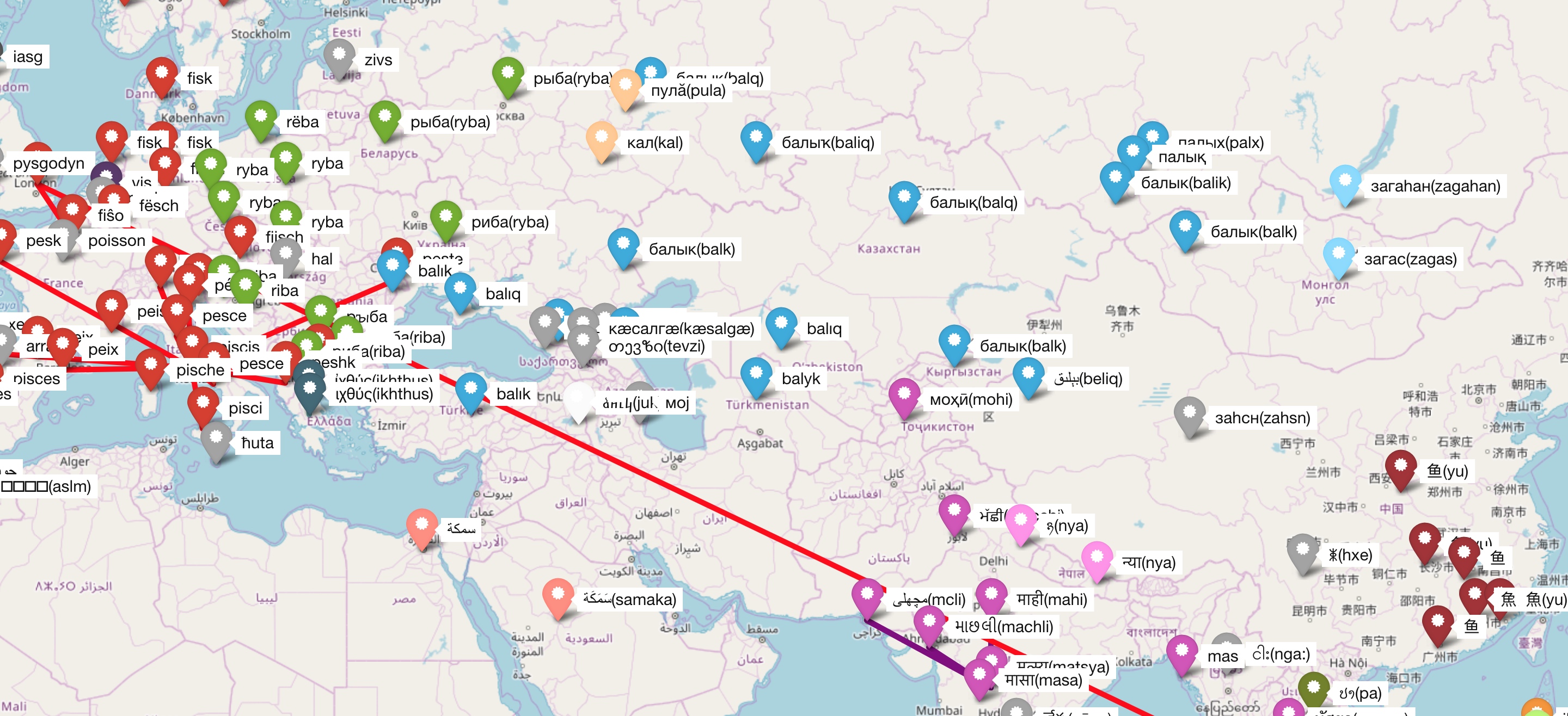
CogNet is a large-scale database of cognate pairs: CogNet v2 contains 8.1 million cognates in 338 languages, 38 writing systems, and 91285 concepts. Its quality is manually evaulated at 94% precision. It was automatically constructed from wordnets and dictionaries contained within the UKC resource, as described in our paper. For 37 different orthographies of 338 languages, we used the Wiktionary tranlisteration, WikTra, developed by Wiktionary linguists and developers.
UKC resource is at http://ukc.disi.unitn.it, and more details of CogNet is at http://cognet.ukc.disi.unitn.it/
Why cognates are important?
In Computational Linguistics: improve the cross-lingual NLP tasks, e.g., word translation, bilingual lexicon induction, cross-lingual knowledge transfer.
How can I explore cognate data?
Besides downloading the entire CogNet as a structured text file, you can also use the Linguarena website to display and browse (currently an older version of) cognate data interactively on a world map, as also shown in the figure above. The fish example is on this link
CogNet Format
Each line represents one instance of a pair of cognate words. Columns are separated by TAB.
| Column | Description |
|---|---|
| concept id | A code used by Princeton WordNet 3.0 to represent a meaning (called a synset) |
| language 1 | the 3-letter iso code for the first language |
| word 1 | a word in the language 1 |
| language 2 | the 3-letter iso code for the second language |
| word 2 | a word in the language 2 |
| transliteration 1 | a romanized word for the first word |
| tranlisteration 2 | a romanized word for the second word |
For example,
| concept id | lang 1 | word 1 | lang 2 | word 2 | translit 1 | translit 2 |
|---|---|---|---|---|---|---|
| n14996158 | glg | polipropileno | jpn | ポリプロピレン | - | poripuropiren |
| n06566077 | nep | सफ्टवेर | kas | سافٹویٚیَر | saphtawera | saftoeyar |
| n07062058 | eng | song | jpn | ソング | - | songu |
| n02506148 | cmn | 象 | mon | заан | xiang | zaan |
License
This tool is available under the Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) License. Read more about this license from https://creativecommons.org/licenses/by-nc-sa/4.0/.
References
Please cite the following articles if you find this resource useful:
Khuyagbaatar Batsuren, Gábor Bella, and Fausto Giunchiglia – CogNet: A large-scale cognate database, Proceedings of The 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019. https://aclweb.org/anthology/papers/P/P19/P19-1302/
Khuyagbaatar Batsuren, Gábor Bella, and Fausto Giunchiglia - A large and evolving cognate database. Lang Resources & Evaluation (2021). https://doi.org/10.1007/s10579-021-09544-6
Acknowledgements
Thanks to Global Wordnet Association (GWA) and all the wordnet developers. http://globalwordnet.org/resources/wordnets-in-the-world/