Major updates are coming in the immediate future. Please watch this space.
CUDA implementation of the LATCH descriptor & brute-force matcher
This is a high performance GPU implementation of the LATCH descriptor invented by Gil Levi and Tal Hassner. Please reference: "LATCH: Learned Arrangements of Three Patch Codes", IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, March, 2016.
You should probably be looking at the OpenMVG branch which includes this code.
On a GTX 970M I see 10^6 descriptor extractions per second (1 to 1.2 microseconds per descriptor), and 3*10^9 comparisons per second. A GTX 760 sees 70% of this speed. NVidia graphics card with CUDA compute capability >=3.0 required.
Look at min.cpp for a minimal introduction. Compile it with "make min -j7". Run it as "./min 1.png 2.png" (Note, min.cpp is broken. Take a look at vo.cpp instead or the OpenMVG class.)
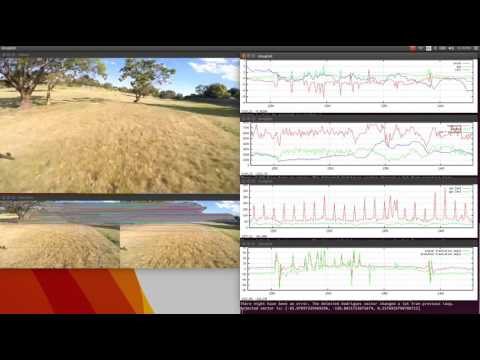
vo.cpp has a better example of how you can hide 100% of the processing time of the GPU. The quickest way to see it in action is to install "youtube-dl" and then run "make demo -j7". Or you could just watch this video: https://www.youtube.com/watch?v=zmfLZY7T6Qg I see cumulative 43ms of CPU overhead for GPU processing of 4250 frames of 1080p video.
Note that currently each descriptor is 2048 bits but the last 1536 bits are 0. I was originally planning on building larger variants: true 1024 bit and 2048 bit LATCH descriptors. You can relatively easily adjust this down to 1024 bits by changing defines, but refactoring is necessary for 512 bits.
Current features:
- hardware interpolation for affine invariant descriptors at virtually no performance overhead
- customizable importance masking for patch triplet comparisons at no performance overhead
- asynchronous GPU operation
- fast cross-checking (symmetry test) with event-driven multi-stream matching kernel
Approximate order of planned features:
- multichannel support ( http://arxiv.org/abs/1603.04408 )
- extractor kernel granularity optimization (possibly increased extractor speed)
- documentation
- 512 bit matcher (increased matcher speed)
- API improvements (currently a mess)
- CUDA implementation of adaptive grid FAST detector
- offline parameter optimization with PyGMO
- integration into OpenCV
Multi-GPU support is not currently planned. Please contact me if you have a use case that requires it.
This work is released under a Creative Commons Attribution-ShareAlike license. If you use this code in an academic work, please cite me by name (Christopher Parker) and link to this repository.
Please email me if you have any questions: [email protected]