The Open Source Deep Learning Glossary
Deep learning terminology can be difficult and overwhelming, especially to newcomers. This glossary tries to define the most commonly used terms.
Since terminology is constantly changing with new terms appearing every day this glossary will be in a permanent work in progress. Feel free to edit or suggest new terms using issues and pull requests.
Table of Contents
- Activation function
- Affine layer
- Attention mechanism
- Autoencoder
- Average-Pooling
- Backpropagation
- Batch
- Batch normalization
- Bias
- Bias term
- Capsule Network
- Convolution Neural Network (CNN)
- Data augmentation
- Dropout
- Epoch
- Exploding gradient
- Feed-forward
- Gradient Recurrent Unit (GRU)
- Graph Convolutional Network (GCN)
- Generative Adversarial Network (GAN)
- Kernel
- Layer
- Loss function
- Learning rate
- Long Short-Term Memory (LSTM)
- Max-Pooling
- Multi Layer Perceptron (MLP)
- Pooling
- Pytorch
- Receptive field
- Recurrent Neural Network (RNN)
- Relational reasoning
- ReLU
- Residual Networks (ResNet)
- Siamese Neural Network
- Tensorflow
- Vanishing gradient
Activation function
Activation functions live inside neural network layers and modify the data they receive before passing it to the next layer. Activation functions give neural networks their power — allowing them to model complex non-linear relationships. By modifying inputs with non-linear functions neural networks can model highly complex relationships between features.
Commonly used functions include tanh, ReLU (Rectified Linear Unit), sigmoid, softmax, and variants of these.
Affine layer
A fully-connected layer in a Neural Network. Affine means that each neuron in the previous layer is connected to each neuron in the current layer. In many ways, this is the “standard” layer of a Neural Network. Affine layers are often added on top of the outputs of Convolutional Neural Networks or Recurrent Neural Networks before making a final prediction. An affine layer is typically of the form y = f(Wx + b) where x are the layer inputs, W the parameters, b a bias vector, and f a nonlinear activation function
Attention mechanism
Attention Mechanisms are inspired by human visual attention, the ability to focus on specific parts of an image. Attention mechanisms can be incorporated in both Language Processing and Image Recognition architectures to help the network learn what to “focus” on when making predictions.
Autoencoder
An Autoencoder is a Neural Network model whose goal is to predict the input itself, typically through a “bottleneck” somewhere in the network. By introducing a bottleneck, we force the network to learn a lower-dimensional representation of the input, effectively compressing the input into a good representation. Autoencoders are related to PCA and other dimensionality reduction techniques, but can learn more complex mappings due to their nonlinear nature. A wide range of autoencoder architectures exist, including Denoising Autoencoders, Variational Autoencoders, or Sequence Autoencoders.
Average-Pooling
Average-Pooling is a pooling technique used in Convolutional Neural Networks for Image Recognition. It works by sliding a window over patches of features, such as pixels, and taking the average of all values within the window. It compresses the input representation into a lower-dimensional representation.
Backpropagation
Backpropagation is an algorithm to efficiently calculate the gradients in a Neural Network, or more generally, a feedforward computational graph. It boils down to applying the chain rule of differentiation starting from the network output and propagating the gradients backward. The first uses of backpropagation go back to Vapnik in the 1960’s, but Learning representations by back-propagating errors is often cited as the source.
Batch
We can’t pass the entire dataset into the neural net at once. So, we divide dataset into Number of Batches or sets or parts.
Just like we divide a big article into multiple sets/batches/parts like Introduction, Gradient descent, Epoch, Batch size and Iterations which makes it easy to read the entire article for the reader and understand it.
Batch normalization
Batch Normalization is a technique that normalizes layer inputs per mini-batch. It accelerates convergence by reducing internal covariate shift inside each batch. If the individual observations in the batch are widely different, the gradient updates will be choppy and take longer to converge.
Batch Normalization has been found to be very effective for Convolutional and Feedforward Neural Networks but hasn’t been successfully applied to Recurrent Neural Networks.
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Batch Normalized Recurrent Neural Networks
- Machine Learning Glossary: Batch Normalization
Bias
What is the average difference between your predictions and the correct value for that observation?
- Low bias could mean every prediction is correct. It could also mean half of your predictions are above their actual values and half are below, in equal proportion, resulting in low average difference.
- High bias (with low variance) suggests your model may be underfitting and you’re using the wrong architecture for the job.
Bias term
Bias terms are additional constants attached to neurons and added to the weighted input before the activation function is applied. Bias terms help models represent patterns that do not necessarily pass through the origin. For example, if all your features were 0, would your output also be zero? Is it possible there is some base value upon which your features have an effect? Bias terms typically accompany weights and must also be learned by your model.
Capsule Network
A Capsule Neural Network (CapsNet) is a machine learning system that is a type of artificial neural network (ANN) that can be used to better model hierarchical relationships. The approach is an attempt to more closely mimic biological neural organization.
The idea is to add structures called "capsules" to a convolutional neural network (CNN), and to reuse output from several of those capsules to form more stable (with respect to various perturbations) representations for higher capsules. The output is a vector consisting of the probability of an observation, and a pose for that observation. This vector is similar to what is done for example when doing classification with localization in CNNs.
CNN
A CNN uses convolutions to connected extract features from local regions of an input. Most CNNs contain a combination of convolutional, pooling and affine layers. CNNs have gained popularity particularly through their excellent performance on visual recognition tasks, where they have been setting the state of the art for several years.
- Stanford CS231n class – Convolutional Neural Networks for Visual Recognition
- Understanding Convolutional Neural Networks for NLP
Data augmentation
Having more data (dataset / samples) is a best way to get better consistent estimators. In the real world getting a large volume of useful data for training a model is cumbersome and labelling is an extremely tedious task.
Either labelling requires more manual annotation, example - For creating a better image classifier we can use Mturk and involve more man power to generate dataset or doing survey in social media and asking people to participate and generate dataset. Above process can yield good dataset however those are difficult to carry and expensive. Having small dataset will lead to the well know Over fitting problem.
Data Augmentation is one of the interesting regularization technique to resolve the above problem. The concept is very simple, this technique generates new training data from given original dataset. Dataset Augmentation provides a cheap and easy way to increase the amount of your training data.
Dropout
Dropout is a regularization technique for Neural Networks that prevents overfitting. It prevents neurons from co-adapting by randomly setting a fraction of them to 0 at each training iteration. Dropout can be interpreted in various ways, such as randomly sampling from an exponential number of different networks. Dropout layers first gained popularity through their use in CNNs, but have since been applied to other layers, including input embeddings or recurrent networks.
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting
- Recurrent Neural Network Regularization
Epoch
An epoch describes the number of times the algorithm sees the entire data set.
Exploding gradient
The Exploding Gradient Problem is the opposite of the Vanishing Gradient Problem. In Deep Neural Networks gradients may explode during backpropagation, resulting number overflows. A common technique to deal with exploding gradients is to perform Gradient Clipping or using LeakyReLU activation function.
Feed-forward
Be the first to contribute!
GRU
The Gated Recurrent Unit is a simplified version of an LSTM unit with fewer parameters. Just like an LSTM cell, it uses a gating mechanism to allow RNNs to efficiently learn long-range dependency by preventing the vanishing gradient problem. The GRU consists of a reset and update gate that determine which part of the old memory to keep vs. update with new values at the current time step.
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
- Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano
GCN
Be the first to contribute!
GAN
Be the first to contribute!
Kernel
Be the first to contribute!
Layer
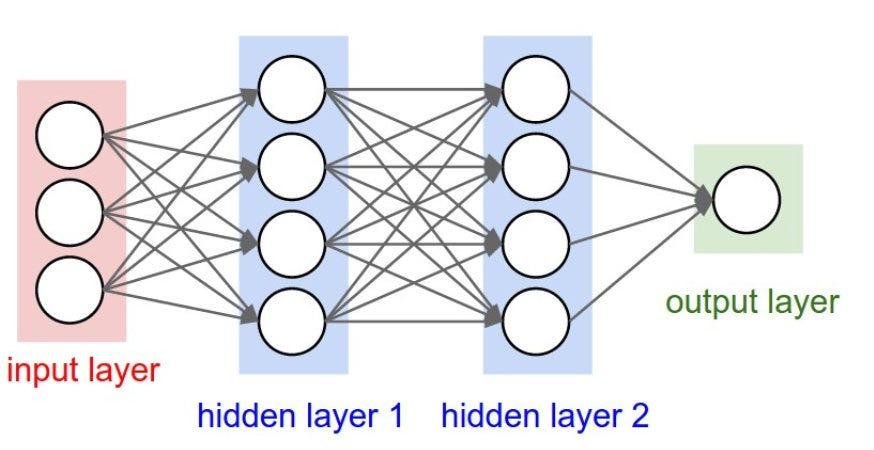
Input Layer
Holds the data your model will train on. Each neuron in the input layer represents a unique attribute in your dataset (e.g. height, hair color, etc.).
Hidden Layer
Sits between the input and output layers and applies an activation function before passing on the results. There are often multiple hidden layers in a network. In traditional networks, hidden layers are typically fully-connected layers — each neuron receives input from all the previous layer’s neurons and sends its output to every neuron in the next layer. This contrasts with how convolutional layers work where the neurons send their output to only some of the neurons in the next layer.
Output Layer
The final layer in a network. It receives input from the previous hidden layer, optionally applies an activation function, and returns an output representing your model’s prediction.
Learning rate
The size of the steps on Gradient descent is called the learning rate. With a high learning rate we can cover more ground each step, but we risk overshooting the lowest point since the slope of the hill is constantly changing. With a very low learning rate, we can confidently move in the direction of the negative gradient since we are recalculating it so frequently. A low learning rate is more precise, but calculating the gradient is time-consuming, so it will take us a very long time to get to the bottom.
Loss function
A loss function, or cost function, is a wrapper around our model’s predict function that tells us “how good” the model is at making predictions for a given set of parameters. The loss function has its own curve and its own derivatives. The slope of this curve tells us how to change our parameters to make the model more accurate! We use the model to make predictions. We use the cost function to update our parameters. Our cost function can take a variety of forms as there are many different cost functions available. Popular loss functions include: MSE (L2) and Cross-entropy Loss.
LSTM
Be the first to contribute!
Max-Pooling
A pooling operations typically used in Convolutional Neural Networks. A max-pooling layer selects the maximum value from a patch of features. Just like a convolutional layer, pooling layers are parameterized by a window (patch) size and stride size. For example, we may slide a window of size 2×2 over a 10×10 feature matrix using stride size 2, selecting the max across all 4 values within each window, resulting in a new 5×5 feature matrix.
Pooling layers help to reduce the dimensionality of a representation by keeping only the most salient information, and in the case of image inputs, they provide basic invariance to translation (the same maximum values will be selected even if the image is shifted by a few pixels). Pooling layers are typically inserted between successive convolutional layers.
MLP
Be the first to contribute!
Pooling
Pooling layers often take convolution layers as input. A complicated dataset with many object will require a large number of filters, each responsible finding pattern in an image so the dimensionally of convolutional layer can get large. It will cause an increase of parameters, which can lead to over-fitting. Pooling layers are methods for reducing this high dimensionally. Just like the convolution layer, there is kernel size and stride. The size of the kernel is smaller than the feature map. For most of the cases the size of the kernel will be 2X2 and the stride of 2. There are mainly two types of pooling layers, Max-Pooling and Average-Pooling.
Pytorch
Be the first to contribute!
Receptive field
Be the first to contribute!
RNN
Be the first to contribute!
Relational reasoning
Be the first to contribute!
ReLU
Be the first to contribute!
ResNet
Be the first to contribute!
Siamese Neural Network
Be the first to contribute!
Tensorflow
Be the first to contribute!
Vanishing gradient
The vanishing gradient problem arises in very deep Neural Networks, typically Recurrent Neural Networks, that use activation functions whose gradients tend to be small (in the range of 0 from 1). Because these small gradients are multiplied during backpropagation, they tend to “vanish” throughout the layers, preventing the network from learning long-range dependencies. Common ways to counter this problem is to use activation functions like ReLUs that do not suffer from small gradients, or use architectures like LSTMs that explicitly combat vanishing gradients. The opposite of this problem is called the exploding gradient problem.