get_jobs
- 利用线程池,协程,异步的方式,爬取各大招聘网站的数据(招聘数据,非简历等个人隐私数据)
声明:
其自身并不是招聘平台,仅供个人学习使用,本人严格保证遵纪守法,不以爬虫的手段侵害他人网络服务器,且保证爬取到的数据永远不以商业形式售卖
二次开发者请遵纪守法,且爬到的数据不管数据是否有价值永远不以商业形式售卖,否则后果自负
更新进度:
-
2019/9/19更新:
- 解决高并发下请求目标url的有效性,保证尽可能多的爬取数据
- 有效躲避反爬机制检测
- 优化断点续爬功能
- 优化已知的小bug
- 去掉不必要的代码/注释
- 增加目标url爬取完毕后立即退出的功能,节省资源,节省时间
-
2019/9/15更新:
- 优化协程并发问题
- 优化断点续爬功能
- 优化已知的小bug
- 优化斗米网数据抓取的部分
- 优化中华英才网的爬取部分
-
2019/9/12更新:
- 支持定时自动存储数据
- 添加日志
- 优化断点续爬功能
-
2019/9/11更新:
- 优化页码问题,去除无效(不必要)的页码,节省爬取时间
- 支持断点续爬功能
- 优化爬取时间,以协程,线程池,线程池+异步的三种方式提升速度(可以自行选择不同的运行方式)
简介:
-
利用爬虫技术抓取各大平台的招聘数据,然后存储到服务器的数据库内,用于学术分析
-
已抓取以下招聘平台的公开数据(对以下网站并无恶意,以学术研究分析为目的)
- 看准网
- boss直聘
- 前程无忧
- 智联招聘
- 智联卓聘
- 拉钩
- 大街网
- 智通人才网
- 中国人才热线
- 应届生求职网
- 卓博人才
- 教师招聘网
- 中国教师人才网
- 百姓网招聘
- 智通硕博网
- 猎聘
- 赶集招聘
- 赶集招聘it类
- 58招聘
- 中华英才网新版
- 中华英才网旧版
- 一览英才网
- 领英
- 斗米
- 工作虫
- OFweek人才网
- 通信人才网
- 天南地北人才网
- 网招天下人才网
- 前程人才网
- pcb人才网
- 百度百聘全职类
- 百度百聘兼职类
- (更多待增加......)
-
程序流程图
主要功能:
-
爬虫部分:
- 整个流程中使用requests实现网络交互请求
- 已带上伪造的UA请求头
- 建立一个IP代理池配合使用,且IP代理实现每天自动更新,自动检测有效性
- 根据不同的网站DOM结构进行分发处理,分别筛选出有用的数据
- 使用线程池ThreadPoolExecutor,以及gevent协程加速并发爬取
- 破解反爬机制:登录账户,验证码,滑动验证码,图形验证码
- 记录爬取过程中的异常日志
- 爬取各大招聘网站的数据,去重去异常
- 使用Apscheduler定时任务框架自动定时存储数据
-
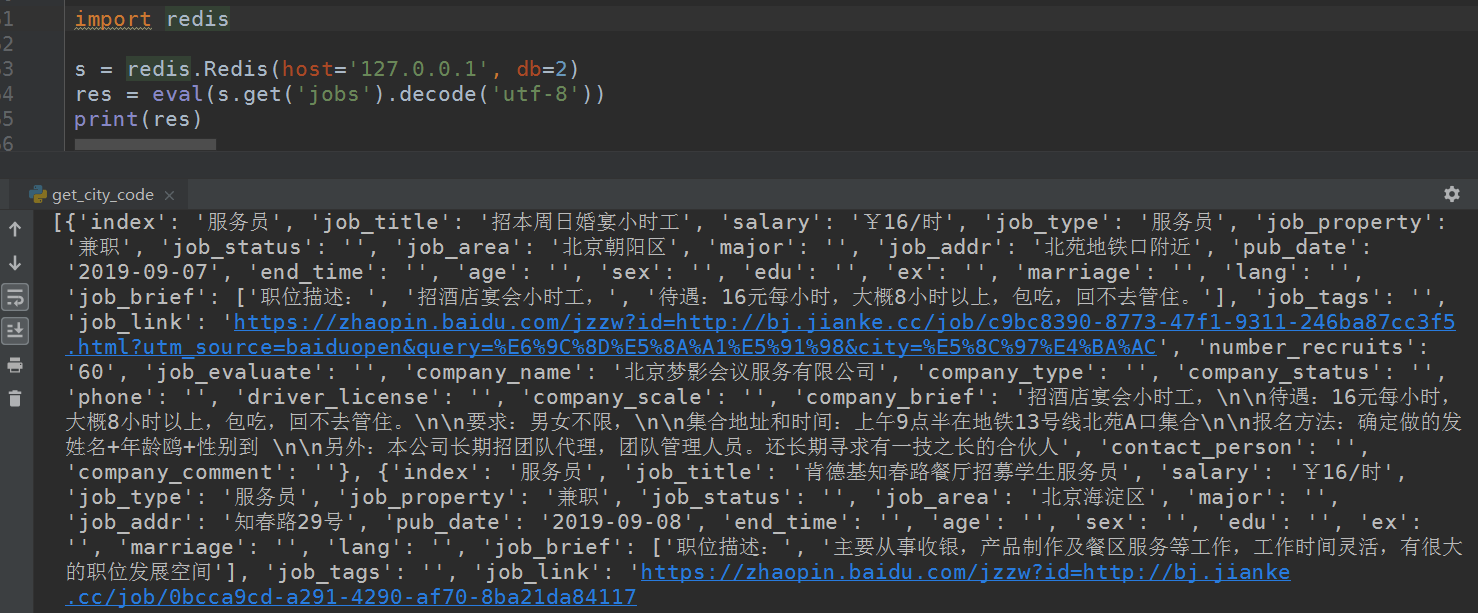
爬取的数据存入mongodb或者redis数据库内
待更新功能:
- 后期考虑借用elasticsearch做数据索引
开发环境:
-
Python3.7
-
lxml
-
gevent
-
beautifulsoup
-
mysql/mongodb/redis
-
进入根目录,使用
pip install -r requirements.txt安装相关模块或包 -
注:可能有忘掉的模块,如果提示未安装某个第三方包或模块,自行安装即可
文件说明:
- │ config.py # 配置文件
- │ v1.py # 主程序文件
- │ logger.py # 日志文件
- │ init.py │
- │─proxy # 代理相关文件夹
- │ │ headers.py # 请求头文件
- │ │ main.py # flask入口文件
- │ │ proxy.py # 爬取代理主程序文件
- │ └─ init.py
- │
- │
- └─log # 日志文件夹
- └─ crawling.log # 存入的日志文件
运行说明/步骤:
-
1.自行配置redis数据库,如果不想用redis数据库可自行修改其他数据库
-
2。在运行v1.py文件之前,请使用浏览器访问boss直聘网,利用抓包工具将__zp_stoken__字段拿到,替换掉config.py里的__zp_stoken__字段即可(因为boss直聘更新,目前暂时未找到boss直聘的token来源,希望有能力的老哥可以解决这个问题)
-
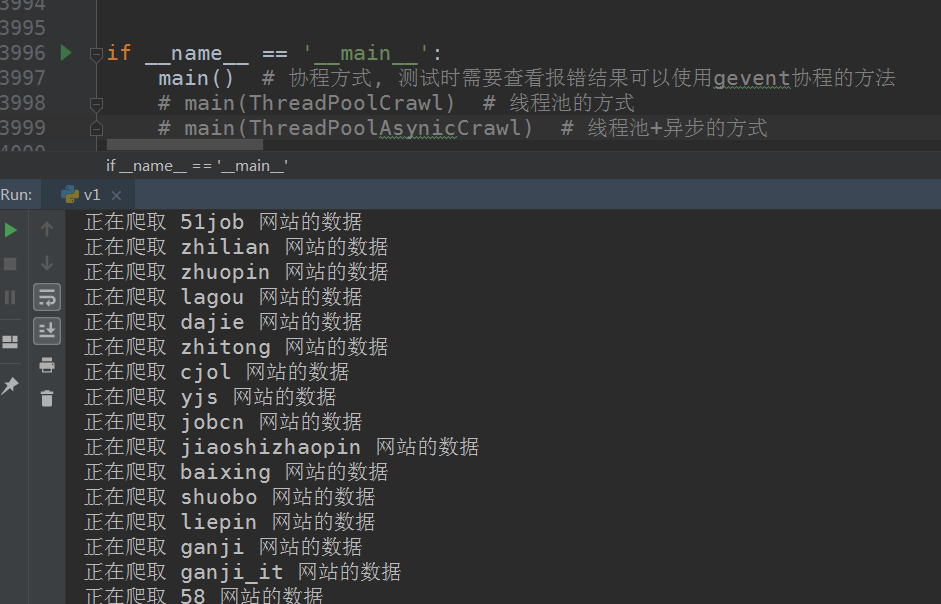
3.直接运行v1.py文件即可,其有三种运行方式:
- main() # 协程方式, 测试时需要查看报错结果可以使用gevent协程的方法
- main(ThreadPoolCrawl) # 线程池的方式
- main(ThreadPoolAsynicCrawl) # 线程池+异步的方式
默认是协程方式,建议选用线程池+异步的方式,需要用哪种方式取消该注释即可
-
4.如果需要解决IP封禁问题:先进入proxy文件夹,运行proxy.py爬取好代理并组成代理池,再运行v1.py文件即可
- 在带上代理并运行v1.py文件时,如果不想在程序每次运行都检测代理可用性,可以把proxy.py文件的get_redis函数的检测代理部分注释掉(文件第1103行,默认已注释)
-
更多配置说明请自行阅读config.py的文件说明,支持自定制,自添加,二次开发(再次强调,请遵纪手法,否则后果自负)
-
如果有问题请提交issue,有空我会更新
相关报错/提示:
-
“UserWarning: libuv only supports millisecond timer resolution; all times less will be set to 1 ms self.timer = get_hub().loop.timer(seconds or 0.0, ref=ref, priority=priority)”
- 这是一个gevent的已知bug,对程序运行没有任何影响,可以忽略
-
Run time of job "save_redis (trigger: interval[0:00:15], next run at: 2019-09-15 11:28:59 CST)" was missed by 0:00:01.461780 或者 Execution of job "save_redis (trigger: interval[0:00:15], next run at: 2019-09-15 13:11:44 CST)" skipped: maximum number of running instances reached (1)
- 这是apscheduler定时框架在存储时的计时机制导致的,在程序启动之前就开始计时,直到目标任务结束就是一个间隔时间,配置文件里设置的30秒存一次数据(可以自定义修改),如果中途某个函数因为某个原因运行时间过长,超过30秒就会有以上提示,不影响整个程序,因为还会在下一个30秒后存储数据,保证数据不丢失
-
报内存错误 MemorryError
- 这个问题是由于数据量太大导致内存不足错误,在配置文件congfig.py里减少搜索关键词,减少爬取深度的页码,扩大你的电脑的虚拟内存(自行百度)
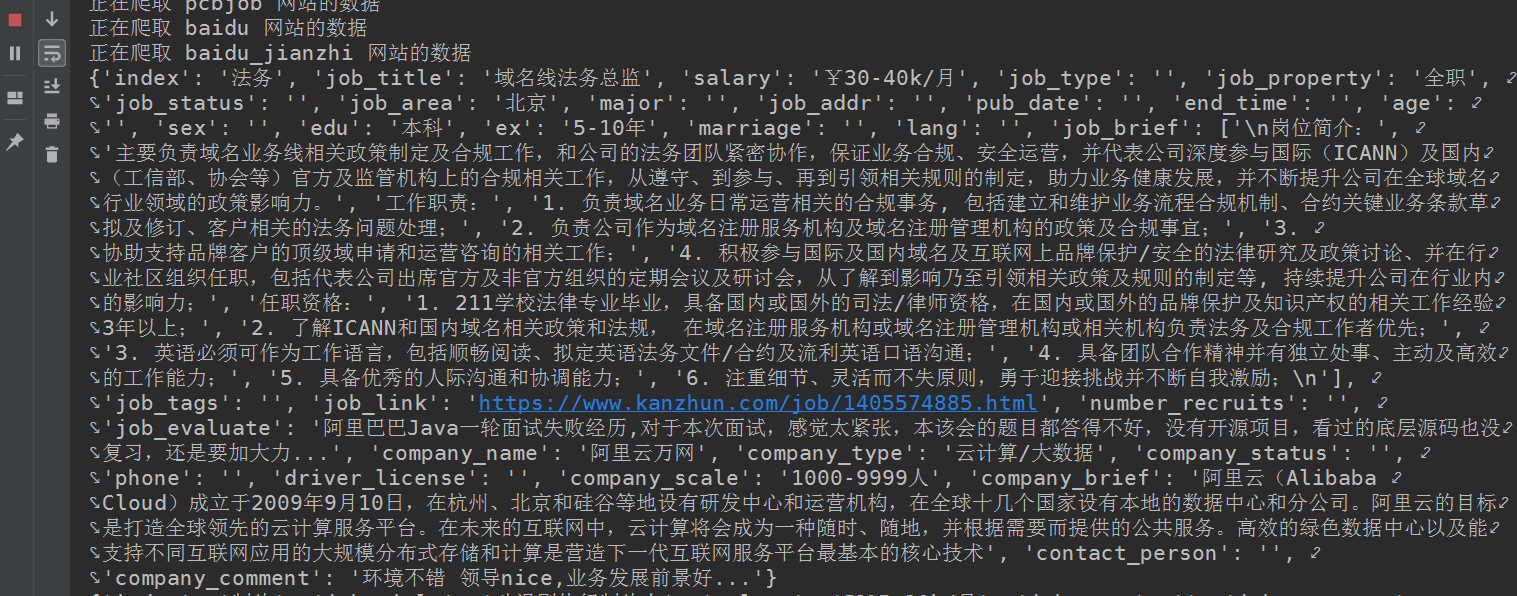
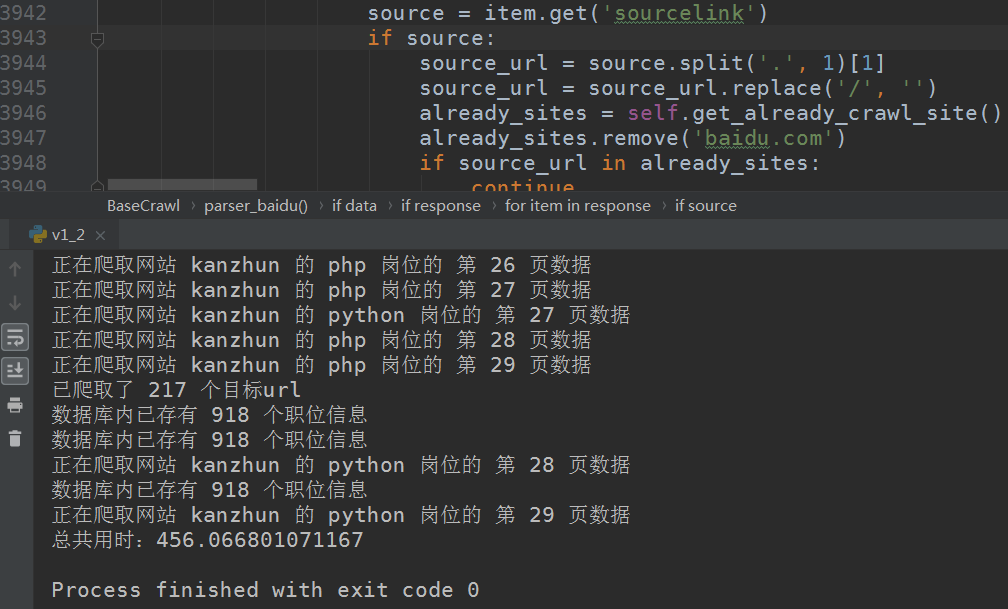
运行结果:
- 根据搜索关键词和爬取深度不同,得到的结果不同,我的数据库内存入的是两千多个职位(还未爬完)