AlgorexHealth / Hcc Python
Programming Languages
Labels
Projects that are alternatives of or similar to Hcc Python
hcc-python
An implementation of the HCC Risk Adjustment Algorithm in Python and pyDatalog.

Motivation:
CMS Publishes code for health systems and other interested parties to run their population against an HCC Risk model. Although this model is 'free' as it is published by CMS here , it comes with an implicit tax by being published in SAS:
- SAS is not open-source and has a high yearly seat-license cost
- SAS is NOT a useful language in the sense of other useful general purpose or stastitcal langugages
Our hope with this repository is to engage the community by providing a free version of this algorithm in Python (specifically Python3).
This repository is not a means by which to generate a linear regression model. It is instead the code to run the pre-existing HCC model (which had been generated against a national medicare population) against a list of beneficiaries and their diagnoses.
Contents
This repository contains the hcc.py library which implements the HCC summing algorithm. It also contains a mapping from ICD codes (both 9 and 10) to code categories, and mappings of code categories over others (called hierarchies). All of these data files must be present to work properly.
Other files in this repository are expository (pngs, reference SAS code, and jupyter notebooks).
In summary, the following files are critical for running HCC on your own using python.
- hcc.py
- icd10.txt
- icd9.txt
- coefficients.txt
Background
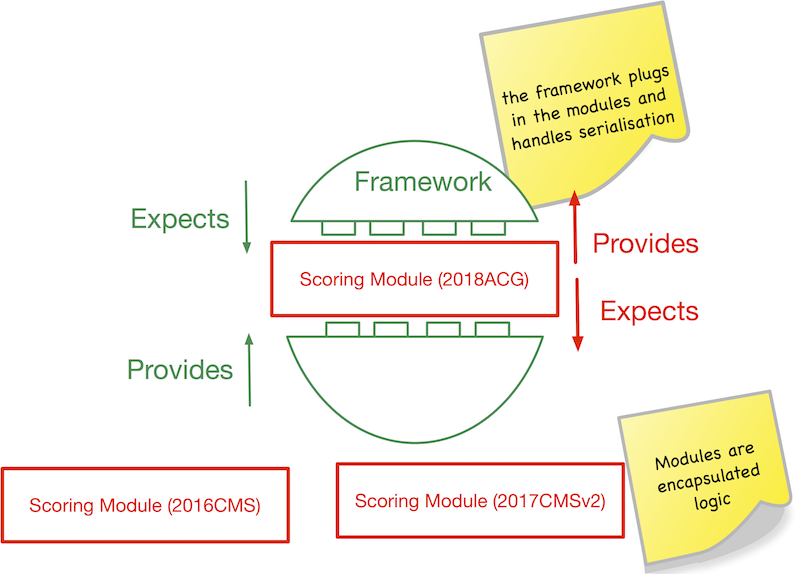
The HCC Risk Adjustment algorithm is a linear regression model summing hundreds of independent variables to a single dependent variable called a risk score. These independent variables are either engaged or not, and their associated coefficients are either added to the ongoing sum or not. We show this diagramatically as such:

As you can see, the model (community in this case) is merely a sum of coefficients. If a beneficiary and their diagnoses triggers one of these independent variables, it will add an incremental value to their risk score. That incremental value is the calculated coefficient for that effect.
The following legend gives names to these components:

To reiterate but in the language of the diagram and this legend, these models are a collection of indicator/coefficient pairs.
model := [ <indicator-coefficient-pair> ]+
indicator-coefficient-pair := ( <indicator-functionN>, <coefficientN>)
An indicator is a predicate
function, i.e. a function that returns either true or false. If the function
returns true, then the coefficient is added to the running total that is this
patient/beneficiary's risk score. Each model is a different collection of
indicator/coefficient pairs that are relevant to the model's calculation (thus,
the new-enrollee model only uses demographic variables for its indicator
functions and not diagnoses). As stated, an indicator function is a predicate
function (sometimes called an indicator or dummy variable in statistics
parlance), but what is it a function of? The answer is "of a beneficiary and
their diagnoses", as shown in the following diagram.
Given this abstraction, which is implemented in SAS by using multiplication and addition of numeric variables to represent falsehood (zero) and truth (any non-zero integer), we have chosen to implement this functionality in a unique way that emphasizes the rules, rather than a more imperative technique standard with procedural and object-oriented languages.
Implementation
Abstract Rules
We have used a packade called pyDatalog to capture the rules that may trigger an indicator function to contribute its coefficient to the
ongoing risk score. For instance,
indicator(B,'MCAID_Male_Aged') <= medicaid(B) & ~disabled(B) & male(B)
indicator(B,'COPD_ASP_SPEC_BACT_PNEUM') <= ben_hcc(B,CC) & ben_hcc(B,CC2) & copd_asp_spec_bact_pneum(CC,CC2)
These two lines of pure python code, are also an embedabble DSL for datalog that capture the logical rules that relate a beneficiary to this indicator.
You may read these rules as such, (in order):
- the MCAID_Male_Aged indicator is true for this beneficiary B
indicator(B,'MCAID_Male_Aged')if<=it is true that this beneficiary is on medicaidmedicaid(B)and that this beneficiary is not disabled~disabled(B)and this beneficiary is malemale(B) - the COPD_ASP_SPEC_BACT_PNEUM indicator is true if this beneficiary has two cost categories (CC and CC2) that are related to each other by the sub-rule
copd_asp_spec_bact_pneum(CC,CC2)(i.e. this sub-rule returns true)
For programmers familiar with standard imperative techniques (or even functional), this might seem new as it encapsulates the logic of what declaratively and eschews an imperative how for the datalog engine.
This effective severing of knowledge from implemenation can yield surprising smaller code which may have higher maintenance characteristics. Consider these rules which effectively capture the notion of hierarchicalization (the 'H' in HCC):
beneficiary_icd(B,ICD,Type) <= (Diag.beneficiary[D] == B) & (Diag.icdcode[D]==ICD) & (Diag.codetype[D]==Type)
beneficiary_has_cc(B,CC) <= beneficiary_icd(B,ICD,Type) & edit(ICD,Type,B,CC) & ~(excised(ICD,Type,B))
beneficiary_has_cc(B,CC) <= beneficiary_icd(B,ICD,Type) & \
cc(ICD,CC,Type) & ~(edit(ICD,Type,B,CC2)) & ~(excised(ICD,Type,B))
has_cc_that_overrides_this_one(B,CC) <= beneficiary_has_cc(B,OT) & overrides(OT,CC)
beneficiary_has_hcc(B,CC) <= beneficiary_has_cc(B,CC) & ~( has_cc_that_overrides_this_one(B,CC))
Though these rules depend on facts (cc and Beneficiary and Diagnosis) and other rules (excised,edit,overrides),
these few lines capture all the logic in relating beneficiaries to ICDs, and to cost categories, and hierarchical cost categories.
In the end, we are left with a database (or knowledegebase of facts and rules) which are formal encapsulations of our problem domain. These facts and rules operate to answer queries on our data.
Usage
At this time, this library is provided as a means for an experienced Python programmer to integrate into their codebase.
Thusly, such a programmer must import this library and be responsible for the de-serialization of their data
into the Python objects. These classes (Beneficiary and Diagnosis) are the effective API of this package, and their code is shown
here to show how simple they are, and what little data is needed by the HCC indicator set to trigger these coefficients:
class Diagnosis(pyDatalog.Mixin):
def __init__(self,
beneficiary,
icdcode,
codetype=ICDType.NINE):
super().__init__()
self.beneficiary = beneficiary
self.icdcode = icdcode
self.codetype = codetype
def __repr__(self): # specifies how to display an Employee
return str(self.beneficiary) + str(self.icdcode) + str(self.codetype)
class Beneficiary(pyDatalog.Mixin):
def __init__(self,
hicno,sex,dob,
original_reason_entitlement=EntitlementReason.OASI,
medicaid=False,
newenrollee_medicaid=False,):
super().__init__()
self.hicno = hicno
self.sex = sex
self.dob = datetime.strptime(dob,"%Y%m%d")
self.age = age_as_of(self.dob,datetime.now())
self.medicaid = medicaid
self.newenrollee_medicaid = newenrollee_medicaid
self.original_reason_entitlement = original_reason_entitlement
self.diagnoses = []
The key takeaway of this is that these objects are automatically integrated into pyDatalog as facts (the ground terms
for a logical set of clauses). As a Python programmer creates these objects, they become available to querying by
the other high-level API, the score datalog rule:
score(B,"community",Score) <= (community_score[B] == Score)
score(B,"institutional",Score) <= (institutional_score[B] == Score)
score(B,"new_enrollee",Score) <= (new_enrollee_score[B] == Score)
Though we show the definition of these rules above, the acutal usage would be to call the score directly from your code:
pyDatalog.create_terms("X")
for b in beneficiary_list:
score(b,"community",X) # where b is just the Beneficiary object, "community" is one of the three models you want scored, and X is a relvar
The relvar X will be populated with the values that make this relation/predicate true, that is to say, the score.
Remaining Items
This code is fresh off the presses. In the following weeks we plan on adding the following:
- Capture ICD specific upper/lower age limits for executing cost-category edits
- provide useful wrapper code to run CSV files with a well-known format for beneficiary/diagnosis data
- provide test harness to show how the SAS code and this code produce the exact same scores for all the models for a large representative data set
- improve performance by exploring other rules-driven technologies
- rules engine (Rete algorithm)
- planners/solvers/answer-set stuff?
- external prolog with better tabling characteristics (XSD?, SWI-PROLOG?)
- Refactor to provide an API and SPI for rolling in other risk adjustment models (and even different versions of the same model)