Munin - a social media archiver
This tool will monitor open Facebook, Instagram and VKontakte account seeds for new posts and archive those posts. Posts are archived in the WARC file format using the excellent Squidwarc package. A playback tool and a simple dashboard is available to monitor collections.

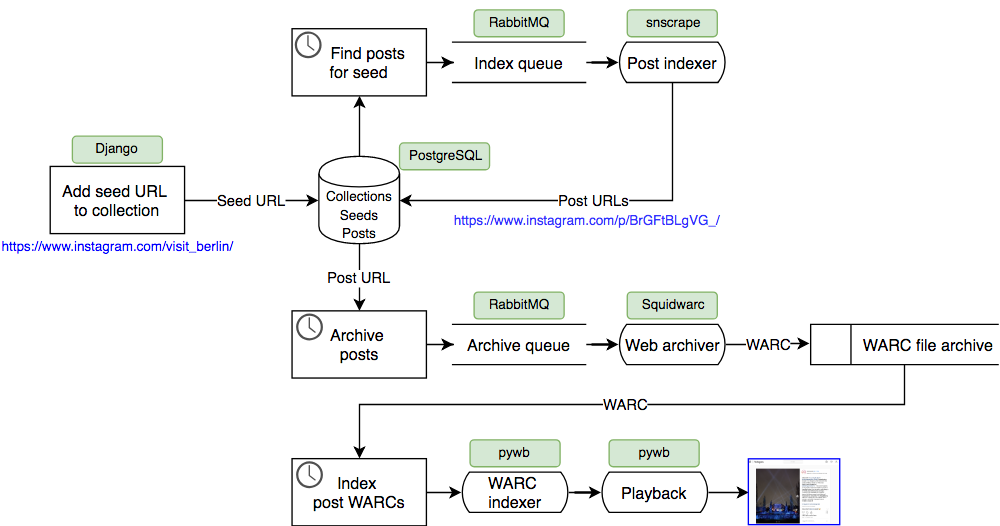
System overview
Munin builds on great software by other people. Indexing of post items is done in snscrape. Archiving of individual pages is done with Squidwarc. Playback of WARC files is enabled by pywb.
Install
-
To run you need to install Docker and Docker Compose. It has only been tested on Linux and Mac OSX currently and the instructions below are for those platforms. Make sure you have git installed.
-
Clone this repository
$ git clone https://github.com/peterk/munin-indexer
- Enter the directory and create an empty data directory for postgres
$ cd munin-indexer
$ mkdir data
- Set up environment variables
Rename the example_env_file to env_file and update it with your settings. You should change the time zone (TZ) to match your location (see the list of time zone names here).
Start everything:
$ docker-compose up -d
The first time the application starts it can take a while (several minutes) before the application becomes available. You can monitor progress by watching the docker logs.
Set up a superuser when the application is up (it will ask you for details to create an administrator):
$ docker-compose exec web python manage.py createsuperuser
Login to the admin dashboard with the newly created superuser at http://0.0.0.0:4444/admin
Start by adding your first Collection item in the admin interface. Then add one or more seed URLs to the collection (e.g. https://www.facebook.com/visitberlin/). You can bulk add multiple seeds (one per line) fron the dashboard.
After a couple of minutes the crawler should have discovered public posts and archived them. You can monitor the dashboard for new items added to the collection. Clicking the play icon will open the archived page. All archived pages are available for playback from http://0.0.0.0:4445/munin/