Optimization for Deep Learning
This repository contains PyTorch implementations of popular/recent optimization algorithms for deep learning, including SGD, SGD w/ momentum, SGD w/ Nesterov momentum, SGDW, RMSprop, Adam, Nadam, Adam w/ L2 regularization, AdamW, RAdam, RAdamW, Gradient Noise, Gradient Dropout, Learning Rate Dropout and Lookahead.
All extensions have been implemented such that it allows for mix-and-match optimization, e.g. you can train a neural net using RAdamW with both Nesterov momentum, Gradient Noise, Learning Rate Dropout and Lookahead.
Related papers
Material in this repository has been developed as part of a special course / study and reading group. This is the list of papers that we have discussed and/or implemented:
An Overview of Gradient Descent Optimization Algorithms
Optimization Methods for Large-Scale Machine Learning
On the importance of initialization and momentum in deep learning
Aggregated Momentum: Stability Through Passive Damping
ADADELTA: An Adaptive Learning Rate Method
Adam: A Method for Stochastic Optimization
On the Convergence of Adam and Beyond
Decoupled Weight Decay Regularization
On the Variance of the Adaptive Learning Rate and Beyond
Incorporating Nesterov Momentum Into Adam
Adaptive Gradient Methods with Dynamic Bound of Learning Rate
On the Convergence of AdaBound and its Connection to SGD
Lookahead Optimizer: k steps forward, 1 step back
The Marginal Value of Adaptive Gradient Methods in Machine Learning
Why Learning of Large-Scale Neural Networks Behaves Like Convex Optimization
Curriculum Learning in Deep Neural Networks
HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
Adding Gradient Noise Improves Learning for Very Deep Networks
How to run
You can run the experiments and algorithms by calling e.g.
python main.py -num_epochs 30 -dataset cifar -num_train 50000 -num_val 2048 -lr_schedule True
with arguments as specified in the main.py file. The algorithms can be run on two different datasets, MNIST and CIFAR-10. For MNIST a small MLP is used for proof of concept, whereas a 808,458 parameter CNN is used for CIFAR-10. You may optionally decrease the size of the dataset and/or number of epochs to decrease computational complexity, but the arguments given above were used to produce the results shown here.
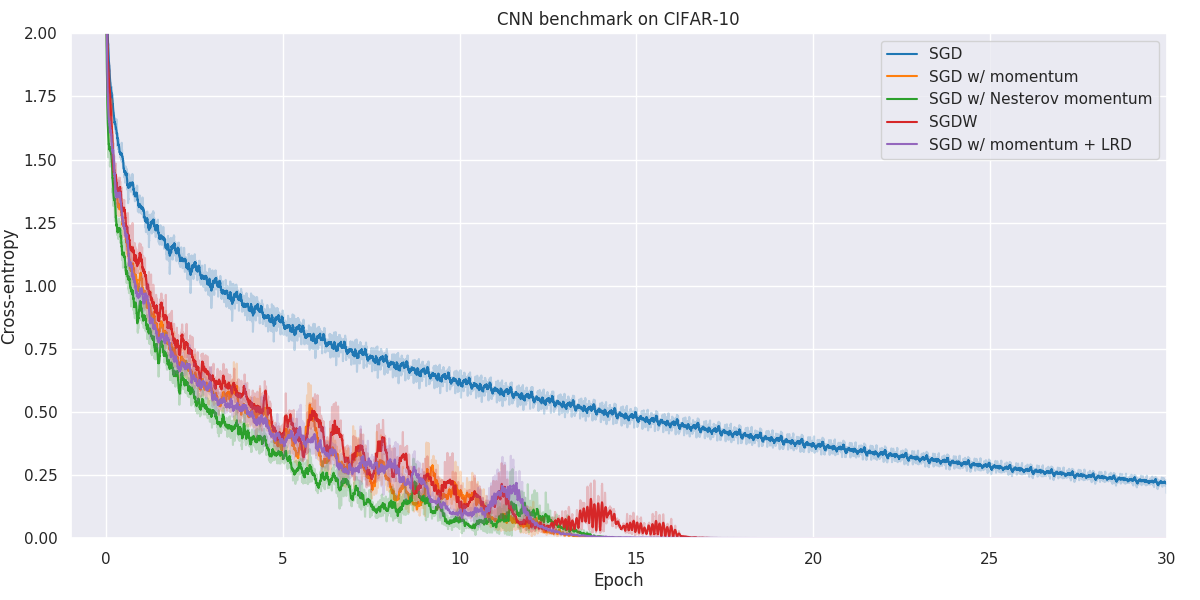
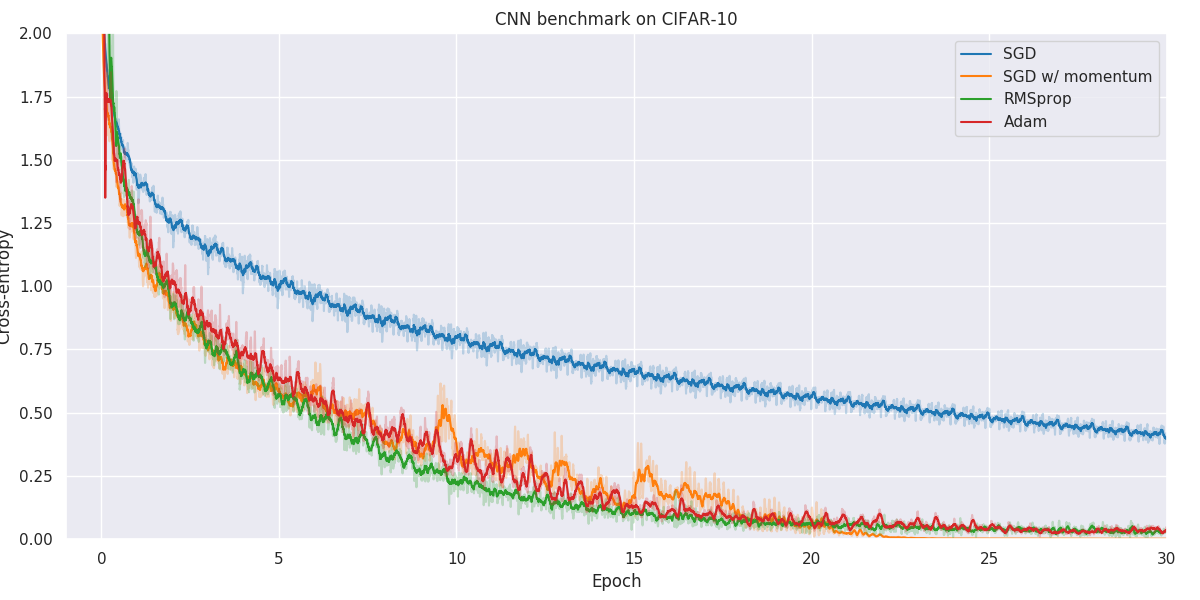
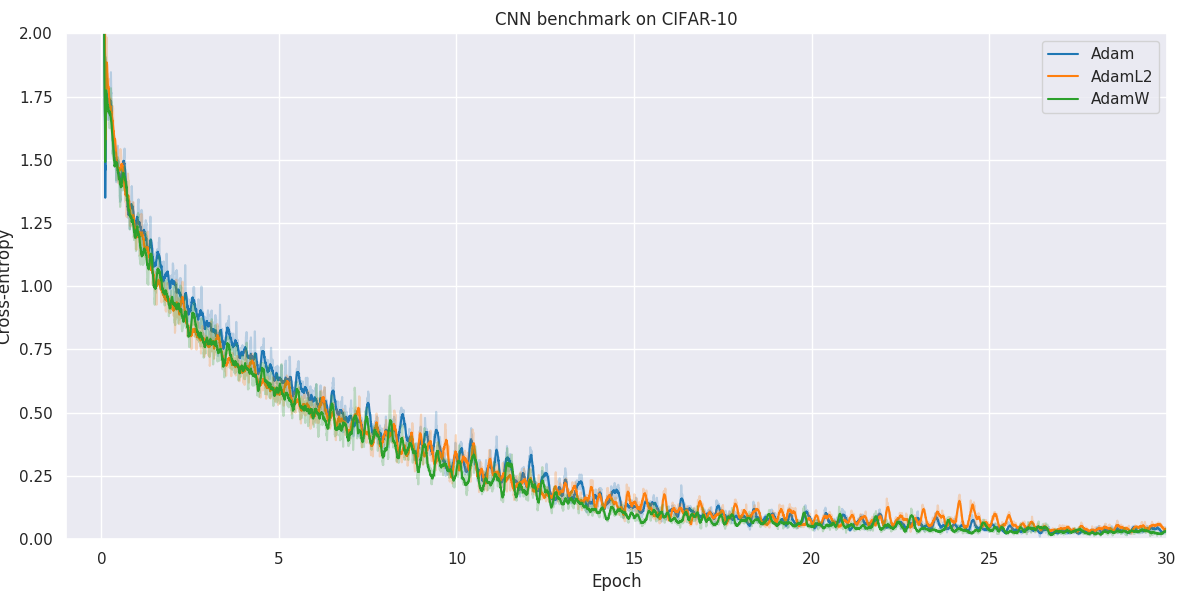
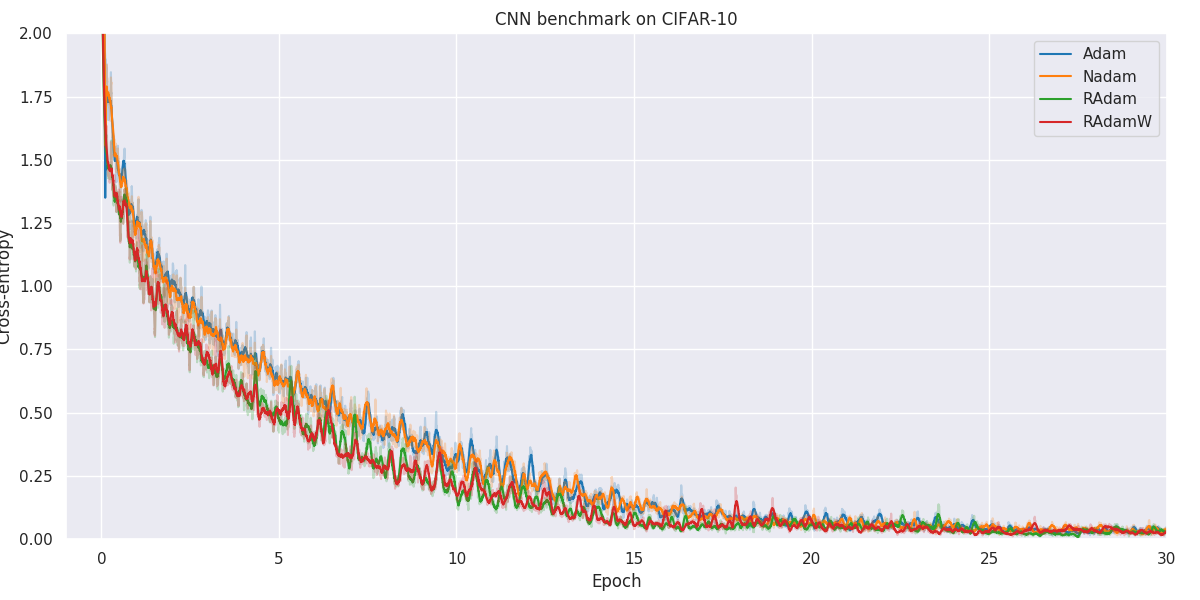
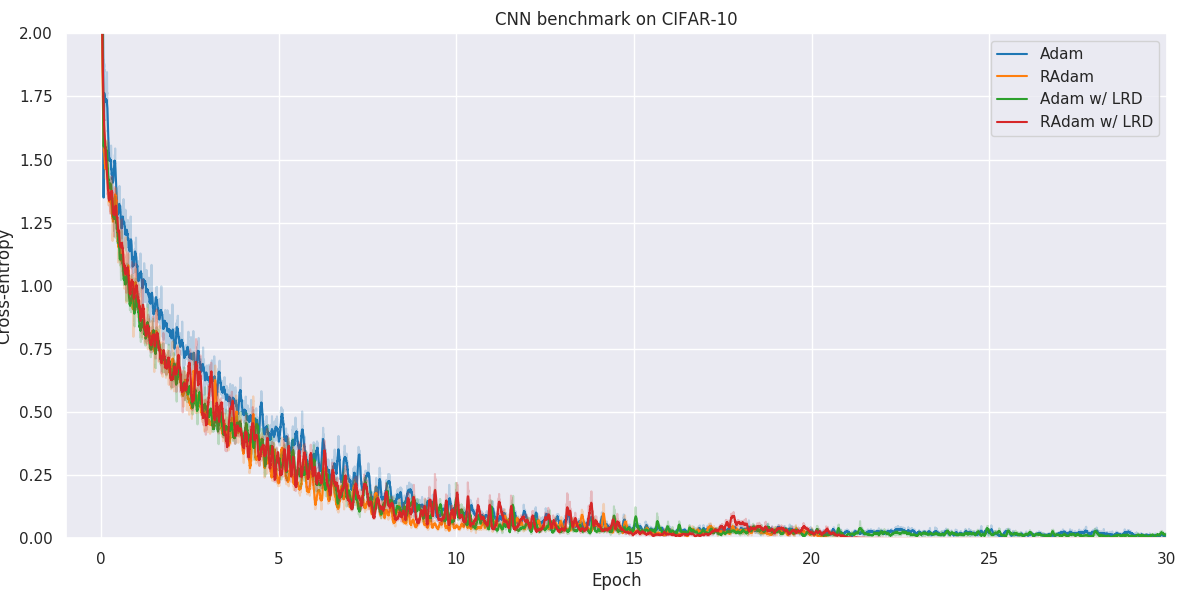
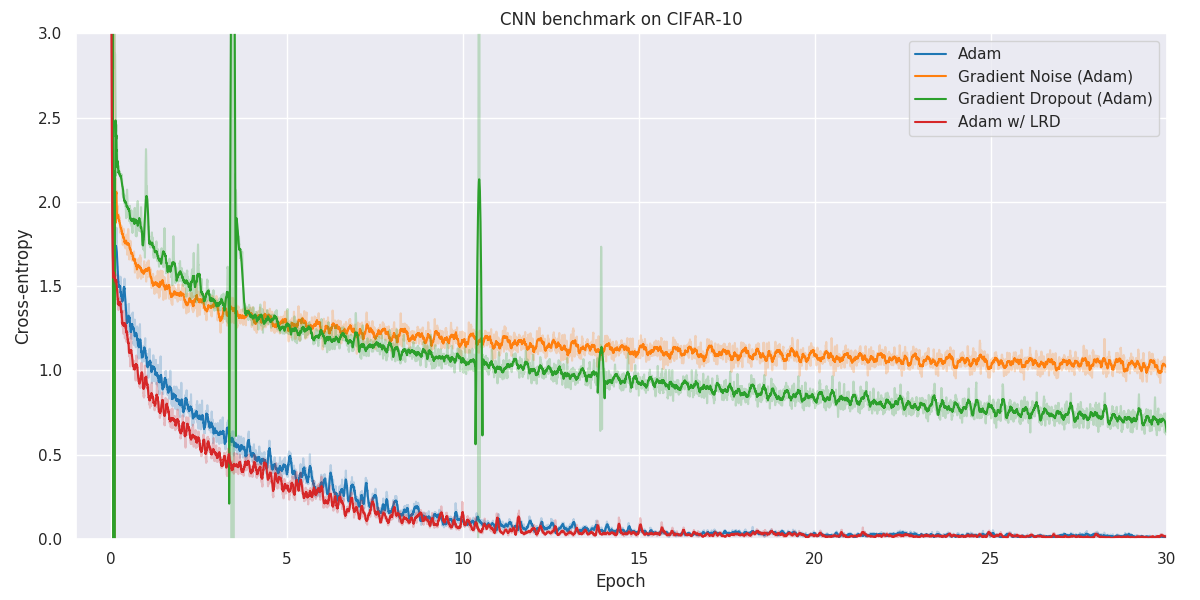
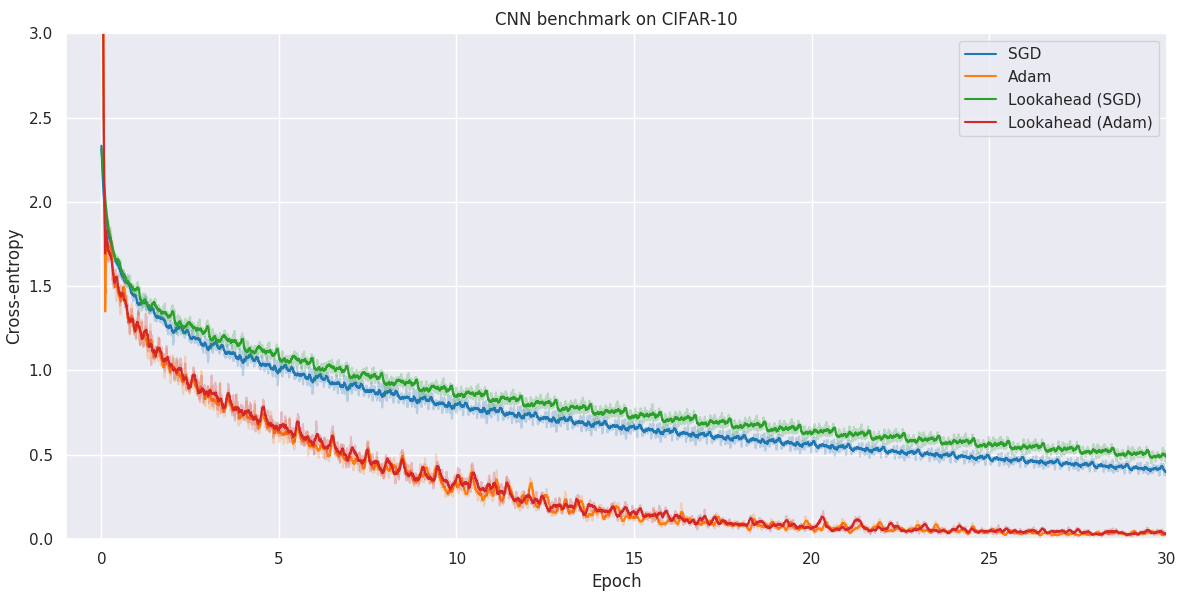
Results
Below you will find our main results. As for all optimization problems, the performance of particular algorithms is highly dependent on the problem details as well as hyper-parameters. While we have made no attempt at fine-tuning the hyper-parameters of individual optimization methods, we have kept as many hyper-parameters as possible constant to better allow for comparison. Wherever possible, default hyper-parameters as proposed by original authors have been used.
When faced with a real application, one should always try out a number of different algorithms and hyper-parameters to figure out what works better for your particular problem.