0bserver07 / One Hundred Layers Tiramisu
Licence: mit
Keras Implementation of The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation by (Simon Jégou, Michal Drozdzal, David Vazquez, Adriana Romero, Yoshua Bengio)
Stars: ✭ 193
Labels
Projects that are alternatives of or similar to One Hundred Layers Tiramisu
Learned Correspondence Release
Code release for "learning to find good correspondences" CVPR 2018
Stars: ✭ 192 (-0.52%)
Mutual labels: jupyter-notebook
Activitynet 2016 Cvprw
Tools to participate in the ActivityNet Challenge 2016 (NIPSW 2016)
Stars: ✭ 191 (-1.04%)
Mutual labels: jupyter-notebook
Ml Tutorial
Introduction to ML packages for the 6.86x course
Stars: ✭ 189 (-2.07%)
Mutual labels: jupyter-notebook
Hashnet
Code release for "HashNet: Deep Learning to Hash by Continuation" (ICCV 2017)
Stars: ✭ 192 (-0.52%)
Mutual labels: jupyter-notebook
Teachopencadd
TeachOpenCADD: a teaching platform for computer-aided drug design (CADD) using open source packages and data
Stars: ✭ 190 (-1.55%)
Mutual labels: jupyter-notebook
Spell Checker
A seq2seq model that can correct spelling mistakes.
Stars: ✭ 193 (+0%)
Mutual labels: jupyter-notebook
Facenet
FaceNet for face recognition using pytorch
Stars: ✭ 192 (-0.52%)
Mutual labels: jupyter-notebook
Cl Jupyter
An enhanced interactive Shell for Common Lisp (based on the Jupyter protocol)
Stars: ✭ 191 (-1.04%)
Mutual labels: jupyter-notebook
Simpleselfattention
A simpler version of the self-attention layer from SAGAN, and some image classification results.
Stars: ✭ 192 (-0.52%)
Mutual labels: jupyter-notebook
Py R Fcn Multigpu
Code for training py-faster-rcnn and py-R-FCN on multiple GPUs in caffe
Stars: ✭ 192 (-0.52%)
Mutual labels: jupyter-notebook
Vanillacnn
Implementation of the Vanilla CNN described in the paper: Yue Wu and Tal Hassner, "Facial Landmark Detection with Tweaked Convolutional Neural Networks", arXiv preprint arXiv:1511.04031, 12 Nov. 2015. See project page for more information about this project. http://www.openu.ac.il/home/hassner/projects/tcnn_landmarks/ Written by Ishay Tubi : ishay2b [at] gmail [dot] com https://www.l
Stars: ✭ 191 (-1.04%)
Mutual labels: jupyter-notebook
Extendedtinyfaces
Detecting and counting small objects - Analysis, review and application to counting
Stars: ✭ 193 (+0%)
Mutual labels: jupyter-notebook
Magic
MAGIC (Markov Affinity-based Graph Imputation of Cells), is a method for imputing missing values restoring structure of large biological datasets.
Stars: ✭ 189 (-2.07%)
Mutual labels: jupyter-notebook
Research2vec
Representing research papers as vectors / latent representations.
Stars: ✭ 192 (-0.52%)
Mutual labels: jupyter-notebook
Ibmquantumchallenge2020
Quantum Challenge problem sets
Stars: ✭ 193 (+0%)
Mutual labels: jupyter-notebook
The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation:
Work In Progress, Results can't be replicated yet with the models here
- UPDATE: April 28th: Skip_Connection added thanks to the reviewers, check model
model-tiramasu-67-func-api.py
feel free to open issues for suggestions:)
- Keras2 + TF used for the recent updates, which might cause with some confilict from previous version I had in here
What is The One Hundred Layers Tiramisu?
- A state of art (as in Jan 2017) Semantic Pixel-wise Image Segmentation model that consists of a fully deep convolutional blocks with downsampling, skip-layer then to Upsampling architecture.
- An extension of DenseNets to deal with the problem of semantic segmentation.
Fully Convolutional DensNet = (Dense Blocks + Transition Down Blocks) + (Bottleneck Blocks) + (Dense Blocks + Transition Up Blocks) + Pixel-Wise Classification layer

The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation (Simon Jégou, Michal Drozdzal, David Vazquez, Adriana Romero, Yoshua Bengio) arXiv:1611.09326 cs.CV
Requirements:
- Keras==2.0.2
- tensorflow-gpu==1.0.1
- or just go ahead and do:
pip install -r requirements.txt
Model Strucure:
-
DenseBlock:
BatchNormalization+Activation [ Relu ]+Convolution2D+Dropout -
TransitionDown:
BatchNormalization+Activation [ Relu ]+Convolution2D+Dropout+MaxPooling2D -
TransitionUp:
Deconvolution2D(Convolutions Transposed)

Model Params:
- RMSprop is used with Learnining Rete of 0.001 and weight decay 0.995
- However, using those got me nowhere, I switched to SGD and started tweaking the LR + Decay myself.
- There are no details given about BatchNorm params, again I have gone with what the Original DenseNet paper had suggested.
- Things to keep in mind perhaps:
- the weight inti: he_uniform (maybe change it around?)
- the regualzrazation too agressive?
Repo (explanation):
- Download the CamVid Dataset as explained below:
- Use the
data_loader.pyto crop images to224, 224as in the paper implementation.
- Use the
- run
model-tiramasu-67-func-api.pyorpython model-tirmasu-56.pyfor now to generate each models file. - run
python train-tirmasu.pyto start training:- Saves best checkpoints for the model and
data_loaderincluded for theCamVidDataset
- Saves best checkpoints for the model and
-
helper.pycontains two methodsnormalizedandone_hot_it, currently for the CamVid Task
Dataset:
-
In a different directory run this to download the dataset from original Implementation.
git clone [email protected]:alexgkendall/SegNet-Tutorial.git- copy the
/CamVidto here, or change theDataPathindata_loader.pyto the above directory
-
The run
python data_loader.pyto generate these two files:-
/data/train_data.npz/and/data/train_label.npz - This will make it easy to process the model over and over, rather than waiting the data to be loaded into memory.
-
- Experiments:
| Models | Acc | Loss | Notes |
|---|---|---|---|
| FC-DenseNet 67 |  |
 |
150 Epochs, RMSPROP |
To Do:
[x] FC-DenseNet 103
[x] FC-DenseNet 56
[x] FC-DenseNet 67
[ ] Replicate Test Accuracy CamVid Task
[ ] Replicate Test Accuracy GaTech Dataset Task
[ ] Requirements
-
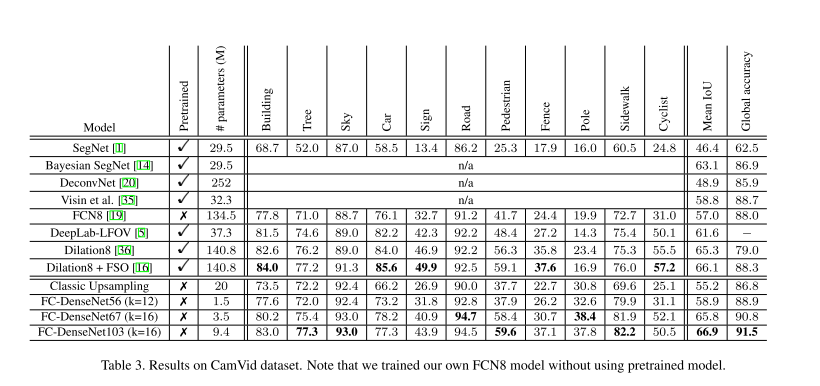
Original Results Table:

Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].