316.《表格识别技术研究进展》,2022.06
三种主流技术方向:
(1)自底向上::先检测单元格,然后确定表格线

(2)自顶向下:先检测表格线,然后确定单元格之间的关系

(3)encoder-decoder:image->html/latex

相关资料:
医疗纸质文档电子档OCR识别:http://www.cips-chip.org.cn/2022/eval4
推荐个离线OCR工具bibiocr(上):https://mp.weixin.qq.com/s/yVnSa7m1BQ7HOHeVK3i3hA
好未来的比赛
315.federated learning的两篇文章:
《When Federated Learning Meets Blockchain:A New Distributed Learning Paradigm》,用区块链技术解决联邦学习的中心化结构问题。中心挂了,系统就会挂。
《Swarm Learning for decentralized and confidential clinical machine learning》,发表在nature上的文章。

314.《Unified Structure Generation for Universal Information Extraction》
整体上采用了encoder-decoder架构,基于transformer模型,实际中预训练模型采用了ernie3.0。用一个统一的架构实现了实体识别,关系抽取,属性抽取,观点提取,事件抽取等各个理解任务。 生成的范式具有极大的灵活性,类似的思想也有很多工作。比如《A Unified Generative Framework for Various NER Subtasks》,该工作用一个生成模型解决NER的各个子任务,在此之前需要单独建模。在中文纠错方向上,由于错误类型较多,比如包含拼写纠错,语法错误等,理论上,一个生成模型可以解决各种设定下的具体任务,而不需要多个模型设计。大概两年前,复现Magi的时候,同组同学基于预训练模型,采用生成的思路做SPO抽取,取得了比理解范式下的模型更好的结果。
313.《Clinical Prompt Learning with Frozen Language Models》
Prompt Learning 在医疗文本分类中的应用。
312.《Context Enhanced Short Text Matching using Clickthrough Data》,利用点击数据做短文本匹配的上下文增强。
311.《PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction》

主要的亮点有三处:
(1)预训练拼写纠错语言模型
(2)多特征融合:character(字形)+position(位置)+phonic(拼音,也许可以进一步考虑发音特征)+shape(笔画)
(3)预训练任务设计:不同于传统的mlm,只预测单个字;该工作中同时预测单字+拼音
310.《Corpora Generation for Grammatical Error Correction》
(1)通过找到维基百科的编辑历史来解决
(2)通过back translation的方式来解决
309.《Towards Unsupervised Dense Information Retrieval With Contrastive Learning》
结论:具体对比学习方法在NLP具体任务上实践,没有显著创新贡献。
数据增强方法:
(1)inverse cloze task
(2)independent cropping
(3)additional data augmentation
负例构建方法:
(1)negative pairs within a batch
(2)negative pairs across batches
308.《Improving language models by retrieving from trillions of tokens》,DeepMind
基于特殊设计的交互组件,通过检索式的方法强化PLM的训练。

307.《Document-level Relation Extraction as Semantic Segmentation》,陈华钧老师组的工作
引用前一段时间的个人微信:
大家都在聊《Pix2seq: A Language Modeling Framework for Object Detection》,发一篇多年前第一次做NER时的一个想法,刚查了下,今年1月的文章,《Named Entity Recognition in the Style of Object Detection》。
在解决问题的范式上,CV和NLP是相通的。
306.《Med-BERT: pretrained contextualized embeddings on large- scale structured electronic health records for disease prediction》
相比其他医学预训练模型,该模型的特色是对ICD编码进行表征。
305.《Named Entity Recognition for Entity Linking》,EMNLP2021
打通NER和EL的关系,核心想法是:如何利用NER得到的Type信息?
304.《Few-Shot Named Entity Recognition_A Comprehensive Study》
文章总结了三种做few-shot ner的方式,并提出了第四种self-training的方式。

具体self-training的思路如下:

303.《Learning Rule Embeddings over Knowledge Graphs: A Case Study from E-Commerce Entity Alignment》, WWW2020
相关工作:AMIE
自动化Rule Learning。
302.《Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese Pre-trained Language Models》

301.ML中的数据验证想法:https://github.com/zhpmatrix/PaperReading/edit/master/README.md
300.《RadGraph: Extracting Clinical Entities and Relations from Radiology Reports》, 放射报告的结构化能力抽取
299.对比学习在NLP中的应用:
相关参考:
2.利用Contrastive Learning对抗数据噪声:对比学习在微博场景的实践
3.对比学习(Contrastive Learning):研究进展精要
298.《DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction》,CCKS2021
糖尿病知识图谱的构建。这篇文章的主要亮点:
(1)糖尿病知识图谱schema的设计:实体和关系
(2)标注流程设计。
297.《Pre-trained Language Model for Web-scale Retrieval in Baidu Search》,预训练模型在百度搜索的应用,印象中Google Blog也有一篇工作是讲述BERT在Google Search中的应用。
向量压缩和量化是工程实践中很关键的技术点。
296.《Wordcraft: a Human-AI Collaborative Editor for Story Writing》,Google Research
人机协作的Editor,一个完整的事情。
295.《A Data-driven Approach for Noise Reduction in Distantly Supervised Biomedical Relation Extraction》
multi-instance learning to noise reduction.
294.《CLINE:Contrastive Learning with Semantic Negative Examples for Natural Language Understanding》
利用对抗样本和对比样本提升PLM的鲁棒性。基于MLM,构建额外两个损失函数,预训练一个语言模型。整体上,个人收获不是很大的一个工作。
293.《AliCG: Fine-grained and Evolvable Conceptual Graph Construction for Semantic Search at Alibaba》
阿里概念图谱的工作,利用search log构建一个concept graph(基于UC Browser的log),可以用在多个应用场景中,如:
(1)text rewriting
(2)concept embedding
(3)conceptualized pretraining
在之前,阿里图谱相关的工作包括但不限于:AliCoCo(认知图谱), AliMe等。
292.《ABCD:A Graph Framework to Convert Complex Sentences to a Covering Set of Simple Sentences》
解决问题:将一个复杂的句子拆分成多个简单的句子。
方法:传统的方法是将问题建模为一个seq2seq的问题,但是在该工作中,借助graph的方式,取得不错的效果。
评价:problem setting有意思。
291.《COVID-19 Imaging Data Privacy By Federated Learning Design: A Threoretical Framework》, 联邦学习在cv领域的一个工作
290.《Large-Scale Network Embedding in Apache Spark》,KDD2021,在腾讯的两款游戏中有上线哦
289.《AliCoCo_Alibaba E-commerce Cognitive Concept Net》,短文本相关的技术
288.《A Neural Multi-Task Learning Framework to Jointly Model Medical Named Entity Recognition and Normalization》
同样的思想,基于multi-task的方式建模ner和norm两个任务。

287.《A transition-based joint model for disease named entity recognition and normalization》
老文章了。讨论的想法是医疗领域针对疾病,做实体识别和norm的联合建模。作为医疗NLP领域的三大基础任务:ner/nre/norm,采用jointly的方式,one model to rule all of them,也许是一个想法。
286.《A Survey on Complex Knowledge Base Question Answering》
主要综述两种KBQA的解决方案:分别是semantic-parsing based methods和information-retrieval based methods。
future中提到的一个有意思的观点是:要做Evolutionary KBQA,简而言之,要将用户的feedback带入到系统的优化中。
285.病历相似性(基于电子病历数据)
目前看到的主流思路是:梳理出EMR的各个维度,然后按照维度计算每个维度的相似性,每个维度都有自己的相似度计算方式,之后按照加权的方式求解。
个人想法:
(1)纯文本的方式。计算tf-idf(ES based solution)
(2)计算表征。但是由于EMR文本较多,医学文本对于精确性要求比较高,因此需要hierarchical representation fusion的思想。(不管怎样,首先需要一个好的encoder)
《Measurement and application of patient similarity in personalized predictive modeling based on electronic medical records》

284.《A Unified Generative Framework for Various NER Subtasks》,邱锡鹏老师组的工作
主要内容:用seq2seq(bart)解决三种常见ner的case(flat ner + nested ner + discontinuous ner)
想法:
(1)在之前的工作中,围绕这三种情况,有很多的paper。但是这篇文章采用seq2seq来解决,思路上之前也已经有相关工作了,但是这篇文章主要采用bart作为plm。毕竟seq2seq是万能的,哈哈。
(2)围绕bert做的中文nlp比较多,为啥?原因之一是因为bert有中文版,但是想用一下bart,就需要自己训练一个中文的bart了。每当这个时候,就不禁想到英文世界的话语权是怎么来的,到底意味着啥?
(3)技术创新个人认为谈不上:seq2seq(plm:bart)+ner(是一个体力活儿,不过还是要做很多工作的)

283.《SMedBERT: A Knowledge-Enhanced Pre-trained Language Model with Structured Semantics for Medical Text Mining》,丁香园的预训练语言模型
知识增强预训练语言模型。研究了丁香园,联合阿里和东南大学做的工作,丁香园利用5G的医疗领域中文文本+内部的知识图谱,通过巧妙的模型设计,得到的模型能够显著提升NER/NRE等上游任务的指标。我们可以利用开源爬取的数据(目前量<5G),同时结合OMAHA,做类似的工作以支持上游模型。
282.《Modeling Joint Entity and Relation Extraction with Table Representation》,EMNLP2014
人傻就要多读书,比如,在2014年的工作中,已经用table的方式解决joint问题了,如下:

四篇information extraction相关的工作:
281.《Read, Retrospect, Select: An MRC Framework to Short Text Entity Linking》
280.《Integrating Graph Contextualized Knowledge into Pre-trained Language Models》,小样本信息抽取相关的工作
279.《A novel cascade binary tagging framework for relational triple extraction》
278.《Entity-Relation Extraction as Multi-Turn Question Answering》
277.《Lifelong Learning based Disease Diagnosis on Clinical Notes》,腾讯天衍实验室的工作,TODO
276.《PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction》,腾讯天衍实验室的工作,TODO
275.《MIE: A Medical Information Extractor towards Medical Dialogues》
annotate online medical consultation dialogues in a window-sliding style.
274.《A Survey of Data Augmentation Approaches for NLP》
比较新的NLP数据增强文章,按照任务类型划分增强的方式。
273.《HyperCore: Hyperbolic and Co-graph Representation for Automatic ICD Coding》, ACL2021
ICD编码映射,医疗NLP的特色任务。
ICD的特点:
(1)层次
(2)共现(因果)
主要方法:GCN的应用
272.《Few-Shot Named Entity Recognition: A Comprehensive Study》,Jiawei Han组的工作
NER中的少样本问题,三种解决方案:
(1)基于proto的few-shot learning方法(此前在研究文本分类的few-shot问题时,该方向上的工作也一直比较受欢迎)
(2)带噪音,有监督预训练
(3)伪标签,自训练
271.《Summarizing Medical Conversations via Identifying Important Utterances》,COLING2020
主要内容:从医疗问答中抽取摘要。
数据:从春雨医生爬取
方法:抽取式摘要
270.《Enquire One’s Parent and Child Before Decision_ Fully Exploit Hierarchical Structure for Self-Supervised Taxonomy Expansion》,腾讯,刘邦
分类树扩展的工作,用于腾讯的疫情问答场景。刘邦的博士论文可以一读。
269.Federated Learning
《Privacy-Preserving Technology to Help Millioins of People_Federated Prediction Model for Stroke Prevention》
FL使用传统模型,也是目前主要做的工作
《Empirical Studies of Institutional Federated Learning For Natural Language Processing》
FL使用TextCNN的经验性工作
《FedED: Federated Learning via Ensemble Distillation for Medical Relation Extraction》
内容:FL应用于医疗关系抽取
结果:实现了隐私保护,但是指标下降
核心:在通信,不在计算
科普:《Introduction to FL》,本质上还是分布式学习的一种。
结论:除非必要,否则目前在工业界推进的ROI应该不算高。不单纯是一个算法问题,还是一个架构问题。但是在医疗行业目前现状下(数据孤岛现象),仍有必要关注
268.《MedDG: A Large-scale Medical Consultation Dataset for Building Medical Dialogue System》,Xiaodan Liang等
构建了一个中文医学对话数据集,特点是:标注了每个对话可能涉及的实体。
基于该数据集,定义了两个任务:
(1)next entity prediction。文章中用multi-label classification的方式实现
(2)doctor response generation。标准的文本生成类任务+融合任务(1)中的实体信息(最简单的方式:直接concat实体)
其他:ICLR2021要基于该数据集举办一个比赛,可以关注。
想法:其实是对生成领域强化对实体信息的利用。传统做生成的同学有一些对应的方式强化对实体信息的利用。不过,文章中的建模方式更偏intent识别。
《MedDialog: Large-scale Medical Dialogue Datasets》,EMNLP2020,这篇工作也是构建了一个中文医疗对话数据集,不过没有实体信息。
267.《BioBERT:a pre-trained biomedical language representation model for biomedical text mining》
预训练任务没有做任何改进,但是在下游的三个理解任务上均取得了提升,比较适合工业界操作的工作。

补充:《Conceptualized Representation Learning for Chinese Biomedical Text Mining》,阿里巴巴,张宁豫

266.《Building Watson:An Overview of the DeepQA Project》,2011年,IBM Watson的DeepQA项目,具体实现细节
讨论了架构和工程实现的问题,其中的特色在于对证据的重视。
265.《Strategies For Pre-training Graph Neural Networks》,ICLR2020
主要内容:预训练图的工作
motivation:node的pretrain和graph的pretrain都要;之前的一些工作只考虑node或者graph的单个类型的pretrain
训练任务:
(1)node:context graph的定义,学习context;attribute mask任务 (2)graph:supervised graph-level properties prediction + structural graph similarity prediction
基础模型: GIN
直观感受:中规中矩;目前还没看到预训练图的工作应用于电商领域等
264.《A User-Centered Concept Mining System for Query and Document Understanding at Tencent》,KDD2019
腾讯刘邦的工作,刘邦的博士论文也有share,主要做概念挖掘,偏向于工程系统的工作。相关文章
263.《Read, Retrospect, Select: An MRC Framework to Short Text Entity Linking》
和《AutoRegressive Entity Retrieval》,ICLR2021一块儿读。
262.《CRSLab:An Open-Source Toolkit for Building Conversational Recommender System》
CRS系统的设定:

261.《Open Domain Event Extraction Using Neural Latent Variable Models》
开放域的事件抽取。(个人对隐变量模型不是很了解)
260.《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》,KDD2018


259.《AutoRegressive Entity Retrieval》,ICLR2021
用生成的方式(seq2seq)做el,entity disambiguation, page retrieval任务。将传统分类任务转化为一个生成任务是问题解决范式的转变,很有意思的工作。在自己的博客,MRC is all you need?中讨论了将很多经典NLP任务用MRC的方式来做。
258.《Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation》,KDD2019
基于user-item-query构建的图,三种类型的边:search,click, guide,用于淘宝意图检测。
257.《Heterogeneous Graph Attention Network》,WWW2019
异构图+gat,文章写作思路很赞。目前,我们正尝试将该工作用于销量预测与归因分析。
256.《POG:Personalized Outfit Generation for Fashion Recommendation ai Alibaba iFashion》,KDD2019
阿里dida平台建设,compatibility+personality都要考察。
相关PR稿(dida也是从luban演化而来):https://hackernoon.com/finding-the-perfect-outfit-with-alibabas-dida-ai-assistant-71ba7c9e8cfa
255.《Spam Review Detection with Graph Convolutional Networks》,CIKM2018 Best Paper
重新翻开这篇文章,方法如下:
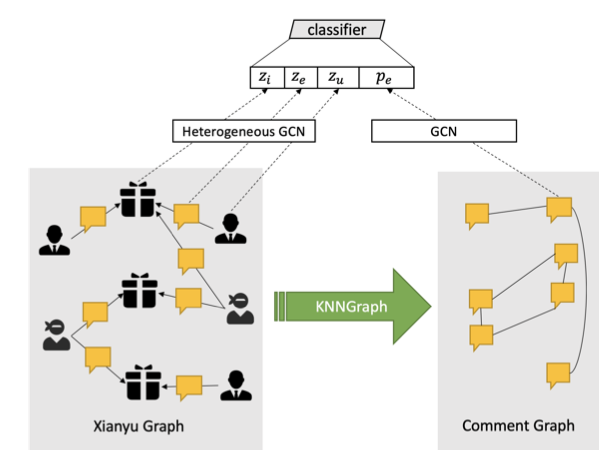
文章要解决的问题是垃圾评论检测,构建了两个图。第一个图:用户-评论-商品图,是异构图;第二个图:评论-评论图,是同构图。分别用异构GCN和GCN学到各自的表征,做节点分类工作。
整体上,文章的思路和这篇《Abusive Language Detection with Graph Convolutional Networks》非常相似,但是二者都没有互相引用。这篇文章做的是Tweet分类(三分类),分别构建两个图。第一个图:用户-用户的同构图;第二个图:用户-Tweet的异构图。针对同构图,用node2vec去学到表征(node2vec不是仅仅适用于同构图,不过效果需要考察);针对异构图,用gcn去学到表征。表征组合(embedding+n-gram)+分类器做节点分类。
对比二者,整体上的技术思路相似,不过显然后者在图构建上更加的自然。
254.《Graph Neural Networks:Taxonomy, Advances and Trends》,最新的GNN相关的综述文章
253.《Understanding Image Retrieval Re-Ranking:A Graph Neural Network Persperctive》
有意思的工作,作者提到:
(1)Re-ranking can be reformulated as a high-parallelism Graph Neural Network (GNN) function.
(2)On the Market-1501 dataset, we accelerate the re-ranking processing from 89.2s to 9.4ms with one K40m GPU.
252.《Why Are Deep Learning Models Not Consistently Winning Recommender Systems Competitions Yet?》,RecSys2020
非常棒的文章,多年以前自己就很好奇了。
251.《Enriching Pre-trained Language Model with Entity Information for Relation Classification》

250.《Diverse, Controllable, and Keyphrase-Aware: A Corpus and Method for News Multi-Headline Generation》
新闻标题生成
249.《CharBERT: Character-aware Pre-trained Language Model》
248.《