Examples Of Web Crawlers一些非常有趣的python爬虫例子,对新手比较友好,主要爬取淘宝、天猫、微信、豆瓣、QQ等网站。(Some interesting examples of python crawlers that are friendly to beginners. )
Stars: ✭ 10,724 (+403.71%)
Mutual labels: crawler, spider, taobao, selenium
FbcrawlA Facebook crawler
Stars: ✭ 536 (-74.82%)
Mutual labels: crawler, spider, scrapy, crawl
Crawlab LiteLite version of Crawlab. 轻量版 Crawlab 爬虫管理平台
Stars: ✭ 122 (-94.27%)
Mutual labels: crawler, spider, scrapy
NetdiscoveryNetDiscovery 是一款基于 Vert.x、RxJava 2 等框架实现的通用爬虫框架/中间件。
Stars: ✭ 573 (-73.09%)
Mutual labels: crawler, spider, selenium
IcrawlerA multi-thread crawler framework with many builtin image crawlers provided.
Stars: ✭ 629 (-70.46%)
Mutual labels: crawler, spider, scrapy
Zhihu Login知乎模拟登录,支持提取验证码和保存 Cookies
Stars: ✭ 340 (-84.03%)
Mutual labels: crawler, spider, crawl
Haipproxy💖 High available distributed ip proxy pool, powerd by Scrapy and Redis
Stars: ✭ 4,993 (+134.52%)
Mutual labels: crawler, spider, scrapy
Python Spider豆瓣电影top250、斗鱼爬取json数据以及爬取美女图片、淘宝、有缘、CrawlSpider爬取红娘网相亲人的部分基本信息以及红娘网分布式爬取和存储redis、爬虫小demo、Selenium、爬取多点、django开发接口、爬取有缘网信息、模拟知乎登录、模拟github登录、模拟图虫网登录、爬取多点商城整站数据、爬取微信公众号历史文章、爬取微信群或者微信好友分享的文章、itchat监听指定微信公众号分享的文章
Stars: ✭ 615 (-71.11%)
Mutual labels: spider, scrapy, selenium
Proxy poolPython爬虫代理IP池(proxy pool)
Stars: ✭ 13,964 (+555.89%)
Mutual labels: crawler, spider, crawl
CrawlabDistributed web crawler admin platform for spiders management regardless of languages and frameworks. 分布式爬虫管理平台,支持任何语言和框架
Stars: ✭ 8,392 (+294.18%)
Mutual labels: crawler, spider, scrapy
Nodespider[DEPRECATED] Simple, flexible, delightful web crawler/spider package
Stars: ✭ 33 (-98.45%)
Mutual labels: crawler, spider, crawl
Alipayspider ScrapyAlipaySpider on Scrapy(use chrome driver); 支付宝爬虫(基于Scrapy)
Stars: ✭ 70 (-96.71%)
Mutual labels: spider, scrapy, selenium
Scrapy IPProxyPool免费 IP 代理池。Scrapy 爬虫框架插件
Stars: ✭ 100 (-95.3%)
Mutual labels: spider, crawl, scrapy
Goribot[Crawler/Scraper for Golang]🕷A lightweight distributed friendly Golang crawler framework.一个轻量的分布式友好的 Golang 爬虫框架。
Stars: ✭ 190 (-91.08%)
Mutual labels: crawler, spider, scrapy
Marmot💐Marmot | Web Crawler/HTTP protocol Download Package 🐭
Stars: ✭ 186 (-91.26%)
Mutual labels: crawler, spider, scrapy
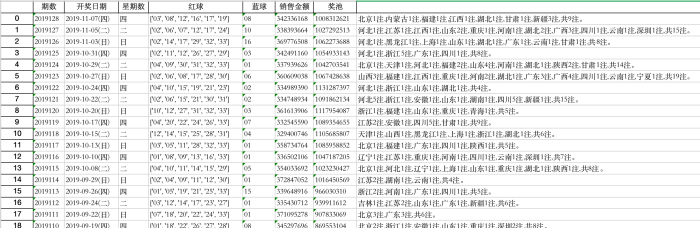
InfospiderINFO-SPIDER 是一个集众多数据源于一身的爬虫工具箱🧰,旨在安全快捷的帮助用户拿回自己的数据,工具代码开源,流程透明。支持数据源包括GitHub、QQ邮箱、网易邮箱、阿里邮箱、新浪邮箱、Hotmail邮箱、Outlook邮箱、京东、淘宝、支付宝、中国移动、中国联通、中国电信、知乎、哔哩哔哩、网易云音乐、QQ好友、QQ群、生成朋友圈相册、浏览器浏览历史、12306、博客园、CSDN博客、开源中国博客、简书。
Stars: ✭ 5,984 (+181.07%)
Mutual labels: spider, crawl, selenium
ScrapingoutsourcingScrapingOutsourcing专注分享爬虫代码 尽量每周更新一个
Stars: ✭ 164 (-92.3%)
Mutual labels: crawler, spider, scrapy
Grab SiteThe archivist's web crawler: WARC output, dashboard for all crawls, dynamic ignore patterns
Stars: ✭ 680 (-68.06%)
Mutual labels: crawler, spider, crawl
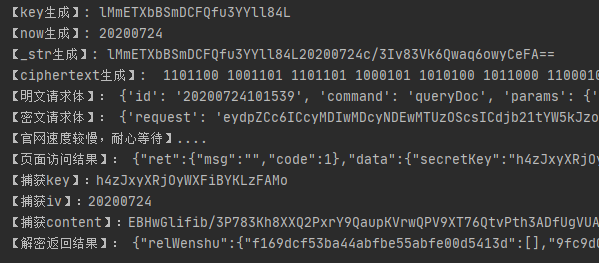
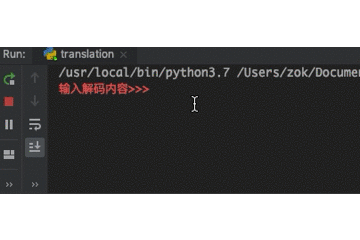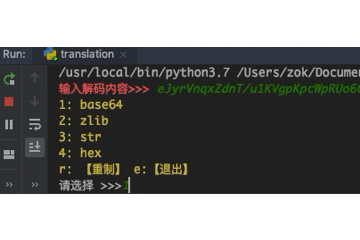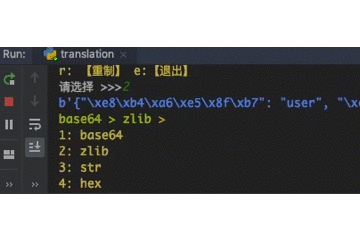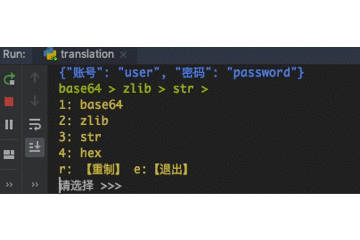
DecryptloginAPIs for loginning some websites by using requests.
Stars: ✭ 1,861 (-12.59%)
Mutual labels: crawler, spider, taobao
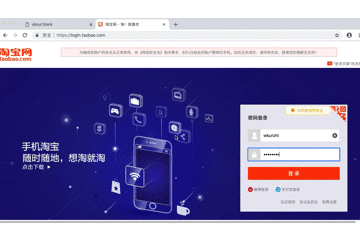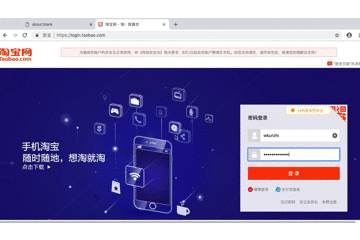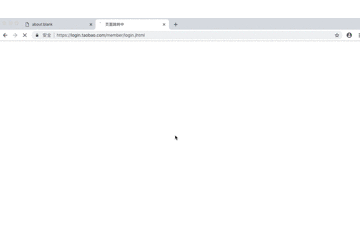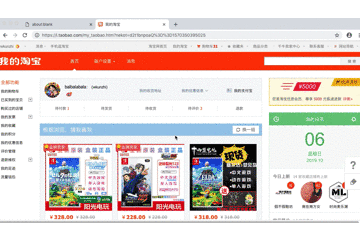
Taobaoscrapy😩Tool For Taobao/Tmall| 儿时玩具已经过时
Stars: ✭ 146 (-93.14%)
Mutual labels: spider, scrapy, taobao