![]()
Machine learning applications often need large amounts of training data to perform well. Whereas unlabeled data can be easily gathered, the labeling process is difficult, time-consuming, or expensive in most applications. Active learning can help solve this problem by querying labels for those data samples that will improve the performance the most. Thereby, the goal is that the learning algorithm performs sufficiently well with fewer labels
With this goal in mind, scikit-activeml has been developed as a Python module for active learning on top of scikit-learn. The project was initiated in 2020 by the Intelligent Embedded Systems Group at the University of Kassel and is distributed under the 3-Clause BSD licence.
Overview
Our philosophy is to extend the sklearn eco-system with the most relevant
query strategies for active learning and to implement tools for working with partially
unlabeled data. An overview of our repository's structure is given in the image below.
Each node represents a class or interface. The arrows illustrate the inheritance
hierarchy among them. The functionality of a dashed node is not yet available in our library.

In our package skactiveml, there three major components, i.e., SkactivemlClassifier,
QueryStrategy, and the not yet supported SkactivemlRegressor.
The classifier and regressor modules are necessary to deal with partially unlabeled
data and to implement active-learning specific estimators. This way, an active learning
cycle can be easily implemented to start with zero initial labels. Regarding the
active learning query strategies, we currently differ between
the pool-based (a large pool of unlabeled samples is available) and stream-based
(unlabeled samples arrive sequentially, i.e., as a stream) paradigm.
On top of both paradigms, we also distinguish the single- and multi-annotator
setting. In the latter setting, multiple error-prone annotators are queried
to provide labels. As a result, an active learning query strategy not only decides
which samples but also which annotators should be queried.
User Installation
The easiest way of installing scikit-activeml is using pip:
pip install -U scikit-activeml
Examples
In the following, there are two simple examples illustrating the straightforwardness
of implementing active learning cycles with our Python package skactiveml.
For more in-depth examples, we refer to our
tutorial section offering
a broad overview of different use-cases:
- pool-based active learning -- getting started,
- deep pool-based active learning -- scikit-activeml with skorch,
- multi-annotator pool-based active learning -- getting started,
- stream-based active learning -- getting started,
- and batch stream-based active learning with pool-based query strategies.
Pool-based Active Learning
The following code implements an active learning cycle with 20 iterations using a Gaussian process
classifier and uncertainty sampling. To use other classifiers, you can simply wrap classifiers from
sklearn or use classifiers provided by skactiveml. Note that the main difficulty using
active learning with sklearn is the ability to handle unlabeled data, which we denote as a specific value
(MISSING_LABEL) in the label vector y. More query strategies can be found in the documentation.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.datasets import make_blobs
from skactiveml.pool import UncertaintySampling
from skactiveml.utils import unlabeled_indices, MISSING_LABEL
from skactiveml.classifier import SklearnClassifier
from skactiveml.visualization import plot_decision_boundary, plot_utilities
# Generate data set.
X, y_true = make_blobs(n_samples=200, centers=4, random_state=0)
y = np.full(shape=y_true.shape, fill_value=MISSING_LABEL)
# GaussianProcessClassifier needs initial training data otherwise a warning will
# be raised by SklearnClassifier. Therefore, the first 10 instances are used as
# training data.
y[:10] = y_true[:10]
# Create classifier and query strategy.
clf = SklearnClassifier(GaussianProcessClassifier(random_state=0),classes=np.unique(y_true), random_state=0)
qs = UncertaintySampling(method='entropy')
# Execute active learning cycle.
n_cycles = 20
for c in range(n_cycles):
query_idx = qs.query(X=X, y=y, clf=clf)
y[query_idx] = y_true[query_idx]
# Fit final classifier.
clf.fit(X, y)
# Visualize resulting classifier and current utilities.
bound = [[min(X[:, 0]), min(X[:, 1])], [max(X[:, 0]), max(X[:, 1])]]
unlbld_idx = unlabeled_indices(y)
fig, ax = plt.subplots(1, 1, figsize=(8, 8))
ax.set_title(f'Accuracy score: {clf.score(X,y_true)}', fontsize=15)
plot_utilities(qs, X=X, y=y, clf=clf, feature_bound=bound, ax=ax)
plot_decision_boundary(clf, feature_bound=bound, confidence=0.6)
plt.scatter(X[unlbld_idx,0], X[unlbld_idx,1], c='gray')
plt.scatter(X[:,0], X[:,1], c=y, cmap='jet')
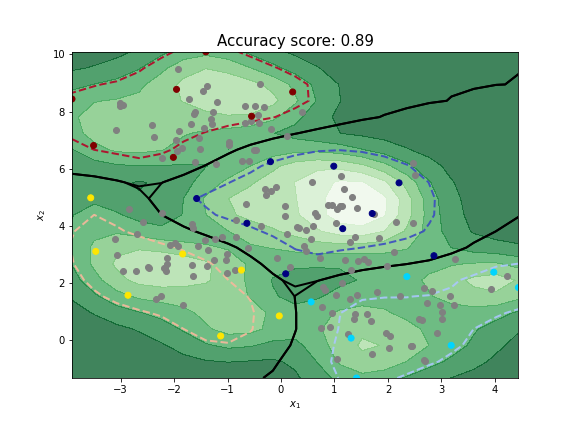
plt.show()As output of this code snippet, we obtain the actively trained Gaussian process classifier including a visualization of its decision boundary and the sample utilities computed with uncertainty sampling.
Stream-based Active Learning
The following code implements an active learning cycle with 200 data points and
the default budget of 10% using a pwc classifier and split uncertainty sampling.
Like in the pool-based example you can wrap other classifiers from sklearn,
sklearn compatible classifiers or like the example classifiers provided by skactiveml.
import numpy as np
import matplotlib.pyplot as plt
from scipy.ndimage import gaussian_filter1d
from sklearn.datasets import make_blobs
from skactiveml.classifier import ParzenWindowClassifier
from skactiveml.stream import Split
from skactiveml.utils import MISSING_LABEL
# Generate data set.
X, y_true = make_blobs(n_samples=200, centers=4, random_state=0)
# Create classifier and query strategy.
clf = ParzenWindowClassifier(random_state=0, classes=np.unique(y_true))
qs = Split(random_state=0)
# Initializing the training data as an empty array.
X_train = []
y_train = []
# Initialize the list that stores the result of the classifier's prediction.
correct_classifications = []
# Execute active learning cycle.
for x_t, y_t in zip(X, y_true):
X_cand = x_t.reshape([1, -1])
y_cand = y_t
clf.fit(X_train, y_train)
correct_classifications.append(clf.predict(X_cand)[0] == y_cand)
sampled_indices = qs.query(candidates=X_cand, clf=clf)
qs.update(candidates=X_cand, queried_indices=sampled_indices)
X_train.append(x_t)
y_train.append(y_cand if len(sampled_indices) > 0 else MISSING_LABEL)
# Plot the classifier's learning accuracy.
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
ax.set_title(f'Learning curve', fontsize=15)
ax.set_xlabel('number of learning cycles')
ax.set_ylabel('accuracy')
ax.plot(gaussian_filter1d(np.array(correct_classifications, dtype=float), 4))
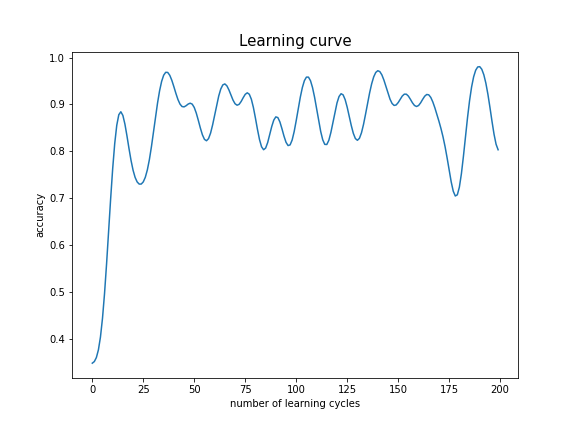
plt.show()As output of this code snippet, we obtain the actively trained pwc classifier incuding a visualization of its accuracy over the 200 samples.
Citing
If you use scikit-activeml in one of your research projects and find it helpful,
please cite the following:
@article{skactiveml2021,
title={scikitactiveml: {A} {L}ibrary and {T}oolbox for {A}ctive {L}}earning {A}lgorithms},
author={Daniel Kottke and Marek Herde and Tuan Pham Minh and Alexander Benz and Pascal Mergard and Atal Roghman and Christoph Sandrock and Bernhard Sick},
journal={Preprints},
doi={10.20944/preprints202103.0194.v1},
year={2021},
url={https://github.com/scikit-activeml/scikit-activeml}
}