seq2seq
![]()
Documentation
seq2seq-pytorch is a framework for attention based sequence-to-sequence models implemented in Pytorch.
The framework has modularized and extensible components for seq2seq models, training, inference, checkpoints, etc.
Intro
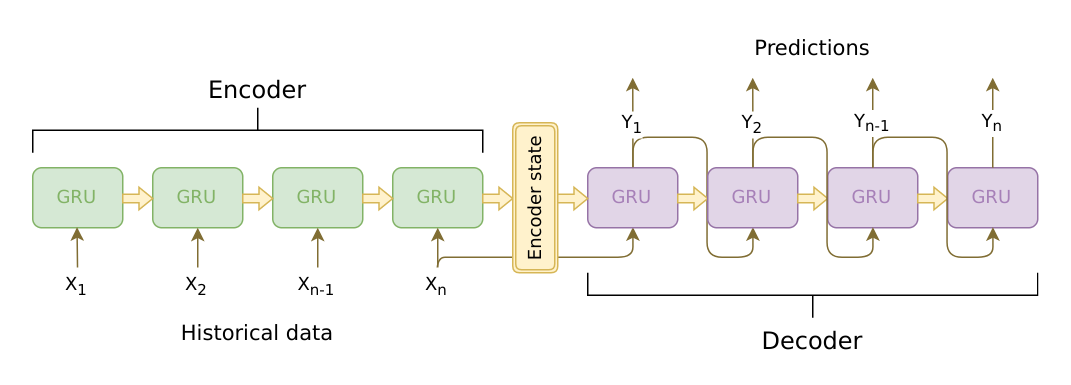
Seq2seq turns one sequence into another sequence. It does so by use of a recurrent neural network (RNN) or more often LSTM or GRU to avoid the problem of vanishing gradient. The context for each item is the output from the previous step. The primary components are one encoder and one decoder network. The encoder turns each item into a corresponding hidden vector containing the item and its context. The decoder reverses the process, turning the vector into an output item, using the previous output as the input context.
Installation
This project recommends Python 3.6 or higher.
I recommend creating a new virtual environment for this project (using virtualenv or conda).
Prerequisites
- Numpy:
pip install numpy(Refer here for problem installing Numpy). - PyTorch: Refer to PyTorch website to install the version w.r.t. your environment.
Get Started
The toy problem is brought from IBM/pytorch-seq2seq.
Prepare toy dataset
$ ./generate_toy_data.sh
Run script to generate the reverse toy dataset.
The generated data is stored in data/toy_reverse by default.
Train and play
$ ./toy.sh
Start training by default setting. If you want to edit default setting, you can edit toy.sh.
Once training is complete, you will be prompted to enter a new sequence to translate and the model will print out its prediction (use ctrl-C to terminate). Try the example below!
Input: 1 3 5 7 9
Expected output: 9 7 5 3 1 EOS
Checkpoints
Checkpoints are organized by experiments and timestamps as shown in the following file structure
experiment_dir
+-- input_vocab
+-- output_vocab
+-- checkpoints
| +-- YYYY_mm_dd_HH_MM_SS
| +-- decoder
| +-- encoder
| +-- model_checkpoint
The sample script by default saves checkpoints in the experiment folder of the root directory. Look at the usages of the sample code for more options, including resuming and loading from checkpoints.
Troubleshoots and Contributing
If you have any questions, bug reports, and feature requests, please open an issue on Github.
or Contacts [email protected] please.
Code Style
I follow PEP-8 for code style. Especially the style of docstrings is important to generate documentation.
Reference
- IBM pytorch-seq2seq
- Sequence to Sequence Learning with Neural Networks
- Neural Machine Translation by Jointly Learning to Align and Translate
- Attention Is All You Need
Author
- Soohwan Kim @sooftware
- Contacts: [email protected]