ShifuML / Shifu
Programming Languages
Projects that are alternatives of or similar to Shifu
![]()

Download
Please download latest shifu here.
Getting Started
After shifu downloading, build your first model with Shifu tutorial. More details about shifu can be found in our wiki pages.
What is Shifu?
Shifu is an open-source, end-to-end machine learning and data mining framework built on top of Hadoop. Shifu is designed for data scientists, simplifying the life-cycle of building machine learning models. While originally built for fraud modeling, Shifu is generalized for many other modeling domains.
One of Shifu's pros is an end-to-end modeling pipeline in machine learning. With only configurations settings, a whole machine pipeline can be built and model can be much more easy to develop and push to production. The pipeline defined in Shifu is in below:
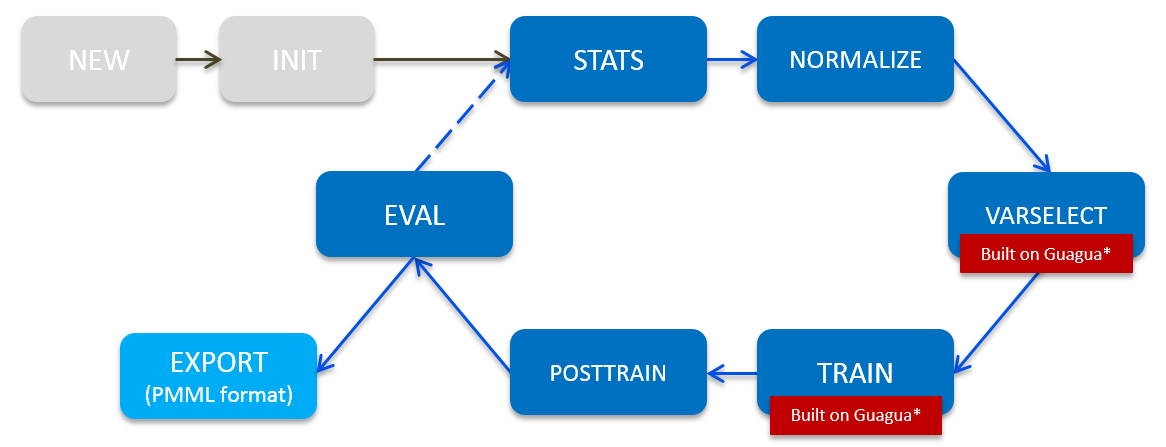
Shifu provides a simple command-line interface for each step of the model building process, including
- Statistic calculation & variable selection to determine the most predictive variables in your data
- Variable normalization
- Distributed variable selection based on sensitivity analysis
- Distributed neural network model training
- Distributed tree ensemble model training
- Post training analysis & model evaluation
- Distributed Tensorflow on Shifu
Shifu’s fast Hadoop-based, distributed neural network / logistic regression / gradient boosted trees training can reduce model training time from days to hours on TB data sets. Shifu integrates with Pig workflows on Hadoop, and Shifu-trained models can be integrated into production code with a simple Java API. Shifu leverages Pig, Akka, Encog and other open source projects.
Guagua, an in-memory iterative computing framework on Hadoop YARN is developed as sub-project of Shifu to accelerate training progress.
More details about shifu can be found in our wiki pages
Conference
Contributors
- Zhanghao Hu ([email protected])
- Grahame Jastrebski ([email protected])
- Lavar Li ([email protected])
- Mark Liu ([email protected])
- David Zhang ([email protected])
- Xin Zhong ([email protected])
- Simon Zhang (jzhang13[email protected])
- Sharma Nitin ([email protected])
- Wayne Zhu ([email protected])
- Devin Wu ([email protected])
- Fred Bai ([email protected])
Google Group
Please join Shifu group if questions, bugs or anything else.
Copyright and License
Copyright 2012-2019, PayPal Software Foundation under the Apache License.