minio / Sidekick
Programming Languages
Projects that are alternatives of or similar to Sidekick
![]()
![]()
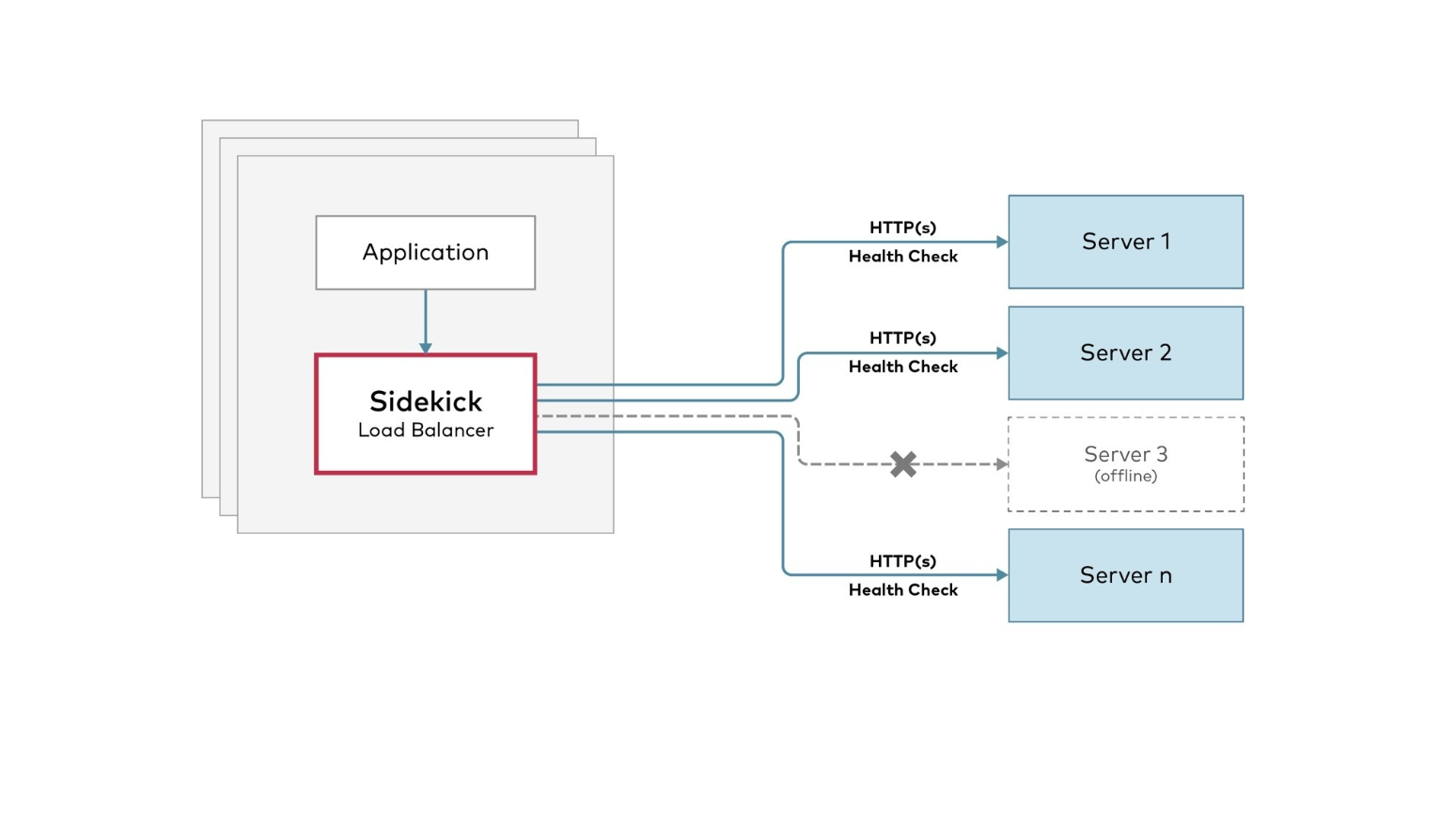
sidekick is a high-performance sidecar load-balancer. By attaching a tiny load balancer as a sidecar to each of the client application processes, you can eliminate the centralized loadbalancer bottleneck and DNS failover management. sidekick automatically avoids sending traffic to the failed servers by checking their health via the readiness API and HTTP error returns.
Table of Contents
Architecture
Demo 
Install
Binary Releases
| OS | ARCH | Binary |
|---|---|---|
| Linux | amd64 | linux-amd64 |
| Linux | arm64 | linux-arm64 |
| Linux | ppc64le | linux-ppc64le |
| Linux | s390x | linux-s390x |
| Apple | amd64 | darwin-amd64 |
| Windows | amd64 | windows-amd64 |
You can also verify the binary with minisign by downloading the corresponding .minisig signature file. Then run:
minisign -Vm sidekick-<OS>-<ARCH> -P RWTx5Zr1tiHQLwG9keckT0c45M3AGeHD6IvimQHpyRywVWGbP1aVSGav
Docker
Pull the latest release via:
docker pull minio/sidekick
Build from source
GO111MODULE=on go get github.com/minio/sidekick/cmd/sidekick
You will need a working Go environment. Therefore, please follow How to install Go. Minimum version required is go1.16
Usage
USAGE:
sidekick [FLAGS] SITE1 [SITE2..]
FLAGS:
--address value, -a value listening address for sidekick (default: ":8080")
--health-path value, -p value health check path
--health-duration value, -d value health check duration in seconds (default: 5)
--insecure, -i disable TLS certificate verification
--log , -l enable logging
--trace, -t enable HTTP tracing
--quiet disable console messages
--json output sidekick logs and trace in json format
--debug output verbose trace
--help, -h show help
--version, -v print the version
SITE:
Each SITE is a comma separated list of pools of the same site: http://172.17.0.{2...5},http://172.17.0.{6...9}
If all servers in SITE1 are down, then the traffic is routed to the next site - SITE2.
Two sites are separated by a space character.
Examples
Load balance across a web service using DNS provided IPs
$ sidekick --health-path=/ready http://myapp.myorg.dom
Load balance across 4 MinIO Servers (http://minio1:9000 to http://minio4:9000)
$ sidekick --health-path=/minio/health/ready --address :8000 http://minio{1...4}:9000
Two sites with 4 servers each
$ sidekick --health-path=/minio/health/ready http://site1-minio{1...4}:9000 http://site2-minio{1...4}:9000
Realworld Example with spark-orchestrator
As spark driver, executor sidecars, to begin with install spark-operator and MinIO on your kubernetes cluster
optional create a kubernetes namespace spark-operator
kubectl create ns spark-operator
Configure spark-orchestrator
We shall be using maintained spark operator by GCP at https://github.com/GoogleCloudPlatform/spark-on-k8s-operator
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
helm install spark-operator incubator/sparkoperator --namespace spark-operator --set sparkJobNamespace=spark-operator --set enableWebhook=true
Install MinIO
helm install minio-distributed stable/minio --namespace spark-operator --set accessKey=minio,secretKey=minio123,persistence.enabled=false,mode=distributed
NOTE: persistence is disabled here for testing, make sure you are using persistence with PVs for production workload. For more details read our helm documentation
Once minio-distributed is up and running configure mc and upload some data, we shall choose mybucket as our bucketname.
Port-forward to access minio-cluster locally.
kubectl port-forward pod/minio-distributed-0 9000
Create bucket named mybucket and upload some text data for spark word count sample.
mc config host add minio-distributed http://localhost:9000 minio minio123
mc mb minio-distributed/mybucket
mc cp /etc/hosts minio-distributed/mybucket/mydata/{1..4}.txt
Run the spark job in k8s
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-minio-app
namespace: spark-operator
spec:
sparkConf:
spark.kubernetes.allocation.batch.size: "50"
hadoopConf:
"fs.s3a.endpoint": "http://127.0.0.1:9000"
"fs.s3a.access.key": "minio"
"fs.s3a.secret.key": "minio123"
"fs.s3a.path.style.access": "true"
"fs.s3a.impl": "org.apache.hadoop.fs.s3a.S3AFileSystem"
type: Scala
sparkVersion: 2.4.5
mode: cluster
image: minio/spark:v2.4.5-hadoop-3.1
imagePullPolicy: Always
restartPolicy:
type: OnFailure
onFailureRetries: 3
onFailureRetryInterval: 10
onSubmissionFailureRetries: 5
onSubmissionFailureRetryInterval: 20
mainClass: org.apache.spark.examples.JavaWordCount
mainApplicationFile: "local:///opt/spark/examples/target/original-spark-examples_2.11-2.4.6-SNAPSHOT.jar"
arguments:
- "s3a://mytestbucket/mydata"
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.5
sidecars:
- name: minio-lb
image: "minio/sidekick:v1.0.0"
imagePullPolicy: Always
args: ["--health-path", "/minio/health/ready", "--address", ":9000", "http://minio-distributed-{0...3}.minio-distributed-svc.spark-operator.svc.cluster.local:9000"]
ports:
- containerPort: 9000
executor:
cores: 1
instances: 4
memory: "512m"
labels:
version: 2.4.5
sidecars:
- name: minio-lb
image: "minio/sidekick:v1.0.0"
imagePullPolicy: Always
args: ["--health-path", "/minio/health/ready", "--address", ":9000", "http://minio-distributed-{0...3}.minio-distributed-svc.spark-operator.svc.cluster.local:9000"]
ports:
- containerPort: 9000
kubectl create -f spark-job.yaml
kubectl logs -f --namespace spark-operator spark-minio-app-driver spark-kubernetes-driver
High Performance S3 Cache
S3 compatible object store can be configured for shared cache storage. This will allow applications using Sidekick load balancer to share a distributed cache, thus allowing hot tier caching. The cache can be any S3 compatible object store either within the network or remote, offering vastly improved time to first byte for applications, while also fully utilizing cache storage capacity and reducing network traffic.
Run sidekick configured with high performance cache on baremetal
Caching can be enabled by setting the cache environment variables for sidekick which specify the endpoint of S3 compatible object store, access key, secret key to authenticate to the store. Objects are cached on GET to the shared store if object from the backend exceeds a configurable minimum size. Default minimum size is 1MB.
export SIDEKICK_CACHE_ENDPOINT="http://minio-remote:9000"
export SIDEKICK_CACHE_ACCESS_KEY="minio"
export SIDEKICK_CACHE_SECRET_KEY="minio123"
export SIDEKICK_CACHE_BUCKET="cache01"
export SIDEKICK_CACHE_MIN_SIZE=64MB
export SIDEKICK_CACHE_HEALTH_DURATION=20
sidekick --health-path=/minio/health/ready http://minio{1...16}:9000
Run the spark job in k8s
Following example shows on how to configure sidekick as high performance cache sidecar with spark orchestrator framework on kubernetes environment.
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-minio-app
namespace: spark-operator
spec:
sparkConf:
spark.kubernetes.allocation.batch.size: "50"
hadoopConf:
"fs.s3a.endpoint": "http://127.0.0.1:9000"
"fs.s3a.access.key": "minio"
"fs.s3a.secret.key": "minio123"
"fs.s3a.path.style.access": "true"
"fs.s3a.impl": "org.apache.hadoop.fs.s3a.S3AFileSystem"
type: Scala
sparkVersion: 2.4.5
mode: cluster
image: minio/spark:v2.4.5-hadoop-3.1
imagePullPolicy: Always
restartPolicy:
type: OnFailure
onFailureRetries: 3
onFailureRetryInterval: 10
onSubmissionFailureRetries: 5
onSubmissionFailureRetryInterval: 20
mainClass: org.apache.spark.examples.JavaWordCount
mainApplicationFile: "local:///opt/spark/examples/target/original-spark-examples_2.11-2.4.6-SNAPSHOT.jar"
arguments:
- "s3a://mytestbucket/mydata"
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.5
sidecars:
- name: minio-lb
image: "minio/sidekick:v0.5.8"
imagePullPolicy: Always
args: ["--health-path", "/minio/health/ready", "--address", ":9000", "http://minio-distributed-{0...3}.minio-distributed-svc.spark-operator.svc.cluster.local:9000"]
env:
- name: SIDEKICK_CACHE_ENDPOINT
value: "http://minio-remote:9000"
- name: SIDEKICK_CACHE_ACCESS_KEY
value: "minio"
- name: SIDEKICK_CACHE_SECRET_KEY
value: "minio123"
- name: SIDEKICK_CACHE_BUCKET
value: "cache01"
- name: SIDEKICK_CACHE_MIN_SIZE
value: "32MiB"
- name: SIDEKICK_CACHE_HEALTH_DURATION
value: "20"
ports:
- containerPort: 9000
executor:
cores: 1
instances: 4
memory: "512m"
labels:
version: 2.4.5
sidecars:
- name: minio-lb
image: "minio/sidekick:v0.5.8"
imagePullPolicy: Always
args: ["--health-path", "/minio/health/ready", "--address", ":9000", "http://minio-distributed-{0...3}.minio-distributed-svc.spark-operator.svc.cluster.local:9000"]
env:
- name: SIDEKICK_CACHE_ENDPOINT
value: "https://minio-remote:9000"
- name: SIDEKICK_CACHE_ACCESS_KEY
value: "minio"
- name: SIDEKICK_CACHE_SECRET_KEY
value: "minio123"
- name: SIDEKICK_CACHE_BUCKET
value: "cache01"
- name: SIDEKICK_CACHE_MIN_SIZE
value: "32MiB"
- name: SIDEKICK_CACHE_HEALTH_DURATION
value: "20"
ports:
- containerPort: 9000
kubectl create -f spark-job.yaml
kubectl logs -f --namespace spark-operator spark-minio-app-driver spark-kubernetes-driver
Features
-
Sidekick cache layer is implemented as a high performance middleware wrapper around the Sidekick load balancer. All GET requests that qualify for caching per the RFC 7234 cache specifications and exceeding minimum configured size are streamed simultaneously to the application and the S3 cache. This allows simple, fast and zero memory overhead caching without affecting performance.
-
If an object is already cached to S3 store, the ETag and LastModified date are verified with the backend unless the Cache-Control header explicitly specifies "immutable" or "only-if-cached". Any cached entry that fails the ETag and/or LastModified checks or deleted from the backend is cache evicted automatically.
-
When a cache resource is stale, the resource is validated with the backend with a If-None-Match header to check if it is in fact still fresh. If so, the backend returns a 304 (Not Modified) header without sending the body of the requested resource, saving some bandwidth.
-
Sidekick cache honors standard HTTP caching policies such as 'Cache-Control', 'Expiry' etc. specified in request and response directives.
-
GET requests with Range headers are not cached to keep the codebase simple.
-
Health-Check: Health check is provided at the path "/v1/health". It returns "200 OK" even if any one of the sites is reachable, else it returns "502 Bad Gateway" error.