brianyiktaktsui / Skymap
Labels
Projects that are alternatives of or similar to Skymap
Click here for quick-start to go from data slicing to publication figures in < 2 minutes
from IPython.display import HTML
HTML('<img src="./Figures/QuickStart.gif">')

Table of Contents
(Links are clickable if u open the README.ipynb in JupyterNotebook)
Feel free to contact me @: [email protected] (I will try to reply within 3 days)
Summary
Skymap is a standalone database that aims to offer:
-
a single data matrix for each omic layer for each species that spans a total of >400k sequencing runs from all the public studies, which is done by reprocessing petabytes worth of sequencing data. Here is how much data we have reprocessed from the SRA:
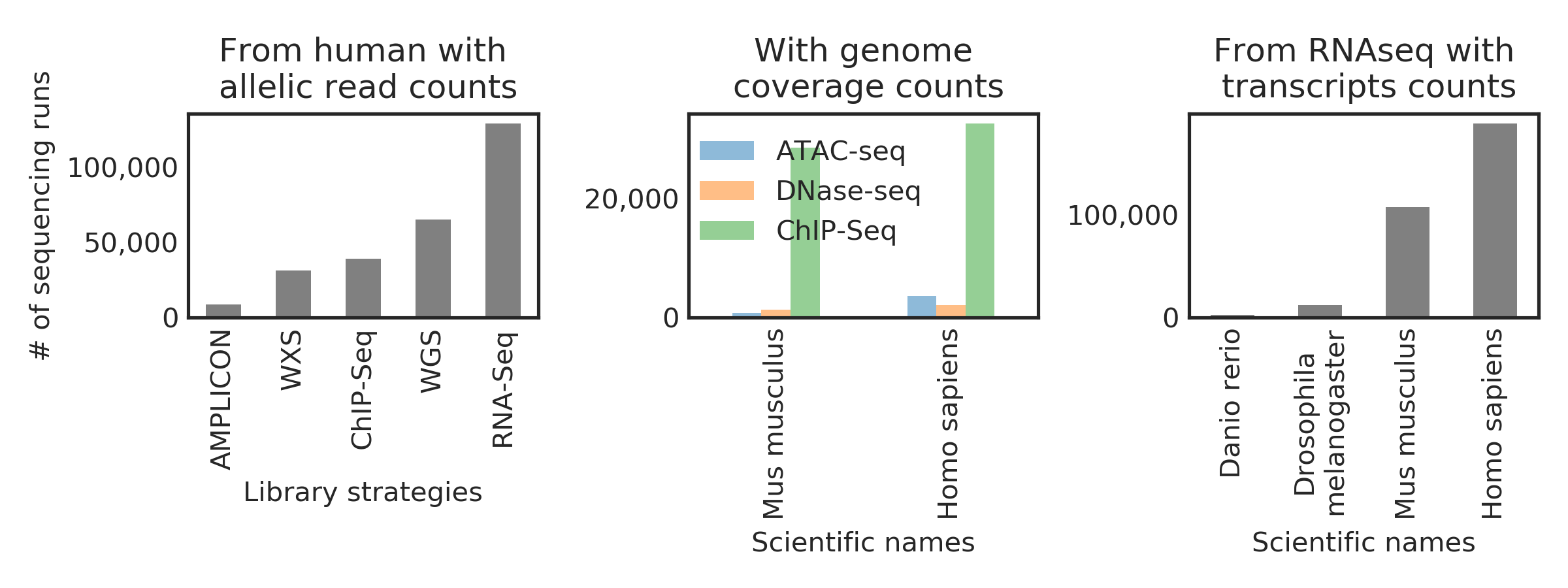
- a biological metadata file that describe the relationships between the sequencing runs and also the keywords extracted from over 3 million freetext annotations using NLP.
- a technical metadata file that describes the relationships between the sequencing runs.

Solution: three tables to related > 100k experiments:
For examples, all the variant data and the data columns can be interpolated like this:

Where they can all fit into your personal computer.
Click here to check out the quick start page and start playing around with the data
Quick-installation-10-mins
-
install miniconda/anaconda with python version >=3.4 (won't work with python 2)
-
Copy and paste to run this following line in unix terminal
conda create --yes -n skymap jupyter python=3.6 pandas=0.23.4 && source activate skymap && jupyter-notebook
-
Choose one of the following notebooks to run. The code will automatically update your python pandas, create a new conda environment if necessary.
- loadVariantDataBySRRID.ipynb: requires 1GB of disk space and 5GB of RAM.
- loadingRNAseqByGene.ipynb: requires 20GB of disk space and 1GB RAM.
-
Click "Run All" to execute all the cells. The notebook will download the example data, install the depedencies and run the data query example.
Check here for more info on executing jupyter notebook
Diagnosis:
- If you run into errors from packages, try the versions I used: python v3.6.5, pandas v0.23.4, synapse client v1.8.1.
- If sage synapse download fails, download the corresponding python pandas pickle using the web interface instead (https://www.synapse.org/#!Synapse:syn11415602/files/) and read in the pickle using pandas.read_pickle.
Data directory and loading examples
I tried to keep the loading to be as simple as possible. The jupyter-notebook each have <10 lines of python codes and package dependency on python pandas only. The memory requirement are all less than 5G.
-omic data
| Title | Data URL | Jupyter-notebook loading examples | Format | Uses |
|---|---|---|---|---|
| Loading allelic read counts by SRR (SRA sequencing run) ID | ftp://download.hannahcarterlab.org/all_seq/snp/mergedBySrr/ | click me to view | python pandas pickle dataframe | Variant, CNV detection |
| Expression matrices | ftp://download.hannahcarterlab.org/all_seq/rnaseq_merged/ | click me to view | numpy array | Expression level quantification |
| Read coverage | - | availability depending upon demand | - | ChIP Peak detection |
| Microbe quantification | - | availability depending upon demand | - | Microbiome community detection |
Metadata
All the metadtata files are located at sage synapse folder: https://www.synapse.org/#!Synapse:syn15661258
| Title | File name | Jupyter-notebook loading examples | Format |
|---|---|---|---|
| biospecieman annotations | allSRS.pickle.gz | click me to view | python pandas pickle dataframe |
| experimental annotations | allSRX.pickle.gz | click me to view | python pandas pickle dataframe |
| biospeiciman experimental and sequencing runs mappings. sequencing and QC stats | sra_dump.fastqc.bowtie_algn.pickle | click me to view | python pandas pickle dataframe |
Axulilary
| Title | File name |
|---|---|
| Distribution of data processed over time | checkProgress.ipynb |
| Generate RNAseq references | generateReferences.ipynb |
| Check the distribution of the reprocessed data | data_count.ipynb |
Example jupyter notebook analysis using reprocessed data
Locating variant and correlating with RNAseq and metadata
This is probably the best example that give you an idea on how to go from data slicing in Skymap to basic data analysis.
High resolution mouse developmental hierachy map
Aggregating many studies (node) to form a smooth mouse developmental hierachy map. By integrating the vast amount of public data, we can cover many developmental time points, which sometime we can see a more transient expression dynamics both across tissues and within tissues over developmental time course.
Each componenet represent a tissue. Each node represent a particular study at a particular time unit. The color is base on the developmental time extracted from experimental annotation using regex. The node size represent the # of sequencing runs in that particulr time point and study. Each edge represent a differentiate-to or part-of relationship.
 And you can easily overlay gene expression level on top of it. As an example, Tp53 expression is known to be tightly regulated in development. Let's look at the dynamic of Tp53 expression over time and spatial locations in the following plot.
And you can easily overlay gene expression level on top of it. As an example, Tp53 expression is known to be tightly regulated in development. Let's look at the dynamic of Tp53 expression over time and spatial locations in the following plot.

Simple RNAseq data slicing and hypothesis testing
Methods
Slides
Google docs and slides with links pointing to jupyter-notebooks: The numbers from the jupyter notebooks will be different from the manuscript as there are more data being incoperated everyday. The hope is that it can help you understand each number and figures from the manuscript.
| Title | Mansucript URL | Figures URL |
|---|---|---|
| Extracting allelic read counts from 250,000 human sequencing runs in Sequence Read Archive | https://docs.google.com/document/d/1BGGQOpWczOwan9STqs-J9zpa8A-aj4aJ1RND_qKzRFs | https://docs.google.com/presentation/d/1dERUDHh2ab8UdPaHa-ki-8RMae6yi2eYJQM4b7ArVog |
| Meta-analysis using NLP (Metamap) and reprocessed RNAseq data | https://docs.google.com/presentation/d/14vLJJQ6ziw-2aLDoQAJGyv1sYo5ENzljsqsbZr9jNLM |
| Title | google docs | google slides |
|---|---|---|
| Extracting allelic read counts from 250,000 human sequencing runs in Sequence Read Archive | https://docs.google.com/document/d/1BGGQOpWczOwan9STqs-J9zpa8A-aj4aJ1RND_qKzRFs | https://docs.google.com/presentation/d/1dERUDHh2ab8UdPaHa-ki-8RMae6yi2eYJQM4b7ArVog |
Unpublished but ongoing manuscripts
| Title | google doc |
|---|---|
| Meta-analysis using NLP (Metamap) and reprocessed RNAseq data | https://docs.google.com/document/d/1_nES7vroX7lCwf5NSNBVZ1k2iubYm5wLeFqusq5aZuk |
Pipeline
The way I organized the code is trying to keep the code as simple as possible. For each pipeline, it has 6 scripts, <500 lines each to ensure readability. Run each pipeliine starting with calcuate_uprocessed.py, which calculate the number of files still require for processing.
If you happen to want to make a copy of the pipeline:
-
make a copy of the pipeline by cloning this github repo,
-
conda env create -n environment_conda_py26_btsui --force -f ./conda_envs/environment_conda_py26_btsui.yml -
conda env create -n environment_conda_py36_btsui --force -f ./conda_envs/environment_conda_py36_btsui.yml -
For Python 2 codes,
source activate environment_conda_py26_btsuibefore running -
For Python 3 codes,
source activate environment_conda_py36_btsuibefore running
Repalce my directory (/cellar/users/btsui/Project/METAMAP/code/metamap/)with your directory if you wanna run it.
Internal: login to an nrnb-node to run the following notebooks.
Here are the scripts:
Metadata layout axuliary
|Column | meaning| |: ---: | :---| | new_ScientificName | the string which the pipeline will use for matching with the reference genome as the species | ScientificName | original scientific name extracted from NCBI SRS|
Acknowledgement
Please considering citing if you are using Skymap. (https://www.biorxiv.org/content/early/2018/08/07/386441)
We want to thank for the advice and resources from Dr. Hannah Carter (my PI), Dr. Jill Mesirov, Dr. Trey Ideker and Shamin Mollah. We also want to thank Dr. Ruben Arbagayen, Dr. Nate Lewis for their suggestion. The method will soon be posted in bioarchive. Also, we want to thank the Sage Bio Network for hosting the data. We also thank to thank the NCBI for holding all the published raw reads at Sequnece Read Archive.
There are also many people who help tested Skymap: Ben Kellman, Rachel Marty, Daniel Carlin, Spiko van Dam.
Grant money that make this work possible: NIH DP5OD017937,GM103504
Term of use: Use Skymap however you want. Just dont sue me, I have no money.
For why I named it Skymap, I forgot.
Data format and coding style
The storage is in python pandas pickle format. Therefore, the only packges you need to load in the data is numpy and pandas, the backbone of data analysis in python. We keep the process of data loading as lean as possible. Less code means less bugs and less errors. For now, Skymap is geared towards ML/data science folks who are hungry for the vast amount of data and ain't afraid of coding. I will port the data to native HDF5 format to reduce platform dependency once I get a chance.
I tried to keep the code and parameters to be lean and self-explanatory for your reference.
References
ISMB 2018 poster: https://github.com/brianyiktaktsui/Skymap/blob/master/ISMB_poster_Skymap.pdf
Preprint on allelic read counts: https://www.synapse.org/#!Synapse:syn11415602/files/
Data: https://www.synapse.org/#!Synapse:syn11415602/files/
Manuscripts in biorxiv related to this project
| Title | URL to manuscript | github |
|---|---|---|
| Extracting allelic read counts from 250,000 human sequencing runs in Sequence Read Archive | https://www.biorxiv.org/content/biorxiv/early/2018/08/07/386441.full.pdf | |
| Deep biomedical named entity recognition NLP engine | https://www.biorxiv.org/content/early/2018/09/12/414136 | https://github.com/brianyiktaktsui/DEEP_NLP |
!ls -lath /nrnb/users/btsui/Data/merged/snp/hg38/mergedBySRR_smallerChunk/ |head
total 59G
drwxr-xr-x 2 btsui users 128K Oct 4 14:15 .
-rw-r--r-- 1 btsui users 3.8M Oct 4 14:15 1581000.pickle.gz
-rw-r--r-- 1 btsui users 8.6M Oct 4 14:15 1558000.pickle.gz
-rw-r--r-- 1 btsui users 822K Oct 4 14:15 1524000.pickle.gz
-rw-r--r-- 1 btsui users 760K Oct 4 14:15 1543000.pickle.gz
-rw-r--r-- 1 btsui users 2.3M Oct 4 14:15 1572000.pickle.gz
-rw-r--r-- 1 btsui users 3.7M Oct 4 14:15 1589000.pickle.gz
-rw-r--r-- 1 btsui users 726K Oct 4 14:15 1590000.pickle.gz
-rw-r--r-- 1 btsui users 3.4M Oct 4 14:15 1520000.pickle.gz
ls: write error: Broken pipe
#!mkdir DEEP_NLP
#!find -name "TemporalQuery_V4_all_clean.ipynb"
!find . -name "*pcr*.ipynb" -print
#!grep -rn "# of sequencing runs <br>with <b>transcript counts</b> profile extracted"
!grep -r --include=\*.ipynb 'allSRS' ./
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "|allSRS.index.get_level_values(0)| SRS ids|\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "|allSRS.index.get_level_values(1)| BioSample attribute|\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "|allSRS.values|textual annotation from submitters|"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "-rw-r--r-- 1 btsui users 2.1G Oct 13 15:52 allSRS.pickle\r\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "-rw-r--r-- 1 btsui users 169M Dec 15 21:48 allSRS.pickle.gz\r\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "-rw-r--r-- 1 btsui users 7.6M Nov 20 15:56 allSRS.with_processed_data.flat.pickle.gz\r\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "-rw-r--r-- 1 btsui users 26M Oct 16 16:50 allSRS.with_processed_data.pickle.gz\r\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "allSRS_pickle_dir='/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz'\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "allSRS=pd.read_pickle(allSRS_pickle_dir)"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "scientificNameS=allSRS[allSRS.index.get_level_values(1)=='SCIENTIFIC_NAME']"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "\u001b[0;32m<ipython-input-32-3f33375cd7a1>\u001b[0m in \u001b[0;36m<module>\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mallSRS\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mallSRS\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mcontains\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'diabet'\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0mcase\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0;32mFalse\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "allSRS.head()"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "memoryS=allSRS.reset_index().memory_usage()"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "memoryS=allSRS.memory_usage()"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "print (\"# of samples retrieved:\",allSRS.index.get_level_values(0).nunique())"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "m_blood=allSRS.str.contains(query_keyword)\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "hitS=allSRS[m_blood]"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "allSRS.loc['ERS069382']"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "age_m=allSRS.index.get_level_values(1)=='age'\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "allSRS_age=allSRS[age_m]\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "allSRS_age.head()"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "print (\"# of samples:\",len(allSRS_age))"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "%time digitS=allSRS_age.str.extract(\"(\\d+)\",expand=False)\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "%time unitS=allSRS_age.str.extract(\"(month|day|year)\",expand=False)\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "ageAnnotDf=pd.DataFrame({'digit':digitS,'unit':unitS,'original_text':allSRS_age}).dropna()\n",
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "allSRS.index.get_level_values(1).nunique()"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "m=allSRS.str.contains('diabet',case=False)"
./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: "tmpS=allSRS[m]"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "|allSRS.index.get_level_values(0)| SRS ids|\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "|allSRS.index.get_level_values(1)| BioSample attribute|\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "|allSRS.values|textual annotation from submitters|"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "-rw-r--r-- 1 btsui users 2.1G Oct 13 15:52 allSRS.pickle\r\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "-rw-r--r-- 1 btsui users 169M Dec 15 21:48 allSRS.pickle.gz\r\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "-rw-r--r-- 1 btsui users 7.6M Nov 20 15:56 allSRS.with_processed_data.flat.pickle.gz\r\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "-rw-r--r-- 1 btsui users 26M Oct 16 16:50 allSRS.with_processed_data.pickle.gz\r\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "allSRS_pickle_dir='/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz'\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "allSRS=pd.read_pickle(allSRS_pickle_dir)"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "scientificNameS=allSRS[allSRS.index.get_level_values(1)=='SCIENTIFIC_NAME']"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "\u001b[0;32m<ipython-input-32-3f33375cd7a1>\u001b[0m in \u001b[0;36m<module>\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mallSRS\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mallSRS\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mcontains\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'diabet'\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0mcase\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0;32mFalse\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "allSRS.head()"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "memoryS=allSRS.reset_index().memory_usage()"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "memoryS=allSRS.memory_usage()"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "print (\"# of samples retrieved:\",allSRS.index.get_level_values(0).nunique())"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "m_blood=allSRS.str.contains(query_keyword)\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "hitS=allSRS[m_blood]"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "allSRS.loc['ERS069382']"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "age_m=allSRS.index.get_level_values(1)=='age'\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "allSRS_age=allSRS[age_m]\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "allSRS_age.head()"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "print (\"# of samples:\",len(allSRS_age))"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "%time digitS=allSRS_age.str.extract(\"(\\d+)\",expand=False)\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "%time unitS=allSRS_age.str.extract(\"(month|day|year)\",expand=False)\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "ageAnnotDf=pd.DataFrame({'digit':digitS,'unit':unitS,'original_text':allSRS_age}).dropna()\n",
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "allSRS.index.get_level_values(1).nunique()"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "m=allSRS.str.contains('diabet',case=False)"
./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: "tmpS=allSRS[m]"
./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: "%time allSRS_S=pd.read_pickle(\"/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz\")"
./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: "allSRS_S.head()"
./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: "allSRS_S.index.names=['SRS_ID','attribute']"
./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: "attribute_array=allSRS_S.index.get_level_values('attribute')"
./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: "%time primary_cancer_m=allSRS_S.str.contains('primary.*tumor|cancer',case=False)"
./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: "cancer_m=allSRS_S.str.contains('oma',case=False)"
./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: "tissueS=allSRS_S[primary_cancer_m]\n",
./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: "cellLineS=allSRS_S[celline_m]"
./Analysis/ExampleSNPSliceForJisoo.ipynb: "allSRSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'"
./Analysis/ExampleSNPSliceForJisoo.ipynb: "mySrsS=pd.read_pickle(allSRSDir)"
./Analysis/README.ipynb: "allSRS.pickle.gz\t\t\tsra_dump.fastqc.bowtie_algn.pickle\r\n",
./Analysis/merge_variant_aligning_statistics.ipynb: "README.ipynb:984: \"allSRS.pickle.gz\\t\\t\\tsra_dump.fastqc.bowtie_algn.pickle\\r\\n\",\n",
./Analysis/.ipynb_checkpoints/merge_variant_aligning_statistics-checkpoint.ipynb: "README.ipynb:984: \"allSRS.pickle.gz\\t\\t\\tsra_dump.fastqc.bowtie_algn.pickle\\r\\n\",\n",
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount-checkpoint.ipynb: "allSRS_S=pd.read_pickle(\"/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz\")"
./Analysis/.ipynb_checkpoints/ExampleSNPSliceForJisoo-checkpoint.ipynb: "allSRSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'"
./Analysis/.ipynb_checkpoints/ExampleSNPSliceForJisoo-checkpoint.ipynb: "mySrsS=pd.read_pickle(allSRSDir)"
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: "%time allSRS_S=pd.read_pickle(\"/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz\")"
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: "allSRS_S.head()"
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: "allSRS_S.index.names=['SRS_ID','attribute']"
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: "attribute_array=allSRS_S.index.get_level_values('attribute')"
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: "%time primary_cancer_m=allSRS_S.str.contains('primary.*tumor|cancer',case=False)"
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: "cancer_m=allSRS_S.str.contains('oma',case=False)"
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: "tissueS=allSRS_S[primary_cancer_m]\n",
./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: "cellLineS=allSRS_S[celline_m]"
./Analysis/.ipynb_checkpoints/SingleCellLeukemia-checkpoint.ipynb: "metaDataMappingSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\n",
./Analysis/.ipynb_checkpoints/SingleCellLeukemia-checkpoint.ipynb: "metaDataMappingSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\n",
./Analysis/SingleCellLeukemia.ipynb: "metaDataMappingSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\n",
./Analysis/SingleCellLeukemia.ipynb: "metaDataMappingSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\n",
./.ipynb_checkpoints/README-checkpoint.ipynb: "| biospecieman annotations| allSRS.pickle.gz | [click me to view](./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb)| python pandas pickle dataframe|\n",
./NLP_spacy/.ipynb_checkpoints/Untitled-checkpoint.ipynb: "sampleS=pd.read_pickle('/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle')"
./NLP_spacy/Untitled.ipynb: "sampleS=pd.read_pickle('/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle')"
./DEEP_NLP/.ipynb_checkpoints/EmbeddingGeneration-checkpoint.ipynb: "inS_dir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\n",
./DEEP_NLP/EmbeddingGeneration.ipynb: "inS_dir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\n",
./README.ipynb: "| biospecieman annotations| allSRS.pickle.gz | [click me to view](./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb)| python pandas pickle dataframe|\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"|allSRS.index.get_level_values(0)| SRS ids|\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"|allSRS.index.get_level_values(1)| BioSample attribute|\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"|allSRS.values|textual annotation from submitters|\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"-rw-r--r-- 1 btsui users 2.1G Oct 13 15:52 allSRS.pickle\\r\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"-rw-r--r-- 1 btsui users 169M Dec 15 21:48 allSRS.pickle.gz\\r\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"-rw-r--r-- 1 btsui users 7.6M Nov 20 15:56 allSRS.with_processed_data.flat.pickle.gz\\r\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"-rw-r--r-- 1 btsui users 26M Oct 16 16:50 allSRS.with_processed_data.pickle.gz\\r\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"allSRS_pickle_dir='/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz'\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"allSRS=pd.read_pickle(allSRS_pickle_dir)\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"scientificNameS=allSRS[allSRS.index.get_level_values(1)=='SCIENTIFIC_NAME']\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"\\u001b[0;32m<ipython-input-32-3f33375cd7a1>\\u001b[0m in \\u001b[0;36m<module>\\u001b[0;34m()\\u001b[0m\\n\\u001b[0;32m----> 1\\u001b[0;31m \\u001b[0mallSRS\\u001b[0m\\u001b[0;34m[\\u001b[0m\\u001b[0mallSRS\\u001b[0m\\u001b[0;34m.\\u001b[0m\\u001b[0mstr\\u001b[0m\\u001b[0;34m.\\u001b[0m\\u001b[0mcontains\\u001b[0m\\u001b[0;34m(\\u001b[0m\\u001b[0;34m'diabet'\\u001b[0m\\u001b[0;34m,\\u001b[0m\\u001b[0mcase\\u001b[0m\\u001b[0;34m=\\u001b[0m\\u001b[0;32mFalse\\u001b[0m\\u001b[0;34m)\\u001b[0m\\u001b[0;34m]\\u001b[0m\\u001b[0;34m\\u001b[0m\\u001b[0m\\n\\u001b[0m\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"allSRS.head()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"memoryS=allSRS.reset_index().memory_usage()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"memoryS=allSRS.memory_usage()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"print (\\\"# of samples retrieved:\\\",allSRS.index.get_level_values(0).nunique())\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"m_blood=allSRS.str.contains(query_keyword)\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"hitS=allSRS[m_blood]\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"allSRS.loc['ERS069382']\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"age_m=allSRS.index.get_level_values(1)=='age'\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"allSRS_age=allSRS[age_m]\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"allSRS_age.head()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"print (\\\"# of samples:\\\",len(allSRS_age))\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"%time digitS=allSRS_age.str.extract(\\\"(\\\\d+)\\\",expand=False)\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"%time unitS=allSRS_age.str.extract(\\\"(month|day|year)\\\",expand=False)\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"ageAnnotDf=pd.DataFrame({'digit':digitS,'unit':unitS,'original_text':allSRS_age}).dropna()\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"allSRS.index.get_level_values(1).nunique()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"m=allSRS.str.contains('diabet',case=False)\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb: \"tmpS=allSRS[m]\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"|allSRS.index.get_level_values(0)| SRS ids|\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"|allSRS.index.get_level_values(1)| BioSample attribute|\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"|allSRS.values|textual annotation from submitters|\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"-rw-r--r-- 1 btsui users 2.1G Oct 13 15:52 allSRS.pickle\\r\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"-rw-r--r-- 1 btsui users 169M Dec 15 21:48 allSRS.pickle.gz\\r\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"-rw-r--r-- 1 btsui users 7.6M Nov 20 15:56 allSRS.with_processed_data.flat.pickle.gz\\r\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"-rw-r--r-- 1 btsui users 26M Oct 16 16:50 allSRS.with_processed_data.pickle.gz\\r\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"allSRS_pickle_dir='/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz'\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"allSRS=pd.read_pickle(allSRS_pickle_dir)\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"scientificNameS=allSRS[allSRS.index.get_level_values(1)=='SCIENTIFIC_NAME']\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"\\u001b[0;32m<ipython-input-32-3f33375cd7a1>\\u001b[0m in \\u001b[0;36m<module>\\u001b[0;34m()\\u001b[0m\\n\\u001b[0;32m----> 1\\u001b[0;31m \\u001b[0mallSRS\\u001b[0m\\u001b[0;34m[\\u001b[0m\\u001b[0mallSRS\\u001b[0m\\u001b[0;34m.\\u001b[0m\\u001b[0mstr\\u001b[0m\\u001b[0;34m.\\u001b[0m\\u001b[0mcontains\\u001b[0m\\u001b[0;34m(\\u001b[0m\\u001b[0;34m'diabet'\\u001b[0m\\u001b[0;34m,\\u001b[0m\\u001b[0mcase\\u001b[0m\\u001b[0;34m=\\u001b[0m\\u001b[0;32mFalse\\u001b[0m\\u001b[0;34m)\\u001b[0m\\u001b[0;34m]\\u001b[0m\\u001b[0;34m\\u001b[0m\\u001b[0m\\n\\u001b[0m\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"allSRS.head()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"memoryS=allSRS.reset_index().memory_usage()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"memoryS=allSRS.memory_usage()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"print (\\\"# of samples retrieved:\\\",allSRS.index.get_level_values(0).nunique())\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"m_blood=allSRS.str.contains(query_keyword)\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"hitS=allSRS[m_blood]\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"allSRS.loc['ERS069382']\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"age_m=allSRS.index.get_level_values(1)=='age'\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"allSRS_age=allSRS[age_m]\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"allSRS_age.head()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"print (\\\"# of samples:\\\",len(allSRS_age))\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"%time digitS=allSRS_age.str.extract(\\\"(\\\\d+)\\\",expand=False)\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"%time unitS=allSRS_age.str.extract(\\\"(month|day|year)\\\",expand=False)\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"ageAnnotDf=pd.DataFrame({'digit':digitS,'unit':unitS,'original_text':allSRS_age}).dropna()\\n\",\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"allSRS.index.get_level_values(1).nunique()\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"m=allSRS.str.contains('diabet',case=False)\"\n",
./README.ipynb: "./clean_notebooks/ExampleDataLoading/.ipynb_checkpoints/loadInMetaData-checkpoint.ipynb: \"tmpS=allSRS[m]\"\n"
./README.ipynb: "./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: \"%time allSRS_S=pd.read_pickle(\\\"/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz\\\")\"\n",
./README.ipynb: "./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: \"allSRS_S.head()\"\n",
./README.ipynb: "./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: \"allSRS_S.index.names=['SRS_ID','attribute']\"\n",
./README.ipynb: "./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: \"attribute_array=allSRS_S.index.get_level_values('attribute')\"\n",
./README.ipynb: "./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: \"%time primary_cancer_m=allSRS_S.str.contains('primary.*tumor|cancer',case=False)\"\n",
./README.ipynb: "./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: \"cancer_m=allSRS_S.str.contains('oma',case=False)\"\n",
./README.ipynb: "./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: \"tissueS=allSRS_S[primary_cancer_m]\\n\",\n",
./README.ipynb: "./Analysis/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines.ipynb: \"cellLineS=allSRS_S[celline_m]\"\n",
./README.ipynb: "./Analysis/ExampleSNPSliceForJisoo.ipynb: \"allSRSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\"\n",
./README.ipynb: "./Analysis/ExampleSNPSliceForJisoo.ipynb: \"mySrsS=pd.read_pickle(allSRSDir)\"\n",
./README.ipynb: "./Analysis/README.ipynb: \"allSRS.pickle.gz\\t\\t\\tsra_dump.fastqc.bowtie_algn.pickle\\r\\n\",\n",
./README.ipynb: "./Analysis/merge_variant_aligning_statistics.ipynb: \"README.ipynb:984: \\\"allSRS.pickle.gz\\\\t\\\\t\\\\tsra_dump.fastqc.bowtie_algn.pickle\\\\r\\\\n\\\",\\n\",\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/merge_variant_aligning_statistics-checkpoint.ipynb: \"README.ipynb:984: \\\"allSRS.pickle.gz\\\\t\\\\t\\\\tsra_dump.fastqc.bowtie_algn.pickle\\\\r\\\\n\\\",\\n\",\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount-checkpoint.ipynb: \"allSRS_S=pd.read_pickle(\\\"/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz\\\")\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/ExampleSNPSliceForJisoo-checkpoint.ipynb: \"allSRSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/ExampleSNPSliceForJisoo-checkpoint.ipynb: \"mySrsS=pd.read_pickle(allSRSDir)\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: \"%time allSRS_S=pd.read_pickle(\\\"/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz\\\")\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: \"allSRS_S.head()\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: \"allSRS_S.index.names=['SRS_ID','attribute']\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: \"attribute_array=allSRS_S.index.get_level_values('attribute')\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: \"%time primary_cancer_m=allSRS_S.str.contains('primary.*tumor|cancer',case=False)\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: \"cancer_m=allSRS_S.str.contains('oma',case=False)\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: \"tissueS=allSRS_S[primary_cancer_m]\\n\",\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/getBasicDataCounting_AllelicReadCount_PrimaryVsCelllines-checkpoint.ipynb: \"cellLineS=allSRS_S[celline_m]\"\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/SingleCellLeukemia-checkpoint.ipynb: \"metaDataMappingSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\\n\",\n",
./README.ipynb: "./Analysis/.ipynb_checkpoints/SingleCellLeukemia-checkpoint.ipynb: \"metaDataMappingSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\\n\",\n",
./README.ipynb: "./Analysis/SingleCellLeukemia.ipynb: \"metaDataMappingSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\\n\",\n",
./README.ipynb: "./Analysis/SingleCellLeukemia.ipynb: \"metaDataMappingSDir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\\n\",\n",
./README.ipynb: "./.ipynb_checkpoints/README-checkpoint.ipynb: \"| biospecieman annotations| allSRS.pickle.gz | [click me to view](./clean_notebooks/ExampleDataLoading/loadInMetaData.ipynb)| python pandas pickle dataframe|\\n\",\n",
./README.ipynb: "./NLP_spacy/.ipynb_checkpoints/Untitled-checkpoint.ipynb: \"sampleS=pd.read_pickle('/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle')\"\n",
./README.ipynb: "./NLP_spacy/Untitled.ipynb: \"sampleS=pd.read_pickle('/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle')\"\n",
./README.ipynb: "./DEEP_NLP/.ipynb_checkpoints/EmbeddingGeneration-checkpoint.ipynb: \"inS_dir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\\n\",\n",
./README.ipynb: "./DEEP_NLP/EmbeddingGeneration.ipynb: \"inS_dir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\\n\",\n"
./README.ipynb: "!grep -r --include=\\*.ipynb 'allSRS' ./"
./XGS_WGS/uploadMetaDataToSynapseList.ipynb: "uploadDirs=['/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz',\n",
./XGS_WGS/checkSubsetOfMouseAllelicReadCountData.ipynb: "allSRS_pickle_dir='/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz'\n",
./XGS_WGS/checkSubsetOfMouseAllelicReadCountData.ipynb: "allSRS=pd.read_pickle(allSRS_pickle_dir)"
./XGS_WGS/checkSubsetOfMouseAllelicReadCountData.ipynb: "allSRS_specie=allSRS[allSRS.index.get_level_values(0).isin(mySpecieSrs)]"
./XGS_WGS/checkSubsetOfMouseAllelicReadCountData.ipynb: "query_m=allSRS_specie.str.contains('V600E',case=False)\n"
./XGS_WGS/checkSubsetOfMouseAllelicReadCountData.ipynb: "allSRSWithGenotypes=allSRS_specie.sample(n=10)#[query_m]"
./XGS_WGS/checkSubsetOfMouseAllelicReadCountData.ipynb: "allSRSWithGenotypes"
./XGS_WGS/checkSubsetOfMouseAllelicReadCountData.ipynb: "sample_m=sra_dump_pickle_df.Sample.isin(allSRSWithGenotypes.index.get_level_values(0))\n",
./XGS_WGS/.ipynb_checkpoints/uploadMetaDataToSynapseList-checkpoint.ipynb: "uploadDirs=['/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz',\n",
./XGS_WGS/.ipynb_checkpoints/checkSubsetOfMouseAllelicReadCountData-checkpoint.ipynb: "allSRS_pickle_dir='/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz'\n",
./XGS_WGS/.ipynb_checkpoints/checkSubsetOfMouseAllelicReadCountData-checkpoint.ipynb: "allSRS=pd.read_pickle(allSRS_pickle_dir)"
./XGS_WGS/.ipynb_checkpoints/checkSubsetOfMouseAllelicReadCountData-checkpoint.ipynb: "allSRS_specie=allSRS[allSRS.index.get_level_values(0).isin(mySpecieSrs)]"
./XGS_WGS/.ipynb_checkpoints/checkSubsetOfMouseAllelicReadCountData-checkpoint.ipynb: "\u001b[0;32m<ipython-input-929-85f2763c0099>\u001b[0m in \u001b[0;36m<module>\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mquery_m\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mallSRS_specie\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mcontains\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'tp53.*+/+'\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0mcase\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0;32mFalse\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
./XGS_WGS/.ipynb_checkpoints/checkSubsetOfMouseAllelicReadCountData-checkpoint.ipynb: "query_m=allSRS_specie.str.contains('tp53.*+/+',case=False)\n"
./XGS_WGS/.ipynb_checkpoints/checkSubsetOfMouseAllelicReadCountData-checkpoint.ipynb: "allSRSWithGenotypes=allSRS_specie[query_m]"
./XGS_WGS/.ipynb_checkpoints/checkSubsetOfMouseAllelicReadCountData-checkpoint.ipynb: "sample_m=sra_dump_pickle_df.Sample.isin(allSRSWithGenotypes.index.get_level_values(0))\n",
./XGS_WGS/.ipynb_checkpoints/uploadDataToSynapseList-checkpoint.ipynb: "allSRS.pickle.gz\t\t\tsra_dump.fastqc.bowtie_algn.pickle\r\n",
./Pipelines/Update_SRA_meta_data/RunAll.ipynb: "|merge SRA metadata | [merge SRS and SRX parsed](./../../SRA_META/SRAmerge.ipynb)| | list of pandas series containing list of (SRS,attribute, freetext) |/cellar/users/btsui/Data/nrnb01_nobackup/tmp/METAMAP//splittedInput_SRAMangaer_SRA_META/(allSRS.pickle,allSRX.pickle) |all SRA SRS biospecieman annotation in allSRS.pickle and allSRX.pickle | /cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/ | 10 mins| Python 3|\n",
./Pipelines/Update_SRA_meta_data/RunAll.ipynb: "#!gunzip --keep /data/cellardata/users/btsui/SRA/DUMP/allSRS.pickle.gz"
./Pipelines/Update_SRA_meta_data/RunAll.ipynb: "#allSRS=pd.read_pickle('/data/cellardata/users/btsui/SRA/DUMP/allSRS.pickle')"
./Pipelines/Update_SRA_meta_data/RunAll.ipynb: "#allSRS.index.get_level_values(0).nunique()"
./Pipelines/Update_SRA_meta_data/annotate_SRA_meta_data.ipynb: "srsMergedS=pd.read_pickle(basePickleDir+'allSRS.pickle.gz')\n",
./Pipelines/Update_SRA_meta_data/pull_SRA_meta.ipynb: "8 allSRS.with_processed_data.pickle.gz\n",
./Pipelines/Update_SRA_meta_data/pull_SRA_meta.ipynb: "9 allSRS.with_processed_data.flat.pickle.gz\n",
./Pipelines/Update_SRA_meta_data/pull_SRA_meta.ipynb: "12 allSRS.pickle\n",
./Pipelines/Update_SRA_meta_data/pull_SRA_meta.ipynb: "18 allSRS.pickle.gz\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/pull_SRA_meta-checkpoint.ipynb: "8 allSRS.with_processed_data.pickle.gz\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/pull_SRA_meta-checkpoint.ipynb: "9 allSRS.with_processed_data.flat.pickle.gz\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/pull_SRA_meta-checkpoint.ipynb: "12 allSRS.pickle\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/pull_SRA_meta-checkpoint.ipynb: "18 allSRS.pickle.gz\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/annotate_SRA_meta_data-checkpoint.ipynb: "srsMergedS=pd.read_pickle(basePickleDir+'allSRS.pickle.gz')\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/ExportForMetamap-checkpoint.ipynb: "srsMergedS=pd.read_pickle(basePickleDir+'allSRS.pickle.gz')\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "allSRS_pickle_dir='/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz'\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "allSRS_with_processed_data_flat_dir=allSRS_pickle_dir.replace('.pickle.gz','.with_processed_data.flat.pickle.gz')"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "allSRS_with_processed_data_dir=allSRS_pickle_dir.replace('.pickle.gz','.with_processed_data.pickle.gz')"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "allSRS=pd.read_pickle(allSRS_pickle_dir)"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "#tmpS1=allSRS+';'"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "srs_a=allSRS.index.get_level_values(0)\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "allSRS_processed=allSRS[srs_m]"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "#allSRS_processed.index.names"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "allSRS_processed.to_pickle(allSRS_with_processed_data_dir)"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "tmpS2=pd.Series(data=allSRS_processed.index.get_level_values(1)+\": \"+allSRS_processed.astype(str)+plotlyLineBreaker,\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: " index=allSRS_processed.index)"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "#tmpS1=(allSRS_processed.astype(str)+'; ')\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "%time allSRS_processed_flat=tmpS2.groupby(level=[0]).sum()"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "allSRS_processed_flat.to_pickle(allSRS_with_processed_data_flat_dir)"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "#allSRS_processed_flat"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "#m1=allSRS_processed_flat.str.contains('neuron.*single.*cell')"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "#m2=allSRS_processed_flat.str.contains('single.*cell.*neuron|neuron.*single.*cell')#.sum()"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: "uploadDirs=[sra_dump_pickle_dir,allSRS_pickle_dir,allSRX_pickle_dir,merged_kallisto_run_info_dir,\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: " allSRS_with_processed_data_dir,sra_project_titles_dir,sra_dump_pickle_all_dir,\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: " allSRS_with_processed_data_flat_dir,vcfDir]+snpBedDirs\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: " rsync -Pvu -e \"ssh -i $HOME/.ssh/jupyter_hub.pem\" /cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz [email protected]:~/efs/all_seq/meta_data/.\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/upload_AWS-checkpoint.ipynb: " rsync -Pvu -e \"ssh -i $HOME/.ssh/jupyter_hub.pem\" /cellar/users/btsui/Data/SRA/DUMP/allSRS.with_processed_data.pickle.gz [email protected]:~/efs/all_seq/meta_data/.\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/RunAll-checkpoint.ipynb: "|merge SRA metadata | [merge SRS and SRX parsed](./../../SRA_META/SRAmerge.ipynb)| | list of pandas series containing list of (SRS,attribute, freetext) |/cellar/users/btsui/Data/nrnb01_nobackup/tmp/METAMAP//splittedInput_SRAMangaer_SRA_META/(allSRS.pickle,allSRX.pickle) |all SRA SRS biospecieman annotation in allSRS.pickle and allSRX.pickle | /cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/ | 10 mins| Python 3|\n",
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/RunAll-checkpoint.ipynb: "#!gunzip --keep /data/cellardata/users/btsui/SRA/DUMP/allSRS.pickle.gz"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/RunAll-checkpoint.ipynb: "#allSRS=pd.read_pickle('/data/cellardata/users/btsui/SRA/DUMP/allSRS.pickle')"
./Pipelines/Update_SRA_meta_data/.ipynb_checkpoints/RunAll-checkpoint.ipynb: "#allSRS.index.get_level_values(0).nunique()"
./Pipelines/Update_SRA_meta_data/ExportForMetamap.ipynb: "srsMergedS=pd.read_pickle(basePickleDir+'allSRS.pickle.gz')\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "allSRS_pickle_dir='/cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz'\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "allSRS_with_processed_data_flat_dir=allSRS_pickle_dir.replace('.pickle.gz','.with_processed_data.flat.pickle.gz')"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "allSRS_with_processed_data_dir=allSRS_pickle_dir.replace('.pickle.gz','.with_processed_data.pickle.gz')"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "allSRS=pd.read_pickle(allSRS_pickle_dir)"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "srs_a=allSRS.index.get_level_values(0)\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "allSRS_processed=allSRS[srs_m]"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "#allSRS_processed.index.names"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "allSRS_processed.to_pickle(allSRS_with_processed_data_dir)"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "tmpS2=pd.Series(data=allSRS_processed.index.get_level_values(1)+\": \"+allSRS_processed.astype(str)+plotlyLineBreaker,\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: " index=allSRS_processed.index)"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "#tmpS1=(allSRS_processed.astype(str)+'; ')\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "%time allSRS_processed_flat=tmpS2.groupby(level=[0]).sum()"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "allSRS_processed_flat.to_pickle(allSRS_with_processed_data_flat_dir)"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "#allSRS_processed_flat"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "#m1=allSRS_processed_flat.str.contains('neuron.*single.*cell')"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "#m2=allSRS_processed_flat.str.contains('single.*cell.*neuron|neuron.*single.*cell')#.sum()"
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: "uploadDirs=[sra_dump_pickle_dir,allSRS_pickle_dir,allSRX_pickle_dir,merged_kallisto_run_info_dir,\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: " allSRS_with_processed_data_dir,sra_project_titles_dir,sra_dump_pickle_all_dir,\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: " allSRS_with_processed_data_flat_dir,vcfDir]+snpBedDirs\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: " rsync -Pvu -e \"ssh -i $HOME/.ssh/jupyter_hub.pem\" /cellar/users/btsui/Data/SRA/DUMP/allSRS.pickle.gz [email protected]:~/efs/all_seq/meta_data/.\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: " rsync -Pvu -e \"ssh -i $HOME/.ssh/jupyter_hub.pem\" /cellar/users/btsui/Data/SRA/DUMP/allSRS.with_processed_data.pickle.gz [email protected]:~/efs/all_seq/meta_data/.\n",
./Pipelines/Update_SRA_meta_data/upload_AWS.ipynb: " rsync -Pvu -e \"ssh -i $HOME/.ssh/jupyter_hub.pem\" /cellar/users/btsui/Data/SRA/DUMP/allSRS.with_processed_data.flat.pickle.gz [email protected]:~/efs/all_seq/meta_data/.\n",
./Pipelines/RNAseq/RunAll.ipynb: "-rw-r--r-- 1 btsui users 2.1G Oct 13 15:52 allSRS.pickle\r\n",
./Pipelines/RNAseq/RunAll.ipynb: "-rw-r--r-- 1 btsui users 169M Dec 15 21:48 allSRS.pickle.gz\r\n",
./Pipelines/RNAseq/RunAll.ipynb: "-rw-r--r-- 1 btsui users 7.6M Nov 20 15:56 allSRS.with_processed_data.flat.pickle.gz\r\n",
./Pipelines/RNAseq/RunAll.ipynb: "-rw-r--r-- 1 btsui users 26M Oct 16 16:50 allSRS.with_processed_data.pickle.gz\r\n",
./SRA_META/.ipynb_checkpoints/SRAmerge-checkpoint.ipynb: "srsMergedS.to_pickle(baseOutDir+'allSRS.pickle.gz')\n",
./SRA_META/SRAmerge.ipynb: "srsMergedS.to_pickle(baseOutDir+'allSRS.pickle.gz')\n",
./jupyter-notebooks/clean_notebooks/TemporalQuery_V4_all_clean.ipynb: "#'/cellar/users/btsui/Data/' allSRS.pickle\n",
./jupyter-notebooks/clean_notebooks/TemporalQuery_V4_all_clean.ipynb: "#!find /cellar/users/btsui/Data/ -name \"allSRS.pickle\" -print\n",
./jupyter-notebooks/clean_notebooks/TemporalQuery_V4_all_clean.ipynb: "inS_dir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\n"
./jupyter-notebooks/clean_notebooks/.ipynb_checkpoints/TemporalQuery_V4_all_clean-checkpoint.ipynb: "#'/cellar/users/btsui/Data/' allSRS.pickle\n",
./jupyter-notebooks/clean_notebooks/.ipynb_checkpoints/TemporalQuery_V4_all_clean-checkpoint.ipynb: "#!find /cellar/users/btsui/Data/ -name \"allSRS.pickle\" -print\n",
./jupyter-notebooks/clean_notebooks/.ipynb_checkpoints/TemporalQuery_V4_all_clean-checkpoint.ipynb: "inS_dir='/cellar/users/btsui/Data/nrnb01_nobackup/METAMAP/allSRS.pickle'\n"
./Skymap_legacy-master/jupyter-notebooks/clean_notebooks/TemporalQuery_V4_all_clean.ipynb: "rawAnnotSrsDir='../../Parsing/allSRS.pickle'\n",
./Skymap_legacy-master/Load_RawMetaData.ipynb: "sampleRawAnnotS_Dir='./meta_data/allSRS.pickle'\n",
#!qstat -u btsui