skrusche63 / Spark Elastic
Programming Languages

Integration of Elasticsearch with Spark
This project shows how to easily integrate Apache Spark, a fast and general purpose engine for large-scale data processing, with Elasticsearch, a real-time distributed search and analytics engine.
Spark is an in-memory processing framework and outperforms Hadoop up to a factor of 100. Spark is accompanied by
- MLlib, a scalable machine learning library,
- Spark SQL, a unified access platform for structured big data,
- Spark Streaming, a library to build scalable fault-tolerant streaming applications.
If you are more interested in an Elasticsearch plugin-in that brings the power of Predictiveworks. to Elasticsearch, then please refer to Elasticinsight.
Predictiveworks. is an ensemble of dedicated predictive engines that covers a wide range of today's analytics requirements from Association Analysis, to Context-Aware Recommendations up to Text Analysis. Elasticinsight. empowers Elasticsearch to seamlessly uses these multiple engines.
Machine Learning with Elasticsearch
Besides linguistic and semantic enrichment, for data in a search index there is an increasing demand to apply knowledge discovery and data mining techniques, and even predictive analytics to gain deeper insights into the data and further increase their business value.
One of the key prerequisites is to easily connect existing data sources to state-of-the art machine learning and predictive analytics frameworks.
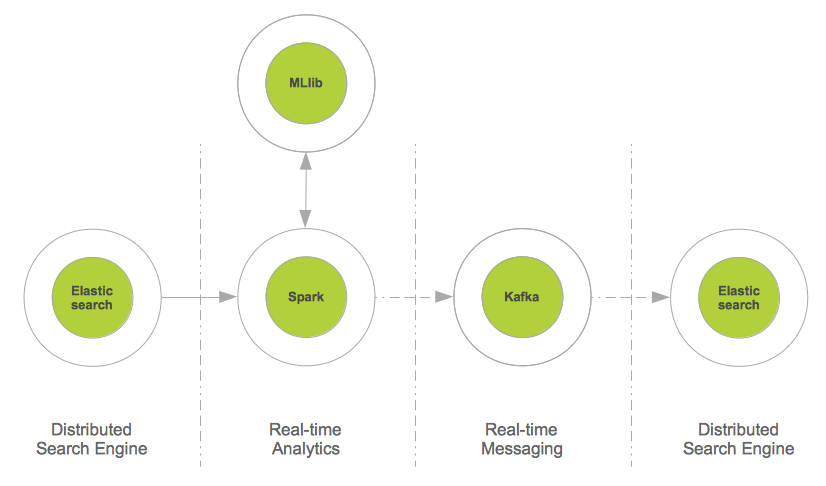
In this project, we give advice how to connect Elasticsearch, a powerful distributed search engine, to Apache Spark and profit from the increasing number of existing machine learning algorithms.
The figure shows the integration pattern for Elasticsearch and Spark from an architectural persepctive and also indicates how to proceed with the enriched content (i.e. the way back to the search index).
The source code below describes a few lines of Scala, that are sufficient to read from Elasticsearch and provide data for further mining and prediction tasks:
val source = sc.newAPIHadoopRDD(conf, classOf[EsInputFormat[Text, MapWritable]], classOf[Text], classOf[MapWritable])
val docs = source.map(hit => {
new EsDocument(hit._1.toString,toMap(hit._2))
})
Document Segmentation with KMeans
From the data format extracted from Elasticsearch RDD[EsDocument] it is just a few lines of Scala to segment these documents with respect to their geo location (latitude,longitude).
From these data a heatmap can be drawn to visualize from which region of world most of the documents come from. The image below shows a multi-colored heatmap, where the colors red, yellow, green and blue indicate different heat ranges.
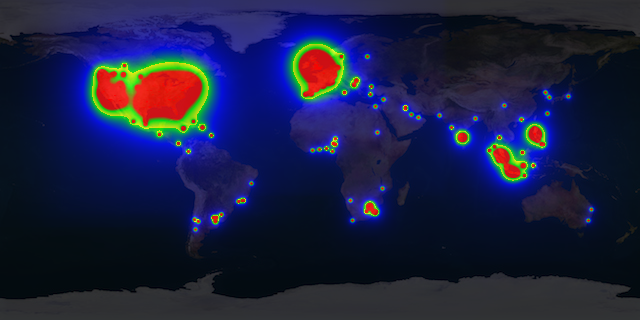
Segmenting documents into specific target groups is not restricted their geo location. Time of the day, product or service categories, total revenue, and other parameters may be used.
For segmentation, the K-Means clustering implementation of MLlib is used:
def cluster(documents:RDD[EsDocument],esConf:Configuration):RDD[(Int,EsDocument)] = {
val fields = esConf.get("es.fields").split(",")
val vectors = documents.map(doc => toVector(doc.data,fields))
val clusters = esConf.get("es.clusters").toInt
val iterations = esConf.get("es.iterations").toInt
/* Train model */
val model = KMeans.train(vectors, clusters, iterations)
/* Apply model */
documents.map(doc => (model.predict(toVector(doc.data,fields)),doc))
}
Clustering Elasticsearch data with K-Means is a first and simple example of how to immediately benefit from the integration with Spark. Other business cases may cover recommendations:
Suppose Elasticsearch is used to index e-commerce transactions on a per user basis, then it is also straightforward to build a recommendation system in just two steps:
- First, implicit user-item ratings have to be derived from the e-commerce transactions, and
- Second, from this item similarities are calculated to provide a recommendation model.
For more information, please read here.
Insights from Elasticsearch with SQL
Spark SQL allows relational queries expressed in SQL to be executed using Spark. This enables to apply queries to Spark data structures and also to Spark data streams (see below).
As SQL queries generate Spark data structures, a mixture of SQL and native Spark operations is also possible, thus providing a sophisticated mechanism to compute valuable insight from data in real-time.
The code example below illustrates how to apply SQL queries on a Spark data structure (RDD) and provide further insight by mixing with native Spark operations.
/*
* Elasticsearch specific configuration
*/
val esConf = new Configuration()
esConf.set("es.nodes","localhost")
esConf.set("es.port","9200")
esConf.set("es.resource", "enron/mails")
esConf.set("es.query", "?q=*:*")
esConf.set("es.table", "docs")
esConf.set("es.sql", "select subject from docs")
...
/*
* Read from ES and provide some insight with Spark & SparkSQL,
* thereby mixing SQL and other Spark operations
*/
val documents = es.documentsAsJson(esConf)
val subjects = es.query(documents, esConf).filter(row => row.getString(0).contains("Re"))
...
def query(documents:RDD[String], esConfig:Configuration):SchemaRDD = {
val query = esConfig.get("es.sql")
val name = esConfig.get("es.table")
val table = sqlc.jsonRDD(documents)
table.registerAsTable(name)
sqlc.sql(query)
}
Real-Time Stream Processing and Elasticsearch
Real-time analytics is a very popular topic with a wide range of application areas:
- High frequency trading (finance),
- Real-time bidding (adtech),
- Real-time social activity (social networks),
- Real-time sensoring (Internet of things),
- Real-time user behavior,
and more, gain tremendous business value from real-time analytics. There exist a lot of popular frameworks to aggregate data in real-time, such as Apache Storm, Apache S4, Apache Samza, Akka Streams, SQLStream to name just a few.
Spark Streaming, which is capable to process about 400,000 records per node per second for simple aggregations on small records, significantly outperforms other popular streaming systems. This is mainly because Spark Streaming groups messages in small batches which are then processed together.
Moreover in case of failure, Spark Streaming batches are only processed once which greatly simplifies the logic (e.g. to make sure some values are not counted multiple times).
Spark Streaming is a layer on top of Spark and transforms and batches data streams from various sources, such as Kafka, Twitter or ZeroMQ into a sequence of Spark RDDs (Resilient Distributed DataSets) using a sliding window. These RDDs can then be manipulated using normal Spark operations.
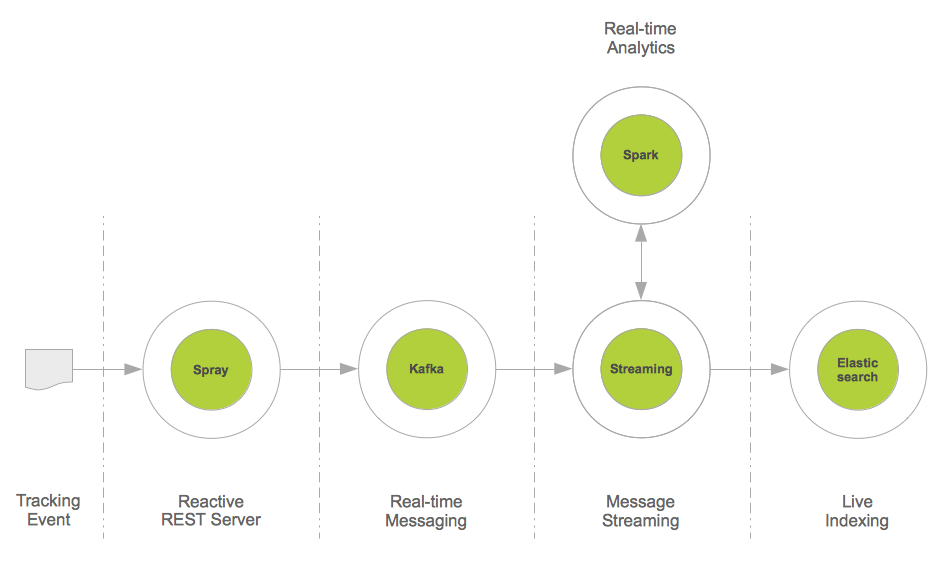
This project provides a real-time data integration pattern based on Apache Kafka, Spark Streaming and Elasticsearch:
Apache Kafka is a distributed publish-subscribe messaging system, that may also be seen as a real-time integration system. For example, Web tracking events are easily sent to Kafka, and may then be consumed by a set of different consumers.
In this project, we use Spark Streaming as a consumer and aggregator of e.g. such tracking data streams, and perform a live indexing. As Spark Streaming is also able to directly compute new insights from data streams, this data integration pattern may be used as a starting point for real-time data analytics and enrichment before search indexing.
The figure below illustrates the architecture of this pattern. For completeness reasons, Spray has been introduced. Spray is an open-source toolkit for building REST/HTTP-based integration layers on top of Scala and Akka. As it is asynchronous, actor-based, fast, lightweight, and modular, it is an easy way to connect Scala applications to the Web.
The code example below illustrates that such an integration pattern may be implemented with just a few lines of Scala code:
val stream = KafkaUtils.createStream[String,Message,StringDecoder,MessageDecoder](ssc, kafkaConfig, kafkaTopics, StorageLevel.MEMORY_AND_DISK).map(_._2)
stream.foreachRDD(messageRDD => {
/**
* Live indexing of Kafka messages; note, that this is also
* an appropriate place to integrate further message analysis
*/
val messages = messageRDD.map(prepare)
messages.saveAsNewAPIHadoopFile("-",classOf[NullWritable],classOf[MapWritable],classOf[EsOutputFormat],esConfig)
})
Most Frequent Items from Streams
Using the architecture as illustrated above not only enables to apply Spark to data streams. It also opens real-time streams to other data processing libraries such as Algebird from Twitter.
Algebird brings, as the name indicates, algebraic algorithms to streaming data. An important representative is Count-Min Sketch which enables to compute the most frequent items from streams in a certain time window. The code example below describes how to apply the CountMinSketchMonoid (Algebird) to compute the most frequent messages from a Kafka Stream with respect to the messages' classification:
object EsCountMinSktech {
def findTopK(stream:DStream[Message]):Seq[(Long,Long)] = {
val DELTA = 1E-3
val EPS = 0.01
val SEED = 1
val PERC = 0.001
val k = 5
var globalCMS = new CountMinSketchMonoid(DELTA, EPS, SEED, PERC).zero
val clases = stream.map(message => message.clas)
val approxTopClases = clases.mapPartitions(clases => {
val localCMS = new CountMinSketchMonoid(DELTA, EPS, SEED, PERC)
clases.map(clas => localCMS.create(clas))
}).reduce(_ ++ _)
approxTopClases.foreach(rdd => {
if (rdd.count() != 0) globalCMS ++= rdd.first()
})
/**
* Retrieve approximate TopK classifiers from the provided messages
*/
val globalTopK = globalCMS.heavyHitters.map(clas => (clas, globalCMS.frequency(clas).estimate))
/*
* Retrieve the top k message classifiers: it may also be interesting to
* return the classifier frequency from this method, ignoring the line below
*/
.toSeq.sortBy(_._2).reverse.slice(0, k)
globalTopK
}
}