dsindex / Syntaxnet
reference code for syntaxnet
Stars: ✭ 189
Programming Languages
python
139335 projects - #7 most used programming language
Labels
Projects that are alternatives of or similar to Syntaxnet
Jest Allure
Generate Allure Report for jest. Allure Report, a flexible lightweight multi-language test report tool with the possibility to add steps, attachments, parameters and so on.
Stars: ✭ 90 (-52.38%)
Mutual labels: tests
Mongodb Memory Server
Spinning up mongod in memory for fast tests. If you run tests in parallel this lib helps to spin up dedicated mongodb servers for every test file in MacOS, *nix, Windows or CI environments (in most cases with zero-config).
Stars: ✭ 1,376 (+628.04%)
Mutual labels: tests
Create Test Server
Creates a minimal Express server for testing
Stars: ✭ 117 (-38.1%)
Mutual labels: tests
Dockertest
Write better integration tests! Dockertest helps you boot up ephermal docker images for your Go tests with minimal work.
Stars: ✭ 2,254 (+1092.59%)
Mutual labels: tests
Xrautomatedtests
XRAutomatedTests is where you can find functional, graphics, performance, and other types of automated tests for your XR Unity development.
Stars: ✭ 77 (-59.26%)
Mutual labels: tests
Kappuccino
A kotlin library to simplify how to do espresso tests on Android.
Stars: ✭ 104 (-44.97%)
Mutual labels: tests
Modern Wasm Starter
🛸 Run C++ code on web and create blazingly fast websites! A starter template to easily create WebAssembly packages using type-safe C++ bindings with automatic TypeScript declarations.
Stars: ✭ 140 (-25.93%)
Mutual labels: tests
Learn Elm Architecture In Javascript
🦄 Learn how to build web apps using the Elm Architecture in "vanilla" JavaScript (step-by-step TDD tutorial)!
Stars: ✭ 173 (-8.47%)
Mutual labels: tests
Awesome Playwright
A curated list of awesome tools, utils and projects using Playwright
Stars: ✭ 79 (-58.2%)
Mutual labels: tests
Go Testdeep
Extremely flexible golang deep comparison, extends the go testing package, tests HTTP APIs and provides tests suite
Stars: ✭ 137 (-27.51%)
Mutual labels: tests
Ember Native Dom Helpers
Test helpers for your integration tests that fire native events
Stars: ✭ 187 (-1.06%)
Mutual labels: tests
Xamarin.forms.mocks
Library for running Xamarin.Forms inside of unit tests
Stars: ✭ 179 (-5.29%)
Mutual labels: tests
Should.js
BDD style assertions for node.js -- test framework agnostic
Stars: ✭ 1,908 (+909.52%)
Mutual labels: tests
Table of Contents generated with DocToc
-
syntaxnet
- description
- history
- how to test
- universal dependency corpus
- training tagger and parser with another corpus
- training parser only
- test new model
- training parser from korean sejong treebank corpus
- test korean parser model
- apply korean POS tagger(Komoran via konlpy)
- tensorflow serving and syntaxnet
- parsey's cousins
- dragnn
- brat annotation tool
- comparison to BIST parser
syntaxnet
description
- test code for syntaxnet
- training and test a model using UD corpus.
- training and test a Korean parser model using the Sejong corpus.
- exporting a trained model and serving(limited to the designated version of syntaxnet(old one))
- training and test a model using dragnn.
- comparision to bist-parser.
history
-
2017. 3. 27- test for dragnn
- version
python : 2.7 bazel : 0.4.3 protobuf : 3.2.0 syntaxnet : 40a5739ae26baf6bfa352d2dec85f5ca190254f8 -
2017. 3. 10- modify for recent version of syntaxnet(tf 1.0), OS X(bash script), universal treebank v2.0
- version
python : 2.7 bazel : 0.4.3 protobuf : 3.0.0b2, 3.2.0 syntaxnet : bc70271a51fe2e051b5d06edc6b9fd94880761d5 -
2016. 8. 16- add 'char-map' to context.pbtxt' for train
- add '--resource_dir' for test
- if you installed old version of syntaxnet(ex, a4b7bb9a5dd2c021edcd3d68d326255c734d0ef0 ), you should specify path to each files in 'context.pbtxt'
- version
syntaxnet : a5d45f2ed20effaabc213a2eb9def291354af1ec
how to test
# after installing syntaxnet.
# gpu supporting : https://github.com/tensorflow/models/issues/248#issuecomment-288991859
$ pwd
/path/to/models/syntaxnet
$ git clone https://github.com/dsindex/syntaxnet.git work
$ cd work
$ echo "hello syntaxnet" | ./demo.sh
# training parser only with parsed corpus
$ ./parser_trainer_test.sh
univeral dependency corpus
- UD official website
- UPPipe
- prepare data
$ cd work
$ mkdir corpus
$ cd corpus
# downloading ud-treebanks-v2.0.tgz
$ tar -zxvf ud-treebanks-v2.0.tgz
$ ls universal-dependencies-2.0
$ UD_Ancient_Greek UD_Basque UD_Czech ....
training tagger and parser with another corpus
# for example, training UD_English.
# detail instructions can be found in https://github.com/tensorflow/models/tree/master/syntaxnet
$ ./train.sh -v -v
...
#preprocessing with tagger
INFO:tensorflow:Seconds elapsed in evaluation: 9.77, eval metric: 99.71%
INFO:tensorflow:Seconds elapsed in evaluation: 1.26, eval metric: 92.04%
INFO:tensorflow:Seconds elapsed in evaluation: 1.26, eval metric: 92.07%
...
#pretrain parser
INFO:tensorflow:Seconds elapsed in evaluation: 4.97, eval metric: 82.20%
...
#evaluate pretrained parser
INFO:tensorflow:Seconds elapsed in evaluation: 44.30, eval metric: 92.36%
INFO:tensorflow:Seconds elapsed in evaluation: 5.42, eval metric: 82.67%
INFO:tensorflow:Seconds elapsed in evaluation: 5.59, eval metric: 82.36%
...
#train parser
INFO:tensorflow:Seconds elapsed in evaluation: 57.69, eval metric: 83.95%
...
#evaluate parser
INFO:tensorflow:Seconds elapsed in evaluation: 283.77, eval metric: 96.54%
INFO:tensorflow:Seconds elapsed in evaluation: 34.49, eval metric: 84.09%
INFO:tensorflow:Seconds elapsed in evaluation: 34.97, eval metric: 83.49%
...
training parser only
# if you have other pos-tagger and want to build parser only from the parsed corpus :
$ ./train_p.sh -v -v
...
#pretrain parser
...
#evaluate pretrained parser
INFO:tensorflow:Seconds elapsed in evaluation: 44.15, eval metric: 92.21%
INFO:tensorflow:Seconds elapsed in evaluation: 5.56, eval metric: 87.84%
INFO:tensorflow:Seconds elapsed in evaluation: 5.43, eval metric: 86.56%
...
#train parser
...
#evaluate parser
INFO:tensorflow:Seconds elapsed in evaluation: 279.04, eval metric: 94.60%
INFO:tensorflow:Seconds elapsed in evaluation: 33.19, eval metric: 88.60%
INFO:tensorflow:Seconds elapsed in evaluation: 32.57, eval metric: 87.77%
...
test new model
$ echo "this is my own tagger and parser" | ./test.sh
...
Input: this is my own tagger and parser
Parse:
tagger NN ROOT
+-- this DT nsubj
+-- is VBZ cop
+-- my PRP$ nmod:poss
+-- own JJ amod
+-- and CC cc
+-- parser NN conj
# original model
$ echo "this is my own tagger and parser" | ./demo.sh
Input: this is my own tagger and parser
Parse:
tagger NN ROOT
+-- this DT nsubj
+-- is VBZ cop
+-- my PRP$ poss
+-- own JJ amod
+-- and CC cc
+-- parser ADD conj
$ echo "Bob brought the pizza to Alice ." | ./test.sh
Input: Bob brought the pizza to Alice .
Parse:
brought VBD ROOT
+-- Bob NNP nsubj
+-- pizza NN dobj
| +-- the DT det
+-- Alice NNP nmod
| +-- to IN case
+-- . . punct
# original model
$ echo "Bob brought the pizza to Alice ." | ./demo.sh
Input: Bob brought the pizza to Alice .
Parse:
brought VBD ROOT
+-- Bob NNP nsubj
+-- pizza NN dobj
| +-- the DT det
+-- to IN prep
| +-- Alice NNP pobj
+-- . . punct
training parser from Sejong treebank corpus
# the corpus is accessible through the path on this image : https://raw.githubusercontent.com/dsindex/blog/master/images/url_sejong.png
# copy sejong_treebank.txt.v1 to `sejong` directory.
$ ./sejong/split.sh
$ ./sejong/c2d.sh
$ ./train_sejong.sh
#pretrain parser
...
NFO:tensorflow:Seconds elapsed in evaluation: 14.18, eval metric: 93.43%
...
#evaluate pretrained parser
INFO:tensorflow:Seconds elapsed in evaluation: 116.08, eval metric: 95.11%
INFO:tensorflow:Seconds elapsed in evaluation: 14.60, eval metric: 93.76%
INFO:tensorflow:Seconds elapsed in evaluation: 14.45, eval metric: 93.78%
...
#evaluate pretrained parser by eoj-based
accuracy(UAS) = 0.903289
accuracy(UAS) = 0.876198
accuracy(UAS) = 0.876888
...
#train parser
INFO:tensorflow:Seconds elapsed in evaluation: 137.36, eval metric: 94.12%
...
#evaluate parser
INFO:tensorflow:Seconds elapsed in evaluation: 1806.21, eval metric: 96.37%
INFO:tensorflow:Seconds elapsed in evaluation: 224.40, eval metric: 94.19%
INFO:tensorflow:Seconds elapsed in evaluation: 223.75, eval metric: 94.25%
...
#evaluate parser by eoj-based
accuracy(UAS) = 0.928845
accuracy(UAS) = 0.886139
accuracy(UAS) = 0.887824
...
test korean parser model
$ cat sejong/tagged_input.sample
1 프랑스 프랑스 NNP NNP _ 0 _ _ _
2 의 의 JKG JKG _ 0 _ _ _
3 세계 세계 NNG NNG _ 0 _ _ _
4 적 적 XSN XSN _ 0 _ _ _
5 이 이 VCP VCP _ 0 _ _ _
6 ᆫ ᆫ ETM ETM _ 0 _ _ _
7 의상 의상 NNG NNG _ 0 _ _ _
8 디자이너 디자이너 NNG NNG _ 0 _ _ _
9 엠마누엘 엠마누엘 NNP NNP _ 0 _ _ _
10 웅가로 웅가로 NNP NNP _ 0 _ _ _
11 가 가 JKS JKS _ 0 _ _ _
12 실내 실내 NNG NNG _ 0 _ _ _
13 장식 장식 NNG NNG _ 0 _ _ _
14 용 용 XSN XSN _ 0 _ _ _
15 직물 직물 NNG NNG _ 0 _ _ _
16 디자이너 디자이너 NNG NNG _ 0 _ _ _
17 로 로 JKB JKB _ 0 _ _ _
18 나서 나서 VV VV _ 0 _ _ _
19 었 었 EP EP _ 0 _ _ _
20 다 다 EF EF _ 0 _ _ _
21 . . SF SF _ 0 _ _ _
$ cat sejong/tagged_input.sample | ./test_sejong.sh -v -v
Input: 프랑스 의 세계 적 이 ᆫ 의상 디자이너 엠마누엘 웅가로 가 실내 장식 용 직물 디자이너 로 나서 었 다 .
Parse:
. SF ROOT
+-- 다 EF MOD
+-- 었 EP MOD
+-- 나서 VV MOD
+-- 가 JKS NP_SBJ
| +-- 웅가로 NNP MOD
| +-- 디자이너 NNG NP
| | +-- 의 JKG NP_MOD
| | | +-- 프랑스 NNP MOD
| | +-- ᆫ ETM VNP_MOD
| | | +-- 이 VCP MOD
| | | +-- 적 XSN MOD
| | | +-- 세계 NNG MOD
| | +-- 의상 NNG NP
| +-- 엠마누엘 NNP NP
+-- 로 JKB NP_AJT
+-- 디자이너 NNG MOD
+-- 직물 NNG NP
+-- 실내 NNG NP
+-- 용 XSN NP
+-- 장식 NNG MOD
apply korean POS tagger(Komoran via konlpy)
# after installing konlpy ( http://konlpy.org/ko/v0.4.3/ )
$ python sejong/tagger.py
나는 학교에 간다.
1 나 나 NP NP _ 0 _ _ _
2 는 는 JX JX _ 0 _ _ _
3 학교 학교 NNG NNG _ 0 _ _ _
4 에 에 JKB JKB _ 0 _ _ _
5 가 가 VV VV _ 0 _ _ _
6 ㄴ다 ㄴ다 EF EF _ 0 _ _ _
7 . . SF SF _ 0 _ _ _
$ echo "나는 학교에 간다." | python sejong/tagger.py | ./test_sejong.sh
Input: 나 는 학교 에 가 ㄴ다 .
Parse:
. SF ROOT
+-- ㄴ다 EF MOD
+-- 가 VV MOD
+-- 는 JX NP_SBJ
| +-- 나 NP MOD
+-- 에 JKB NP_AJT
+-- 학교 NNG MOD

tensorflow serving and syntaxnet
$ bazel-bin/tensorflow_serving/example/parsey_client --server=localhost:9000
나는 학교에 간다
Input : 나는 학교에 간다
Parsing :
{"result": [{"text": "나 는 학교 에 가 ㄴ다", "token": [{"category": "NP", "head": 1, "end": 2, "label": "MOD", "start": 0, "tag": "NP", "word": "나"}, {"category": "JX", "head": 4, "end": 6, "label": "NP_SBJ", "start": 4, "tag": "JX", "word": "는"}, {"category": "NNG", "head": 3, "end": 13, "label": "MOD", "start": 8, "tag": "NNG", "word": "학교"}, {"category": "JKB", "head": 4, "end": 17, "label": "NP_AJT", "start": 15, "tag": "JKB", "word": "에"}, {"category": "VV", "head": 5, "end": 21, "label": "MOD", "start": 19, "tag": "VV", "word": "가"}, {"category": "EC", "end": 28, "label": "ROOT", "start": 23, "tag": "EC", "word": "ㄴ다"}], "docid": "-:0"}]}
...
parsey's cousins
- a collection of pretrained syntactic models
- how to test
# download models from http://download.tensorflow.org/models/parsey_universal/<language>.zip
# for `English`
$ echo "Bob brought the pizza to Alice." | ./parse.sh
# tokenizing
Bob brought the pizza to Alice .
# morphological analysis
1 Bob _ _ _ Number=Sing|fPOS=PROPN++NNP 0 _ _ _
2 brought _ _ _ Mood=Ind|Tense=Past|VerbForm=Fin|fPOS=VERB++VBD 0 _ _ _
3 the _ _ _ Definite=Def|PronType=Art|fPOS=DET++DT 0 _ _ _
4 pizza _ _ _ Number=Sing|fPOS=NOUN++NN 0 _ _ _
5 to _ _ _ fPOS=ADP++IN 0 _ _ _
6 Alice _ _ _ Number=Sing|fPOS=PROPN++NNP 0 _ _ _
7 . _ _ _ fPOS=PUNCT++. 0 _ _ _
# tagging
1 Bob _ PROPN NNP Number=Sing|fPOS=PROPN++NNP 0 _ _ _
2 brought _ VERB VBD Mood=Ind|Tense=Past|VerbForm=Fin|fPOS=VERB++VBD 0 _ _ _
3 the _ DET DT Definite=Def|PronType=Art|fPOS=DET++DT 0 _ _ _
4 pizza _ NOUN NN Number=Sing|fPOS=NOUN++NN 0 _ _ _
5 to _ ADP IN fPOS=ADP++IN 0 _ _ _
6 Alice _ PROPN NNP Number=Sing|fPOS=PROPN++NNP 0 _ _ _
7 . _ PUNCT . fPOS=PUNCT++. 0 _ _ _
# parsing
1 Bob _ PROPN NNP Number=Sing|fPOS=PROPN++NNP 2 nsubj _ _
2 brought _ VERB VBD Mood=Ind|Tense=Past|VerbForm=Fin|fPOS=VERB++VBD 0 ROOT _ _
3 the _ DET DT Definite=Def|PronType=Art|fPOS=DET++DT 4 det _ _
4 pizza _ NOUN NN Number=Sing|fPOS=NOUN++NN 2 dobj _ _
5 to _ ADP IN fPOS=ADP++IN 6 case _ _
6 Alice _ PROPN NNP Number=Sing|fPOS=PROPN++NNP 2 nmod _ _
7 . _ PUNCT . fPOS=PUNCT++. 2 punct _ _
# conll2tree
Input: Bob brought the pizza to Alice .
Parse:
brought VERB++VBD ROOT
+-- Bob PROPN++NNP nsubj
+-- pizza NOUN++NN dobj
| +-- the DET++DT det
+-- Alice PROPN++NNP nmod
| +-- to ADP++IN case
+-- . PUNCT++. punct
- downloaded model vs trained model
1. downloaded model
Language No. tokens POS fPOS Morph UAS LAS
-------------------------------------------------------
English 25096 90.48% 89.71% 91.30% 84.79% 80.38%
2. trained model
INFO:tensorflow:Total processed documents: 2077
INFO:tensorflow:num correct tokens: 18634
INFO:tensorflow:total tokens: 22395
INFO:tensorflow:Seconds elapsed in evaluation: 19.85, eval metric: 83.21%
3. where does the difference(84.79% - 83.21%) come from?
as mentioned https://research.googleblog.com/2016/08/meet-parseys-cousins-syntax-for-40.html
they found good hyperparameters by using MapReduce.
for example,
the hyperparameters for POS tagger :
- POS_PARAMS=128-0.08-3600-0.9-0
- decay_steps=3600
- hidden_layer_sizes=128
- learning_rate=0.08
- momentum=0.9
dragnn
- how to compile examples
$ cd ../
$ pwd
/path/to/models/syntaxnet
$ bazel build -c opt //examples/dragnn:tutorial_1
- training tagger and parser with CoNLL corpus
# compile
$ pwd
/path/to/models/syntaxnet
$ bazel build -c opt //work/dragnn_examples:write_master_spec
$ bazel build -c opt //work/dragnn_examples:train_dragnn
$ bazel build -c opt //work/dragnn_examples:inference_dragnn
# training
$ cd work
$ ./train_dragnn.sh -v -v
...
INFO:tensorflow:training step: 25300, actual: 25300
INFO:tensorflow:training step: 25400, actual: 25400
INFO:tensorflow:finished step: 25400, actual: 25400
INFO:tensorflow:Annotating datset: 2002 examples
INFO:tensorflow:Done. Produced 2002 annotations
INFO:tensorflow:Total num documents: 2002
INFO:tensorflow:Total num tokens: 25148
INFO:tensorflow:POS: 85.63%
INFO:tensorflow:UAS: 79.67%
INFO:tensorflow:LAS: 74.36%
...
# test
$ echo "i love this one" | ./test_dragnn.sh
Input: i love this one
Parse:
love VBP root
+-- i PRP nsubj
+-- one CD obj
+-- this DT det
- training parser with Sejong corpus
# compile
$ pwd
/path/to/models/syntaxnet
$ bazel build -c opt //work/dragnn_examples:write_master_spec
$ bazel build -c opt //work/dragnn_examples:train_dragnn
$ bazel build -c opt //work/dragnn_examples:inference_dragnn_sejong
# training
$ cd work
# to prepare corpus, please refer to `training parser from Sejong treebank corpus` section.
$ ./train_dragnn_sejong.sh -v -v
...
INFO:tensorflow:training step: 33100, actual: 33100
INFO:tensorflow:training step: 33200, actual: 33200
INFO:tensorflow:finished step: 33200, actual: 33200
INFO:tensorflow:Annotating datset: 4114 examples
INFO:tensorflow:Done. Produced 4114 annotations
INFO:tensorflow:Total num documents: 4114
INFO:tensorflow:Total num tokens: 97002
INFO:tensorflow:POS: 93.95%
INFO:tensorflow:UAS: 91.38%
INFO:tensorflow:LAS: 87.76%
...
# test
# after installing konlpy ( http://konlpy.org/ko/v0.4.3/ )
$ echo "제주로 가는 비행기가 심한 비바람에 회항했다." | ./test_dragnn_sejong.sh
INFO:tensorflow:Read 1 documents
Input: 제주 로 가 는 비행기 가 심하 ㄴ 비바람 에 회항 하 았 다 .
Parse:
. SF VP
+-- 다 EF MOD
+-- 았 EP MOD
+-- 하 XSA MOD
+-- 회항 SN MOD
+-- 가 JKS NP_SBJ
| +-- 비행기 NNG MOD
| +-- 는 ETM VP_MOD
| +-- 가 VV MOD
| +-- 로 JKB NP_AJT
| +-- 제주 MAG MOD
+-- 에 JKB NP_AJT
+-- 비바람 NNG MOD
+-- ㄴ SN MOD
+-- 심하 VV NP
# it seems that pos tagging results from the dragnn are somewhat incorrect.
# so, i replace those to the results from the Komoran tagger.
# you can modify 'inference_dragnn_sejong.py' to use the tags from the dragnn.
Input: 제주 로 가 는 비행기 가 심하 ㄴ 비바람 에 회항 하 았 다 .
Parse:
. SF VP
+-- 다 EF MOD
+-- 았 EP MOD
+-- 하 XSV MOD
+-- 회항 NNG MOD
+-- 가 JKS NP_SBJ
| +-- 비행기 NNG MOD
| +-- 는 ETM VP_MOD
| +-- 가 VV MOD
| +-- 로 JKB NP_AJT
| +-- 제주 NNG MOD
+-- 에 JKB NP_AJT
+-- 비바람 NNG MOD
+-- ㄴ ETM MOD
+-- 심하 VA NP
- web api using tornado
- how to run
# compile $ pwd /path/to/models/syntaxnet $ bazel build -c opt //work/dragnn_examples:dragnn_dm # start tornado web api $ cd work/dragnn_examples/www # start single process $ ./start.sh -v -v 0 0 # despite tornado suppoting multi-processing, session of tensorflow is not fork-safe. # so do not use multi-processing option. # if you want to link to the model trained by Sejong corpus, just edit env.sh # : enable_konlpy='True' # http://hostip:8897 # http://hostip:8897/dragnn?q=i love it # http://hostip:8897/dragnn?q=나는 학교에 가서 공부했다.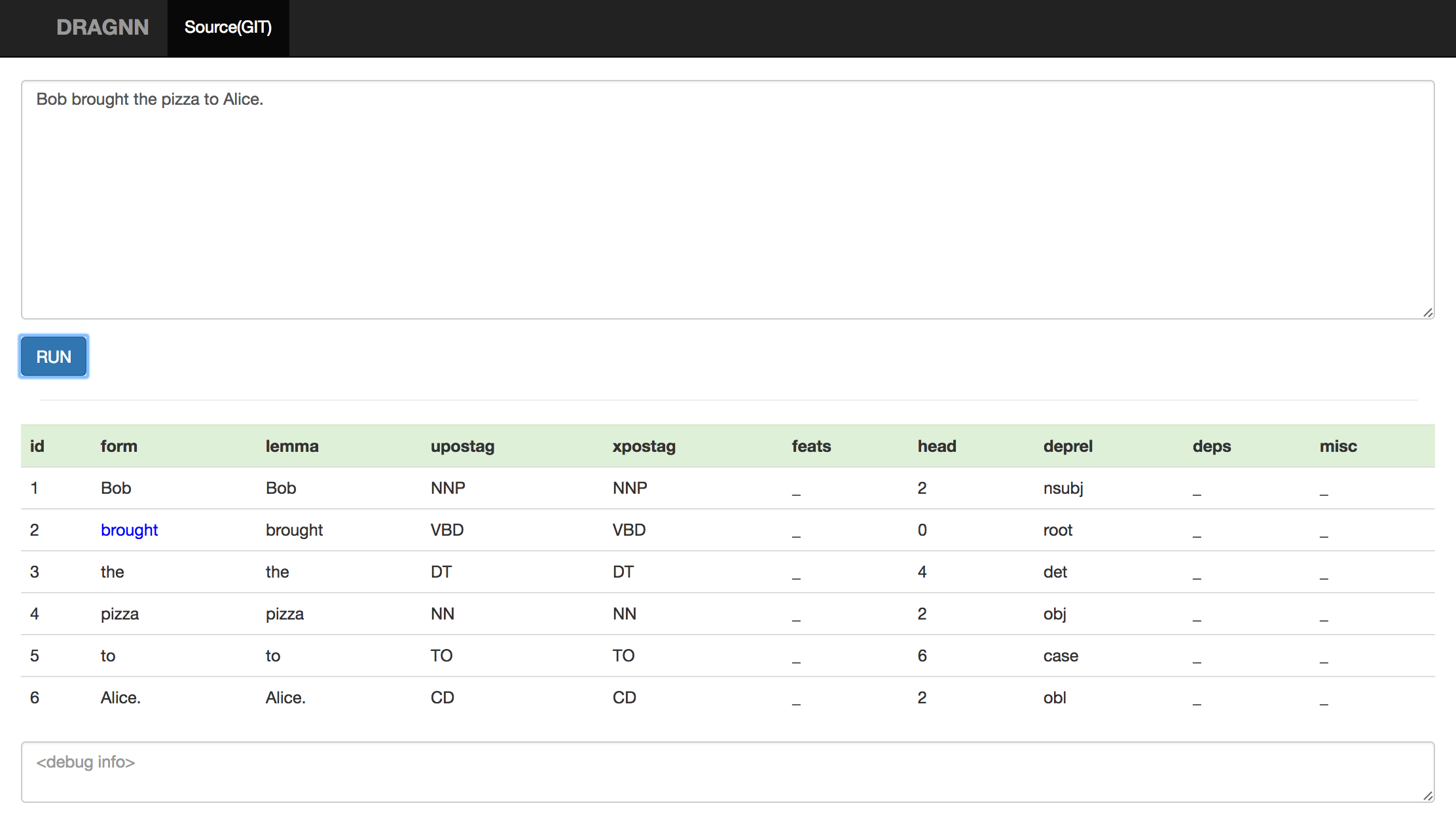
{kind=link}
brat annotation tool
comparison to BIST parser
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].