taki0112 / Tensorflow2 Cookbook
Licence: mit
Simple Tensorflow 2.x Cookbook for easy-to-use
Stars: ✭ 249
Programming Languages
python
139335 projects - #7 most used programming language

Tensorflow1 Cookbook
Contributions
In now, this repo provides general architectures and functions that are useful for the GAN and classification.
I will continue to add useful things to other areas.
Also, your pull requests and issues are always welcome.
And tell me what you want to implement on the issue. I'll implement it.
Functional vs Sequential
Functional API [Template code]
Pros
- More fast than Sequential
- More easy to create a flexible model architecture
- Easy to use some layer operaions like
concatenate,add, ...
- Easy to use some layer operaions like
Cons
-
Define
tf.keras.layers.Input- You have to know the
shape of input tensor
- You have to know the
-
Define
tf.keras.Model- You have to create the
Modelconstructor at the end
- You have to create the
Sequential API [Template code]
Pros
-
Simple to use
- Similar to Pytorch style
Cons
- Hard to create a flexible model architecture
Example code
How to use
1. Import
Funtional API
-
ops_functional.py- Functional API operations
- from ops_functional import *
Sequential API
-
ops_sequential.py- Sequential API operations
- from ops_sequential import *
Common
-
utils.py- image processing + something useful functions (e.g. automatic_gpu_usage)
-
automatic_gpu_usage: Automatically manage gpu memory -
multiple_gpu_usage: You can set gpu memory limit
-
- from utils import *
- image processing + something useful functions (e.g. automatic_gpu_usage)
2. Network template
Functional API
from ops_functional import *
from utils import *
automatic_gpu_usage() # for efficient gpu use
input_shape = [img_height, img_width, img_ch]
inputs = tf.keras.layers.Input(input_shape, name='input')
# architecture
x = conv(inputs, channels=64, kernel=3, stride=2, pad=1, pad_type='reflect', use_bias=False, sn=False, name='conv')
x = batch_norm(x, name='batch_norm')
x = relu(x)
x = global_avg_pooling(x)
x = fully_connected(x, units=10, sn=False, name='fc')
model = tf.keras.Model(inputs, s, name='model')
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
Sequential API
from ops_sequential import *
from utils import *
automatic_gpu_usage() # for efficient gpu use
model = []
model += [Conv(channels=64, kernel=3, stride=2, pad=1, pad_type='reflect', use_bias=False, sn=False, name='conv')]
model += [BatchNorm(name)]
model += [Relu()]
model += [Global_Avg_Pooling()]
model += [FullyConnected(units=10, sn=False, name='fc')]
model = Sequential(model, name='model')
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
3. Data pipeline
img_class = Image_data(img_height, img_width, img_ch, dataset_path, augment_flag)
img_class.preprocess()
img_slice = tf.data.Dataset.from_tensor_slices(img_class.dataset)
gpu_device = '/gpu:0'
img_slice = img_slice. \
apply(shuffle_and_repeat(dataset_num)). \
apply(map_and_batch(img_class.image_processing, self.batch_size,
num_parallel_batches=AUTOTUNE,
drop_remainder=True)). \
apply(prefetch_to_device(gpu_device, AUTOTUNE))
dataset_iter = iter(img_slice)
4. Restore
ckpt = tf.train.Checkpoint(model=model, optimizer=optimizer)
manager = tf.train.CheckpointManager(ckpt, checkpoint_dir, max_to_keep=2)
start_iteration = 0
if manager.latest_checkpoint:
ckpt.restore(manager.latest_checkpoint)
start_iteration = int(manager.latest_checkpoint.split('-')[-1])
print('Latest checkpoint restored!!')
else:
print('Not restoring from saved checkpoint')
5-1. Train
def train_step(img):
with tf.GradientTape() as tape:
logit = model(img)
# calculate loss
"""
if classification
your_loss = cross_entropy_loss(logit, label)
"""
loss = your_loss + regularization_loss(model)
train_variable = model.trainable_variables
gradient = tape.gradient(loss, train_variable)
optimizer.apply_gradients(zip(gradient, train_variable))
return loss
def train():
# setup tensorboard
summary_writer = tf.summary.create_file_writer(log_dir)
for idx in range(start_iteration, total_iteration):
img = next(dataset_iter)
# update network
loss = train_step(img)
# save to tensorboard
with summary_writer.as_default():
tf.summary.scalar('loss', loss, step=idx)
# save ckpt
manager.save(checkpoint_number=idx + 1)
# save model for final step
manager.save(checkpoint_number=total_iteration)
5-2. Multi-GPUs train [Template code]
strategy = tf.distribute.MirroredStrategy()
NUM_GPUS = strategy.num_replicas_in_sync
total_iteration = iteration // NUM_GPUS
with strategy.scope():
# copy & paste
# 2. Network template
# 3. Data pipeline
# 4. Restore
def train_step(img):
""" SAME """
def distribute_train_step(img):
with strategy.scope():
loss = strategy.experimental_run_v2(train_step, args=(img))
loss = strategy.reduce(tf.distribute.ReduceOp.MEAN, loss, axis=None)
return loss
def train():
# setup tensorboard
summary_writer = tf.summary.create_file_writer(log_dir)
for idx in range(start_iteration, total_iteration):
img = next(dataset_iter)
# update network
loss = distribute_train_step(img)
"""
SAME
"""
Weight
weight_initializer = tf.initializers.RandomNormal(mean=0.0, stddev=0.02)
weight_regularizer = tf.keras.regularizers.l2(0.0001)
weight_regularizer_fully = tf.keras.regularizers.l2(0.0001)
Initialization
-
Xavier: tf.initializers.GlorotUniform() or tf.initializers.GlorotNormal() -
He: tf.initializers.VarianceScaling() -
Normal: tf.initializers.RandomNormal(mean=0.0, stddev=0.02) -
Truncated normal: tf.initializers.TruncatedNormal(mean=0.0, stddev=0.02) -
Orthogonal: tf.initializers.Orthogonal0.02)
Regularization
-
l2_decay: tf.keras.regularizers.l2(0.0001) -
orthogonal_regularizer: orthogonal_regularizer(0.0001) # orthogonal_regularizer_fully(0.0001)
Option
-
padding='SAME'- pad = ceil[ (kernel - stride) / 2 ]
-
pad_type- 'zero' or 'reflect'
-
sn- use spectral normalization of not
Examples of Functional API
Recurrent
x = various_rnn(x, n_hidden=128, n_layer=2, dropout_rate=0.5, training=True, bidirectional=True, rnn_type='lstm', name='rnn')
LSTM

GRU

Bidirectional

Deep (n_layer > 1)

Convolution
basic conv
x = conv(x, channels=64, kernel=3, stride=2, pad=1, pad_type='reflect', use_bias=True, sn=True, name='conv')

partial conv (NVIDIA Partial Convolution)
x = partial_conv(x, channels=64, kernel=3, stride=2, use_bias=True, padding='SAME', sn=True, name='partial_conv')


dilated conv
x = dilate_conv(x, channels=64, kernel=3, rate=2, use_bias=True, padding='VALID', sn=True, name='dilate_conv')

Deconvolution
basic deconv
x = deconv(x, channels=64, kernel=3, stride=1, padding='SAME', use_bias=True, sn=True, name='deconv')
Fully-connected
x = fully_connected(x, units=64, use_bias=True, sn=True, snamecope='fully_connected')

Pixel shuffle
x = conv_pixel_shuffle_down(x, scale_factor=2, use_bias=True, sn=True, name='pixel_shuffle_down')
x = conv_pixel_shuffle_up(x, scale_factor=2, use_bias=True, sn=True, name='pixel_shuffle_up')
-
down===> [height, width] -> [height // scale_factor, width // scale_factor] -
up===> [height, width] -> [height * scale_factor, width * scale_factor]
![]()
Block
residual block
x = resblock(x, channels=64, is_training=is_training, use_bias=True, sn=True, name='residual_block')
x = resblock_down(x, channels=64, is_training=is_training, use_bias=True, sn=True, name='residual_block_down')
x = resblock_up(x, channels=64, is_training=is_training, use_bias=True, sn=True, name='residual_block_up')
-
down===> [height, width] -> [height // 2, width // 2] -
up===> [height, width] -> [height * 2, width * 2]
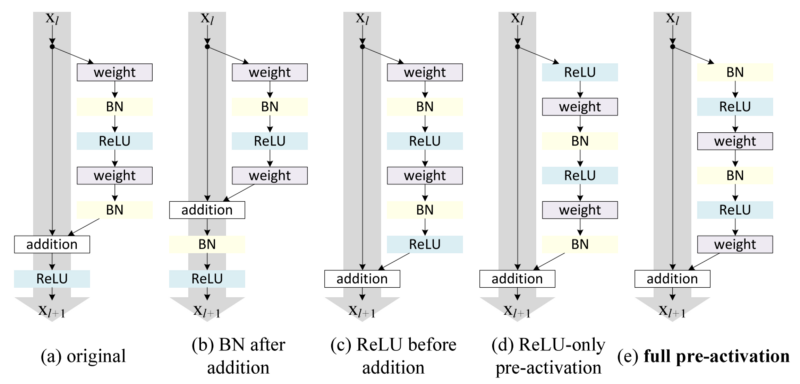
dense block
x = denseblock(x, channels=64, n_db=6, is_training=is_training, use_bias=True, sn=True, name='denseblock')
-
n_db===> The number of dense-block

residual-dense block
x = res_denseblock(x, channels=64, n_rdb=20, n_rdb_conv=6, is_training=is_training, use_bias=True, sn=True, name='res_denseblock')
-
n_rdb===> The number of RDB -
n_rdb_conv===> per RDB conv layer



attention block
x = self_attention(x, use_bias=True, sn=True, name='self_attention')
x = self_attention_with_pooling(x, use_bias=True, sn=True, name='self_attention_version_2')
x = squeeze_excitation(x, ratio=16, use_bias=True, sn=True, name='squeeze_excitation')
x = convolution_block_attention(x, ratio=16, use_bias=True, sn=True, name='convolution_block_attention')
x = global_context_block(x, use_bias=True, sn=True, name='gc_block')
x = srm_block(x, use_bias=False, is_training=is_training, name='srm_block')



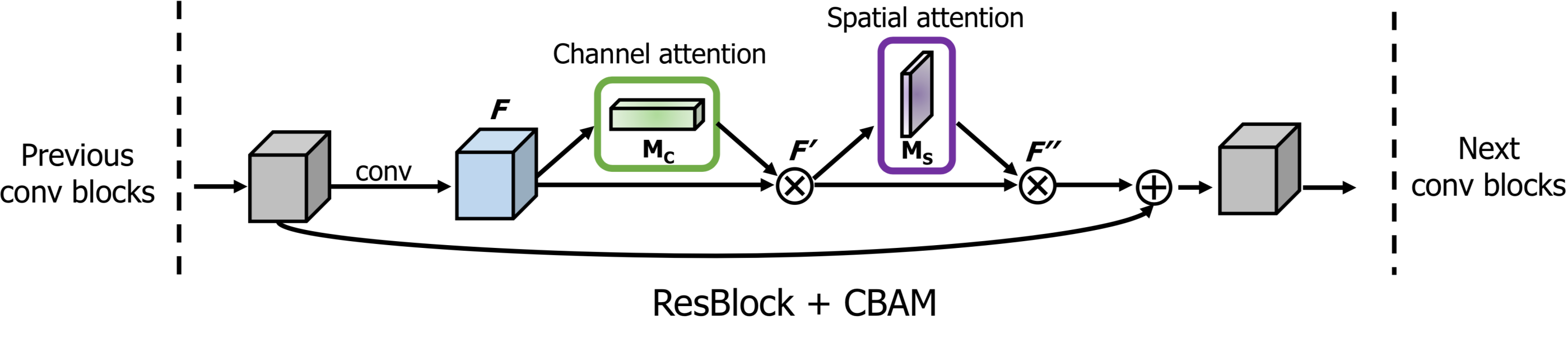



Normalization
x = batch_norm(x, training=training, name='batch_norm')
x = layer_norm(x, name='layer_norm')
x = instance_norm(x, name='instance_norm')
x = group_norm(x, groups=32, name='group_norm')
x = pixel_norm(x)
x = batch_instance_norm(x, name='batch_instance_norm')
x = layer_instance_norm(x, name='layer_instance_norm')
x = switch_norm(x, scope='switch_norm')
x = condition_batch_norm(x, z, training=training, name='condition_batch_norm'):
x = adaptive_instance_norm(x, gamma, beta)
x = adaptive_layer_instance_norm(x, gamma, beta, smoothing=True, name='adaLIN')
- See this for how to use
condition_batch_norm - See this for how to use
adaptive_instance_norm - See this for how to use
adaptive_layer_instance_norm&layer_instance_norm


Activation
x = relu(x)
x = lrelu(x, alpha=0.2)
x = tanh(x)
x = sigmoid(x)
x = swish(x)
x = elu(x)
Pooling & Resize
x = nearest_up_sample(x, scale_factor=2)
x = bilinear_up_sample(x, scale_factor=2)
x = nearest_down_sample(x, scale_factor=2)
x = bilinear_down_sample(x, scale_factor=2)
x = max_pooling(x, pool_size=2)
x = avg_pooling(x, pool_size=2)
x = global_max_pooling(x)
x = global_avg_pooling(x)
x = flatten(x)
x = hw_flatten(x)
Loss
classification loss
loss, accuracy = classification_loss(logit, label)
loss = dice_loss(n_classes=10, logit, label)
regularization loss
model_reg_loss = regularization_loss(model)
- If you want to use
regularizer, then you should write it
pixel loss
loss = L1_loss(x, y)
loss = L2_loss(x, y)
loss = huber_loss(x, y)
loss = histogram_loss(x, y)
loss = gram_style_loss(x, y)
loss = color_consistency_loss(x, y)
-
histogram_lossmeans the difference in the color distribution of the image pixel values. -
gram_style_lossmeans the difference between the styles using gram matrix. -
color_consistency_lossmeans the color difference between the generated image and the input image.
gan loss
d_loss = discriminator_loss(Ra=True, gan_type='wgan-gp', real_logit=real_logit, fake_logit=fake_logit)
g_loss = generator_loss(Ra=True, gan_type='wgan-gp', real_logit=real_logit, fake_logit=fake_logit)
-
Ra- use relativistic gan or not
-
loss_func

vdb loss
d_bottleneck_loss = vdb_loss(real_mu, real_logvar, i_c) + vdb_loss(fake_mu, fake_logvar, i_c)
kl-divergence (z ~ N(0, 1))
loss = kl_loss(mean, logvar)
Author
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].