tracerT
note: this project is no longer maintained and is incompatible with the current GHDB site
Automated Google dorking with custom search engines
Description
This utility has two submodules. The first submodule (GHDB) will scrape the Google Hacking Database for dorks in a given category then save them to a local file. The second submodule will take an input file of Google dorks and query them against the Google Custom Search Engine API for a given target domain. If a dorks returns any results, the dork will be saved to a local file. The third module will take a comma separated list of TLDS (e.g. 'com,net,io') and produce a TSV configuration file that can be imported into a CSE.
Prerequisities
-
A valid API key. Generate one from the Google Developer Console (Make sure to first enable the Custom Search API).
-
Scope the search engine to no site and set the dropdown to search the entire web. See the image below for clarification

Alternatively, scope the search engine to a TLD matching the target domain. See the image below for clarification
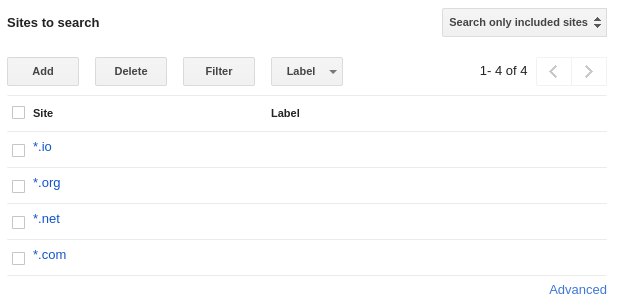
Setup
pip install -r requirements.txt
Usage & Notes
GHDB submodule
Print GHDB categories
python tracerT.py ghdb --cat-list
Retrive dorks for a category
python tracerT.py ghdb -c 9 -o dorks.csv
Full help
usage: tracerT ghdb [-h] [-c CATEGORY] [--cat-list] [-o OUTDORK]
optional arguments:
-h, --help show this help message and exit
-c CATEGORY, --category CATEGORY
GHDB dork category. Use the --cat-list for category
list
--cat-list show categories list
-o OUTDORK, --out-file OUTDORK
output file for dorks (CSV)
CSE submodule
Query CSE for dorks
python tracerT.py cse -x <cse id> -a <api key> -i dorks.csv -t example.com -o results.txt
Full help
usage: tracerT cse [-h] -x CSE -a API -i ILIST [-f FFORMAT] -t TARGET
[--skip-lc] -o OUTRES
optional arguments:
-h, --help show this help message and exit
-x CSE, --cse CSE CSE ID
-a API, --api API API key
-i ILIST, --ilist ILIST
input list of dorks
-f FFORMAT, --format FFORMAT
input list format (txt,csv)
-t TARGET, --target TARGET
target domain
--skip-lc skip line count for input file
-o OUTRES, --out-file OUTRES
output file for search results (CSV)
- --skip-lc: The CSE API has a limit of 100 queries per day for the free tier so the script is set to not run if the input file exceeds 100 lines. If you are willing to pay for extended use, you can use this switch to disable the line count check
- -f, --format: The script accepts both .txt and .csv input files. Text file input should be a newline delimited list of dorks. CSV file input should be in the format of 'GHDB ID,Dork'. This is also the output given by the GHDB submodule. Make sure to leave the column title in the file (the script will remove it). This argument is optional. However, the script will use the file extension to determine the format if you omit it.
TSV submodule
Generate TSV configuration file
python tracerT.py tsv -o annotations.tsv -i 'com,net,io' -x <cse id>
Full help
usage: tracerT tsv [-h] -x CSECONF -o OUTCONF -i ITLD
optional arguments:
-h, --help show this help message and exit
-x CSECONF, --cse CSECONF
CSE ID
-o OUTCONF, --out-file OUTCONF
output file for config
-i ITLD, --itld ITLD comma separated TLDs
To-dos & Feature Requests
- Multiple input list support
Known Issues
- Retrieving dorks from GHDB for category 1 will fail. This appears to be an issue with the site itself not properly displaying the dorks.
Changelog
- 05/09/2018 - Added TSV submodule
- 02/11/2018 - Initial release