Henryhaohao / Wenshu_spider
Licence: mit
🌈Wenshu_Spider-Scrapy框架爬取中国裁判文书网案件数据(2019-1-9最新版)
Stars: ✭ 177
Programming Languages
python
139335 projects - #7 most used programming language
Labels
Projects that are alternatives of or similar to Wenshu spider
torchestrator
Spin up Tor containers and then proxy HTTP requests via these Tor instances
Stars: ✭ 32 (-81.92%)
Mutual labels: proxy-server, scrapy
Psiphon
A multi-functional version of a popular network circumvention tool
Stars: ✭ 169 (-4.52%)
Mutual labels: proxy-server
Mockingbird
Simplify software testing, by easily mocking any system using HTTP/HTTPS, allowing a team to test and develop against a service that is not complete or is unstable or just to reproduce planned/edge cases.
Stars: ✭ 149 (-15.82%)
Mutual labels: proxy-server
Netflix Clone
Netflix like full-stack application with SPA client and backend implemented in service oriented architecture
Stars: ✭ 156 (-11.86%)
Mutual labels: scrapy
Juno crawler
Scrapy crawler to collect data on the back catalog of songs listed for sale.
Stars: ✭ 150 (-15.25%)
Mutual labels: scrapy
Awesome Web Scraper
A collection of awesome web scaper, crawler.
Stars: ✭ 147 (-16.95%)
Mutual labels: scrapy
Weibospider sentimentanalysis
借助Python抓取微博数据,并对抓取的数据进行情绪分析
Stars: ✭ 173 (-2.26%)
Mutual labels: scrapy
Fp Server
Free proxy server, continuously crawling and providing proxies, based on Tornado and Scrapy. 免费代理服务器,基于Tornado和Scrapy,在本地搭建属于自己的代理池
Stars: ✭ 154 (-12.99%)
Mutual labels: scrapy
Free Email Forwarding
The best free email forwarding for custom domains. Visit our website to get started (SMTP server)
Stars: ✭ 2,024 (+1043.5%)
Mutual labels: proxy-server
Beyond
BeyondCorp-inspired Access Proxy. Secure internal services outside your VPN/perimeter network during a zero-trust transition.
Stars: ✭ 151 (-14.69%)
Mutual labels: proxy-server
Datamining And Social Sentiment Analysis Based On Weibo
基于微博的数据挖掘与社交舆情分析
Stars: ✭ 149 (-15.82%)
Mutual labels: scrapy
Proxyman
Modern and Delightful Web Debugging Proxy for macOS, iOS, and Android ⚡️
Stars: ✭ 2,571 (+1352.54%)
Mutual labels: proxy-server
Movie recommend
基于Spark的电影推荐系统,包含爬虫项目、web网站、后台管理系统以及spark推荐系统
Stars: ✭ 2,092 (+1081.92%)
Mutual labels: scrapy
Goproxy
🦁 goproxy is a proxy server which can forward http or https requests to remote servers./ goproxy 是一个反向代理服务器,支持转发 http/https 请求。
Stars: ✭ 175 (-1.13%)
Mutual labels: proxy-server
Macos Openvpn Server
macOS OpenVPN Server and Client Configuration (OpenVPN, Tunnelblick, PF)
Stars: ✭ 172 (-2.82%)
Mutual labels: proxy-server
Scrapy框架爬取中国裁判文书网案件数据 
![]()
![]()
![]()
![]()
![]()
中国裁判文书网 - http://wenshu.court.gov.cn/
| Author | 😎Henryhaohao😎 |
|---|---|
| ♥️[email protected]♥️ |
🐬声明
软件均仅用于学习交流,请勿用于任何商业用途!感谢大家!
🐬介绍
该项目为Scrapy框架爬取中国裁判文书网案件数据(2018-10-20最新版)
- 项目文件: Wenshu_Project
- 运行须知:
数据库配置 : 运行前根据自己需要修改settings.py中的MongoDB数据库的配置
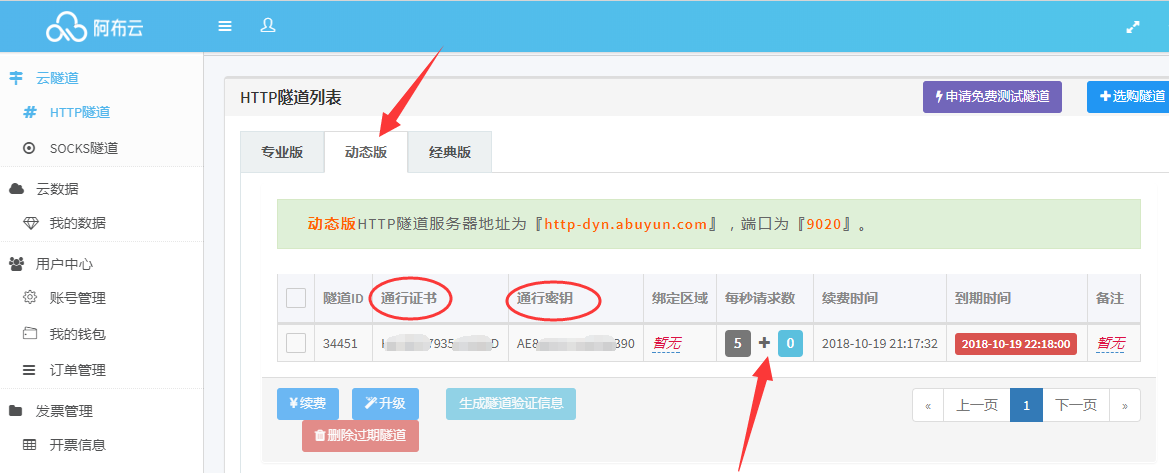
反爬问题 : 由于文书网的反爬监控很严格(一级验证码,二级验证码,JavaScript反爬,IP检测...),所有采用阿布云动态隧道代理方案,每一次request请求都是不同的IP,这样就不会触发反爬检测了~😎。还是挺好用的,基本上每个IP都可以用,主要也还方便,直接用它的代理服务器发出请求,不用像一般的代理IP那样还需要取出IP,再代入IP进行请求。代理相关配置在middlewares.py的类ProxyMiddleware中。
爬取策略问题 : 现在的文书网总量已经高达5千多万份了,但是每个筛选条件下只能查看20页,每页10条。本项目以爬取1996-2000年的所有文书为例,大家有好的爬取方案,可以自行修改Param参数即可。
速度问题 : 配置在setting.py中:DOWNLOAD_DELAY = 0(无delay实现请求0延时);CONCURRENT_REQUESTS_PER_SPIDER = 5 (开启线程数为5);因为我用的代理配置是默认的每秒5个请求数,所以在此设置线程数为5;如果想爬取更快,可以加大代理请求数(当然是要money滴~),最高可以加到100的请求数,我滴天呀,那得多快啊!我现在的速度大概每秒爬取4个案件,加到100的话,估计每秒80个,一分钟4800个,一小时288000,一天就是6912000,目前总量5千4百万,大概8~9天就能爬完,如果在加上redis分布式的话,哇,不敢想象!😋
🐬运行环境
-
Version: Python3
-
JS解析环境: Nodejs
有不少小伙伴向我反映运行后报错:execjs._exceptions.ProgramError: TypeError: 'key' 为 null 或不是对象
解决方案如下:
如果pyexecjs包没问题的话,那就是没有安装nodejs的问题; 因为你没有安装nodejs的话默认js解析环境是JScript, 但是项目中的js代码有的地方需要node环境才能运行, 所以需要装一下Nodejs再运行就好了;
注意: nodejs安装完成后记得把IDE关闭重新打开,比如pycharm,不然IDE不会监测到jscript引擎的变化,导致依然报错 关于NodeJs安装可以参考这篇文章: https://www.cnblogs.com/liuqiyun/p/8133904.html
🐬安装依赖库
pip3 install -r requirements.txt
🐬存储数据库
Database: MongoDB
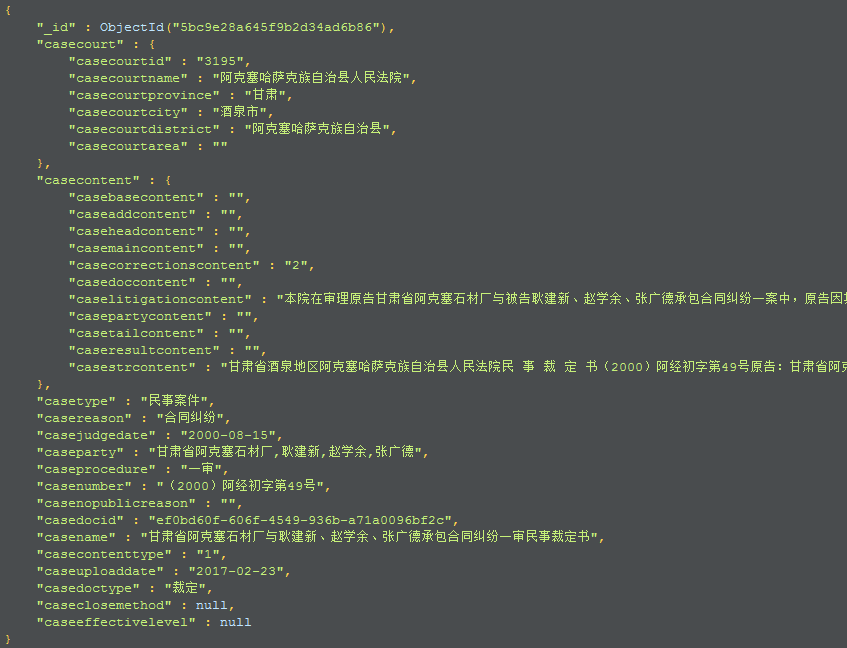
🐬相关截图
- 运行过程

- 数据截图
- 阿布云
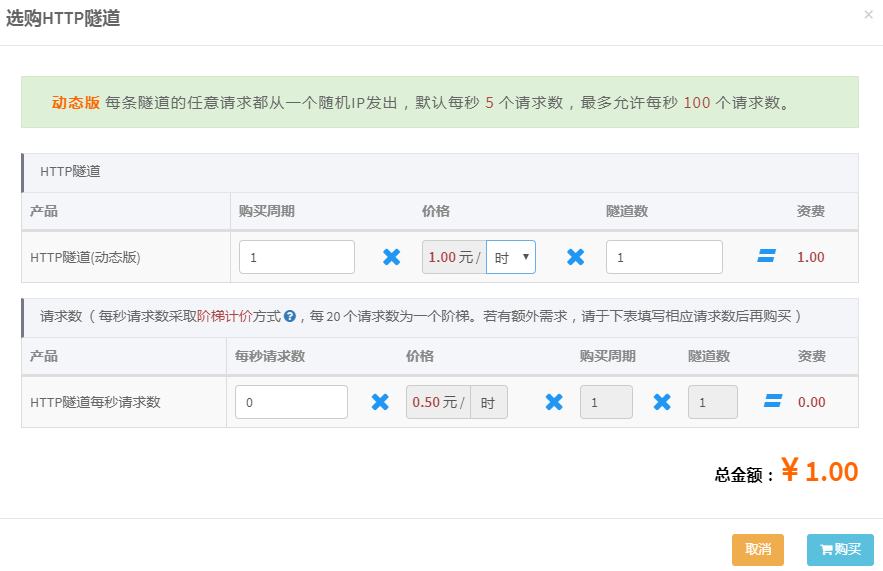




🐬总结
最后,如果你觉得这个项目不错或者对你有帮助,给个Star呗,也算是对我学习路上的一种鼓励!
哈哈哈,感谢大家!笔芯哟~💘💘
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].