cy69855522 / Ai Paper Drawer
人工智能论文关键点集结。This project aims to collect key points of AI papers.
Stars: ✭ 82
Projects that are alternatives of or similar to Ai Paper Drawer
Cnn Paper2
🎨 🎨 深度学习 卷积神经网络教程 :图像识别,目标检测,语义分割,实例分割,人脸识别,神经风格转换,GAN等🎨🎨 https://dataxujing.github.io/CNN-paper2/
Stars: ✭ 77 (-6.1%)
Mutual labels: cv, gans
Ai Study
人工智能学习资料超全整理,包含机器学习基础ML、深度学习基础DL、计算机视觉CV、自然语言处理NLP、推荐系统、语音识别、图神经网路、算法工程师面试题
Stars: ✭ 93 (+13.41%)
Mutual labels: graph, cv
Serial Studio
Multi-purpose serial data visualization & processing program
Stars: ✭ 1,168 (+1324.39%)
Mutual labels: graph
Agis Net
[SIGGRAPH Asia 2019] Artistic Glyph Image Synthesis via One-Stage Few-Shot Learning
Stars: ✭ 77 (-6.1%)
Mutual labels: gans
Rlenv.directory
Explore and find reinforcement learning environments in a list of 150+ open source environments.
Stars: ✭ 79 (-3.66%)
Mutual labels: rl
Bicyclegan
Toward Multimodal Image-to-Image Translation
Stars: ✭ 1,215 (+1381.71%)
Mutual labels: gans
Jrds
Another monitoring application, intentend to be simple to use and extensible.
Stars: ✭ 72 (-12.2%)
Mutual labels: graph
Virtualhome
API to run VirtualHome, a Multi-Agent Household Simulator
Stars: ✭ 80 (-2.44%)
Mutual labels: graph
🗃 AI-Paper-Drawer
人工智能论文笔记,若有不当之处欢迎指正(发 issue 或 PR)。 ⛄欢迎扫码加入QQ交流群832405795 ↓

此 repo 旨在记录各 AI 论文具有启发性的核心思想和流程
- 点击论文标题前的超链接可访问原文
- 点击✒可进入流程速记页面,记录核心算法公式,便于复习
子抽屉
相关链接
- 🐍 LeetCode最短Python题解 。
- 🚀 AI Power 云GPU租借/出租平台:图网络的计算需要高算力支持,赶论文、拼比赛的朋友不妨了解一下~ 现在注册并绑定(参考Github)即可获得高额算力,详情请参考AI Power指南
💫 Graph 图网络
图数据
【2016 ICLR】 ✒ GATED GRAPH SEQUENCE NEURAL NETWORKS
动机:为了使GNN能够用于处理序列问题- 图神经网络的一种,以每一次局部传播的结果作为输入,网络层数即传播次数固定,层与层之间的信息传递手法利用GRU的门控机制
点云
【2020 AAAI】 ✒ Point2Node: Correlation Learning of Dynamic-Node for Point Cloud Feature Modeling
动机:探索自我(自身特征通道)相关性、局部相关性、非局部相关性- 利用
softmax引入自身通道注意力、节点与节点间注意力。考虑节点与节点间注意力时参考“Non-Local Neural Network”做矩阵乘法构建各点间的注意力。利用门控式分权聚合代替残差连接
【2020 AAAI】 ✒ Geometry Sharing Network for 3D Point Cloud Classification and Segmentation
动机:构建特征空间的相似连接,挖掘远距离相似结构的相关性- 利用局部点构成的结构矩阵的特征值作为旋转平移不变的局部特征,寻找结构相似的点作为邻居
【2019 ICCV】 Interpolated Convolutional Networks for 3D Point Cloud Understanding
动机:利用插值解决点云数据结构的稀疏性、不规则性和无序性- 预设几个离散卷积核权重的位置,对每个中心点所对应的核权重位置进行插值并归一化,然后计算激活值
【2019 ICCV】 PointCloud Saliency Maps
动机:建立点云的显著性图,评估每个点对于下游任务的重要性- 将某点的坐标移动到原点,计算模型性能差异作为点对于下游任务的贡献度。贡献度由
loss对于点坐标模长r的偏导数决定
【2019 CVPR】 ✒ Modeling Local Geometric Structure of 3D Point Clouds using Geo-CNN
动机:显式建模局部点间的几何结构- 将局部点云特征提取过程按三个正交基分解,然后根据边向量与基之间的夹角对提取的特征进行聚合,鼓励网络在整个特征提取层次中保持欧氏空间的几何结构
【2019 CVPR】 Graph Attention Convolution for Point Cloud Segmentation
动机:引入注意力机制缓解图卷积各向同性问题,避免特征污染- 将离散卷积核设定为相对位置和特征差分的函数,并利用
softmax做归一化
【2018 CVPR】 Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
动机:类比卷积局部激活性到三维离散点云核相关- 类比卷积核对分布相近数据具有更高激活值的特点,构造可学习的图核,通过局部区域点的分布与图核的相似性计算激活值
【2018 CVPR】 SplineCNN: Fast Geometric Deep Learning with Continuous B-Spline Kernels
动机:一个新的基于b样条的卷积算子,它使得计算时间独立于核大小
【2017 CVPR】 ⭐ PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
动机:构造具有排列不变性的神经网络- 本文开创 DL 在无序点云上识别的先河,利用核长为1的卷积核对每个点单独升维后使用对称函数(+、max 等)获取具有输入排列不变性的全局点云特征
🖼 CV 计算机视觉
卷积演变
【2019 CVPR】 Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
动机:缓解卷积层在特征图空间频率的冗余- 将卷积通道划分为俩个部分,高分辨率通道存储高频特征,低分辨率通道存储低频特征,提高效率
📜 NLP 自然语言处理
循环神经网络
【2014】 ✒ Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
- 提出了
GRU,其效果与LSTM相近,效率更高
💞 Recommendation 推荐系统
👾 RL 强化学习
🎨 GANs 生成式对抗网络
🔘 Meta Learning 元学习
🚥 Cluster 聚类
目标函数
【2019 ICCV】 ✒ Invariant Information Clustering for Unsupervised Image Classification and Segmentation
动机:提出一种新的聚类目标IIC作为端到端神经网络损失函数- 以一对近似样本投入神经网络获得成对的输出,最大化俩者的互信息
⚗ Others 其他
🎯 知识点速记
数据结构
堆
- 二叉树结构,被用于实现优先队列
- 最小的数在最上面,子结点必定大于父结点
- 添加数据时加到最后一行从左往右添加,取出数据时拿走树顶的数并把最后一个(最后一行最右边一个)放在顶点处进行维护
- 添加/提取的时间复杂度都为
O(logN)
二叉查找树
- 我们可以把二叉查找树当作是二分查找算法思想的树形结构体现
- 每个结点的值均大于其左子树上任意一个结点的值,小于其右子树上任意一个结点的值
- 删除节点后,在被删除结点的左子树中寻找最大结点放上去,如果需要移动的结点还有子结点,就递归执行前面的操作
- 平衡时时间复杂度为
o(logN),最坏情况下O(N)
排序
冒泡排序
- 重复“从序列右边开始比较相邻两个数字的大小,再根据结果交换两个数字的位置”,每次迭代都把最小的数字移动到最左边
- 时间复杂度:
O(N^2)
选择排序
- 执行N次不放回地取最小值操作
- 时间复杂度:
O(N^2)
插入排序
- 把右侧未排序的数逐个插入到左侧已经排好的区域
- 时间复杂度:
O(N^2)
堆排序
- 把数据存进堆,然后从堆顶逐个取出
- 时间复杂度:
O(NlogN)
归并排序
- 把数据递归地对半分,分到不能分的时候对半组合并排序
- 时间复杂度:
O(NlogN),将长度为N的序列对半分割直到只有一个数据为止时,可以分成log2(N)行,每行排序耗费N次比较。也就是说,总的运行时间为 O(NlogN) -
def merge(num: list): if len(num) < 1: return num a = [] a1, a2 = merge(num[:(half:=len(num)//2)]), merge(num[half:]) while a1 and a2: if a1[0] > a2[0]: a1, a2 = a2, a1 a.append(a1[0]) a1 = a1[1:] return a + a1 + a2
快速排序
- 选择一个基准值
m,然后把数据划分为比m小和不小于m的俩个部分。递归这两个部分,最后整个数组就是从小到大了 - 时间复杂度:平均
O(NlogN),最差情况(每次m都选到极端数字,需要递归O(N)次)O(N^2) -
def quick(num: list): if len(num) < 1: return num m, num = num[0], num[1:] l = quick([n for n in num if n < m]) r = quick([n for n in num if n >= m]) return l + [m] + r
数组查找
二分查找
- 需要数组已经排好序
- 每次都对比中间值,进而缩小一半的搜索范围
- 时间复杂度为:
logN
图的搜索
最小生成树
- 边权和最小的生成树(无环,但连接了所有节点)
- Kruskal
- 对所有边进行排序
- 按权的顺序来添加边(已经连通的点不需要)
- Prim
- 随便选一点加入点集
- 选择距离点集最近的点加入点集
广度优先 BFS
- 广度优先搜索(BFS)是一种对图进行搜索的算法。BFS会优先从离起点近的顶点开始搜索,这样由近及广。根据BFS的特性,其常常被用于
遍历和搜索最短路径 - BFS一般流程:
class Solution(object): def BFS(self): # 1.使用 queue.Queue 初始化队列 q = Queue() # 2.选择合适的根节点压入队列 # 3.使用 wile 进入队列循环,直到搜索完毕 while not q.empty(): # { # 4.取出一个节点 q.get() # 5.放入这个节点周围的节点 q.put() # }
- 使用 BFS 时,需要抓住 3 个关键点:根节点是什么?根节点的一阶邻域节点是哪些?什么时候停止搜索?
深度优先 DFS
- 深度优先搜索会沿着一条路径不断往下搜索直到不能再继续为止,然后再折返,开始搜索下一条候补路径。
- DFS一般流程类似于BFS,但是用栈而不是队列
微积分
链式法则
f(g(x))' = f'g'f(g(x),z(x))' = f'g' + f'z'- 参考:
线性代数
✒ 矩阵
- 矩阵代表一种对空间内所有点的线性变换,即线性地改变空间的标准正交基
- 线性变换:旋转、缩放
- 方阵可分解为特征值与特征向量,矩阵的变化过程可以用多个方向的缩放表示,特征值代表方向,特征值代表程度
评估指标
- accuracy 正确率:被分对的样本 / 所有样本
- precision 精度:分对的正样本 / 预测为正的样本
- recall 召回率(真阳性率):分对的正样本 / 正样本,有病的被查出来的概率
- 假阳性率:分错的负样本 / 负样本,没病的被当成有病的概率
- ROC曲线:滑动归类阈值来产生关键点并连接,横坐标为
1 - 假阳性率,纵坐标为真阳性率,线下面积AUC = (1 - 假阳性率)*真阳性率越高越好 - f1 score:
2*precision*recall / (precision + recall)
优化方法
- 最小二乘法:设偏导为0求解参数
- 梯度下降:朝着损失下降最快的方向迭代
SGD
Adam
损失函数
✒ Cross Entropy
- 交叉熵常用于分类问题,表示的是预测结果的概率分布与实际结果概率分布的差异
归一化
激活函数
Sigmoid/Logistic

- y = 1/(1+e^(-x))
- 导数 y' = y(1-y)
ML模型
Logistic Regression 逻辑回归
- 以sigmoid为激活函数的单层全连接网络
LDA 线性判别分析
- 将高维数据投影到二维进行分类,最小化投影后类内协方差,最大化投影后两个类别中心的距离
K-Means K均值聚类
- 简单,效率高
- 随机选择K个样本作为类心
- 把每个样本点归类到最近的类心下
- 重新计算每个类的均值作为新的类心
- 重复2~3直到收敛(类心变动不大)
Naive Bayes 朴素贝叶斯
- 根据训练集预估:已知条件B下某类A出现的概率
- 边缘概率(又称先验概率):某一个事件的概率
P(A) - 联合概率:多个事件共同发生的概率
P(A∩B) - 条件概率(又称后验概率):事件A在另外一个事件B已经发生条件下的发生概率
P(A|B) 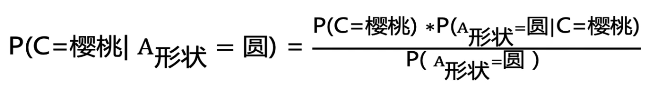
P(A|B) = P(A∩B)/P(B) = P(A)P(B|A)/P(B)- 总结:
P(樱桃|圆形) = P(樱桃∩圆形) / P(圆形)- 已知特征B的情况下推测样本属于A的概率 = 训练集中具备特征B的样本中存在类别A的概率

PCA 主成分分析
- 假设均值为0
- 朝着方差最大的基降维,不同基之间正交,基的个数即降维后数据维数
- 理解:
- 设输入为矩阵
M,形状N×3,N代表样本个数,3是特征通道数 -
C = M^T × M,C为协方差矩阵 - PCA要找到一个变换矩阵
Q,使得MQ的协方差矩阵成为一个对角阵。此时对角线上的方差有数值,而其余的协方差为0(降维后基正交)。 - 因此新的协方差矩阵
C' = (MQ)^T × MQ = Q^T M^T M Q = Q^T C Q = λ,同特征分解 - 为了尽可能保留数据特征,PCA希望在新的基上数据分散一些(方差大),故选择特征值大的特征向量作为
Q
- 设输入为矩阵
- 参考:
SVM 支持向量机
- 使得距离边界最近的点到边界的距离尽量大(Margin)
Decision Tree 决策树
- ★构造决策树
- 熵:信息量的期望 -∑Pi·ln(Pi)
- Gini系数(和熵一样用于衡量混乱度):
-∑Pi·(1-Pi) - 决策树以特征为节点,把原本规划到不同分支的叶子上
- 出于推理速度的考虑,决策树越矮越好,因此节点的熵降低越快越好
- 信息增益(添加节点后熵减小的程度) = 节点的熵 - ∑分支概率·分支后的熵
- ID3:以信息增益大的点作为新节点构树
- C4.5:为了排除类似ID特征一样的干扰项(增益高,分支下样本稀缺),以信息增益率(增益/分支方式的熵)作为添加节点的依据
- 损失函数C:叶子的熵的期望
∑Nt·H(t)越小越好,N代表叶子下样本量,H代表熵 - 连续值作为节点特征:区间化
- 剪枝
- 预剪枝(控制是否继续分叉)
- 提前停止(限制最大深度)
- 最小节点样本量(小于某个阈值不再分割)
- 后剪枝 损失函数C':C+α|T|,α为参数,|T|代表叶子数
- 参考:
Ensemble 集成学习
- Bootstraping:有放回采样
- Bagging:利用Bootstraping采样多次分别构造多个同类分类器,最后进行投票。可并行。降低了模型表现的方差variance。
- Boosting:递归地构建多个同类弱分类器,每个弱分类器都修正上一次的结果。不可并行。降低了模型表现的偏差bias。
- Stacking:堆叠不同的模型
- 参考:
-
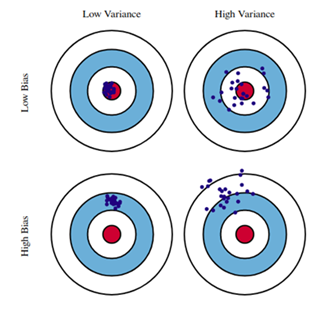 靶心指的是表现最好的模型
靶心指的是表现最好的模型 - 📘 知乎◽为什么说bagging是减少variance,而boosting是减少bias?
-

Random Forest 随机森林
- 样本选择(有放回):利用Bagging并行构造多颗决策树投票
- 特征选择(不放回):选取部分特征
Adaboost
- 递进地组合多个弱分类器形成一个强分类器,每轮根据上一个基分类器的效果调整数据权重,增加被分错的样本的权重
- 对每个训练样本赋予相同的权重,训练第一个基分类器
- 根据前一个基分类器的效果更新样本权重,重复此步骤多次得到多个基分类器
- 依据基分类器的表现,对所有基分类器的预测结果加权求和
GBDT
- 递进地组合多个弱分类器形成一个强分类器,每轮以之前组合模型的残差(真实值-预测值)作为标签学习一个决策树,预测残差
- 有一个样本[数据->标签]是:[(2,4,5)-> 4]
- 第一棵决策树用这个样本训练的预测为3.3
- 那么第二棵决策树训练时的输入,这个样本就变成了:[(2,4,5)-> 0.7]。也就是说,下一棵决策树输入样本会与前面决策树的训练和预测相关
- 重复引入新的树学习残差
- 把样本通过所有树的结果相加获得最终预测值
- 以上是针对均方差损失函数。然而,对于更复杂的损失函数,比如引入了正则项,则最优目标不是让预测值完全等于真实值。此时,可以用损失函数针对
- 总结:
- 仿照梯度下降原理,考虑:
Loss=LossFunction(之前的模型f(x)),那么要最小化损失,现在可以引入一个新的模型g,使得Loss=LossFunction(之前的模型f(x)+新模型g(x))最小。 - 根据梯度下降算法,可以让g(x)为f(x)的负梯度,通过不断迭代来逼近最小Loss,因此GBDT以f(x)的负梯度作为标签训练新的模型g
- 仿照梯度下降原理,考虑:
- 参考:
XGBoost
- 类似于GBDT,区别为:
- GBDT将LossFunction泰勒展开到一阶,而XGBoost将目标函数泰勒展开到了二阶
- GBDT是给新的基模型寻找新的拟合标签(前面加法模型的负梯度),而XGBoost是给新的基模型寻找新的目标函数(目标函数关于新的基模型的二阶泰勒展开)。换句话说,GBDT要求新模型最终预测值拟合负梯度,而XGBoost直接利用这种要求来构建最优决策树
- XGBoost加入了叶子权重的L2正则化项
- 参考:
深度学习
- 为方便表示,
σ为激活函数,S^t为t时隐状态,X为输入,Y为输出
RNN
S^t = σ(W1·X^t + W2·S^(t-1))Y^t = σ(W3·S^t)- 梯度问题:
S^t = σ(W1·X^t + W2·σ(W1·X^(t-1) + W2·σ(W1·X^(t-2) + W2·...))- 根据链式法则,W的梯度可以分解为多个时间步上梯度的累和,越远的时间步梯度需要连乘越多次W2σ'。连乘相同W多次,W过小容易导致梯度弥散,过大容易导致梯度爆炸
LSTM

- 拼接
H^(t-1)和X生成细胞状态C^~和三个门,遗忘门过滤C^(t-1),输入门过滤C^~,输出门过滤新的细胞状态C^t = tanh(过滤后的C^(t-1) + 过滤后的C^~)来生成隐向量H^t input_gate = sigmoid(W3·X^t + W4·H^(t-1))C^~ = tanh(W5·X^t + W6·H^(t-1))forget_gate = sigmoid(W1·X^t + W2·H^(t-1))C^t = forget_gate ⊙ C^(t-1) + input_gate ⊙ C^~output_gate = sigmoid(W7·X^t + W8·H^(t-1))H^t = output_gate ⊙ tanh(C^t)- 与RNN的核心不同:
-
C^~就是RNN中的State,相当于把State做了个门控式的残差连接 - 对
C^t也做了一个门控来生成最后的输出H^t
-
GRU ✒
- 拼接
H^(t-1)和X生成隐状态H^~和俩个门,重置门在生成隐状态H^~时过滤上一次的隐状态H^(t-1),更新门控制隐状态的残差连接,连接后直接作为新的隐向量 reset_gate = sigmoid(W1·X^t + W2·H^(t-1))H^~ = tanh(W3·X^t + reset_gate ⊙ W4·H^(t-1))update_gate = sigmoid(W5·X^t + W6·H^(t-1))H^t = (1 - update_gate) ⊙ H^(t-1) + update_gate ⊙ H^~- 与RNN的核心不同:
-
H^~就是RNN中的State,生成State时对H^(t-1)做了一个门控,同LSTM做了一个残差连接 - 隐状态直接作为输出
-
- 与LSTM的核心不同:
- 做残差的时候用更新门代替了输入门和遗忘门
- 把输出门提前了作为上一次状态的过滤
Transformer
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].