kong36088 / Baiduimagespider
Licence: mit
一个超级轻量的百度图片爬虫
Stars: ✭ 591
Programming Languages
Projects that are alternatives of or similar to Baiduimagespider
Decryptlogin
APIs for loginning some websites by using requests.
Stars: ✭ 1,861 (+214.89%)
Mutual labels: baidu, crawler, spider
Baiduspider
BaiduSpider,一个爬取百度搜索结果的爬虫,目前支持百度网页搜索,百度图片搜索,百度知道搜索,百度视频搜索,百度资讯搜索,百度文库搜索,百度经验搜索和百度百科搜索。
Stars: ✭ 105 (-82.23%)
Mutual labels: baidu, crawler, spider
Bilili
🍻 bilibili video (including bangumi) and danmaku downloader | B站视频(含番剧)、弹幕下载器
Stars: ✭ 379 (-35.87%)
Mutual labels: crawler, spider
Xsrfprobe
The Prime Cross Site Request Forgery (CSRF) Audit and Exploitation Toolkit.
Stars: ✭ 532 (-9.98%)
Mutual labels: crawler, spider
Netdiscovery
NetDiscovery 是一款基于 Vert.x、RxJava 2 等框架实现的通用爬虫框架/中间件。
Stars: ✭ 573 (-3.05%)
Mutual labels: crawler, spider
Haipproxy
💖 High available distributed ip proxy pool, powerd by Scrapy and Redis
Stars: ✭ 4,993 (+744.84%)
Mutual labels: crawler, spider
Fictiondown
小说下载|小说爬取|起点|笔趣阁|导出Markdown|导出txt|转换epub|广告过滤|自动校对
Stars: ✭ 362 (-38.75%)
Mutual labels: crawler, spider
Awesome Crawler
A collection of awesome web crawler,spider in different languages
Stars: ✭ 4,793 (+711%)
Mutual labels: crawler, spider
Signature algorithm
各种App、小程序、网站的请求签名或加密算法。 现已有:自如、小红书、蛋壳公寓、luckin coffee(瑞幸咖啡)、bangkokair(曼谷航空)
Stars: ✭ 380 (-35.7%)
Mutual labels: crawler, spider
Xxl Crawler
A distributed web crawler framework.(分布式爬虫框架XXL-CRAWLER)
Stars: ✭ 561 (-5.08%)
Mutual labels: crawler, spider
Webster
a reliable high-level web crawling & scraping framework for Node.js.
Stars: ✭ 364 (-38.41%)
Mutual labels: crawler, spider
Freshonions Torscraper
Fresh Onions is an open source TOR spider / hidden service onion crawler hosted at zlal32teyptf4tvi.onion
Stars: ✭ 348 (-41.12%)
Mutual labels: crawler, spider
BaiduImageSpider
百度图片爬虫,基于python3
个人学习开发用
单线程爬取百度图片
Required
需要安装python版本 >= 3.6
使用方法
$ python crawling.py -h
usage: crawling.py [-h] -w WORD -tp TOTAL_PAGE -sp START_PAGE
[-pp [{10,20,30,40,50,60,70,80,90,100}]] [-d DELAY]
optional arguments:
-h, --help show this help message and exit
-w WORD, --word WORD 抓取关键词
-tp TOTAL_PAGE, --total_page TOTAL_PAGE
需要抓取的总页数
-sp START_PAGE, --start_page START_PAGE
起始页数
-pp [{10,20,30,40,50,60,70,80,90,100}], --per_page [{10,20,30,40,50,60,70,80,90,100}]
每页大小
-d DELAY, --delay DELAY
抓取延时(间隔)
开始爬取图片
python crawling.py --word "美女" --total_page 10 --start_page 1 --per_page 30
另外也可以在crawling.py最后一行修改编辑查找关键字
图片默认保存在项目路径
运行爬虫:
python crawling.py
博客
效果图:
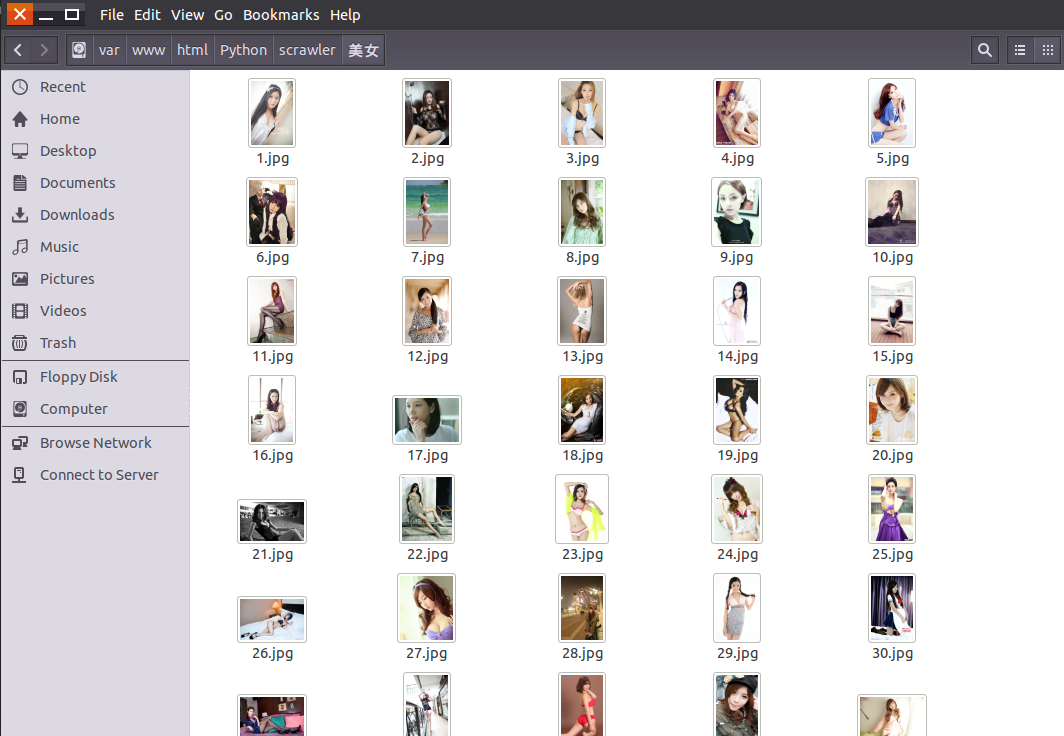
捐赠
您的支持是对我的最大鼓励!
谢谢你请我吃糖


Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].