Buddhabrot
Optimized Buddhabrot HDR image generators:
- Single threaded (CPU),
- multi-threaded OpenMP (CPU),
- multi-threaded C++14 (CPU) {forthcoming}
- multi-core using CUDA (GPU) {forthcoming},
- and multi-core using OpenCL {forthcoming},
Full image
This 4,500 x 6000 (27 Mega pixels!) at 524,288 depth image took 1 day, 18 hours on a MacBook Pro (i7 @ 2.8 GHz) utilizing all 8 cores.
{kind=link}
Here is a thumbnail image at 30% size (1350x1800):

Note: If low resolution images have a "blocky" look that is due to under-sampling the image -- the max depth is not deep enough.
Depth thumbnails
The maximum depth effects how many finer details are visible. Here are some depth comparisons:
 Depth 256
Depth 256
 Depth 512
Depth 512
 Depth 1,024
Depth 1,024
 Depth 2,048
Depth 2,048
 Depth 4,096
Depth 4,096
 Depth 8,192
Depth 8,192
 Depth 16,384
Depth 16,384
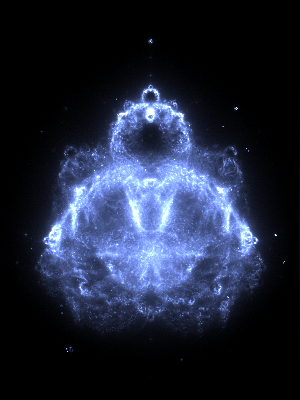 Depth 32,768
Depth 32,768
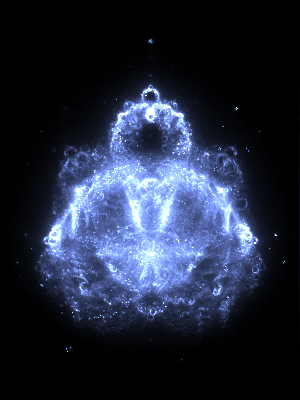 Depth 65,536
Depth 65,536
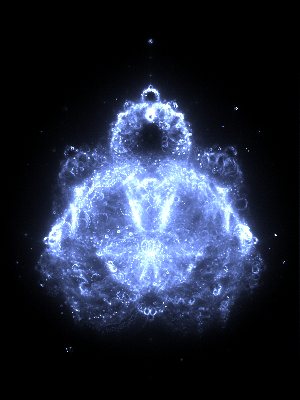 Depth 131,072
Depth 131,072
 Depth 262,144
Depth 262,144
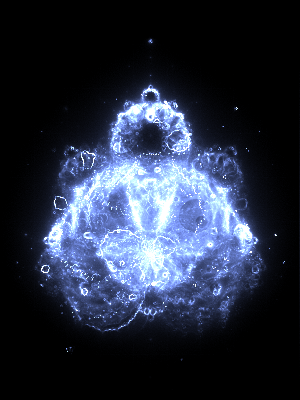 Depth 524,288
Depth 524,288
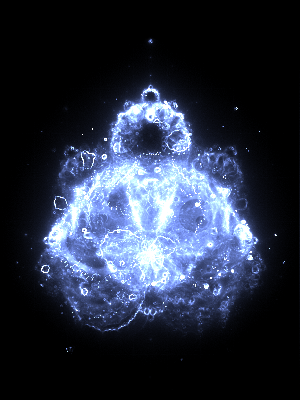 Depth 1,048,576
Depth 1,048,576
NOTE: These are HDR (High Dynamic Range) 16-bit single channel images (monochrome) converted into a SR (Standard Range) 8-bit / channel "false color" image.
HDR
Can I view/edit the raw HDR images in Photoshop or GIMP?
Yes for Photoshop, partially for GIMP.
Photoshop HDR
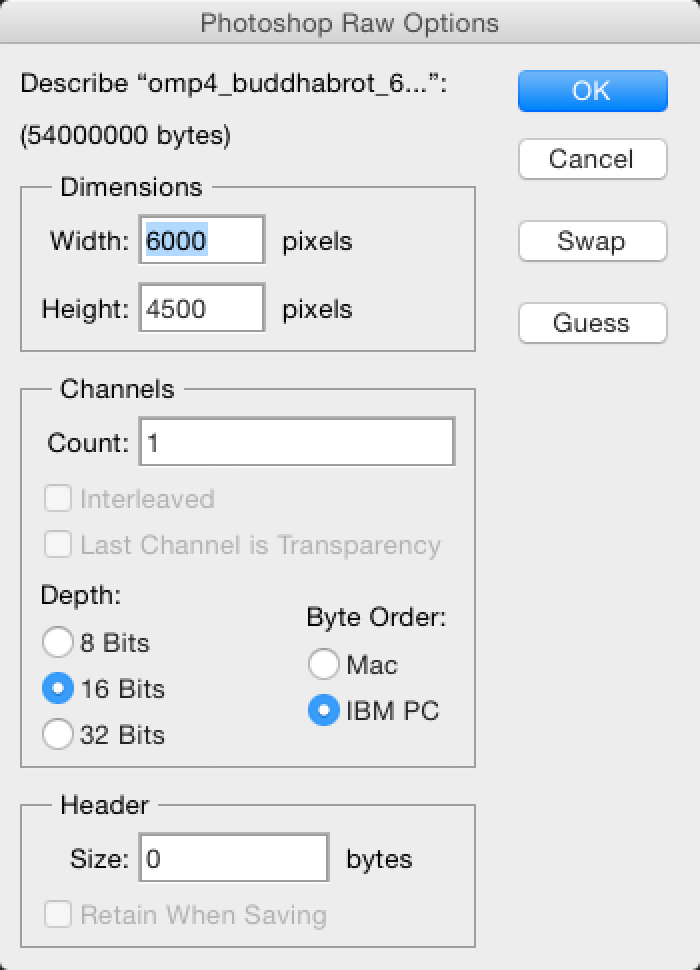
For example using the file omp4_buddhabrot_6000x4500_d524288_s10_j8.u16.data:
- Copy the file and rename the extension from
.datato.raw - File Open, and specify:
- Header: 0 (default)
- Channels: 1
- Width: 6000
- Height: 4500
- Depth: 16 Bits
- Byte Order: IBM PC (Little Endian)
- Image, Image Rotation, 90° CW
- Image, Mode, RGB Color
- Image, Adjustments, HDR Toning...
- Method: Local Adaptation
- Radius: 1
- Strength: 0.1
- Tone and Detail
- Gamma: 1 (or 2 for a little brighter)
- Exposure: -1 (or 0 for a little brighter)
- Detail: 0%
- Advanced
- Shadow: 0% (or -100% for a little deeper black)
- Highlight: 0%
- Tone Curve and Histogram
- Input: 11%
- Output: 0%
- Corner: Yes
The HDR image has a single channel. To produce a false color image you'll need to manually do layer blends.
i.e.
-
Layer, New, Layer
-
Name: Subtract Grey
-
Mode: Subtract
-
Background Color:
-
RGB: 7,7,7
-
Edit, Fill
-
Use: Background Color
-
Blending: Normal
-
Opacity: 100%
-
Layer, New, Layer
-
Name: Colorize
-
Mode: Overlay
-
Foreground Color
-
RGB: #0080FF (Or for a slightly brighter blue #7F9CFF)
-
Edit, Fill
-
Use: Foreground Color
-
Blending: Normal
-
Opacity: 100%
You'll want to save and then export to an 8-bit !
1350x1800 Thumbnail

Alternatively, you could also use 32 bits/channel preview
- Image, Mode, 32 bits/channel
- View, 32-Bit Preview Options...
- Exposure: 7
- Gamma: 2
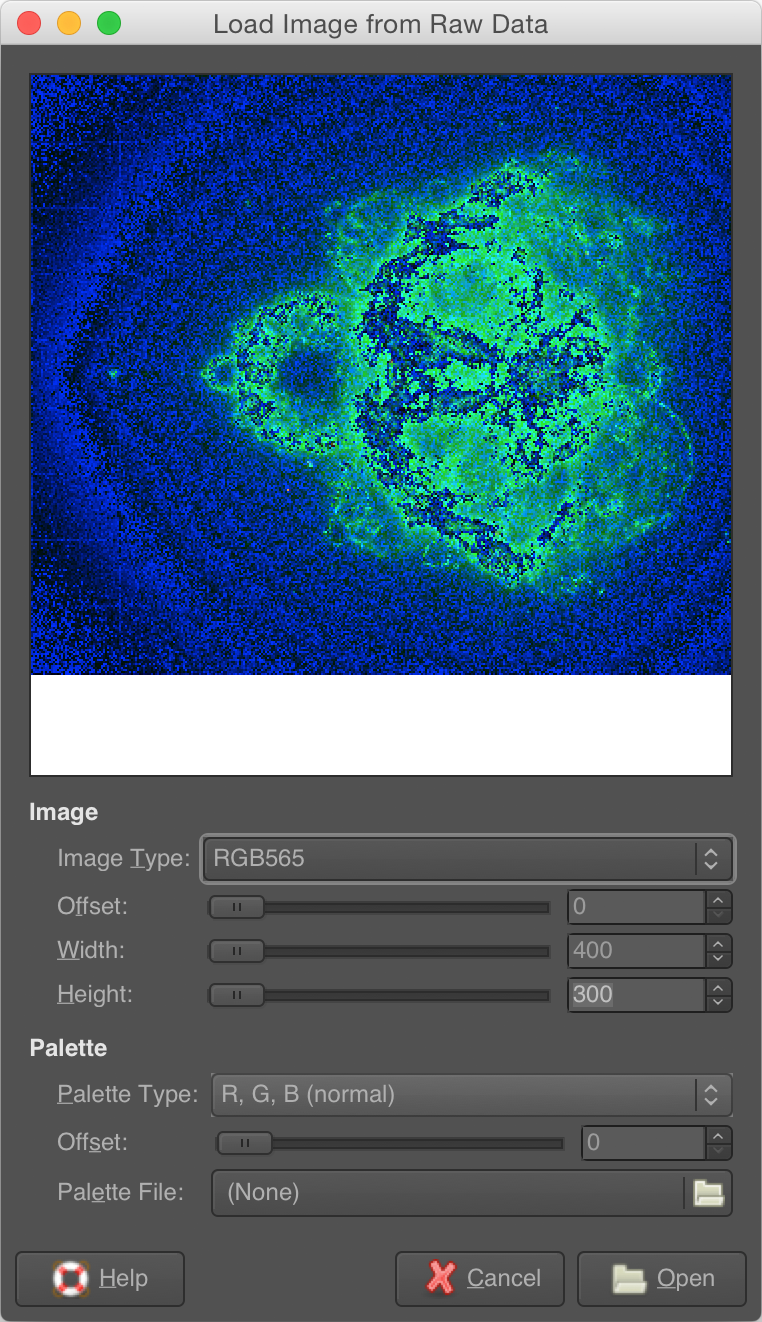
GIMP HDR
- File Open, File Type: RAW, and specify:
- Offset: 0 (default)
- Width
- Height
- Image Type: RGB565
- Palette: n/a
Unfortunately GIMP 2.8 is gimped -- it doesn't have proper 16-bit/channel support so you won't be able to view the monochrome HDR image, only a false 15-bit image.
Status
- Single threaded (CPU)
- Multi-threaded OpenMP
-
-j#Use a maximum number of threads -
--no-bmpDon't save BMP image -
--no-rawDon't save raw image -
--no-rotDon't rotate BMP -
-bmp foo.bmpSave BMP with specified filename -
-raw bar.rawsave RAW with specified filename
TODO
-
-hSave partial histogram images - Exposure settings via:
raw2bmp -bias # -min # - max # - MSVC solution and project -- not yet started
- Multi-threaded C++14 -- not yet started
- Multi-core CUDA -- not yet started
- Multi-core OpenCL -- not yet started
| Type | Linux | OSX | Windows | Filename |
|---|---|---|---|---|
| Single threaded | Done | Done | TODO | bin/buddhabrot |
| OpenMP | Done | Done | TODO | bin/omp2 |
| C++14 | TODO | TODO | TODO | bin/c14 |
| CUDA | TODO | TODO | TODO | bin/cuda |
| OpenCL | TODO | TODO | TODO | bin/ocl |
Compiling
You will need a compiler that supports OpenMP. (And eventually C++14, CUDA, and OpenCL.)
Windows
On Windows a MSVC (Microsoft Visual C++) solution and project are provided in build/. Currently a MSVC 2010 Express solution is available under build/Buddhabrot_MSVC2010Express.sln
If you try to use MSVC 2010 Express edition to build the OpenMP code note that the Express edition can generate OpenMP code BUT the required header and library files are not present out-of-the-box! They will be provided soon as a convenience.
Note: If you wish to use various OpenMP's directives #pragma omp with Microsoft's compiler, they in typical fashion, only support OpenMP 2.0 (and no later versions.)
OSX
To build type: make The makefile will detect the OS and use the right flags. Note that the CUDA versions are NOT built by default, you must use make cuda
For OpenMP support under OSX, Apple switched from the default compiler from gcc (which does) to llvm (which does not.) Here are the details and instructions on how to install gcc and get OpenMP support:
* OpenMP On OSX (10.8, 10.9)
There are 2 initial problems compiling with OpenMP under OSX.
a) The default C/C++ compiler is llvm not gcc; llvm does not (yet) support OpenMP.
The solution is to install and use gcc.
Install gcc 4.7 (or greater) from MacPorts
https://www.macports.org/install.php
sudo port install gcc47
sudo port select gcc mp-gcc477
usr/local/bin/g++ --version
b) Compiling with gcc you may get this error message:
Undefined symbols for architecture x86_64:
"_gomp_thread_attr", referenced from:
_initialize_env in libgomp.a(env.o)
ld: symbol(s) not found for architecture x86_64
There are 2 solutions:
1) Install gcc 4.7 (or greater) from MacPorts as documented above
or
2) Add the global thread symbol for gomp (Gnu OpenMP)
#include <pthread.h> // required on OSX 10.8
pthread_attr_t gomp_thread_attr;
To find out where OpenMP's header is:
sudo find / -name omp.h
Default on XCode 4.6 + Command Line Tools
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/usr/llvm-gcc-4.2/lib/gcc/i686-apple-darwin10/4.2.1/include/omp.h
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.7.sdk/Developer/usr/llvm-gcc-4.2/lib/gcc/i686-apple-darwin11/4.2.1/include/omp.h
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.7.sdk/usr/lib/gcc/i686-apple-darwin11/4.2.1/include/omp.h
/Applications/Xcode.app/Contents/Developer/usr/llvm-gcc-4.2/lib/gcc/i686-apple-darwin11/4.2.1/include/omp.h
If you have installed gcc:
/user/local/lib/gcc/x86_64-apple-darwin14.0.0/4.9.2/include/omp.h
/user/local/lib/gcc/x86_64-apple-darwin14.0.0/5.0.0/include/omp.h
Linux
See the OSX instructions for make
Running
To run the single threaded version bin/buddhabrot
To run the multi-threaded version bin/omp4
One can specify a custom resolution. If you change specify the width and height it is highly recommended you keep the aspect ratio of 4:3. e.g. bin/omp3 4000 3000
The raw data will be 4,000 x 3,000. The generated BMP will be rotated 90 degrees so the Buddhabrot appears in the "standard form" at 3,000 x 4,000.
Benchmarks
Using the default 1,024 x 768 at 1,000 depth we can see how much faster parallelizing the code can be:
| Hardware | org. | cpu1 | omp1 | omp2 | omp3 | cuda | ocl |
|---|---|---|---|---|---|---|---|
| Intel i7 @ 2.6 GHz | 0:57 | 0:55 | 0:22 | 0:17 | 0:10 | n/a | n/a |
| AMD 955BE@ 3.5 GHz | 1:37 | 1:29 | 1:00 | 0:42 | 0:30 | n/a | n/a |
(min:sec) (Lower is better)
Legend:
org. Original Evercat version
cpu1 Single core master reference
omp1 Multi core (OpenMP) initial version 1
omp2 Multi core (OpenMP) faster version 2
omp3 Multi core (OpenMP) fastest version 3
omp4 Multi core (OpenMP) version 3 with float32 instead of float64 for comparison
cuda Multi core (CUDA )
ocl Multi core (OpenCL)
c14 Multi core (C++14)
= Hardware =
Details on hardware used for building and testing:
| CPU | Clock | OS | RAM | GPU | Cores |
|---|---|---|---|---|---|
| Intel i7-4770K | 4040 MHz | Windows 7 Pro | 32 GB DDR3 1600 Mhz | GTX 980Ti | 2816 |
| Intel i7 | 2600 MHz | OSX 10.9 | 16 GB DDR3 1600 MHz | GT 750M | 384 |
| AMD Phenom II 955BE | 3500 MHz | Linux, Ubuntu 12.04 LTS | 16 GB DDR3 1333 MHz | GTX Titan | 2688 |
- Note: Sorry, no AMD FX-8350 or AMD GPU verification for now. I'll eventuallly add Radeon 290X timings.
= Threads =
Using the shell script jobs.sh we can see how the numbers of threads effects time for bin/omp3 on the AMD system:
| Command line | # | Time |
|---|---|---|
bin/omp3 -j1 |
1 | 1:31 |
bin/omp3 -j2 |
2 | 0:47 |
bin/omp3 -j3 |
3 | 0:33 |
bin/omp3 -j4 |
4 | 0:30 |
= Depth =
Using the shell script depth.sh we can see how depth effects time on the AMD box:
| Command line | Time |
|---|---|
bin/omp3 -v 4000 3000 4000 |
27:18 |
bin/omp3 4000 3000 4000 |
26:45 |
bin/omp3 -v 4000 3000 3000 |
??:?? |
bin/omp3 4000 3000 3000 |
??:?? |
bin/omp3 -v 4000 3000 2000 |
14:21 |
bin/omp3 4000 3000 2000 |
14:12 |
bin/omp3 -v 4000 3000 1000 |
8:01 |
bin/omp3 4000 3000 1000 |
7:52 |
| Command line | Seconds | Time |
|---|---|---|
/bin/omp2 4000 3000 2000 |
637 | 10:37 |
Tutorial: HOWTO Write a Multi-Core program
Let's convert a single core program, Buddhabrot, to a multi-core version.
Why Buddhabrot and not the more conventional Mandelbrot?
Two reasons:
- Mandlebrot is trivial to parallelize while Buddhabrot is not, as a result Buddhabrot is less popular,
- Buddhabrot looks cooler then the over-used Mandelbrot fractal.
== Introduction to Mandelbrot ==
TL:DR; For those not familiar with Mandelbrot here is a quick refresher: Given a complex point we iterate "max depth" times and check to see if that point "escapes" -- that is stopping if its length is > 2.0. If the current depth < max iterations then we plot it using a false color based on [0..depth].
In contradistinction the key difference between Mandelbort and Buddhabrot is that when a point "escapes" we plot a historgram of ALL the pixels of the "path" it took. Buddhabrot touching many pixels makes this a slightly more complicated problem to parallelize.
Here are some more details in how Mandelbrot works:
We start with a 2D region. We use complex numbers to define the dimensions of this region. The gist is that for each complex point in this region we do some processing to generate an image.
Given a complex point, P, we iterate the equation Zn+1 = Zn^2 + P a certain amount of times. We call the maximum number of iterations we process this equation the "maximum depth." If at any time the Euclidean length of this new point, |Zn+1|, is > 2.0 then we will denote the original point as "escaping" -- we will also note the "current depth" when this happened. How we plot this point depends on if we are rendering the Mandelbrot or Buddhabrot set:
With Mandelbrot:
If the current depth == max depth, then the original point doesn't escape and we don't plot it -- we simple leave the background "as is." However, if the current depth < max depth then the point P does "escape" and we plot a pixel with some false color based on the current depth and move on to processing the next point. Each complex point updates one and only one pixel in the output bitmap. This is trivial to parallelize and is nice and fast. The only "hard" part is is determining a "nice" color ramp you pick for pixel = [ 0 .. depth-1 ] which is what determines all those cool fractals. :-) End of the Mandelbrot story unless you were a FracInt user back in the day.
== Shut up and show me the (Mandelbrot) code! ==
Here is a small program to demonstrate how simple Mandelbrot is:
File: text_mandelbrot.cpp
#include <complex>
#include <stdio.h> // printf
#include <string.h> // memset
typedef std::complex<double> complex;
int MandelbrotCalculate( complex c, int max_depth )
{
// iterates z = z + c until |z| >= 2 or max_depth is reached,
// returns the number of iterations.
complex z = c;
int depth = 0;
for( depth = 0; depth < max_depth; ++depth )
{
// Optimization: Remove unnecessary square root by squaring both sides
//if( std::abs(z) >= 2.0) break;
if( (z.real()*z.real() + z.imag()*z.imag()) > 4.0) break;
z = z*z + c;
}
return depth;
}
void MandelbrotPlot( int depth, int x, int y, char *output, int width )
{
static const char charset[] = ".,c8M@jawrpogOQEPGJ";
char c = charset[ depth % (sizeof(charset)-1)];
output[ (y*width) + x ] = c;
}
int main()
{
const int width = 78, height = 44, num_pixels = width*height;
const complex center(-.7, 0),
span(2.7, -(4/3.0)*2.7*height/width), // 4/3 is aspect ratio
TopLeft = center - span/2.0;
const int max_depth = 100000;
char output[ height ][ width ];
memset( output, (int)' ', sizeof( output ) );
for(int pix=0; pix<num_pixels; ++pix)
{
const int x = pix%width, y = pix/width;
complex p = TopLeft + complex(
x * span.real() / (width +1.0),
y * span.imag() / (height+1.0));
int cur_depth = MandelbrotCalculate( p, max_depth );
if (cur_depth != max_depth)
{
MandelbrotPlot( cur_depth, x, y, (char*)output, width ); // output[y][x] = c
}
}
// We could have a 1 character skirt on the right edge and bottom
// but reserve one column and row for outputing.
for( int y = 0; y < height-1; y++ )
output[ y ][ width-1 ] = '\n';
output[ height-1 ][ width-1 ] = 0;
printf( "%s\n", &output[0][0] );
return 0;
}
Which produces this output:
..........,,,,,,,cccccccccccccccccccccccc888888888MMM@jprajwaM888888cccccc,,,
.........,,,,,,,ccccccccccccccccccccccc8888888888MMM@@jwoOQrj@M8888888cccccc,
.........,,,,,cccccccccccccccccccccccc8888888888MMMM@jaroEpaj@MM8888888cccccc
........,,,,,ccccccccccccccccccccccc8888888888MMMM@@aOrOJ .raj@MMM888888ccccc
.......,,,,,cccccccccccccccccccccc88888888888MMM@@@wQQGa MO8w@MMMMM88888cccc
.......,,,ccccccccccccccccccccccc8888888888MMM@@@jjarP @wj@@MMMMM8888ccc
......,,,cccccccccccccccccccccc8888888888MM@@@@@jjawo@ Qwaj@@@@MMMM88ccc
......,,cccccccccccccccccccccc88888888MMM@aaaraaawwrpQ Ogrwwaj@@@@wjM88cc
.....,,,cccccccccccccccccccc8888888MMMMM@jrpjgrro8EQcr@. oM.PJgEraajapr@M88c
.....,,ccccccccccccccccccc888888MMMMMM@@@jQQjgrOQQE p grp8ogg8MM8c
....,,ccccccccccccccccccc8888MMMMMMMM@@@jawGP c g.. rgwMM88
....,ccccccccccccccccc8888MMMMMMMMMM@@@jawrgGP crj@MM8
....,ccccccccccccccc888MMMMMMMMMMM@@@@jwOgQo Epaj@MM8
...,cccccccccccc88888Mja@@@@@@@@@@@jjjawOM ,waj@M8
...,cccccccc8888888MM@jwaajjjaoajjjjjaarPP OOpPjM8
...cccccc88888888MMM@@aoorrwwrOrwwaaawro JjM8
...cccc88888888MMMMM@@jwpJJPggPOO8pwwrpp jpa@M8
..,cc888888888MMMMMM@jjwr. @ .Epogp og@M8
..cc888888888MMMMMM@jjapoPg GjOE pww@M8
..c88888888MMMMMM@aaawrgQr ,. oQjMM8
..c8888888M@@@@@jjaGpggP w Oa@MM8
..8MMMMM@j@@@@jjjwwo@wGc a Jwj@MM8
..MM@@jjrgwawwawpggOJ .wj@@MM8
..MM@@jjrgwawwawpggOJ .wj@@MM8
..8MMMMM@j@@@@jjjwwo@wGc a Jwj@MM8
..c8888888M@@@@@jjaGpggP w Oa@MM8
..c88888888MMMMMM@aaawrgQO ,. oQjMM8
..cc888888888MMMMMM@jjapoPg GjOE pww@M8
..,cc888888888MMMMMM@jjwr. @ .Epogp og@M8
...cccc88888888MMMMM@@jwpJJPggPOO8pwwrpp rpa@M8
...cccccc88888888MMM@@aoorrwwrOrwwaaawro JjM8
...,cccccccc8888888MM@jwaajjjaoajjjjjaarPP OOpPjM8
...,cccccccccccc88888Mja@@@@@@@@@@@jjjawOM ,waj@M8
....,ccccccccccccccc888MMMMMMMMMMM@@@@jwOgQo Epaj@MM8
....,ccccccccccccccccc8888MMMMMMMMMM@@@jawrgGP crj@MM8
....,,ccccccccccccccccccc8888MMMMMMMM@@@jawGP c g.. rgwMM88
.....,,ccccccccccccccccccc888888MMMMMM@@@jQQjgrOQQE p grp8ogg8MM8c
.....,,,cccccccccccccccccccc8888888MMMMM@jrpjgrro8EQcr@. oM.PJgEraajapr@M88c
......,,cccccccccccccccccccccc88888888MMM@aaaraaawwrpQ Ogrwwaj@@@@wjM88cc
......,,,cccccccccccccccccccccc8888888888MM@@@@@jjawo@ Qwaj@@@@MMMM88ccc
.......,,,ccccccccccccccccccccccc8888888888MMM@@@jjarP @wj@@MMMMM8888ccc
.......,,,,,cccccccccccccccccccccc88888888888MMM@@@wQQGa MO8w@MMMMM88888cccc
........,,,,,ccccccccccccccccccccccc8888888888MMMM@@aOrOJ .raj@MMM888888ccccc
.........,,,,,cccccccccccccccccccccccc8888888888MMMM@jaroEpaj@MM8888888cccccc
Note: The original code used a costly square root with std::abs(z) > 2 in MandelbrotCalculate(). The very first things we can do is optimize that out.
for( depth = 0; depth < max_depth; ++depth )
{
// Optimization: Remove unnecessary square root by squaring both sides
//if( std::abs(z) >= 2.0) break;
if( (z.real()*z.real() + z.imag()*z.imag()) > 4.0) break;
z = z*z + c;
}
Moving on, let's take a quick look at an parallelized OpenMP version:
It isn't quite as fast as it could be since it serializes the output, but it shoulds the mininmal number of changes we need to convert this from singel core to multi core.
File: mandelbrot.cpp
#include <complex>
#include <cstdio>
#include <omp.h>
typedef std::complex<double> complex;
int MandelbrotCalculate(complex c, int maxiter)
{
// iterates z = z + c until |z| >= 2 or maxiter is reached,
// returns the number of iterations.
complex z = c;
int n=0;
for(; n<maxiter; ++n)
{
if( std::abs(z) >= 2.0) break;
z = z*z + c;
}
return n;
}
int main()
{
const int width = 78, height = 44, num_pixels = width*height;
const complex center(-.7, 0), span(2.7, -(4/3.0)*2.7*height/width);
const complex begin = center-span/2.0, end = center+span/2.0;
const int maxiter = 100000;
#pragma omp parallel for ordered schedule(dynamic)
for(int pix=0; pix<num_pixels; ++pix)
{
const int x = pix%width, y = pix/width;
complex c = begin + complex(
x * span.real() / (width +1.0),
y * span.imag() / (height+1.0));
int n = MandelbrotCalculate(c, maxiter);
if(n == maxiter) n = 0;
#pragma omp ordered
{
char c = ' ';
if(n > 0)
{
static const char charset[] = ".,c8M@jawrpogOQEPGJ";
c = charset[n % (sizeof(charset)-1)];
}
std::putchar(c);
if(x+1 == width) std::puts("|");
}
}
}
The Buddhabrot is mostly the same as Mandelbrot; the differences is how it is rendered:
const int iCol = iCel % nCol;
const int iRow = iCel / nCol;
const double x = gnWorldMinX + (iCol * dx);
const double y = gnWorldMinY + (iRow * dy);
/* */ double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = (r*r - i*i) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2.0*r*i) + y;
r = s;
i = j;
if ((r*r + i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, pTex, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
VERBOSE
if (iTid == 0)
{
const double percent = (100.0 * iCel) / nCel;
printf( "%6.2f%% = %d / %d%s", percent, iCel, nCel, gaBackspace );
fflush( stdout );
}
}
= Single Core =
With Buddhabrot:
Things are slightly more complicated as we iterate the depth (potentially) twice for each point.
Let's say we have two points A and B in this region.
We iterate the complex Zn+1 = Zn^2 + A equation for A. Say after depth iterations we find it does NOT escape. We don't plot anything for this point. We're done with A and move on.
We now process B and say we find after depth iterations it DOES escapes. Now this is where things become interesting. We restart the equation again but this time for each Zn+1 we plot it's current location. By plot we mean update a 2D histogram bitmap. This has has the effect of leaving a "ghost trail."
Now here's the multi-core problem: You give each point P its own thread. Each point P is potentially updating hundreds of pixels. Since it is a shared read-update-write resource we MUST synchronize access to the shared histogram bitmap, say using a critical section; if we don't then we'll get "dropped" pixels. On the other hand if we synchronize access we completely kill performance! Whoops! Damn'd if you do, damn'd if you don't.
One minor optimization we can do with the Mandlebrot / Buddhabrot test "if escapes" is to remove that costly square root.
if( sqrtf( r*r + i*i ) > 2.0 )
With the equivalent:
if ((r*r + i*i) > 4.0)
This is what we have so far:
int iCol = 0;
for( double x = gnWorldMinX; x < gnWorldMaxX; x += dx )
{
iCol++;
for( double y = gnWorldMinY; y < gnWorldMaxY; y += dy )
{
double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = (r*r - i*i)) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2*r*i) + y;
r = s;
i = j;
if ((r*r + i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, gpGreyscaleTexels, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
}
Let's also display a percentage based on the columns we've completed.
if( bDisplayProgress ) // Update % complete for each column
{
const double percent = (100.0 * iCol) / nCol;
for( int i = 0; i < 40; i++ )
printf( "%c", 8 ); // ASCII backspace
printf( "%6.2f%% = %d / %d", percent, iCel, nCel ); // iCol, nCol );
fflush( stdout );
}
}
AMD: 1:29 (89 seconds)
While not impressive, we've already wittled off 10 seconds just by a little cleanup.
= Multi Core (OpenMP) =
== Pre-OpenMP cleanup ==
To properly convert from single-core to multi-core we first need to do a few things:
- When using OpenMP it can run a for() loop in parallel but ONLY if the loop index is an integer, not a floating-point value. Hmm.
We convert from steping by dx and dy (floating-point) to stepping along the scaled width and scaled height (integers.) This means we'll recompute the world space coordintes.
See, File: buddhabrot.cpp, Func: Buddhabrot()
for( int iCol = 0; iCol < nCol; iCol++ )
{
const double x = gnWorldMinX + (dx*iCol);
for( int iRow = 0; iRow < nRow; iRow++ )
{
const double y = gnWorldMinY + (dy*iRow);
iCel++;
double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = (r*r - i*i) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2.0*r*i) + y;
r = s;
i = j;
if ((r*r) + (i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, gpGreyscaleTexels, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
}
if( bDisplayProgress )
{
const double percent = (100.0 * iCel) / nCel;
for( int i = 0; i < 40; i++ )
printf( "%c", 8 ); // ASCII backspace
printf( "%6.2f%% = %d / %d", percent, iCel, nCel );
fflush( stdout );
}
}
- Since we have N threads all fighting for contention over a single resource (greyscale output bitmap) we instead allocate N greyscale bitmaps so each thread has its own indepent local copy -- this will prevent costly
synchronizationfences / barries / waiting.
First, we'll need to extend our initial image allocation to allocate N images -- one for each thread.
Func: AllocImageMemory()
// BEGIN OMP
gnThreads = omp_get_num_procs();
printf( "Detected: %d cores\n", gnThreads );
for( int iThread = 0; iThread < gnThreads; iThread++ )
{
gaThreadsTexels[ iThread ] = (uint16_t*) malloc( nGreyscaleBytes );
memset( gaThreadsTexels[ iThread ], 0, nGreyscaleBytes );
}
// END OMP
Next, once we all done then we will then merge (add) all the thread's bitmap back into a single master image.
// BEGIN OMP
// 2. Gather
const int nPix = gnWidth * gnHeight; // Normal area
for( int iThread = 0; iThread < gnThreads; iThread++ )
{
const uint16_t *pSrc = gaThreadsTexels[ iThread ];
/* */ uint16_t *pDst = gpGreyscaleTexels;
for( int iPix = 0; iPix < nPix; iPix++ )
*pDst++ += *pSrc++;
}
// END OMP
Now whenever writing any multi-core program it is best to have a reference single core version to "fall back" onto. This will allow us to do a diff on the output (raw.data or .bmp) to check for divergence. Translation: Detect bugs in the multi-core versions.
On our AMD platform the original version runs in 1:37 (97 seconds) -- this is mostly due to three things:
- is single threaded,
- excessive printf() calls,
- for() loop with extra counters (floating point and integer)
Since the original version has numerous bugs, lacks features, and is hard-coded we'll clean it up so the code is clean, clear, compact, and concise. Along the way we'll also add multi-core support and provide timings of various hardware so we can see just how much faster each version becomes.
| CPU | Time |
|---|---|
| AMD | 0:42 |
int Buddhabrot()
{
if( gnScale < 0)
gnScale = 1;
const int nCol = gnWidth * gnScale ; // scaled width
const int nRow = gnHeight * gnScale ; // scaled height
const int nCel = nCol * nRow ; // scaled width * scaled height;
const double nWorldW = gnWorldMaxX - gnWorldMinX;
const double nWorldH = gnWorldMaxY - gnWorldMinY;
// Map Source (world space) to Pixels (image space)
const double nWorld2ImageX = (double)(gnWidth - 1.) / nWorldW;
const double nWorld2ImageY = (double)(gnHeight - 1.) / nWorldH;
const double dx = nWorldW / (nCol - 1.0);
const double dy = nWorldH / (nRow - 1.0);
// 1. Scatter
// Linearize to 1D
// BEGIN OMP
#pragma omp parallel for
// END OMP
for( int iCel = 0; iCel < nCel; iCel++ )
{
// BEGIN OMP
const int iTid = omp_get_thread_num(); // Get Thread Index: 0 .. nCores-1
/* */ uint16_t* pTex = gaThreadsTexels[ iTid ];
// END OMP
const int iCol = iCel % nCol;
const int iRow = iCel / nCol;
const double x = gnWorldMinX + (iCol * dx);
const double y = gnWorldMinY + (iRow * dy);
/* */ double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = (r*r - i*i) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2.0*r*i) + y;
r = s;
i = j;
if ((r*r + i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, pTex, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
VERBOSE
// BEGIN OMP
if( (iTid == 0) && (iCel % gnWidth == 0) )
// END OMP
{
// We no longer need a critical section
// since we only allow thread 0 to print
{
const double percent = (100.0 * iCel) / nCel;
for( int i = 0; i < 40; i++ )
printf( "%c", 8 ); // ASCII backspace
printf( "%6.2f%% = %d / %d", percent, iCel, nCel );
fflush( stdout );
}
}
}
// BEGIN OMP
// 2. Gather
const int nPix = gnWidth * gnHeight; // Normal area
for( int iThread = 0; iThread < gnThreads; iThread++ )
{
const uint16_t *pSrc = gaThreadsTexels[ iThread ];
/* */ uint16_t *pDst = gpGreyscaleTexels;
for( int iPix = 0; iPix < nPix; iPix++ )
*pDst++ += *pSrc++;
}
// END OMP
return nCel;
}
== Multi-Core version 1 ==
When using OpenMP it is easy to miss some of the syntax for the #pragma's.
i.e. When you parallelize a for loop() there are 2 subtle but different outcomes.
omp parallel -- spawn a group of threads, for() excuted for each thread!
omp parallel for -- divie loop amongst all threads, each thread does partial work
Using omp parallel won't produce the desired outcome.
#pragma omp parallel for
for( int iCol = 0; iCol < nCol; iCol++ )
{
const double x = gnWorldMinX + (dx*iCol);
// BEGIN OMP
int iTid = omp_get_thread_num(); // Get Thread Index: 0 .. nCores-1
uint16_t* pTex = gaThreadsTexels[ iTid ];
// END OMP
for( int iRow = 0; iRow < nRow; iRow++ )
{
double y = gnWorldMinY + (dy*iRow);
// BEGIN OMP
#pragma omp atomic
iPix++;
// END OMP
double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = ((r*r) - (i*i)) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2*r*i) + y;
r = s;
i = j;
if( (r*r + i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, pTex, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
}
// BEGIN OMP
if( iTid > -1 ) // All threads can print but need to guard with a critical section
// END OMP
if( bDisplayProgress )
{
double percent = (100.0 * iPix) / nPix;
#pragma omp critical
{
for( int i = 0; i < 32; i++ )
printf( "%c", 8 ); // ASCII backspace
printf( "%6.2f%% = %d / %d", percent, iPix, nPix ); // iCol, nCol );
fflush( stdout );
}
}
}
On our AMD box we've gone from our initial 1:37 to 1:00 which isn't bad. How much faster is this? The formulate is:
% faster = 100 * (1 - (new time / old time))
= 100 * 1 - (59 / 96)
= 38.5% faster
Can we do better?
== Faster Multi-Core? ==
Inspecting the CPU load (Linux: System Monitor, OSX: Activity Monitor, Windows: Task Manager) we notice that only a few cores tend to be pegged. :-(
Why?
The key to good multi-core performance is load balancing. We have 2 loops but we're only effectively parallelizing the outer. Ack!
If we "linearize" the 2D loop into a 1D loop we can achieve better CPU utilization; we are breaking large tasks down into smaller ones that can be scheduled across the cores.
// 1. Scatter
// Linearize to 1D
#pragma omp parallel for
for( int iCel = 0; iCel < nCel; iCel++ )
{
// BEGIN OMP
const int iTid = omp_get_thread_num(); // Get Thread Index: 0 .. nCores-1
/* */ uint16_t* pTex = gaThreadsTexels[ iTid ];
// END OMP
const int iCol = iCel % nCol;
const int iRow = iCel / nCol;
const double x = gnWorldMinX + (iCol * dx);
const double y = gnWorldMinY + (iRow * dy);
/* */ double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = (r*r - i*i) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2*r*i) + y;
r = s;
i = j;
if ((r*r + i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, pTex, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
if( iTid == 0 )
if( bDisplayProgress )
{
{
const double percent = (100.0 * iCel) / nCel;
for( int i = 0; i < 40; i++ )
printf( "%c", 8 ); // ASCII backspace
printf( "%6.2f%% = %d / %d", percent, iCel, nCel );
fflush( stdout );
}
}
}
// BEGIN OMP
// 2. Gather
const int nPix = gnWidth * gnHeight; // Normal area
for( int iThread = 0; iThread < gnThreads; iThread++ )
{
const uint16_t *pSrc = gaThreadsTexels[ iThread ];
/* */ uint16_t *pDst = gpGreyscaleTexels;
for( int iPix = 0; iPix < nPix; iPix++ )
*pDst++ += *pSrc++;
}
// END OMP
We try out the new code bin/omp2 and see we have a time of 0:42 seconds which looks great!
% faster = 100 * (1 - (new time / old time))
= 100 * 1 - (47 / 96)
= 51.04% faster
=== Bottlenecks? ===
Except there is one minor performance penalty. What!?
Hint: It is with output.
Notice that if we are displaying the progress then for every cell update we are calling printf() and fflush(). This means we are spending enormous amounts of time outputting the progress -- all this overheads adds up! Ideally we would check every N cells. Just how bad is this?
For example, on the i7
bin/omp2 # 17 seconds, 0:17
bin/omp2 -v # 73 seconds, 1:13
Whoa!
Fortunately the fix is simple:
From:
if( bDisplayProgress )
if( iTid == 0 )
To:
if( bDisplayProgress )
if( (iTid == 0) && (iCel % gnWidth == 0) )
With output on the i7 we're back down to:
bin/omp2 -v # 22 seconds, 0:22
However we still have a problem. For some reason on OSX the progress will "stall" at 12.50%.
In order to have an accurate progress with multi-core we must use an atomic counter.
#pragma omp atomic
iPix++;
Fortunately atomics are relatively cheap. Here is the final version:
// 1. Scatter
// Linearize to 1D
// BEGIN OMP
#pragma omp parallel for
// END OMP
for( int iPix = 0; iPix < nCel; iPix++ )
{
// BEGIN OMP
#pragma omp atomic
iCel++;
const int iTid = omp_get_thread_num(); // Get Thread Index: 0 .. nCores-1
/* */ uint16_t* pTex = gaThreadsTexels[ iTid ];
// END OMP
const int iCol = iCel % nCol;
const int iRow = iCel / nCol;
const double x = gnWorldMinX + (iCol * dx);
const double y = gnWorldMinY + (iRow * dy);
/* */ double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = (r*r - i*i) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2.0*r*i) + y;
r = s;
i = j;
if ((r*r + i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, pTex, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
VERBOSE
// BEGIN OMP
if (iTid == 0)
// END OMP
{
// We no longer need a critical section
// since we only allow thread 0 to print
{
const double percent = (100.0 * iCel) / nCel;
printf( "%6.2f%% = %d / %d%s", percent, iCel, nCel, gaBackspace );
fflush( stdout );
}
}
}
| CPU | Time |
|---|---|
| AMD 955BE | 0:42 |
int Buddhabrot()
{
if( gnScale < 0)
gnScale = 1;
const int nCol = gnWidth * gnScale ; // scaled width
const int nRow = gnHeight * gnScale ; // scaled height
const int nCel = nCol * nRow ; // scaled width * scaled height;
const double nWorldW = gnWorldMaxX - gnWorldMinX;
const double nWorldH = gnWorldMaxY - gnWorldMinY;
// Map Source (world space) to Pixels (image space)
const double nWorld2ImageX = (double)(gnWidth - 1.) / nWorldW;
const double nWorld2ImageY = (double)(gnHeight - 1.) / nWorldH;
const double dx = nWorldW / (nCol - 1.0);
const double dy = nWorldH / (nRow - 1.0);
// 1. Scatter
// Linearize to 1D
// BEGIN OMP
#pragma omp parallel for
// END OMP
for( int iCel = 0; iCel < nCel; iCel++ )
{
// BEGIN OMP
const int iTid = omp_get_thread_num(); // Get Thread Index: 0 .. nCores-1
/* */ uint16_t* pTex = gaThreadsTexels[ iTid ];
// END OMP
const int iCol = iCel % nCol;
const int iRow = iCel / nCol;
const double x = gnWorldMinX + (iCol * dx);
const double y = gnWorldMinY + (iRow * dy);
/* */ double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = (r*r - i*i) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2.0*r*i) + y;
r = s;
i = j;
if ((r*r + i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, pTex, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
VERBOSE
// BEGIN OMP
if( (iTid == 0) && (iCel % gnWidth == 0) )
// END OMP
{
// We no longer need a critical section
// since we only allow thread 0 to print
{
const double percent = (100.0 * iCel) / nCel;
for( int i = 0; i < 40; i++ )
printf( "%c", 8 ); // ASCII backspace
printf( "%6.2f%% = %d / %d", percent, iCel, nCel );
fflush( stdout );
}
}
}
// BEGIN OMP
// 2. Gather
const int nPix = gnWidth * gnHeight; // Normal area
for( int iThread = 0; iThread < gnThreads; iThread++ )
{
const uint16_t *pSrc = gaThreadsTexels[ iThread ];
/* */ uint16_t *pDst = gpGreyscaleTexels;
for( int iPix = 0; iPix < nPix; iPix++ )
*pDst++ += *pSrc++;
}
// END OMP
return nCel;
}
== Fastest Multi-Core? ==
Is this the fastest we can do? Believe it or not we can further tweak the inner loop:
// @return Number of input scaled pixels (Not uber total of all pixels processed)
// ========================================================================
int Buddhabrot()
{
if( gnScale < 0)
gnScale = 1;
const int nCol = gnWidth * gnScale ; // scaled width
const int nRow = gnHeight * gnScale ; // scaled height
/* */ int iCel = 0 ; // Progress status for percent compelete
const int nCel = nCol * nRow ; // scaled width * scaled height;
const double nWorldW = gnWorldMaxX - gnWorldMinX;
const double nWorldH = gnWorldMaxY - gnWorldMinY;
// Map Source (world space) to Pixels (image space)
const double nWorld2ImageX = (double)(gnWidth - 1.) / nWorldW;
const double nWorld2ImageY = (double)(gnHeight - 1.) / nWorldH;
const double dx = nWorldW / (nCol - 1.0);
const double dy = nWorldH / (nRow - 1.0);
// BEGIN OMP
// 1. Scatter
// Linearize to 1D
#pragma omp parallel for
// END OMP
for( int iPix = 0; iPix < nCel; iPix++ )
{
// BEGIN OMP
#pragma omp atomic
iCel++;
const int iTid = omp_get_thread_num(); // Get Thread Index: 0 .. nCores-1
/* */ uint16_t* pTex = gaThreadsTexels[ iTid ];
// END OMP
const int iCol = iCel % nCol;
const int iRow = iCel / nCol;
const double x = gnWorldMinX + (iCol * dx);
const double y = gnWorldMinY + (iRow * dy);
/* */ double r = 0., i = 0., s, j;
for (int depth = 0; depth < gnMaxDepth; depth++)
{
s = (r*r - i*i) + x; // Zn+1 = Zn^2 + C<x,y>
j = (2.0*r*i) + y;
r = s;
i = j;
if ((r*r + i*i) > 4.0) // escapes to infinity so trace path
{
plot( x, y, nWorld2ImageX, nWorld2ImageY, pTex, gnWidth, gnHeight, gnMaxDepth );
break;
}
}
VERBOSE
// BEGIN OMP
if (iTid == 0)
// END OMP
{
// We no longer need a critical section
// since we only allow thread 0 to print
{
const double percent = (100.0 * iCel) / nCel;
printf( "%6.2f%% = %d / %d%s", percent, iCel, nCel, gaBackspace );
fflush( stdout );
}
}
}
// BEGIN OMP
// 2. Gather
const int nPix = gnWidth * gnHeight; // Normal area
for( int iThread = 0; iThread < gnThreads; iThread++ )
{
const uint16_t *pSrc = gaThreadsTexels[ iThread ];
/* */ uint16_t *pDst = gpGreyscaleTexels;
for( int iPix = 0; iPix < nPix; iPix++ )
*pDst++ += *pSrc++;
}
// END OMP
return nCel;
}
Timings:
| CPU | Time |
|---|---|
| i7 | 0:10 |
| AMD 955BE | 0:28 |
Our third tweak gets our best time on the AMD box down to:
% faster = 100 * (1 - (new time / old time))
= 100 * 1 - (28 / 96)
= 70.83% faster
== Bottlenecks revisted ==
The previous timing was our best case. If we again turn on output our time for the AMD box goes from 0:28 to ?:??.
The problem is this naive if() that determines how often we display our progress.
// BEGIN OMP
if (iTid == 0)
// END OMP
{
}
What is happening? We are spending valuable time displaying our progress ...
+----+----+----+----+----+----+----+----+----+----+
|work| % |work| % |work| % |work| % |work| % |
+----+----+----+----+----+----+----+----+----+----+
1s 1s 1s 1s 1s 1s 1s 1s 1s 1s
... instead of spending the majority of time doing work!
+----+----+----+----+----+----+----+----+----+----+
|work|work|work|work|work|work|work|work|work| % |
+----+----+----+----+----+----+----+----+----+----+
1s 1s 1s 1s 1s 1s 1s 1s 1s 1s
Given the same length of time we are only doing 50% of the work compared to the best case of 100% work with no output.
+----+----+----+----+----+----+----+----+----+----+
|work|work|work|work|work|work|work|work|work|work|
+----+----+----+----+----+----+----+----+----+----+
1s 1s 1s 1s 1s 1s 1s 1s 1s 1s
The question then becomes how often should we interleave work and updating the progress? In the previous version we simply used the non-scaled width:
// BEGIN OMP
if( (iTid == 0) && (iCel % gnWidth == 0) )
// END OMP
{
}
Lets remove that costly division and replace it with something simpler and faster.
// BEGIN OMP
if( (iTid == 0) && ((iCel & frequency) == 0) )
// END OMP
{
}
What is a good balance for the frequency? Let's compare some frequencies running bin/omp3 -v 4000 3000
| Frequency | Hex | Time | +% |
|---|---|---|---|
| 0 | n/a | ??:?? | < 0.01% |
| 2^8-1 | 0xFF | 10:16 | < 0.01% |
| width | 4000 | 8:19 | < 0.01% |
| 2^12-1 | 0xFFF | 8:19 | 0.02% |
| 2^16-1 | 0xFFFF | 8:09 | 0.03% |
| 2^20-1 | 0xFFFFF | 8:34 | 13.98% |
| 2^24-1 | 0xFFFFFF | 8:08 | 34.95% |
| no output | n/a | 8:02 | n/a |
Thus we see that there is always a trade-off between raw speed and displaying a progress. If we update the progress more frequent then it will take longer to actually finish the rendering.
== A matter of precision? ==
Since we are using doubles what would happen if we used floats?
File: buddhabrot_omp3float.cpp
Luckily Modern CPU's don't have a float64 penalty compared to float32. When we run this on the GPU we'll revisit this difference. i.e. Modern GPU float:double performance can be as little as 1:3 in high end graphics cards such as the original nVidia GTX Titan, or as high as 1:24 in "gaming" graphics cards such as the nVidia GTX 980.
= Verification =
Ther is a shell script verify.sh (Linux, OSX) that will very the raw output for the various versions.
Conclusions
Parallelzing an algorithm is not always possible. Sometimes we have to think "out of the box" to do so. Hopefully this tutorial has inspired you to add multi-core
Utilities
raw2bmpConvert a raw 16-bit .data to .bmpcuda-infoDisplay # of cores on your nVidia GPU
Interesting Buddhabrot Links
- http://erleuchtet.org/2010/07/ridiculously-large-buddhabrot.html
- http://www.fractalforums.com/mandelbulb-implementation/webgl-mandelbulb-with-three-js-flythrough-controls-%28optimizations-wanted%29/
- http://www.fractalforums.com/programming/buddhabrot-on-gpu/
- https://sites.google.com/site/buddhabrotmt/
- http://code.google.com/p/buddahbrot-opencl/
- https://devtalk.nvidia.com/default/topic/472080/most-amazing-fractal-renderer-buddhabrots-comes-with-source-code-and-ready-to-run-binaries/
- http://www.ozone3d.net/tutorials/mandelbrot_set_p6.php
- http://www.infinityk.com/asier/portfolio/buddhabrot-rendered-using-opencl/
Intersting Mandelbrot Links
- http://www.aluminumstudios.com/under-the-bodhi-tree-buddhabrot-animation/
- https://www.youtube.com/watch?v=0jGaio87u3A
References
- PDF: A "Hands-on" Introduction to OpenMP
- PDF: OpenMP by Example
- HTML: https://computing.llnl.gov/tutorials/openMP/
- PPT: http://www.cs.berkeley.edu/~mhoemmen/cs194/Lectures/openmp-tutorial.ppt
- https://software.intel.com/en-us/node/527527
- http://stackoverflow.com/questions/14016026/openmp-and-pragma-omp-atomic
- http://stackoverflow.com/questions/1448318/omp-parallel-vs-omp-parallel-for
- C++ Thread Library -- http://en.cppreference.com/w/cpp/thread
- C++ std::thread -- http://en.cppreference.com/w/cpp/thread/thread