go-crawler / Douban Movie
Golang爬虫 爬取豆瓣电影Top250
Stars: ✭ 114
Projects that are alternatives of or similar to Douban Movie
Geziyor
Geziyor, a fast web crawling & scraping framework for Go. Supports JS rendering.
Stars: ✭ 1,246 (+992.98%)
Mutual labels: crawler, spider
Crawler examples
Some classic web crawler projects.一些经典的爬虫
Stars: ✭ 74 (-35.09%)
Mutual labels: crawler, spider
Beanbun
Beanbun 是用 PHP 编写的多进程网络爬虫框架,具有良好的开放性、高可扩展性,基于 Workerman。
Stars: ✭ 1,096 (+861.4%)
Mutual labels: crawler, spider
Lxspider
爬虫案例合集。包括但不限于《淘宝、京东、天猫、豆瓣、抖音、快手、微博、微信、阿里、头条、pdd、优酷、爱奇艺、携程、12306、58、搜狐、百度指数、维普万方、Zlibraty、Oalib、小说、招标网、采购网、小红书》
Stars: ✭ 60 (-47.37%)
Mutual labels: crawler, douban
Baiduspider
BaiduSpider,一个爬取百度搜索结果的爬虫,目前支持百度网页搜索,百度图片搜索,百度知道搜索,百度视频搜索,百度资讯搜索,百度文库搜索,百度经验搜索和百度百科搜索。
Stars: ✭ 105 (-7.89%)
Mutual labels: crawler, spider
Avbook
AV 电影管理系统, avmoo , javbus , javlibrary 爬虫,线上 AV 影片图书馆,AV 磁力链接数据库,Japanese Adult Video Library,Adult Video Magnet Links - Japanese Adult Video Database
Stars: ✭ 8,133 (+7034.21%)
Mutual labels: crawler, spider
Ruia
Async Python 3.6+ web scraping micro-framework based on asyncio
Stars: ✭ 1,366 (+1098.25%)
Mutual labels: crawler, spider
Crawler Detect
🕷 CrawlerDetect is a PHP class for detecting bots/crawlers/spiders via the user agent
Stars: ✭ 1,549 (+1258.77%)
Mutual labels: crawler, spider
Awesome Python Primer
自学入门 Python 优质中文资源索引,包含 书籍 / 文档 / 视频,适用于 爬虫 / Web / 数据分析 / 机器学习 方向
Stars: ✭ 57 (-50%)
Mutual labels: crawler, spider
Arachnid
Powerful web scraping framework for Crystal
Stars: ✭ 68 (-40.35%)
Mutual labels: crawler, spider
Photon
Incredibly fast crawler designed for OSINT.
Stars: ✭ 8,332 (+7208.77%)
Mutual labels: crawler, spider
Crawlab
Distributed web crawler admin platform for spiders management regardless of languages and frameworks. 分布式爬虫管理平台,支持任何语言和框架
Stars: ✭ 8,392 (+7261.4%)
Mutual labels: crawler, spider
Gopa Abandoned
GOPA, a spider written in Go.(NOTE: this project moved to https://github.com/infinitbyte/gopa )
Stars: ✭ 98 (-14.04%)
Mutual labels: crawler, spider
Skycaiji
蓝天采集器是一款免费的数据采集发布爬虫软件,采用php+mysql开发,可部署在云服务器,几乎能采集所有类型的网页,无缝对接各类CMS建站程序,免登录实时发布数据,全自动无需人工干预!是网页大数据采集软件中完全跨平台的云端爬虫系统
Stars: ✭ 1,514 (+1228.07%)
Mutual labels: crawler, spider
爬取豆瓣电影 Top250
爬虫是标配了,第一个就从最最最简单的爬虫开始写起吧
目标
我们的目标站点是 豆瓣电影 Top250,估计大家都很眼熟了
本次爬取8个字段,用于简单的概括分析。具体的字段如下:
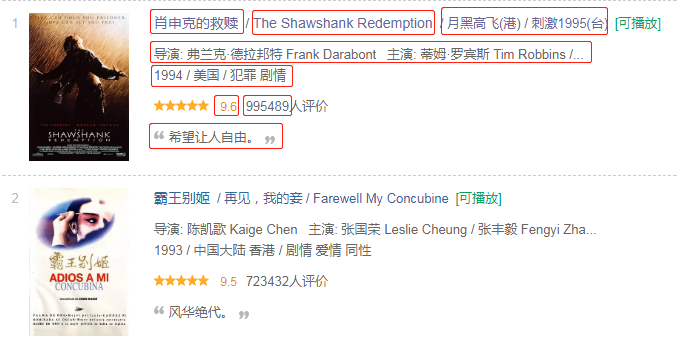
简单的分析一下目标源
- 一页共25条
- 含分页(共10页)且分页规则是正常的
- 每一项的数据字段排序都是规则且不变
开始
由于量不大,我们的爬取步骤如下
- 分析页面,获取所有的分页
- 分析页面,循环爬取所有页面的电影信息
- 爬取的电影信息入库
安装
$ go get -u github.com/PuerkitoBio/goquery
运行
$ go run main.go
代码片段
1、获取所有分页
func ParsePages(doc *goquery.Document) (pages []Page) {
pages = append(pages, Page{Page: 1, Url: ""})
doc.Find("#content > div > div.article > div.paginator > a").Each(func(i int, s *goquery.Selection) {
page, _ := strconv.Atoi(s.Text())
url, _ := s.Attr("href")
pages = append(pages, Page{
Page: page,
Url: url,
})
})
return pages
}
2、分析豆瓣电影信息
func ParseMovies(doc *goquery.Document) (movies []Movie) {
doc.Find("#content > div > div.article > ol > li").Each(func(i int, s *goquery.Selection) {
title := s.Find(".hd a span").Eq(0).Text()
...
movieDesc := strings.Split(DescInfo[1], "/")
year := strings.TrimSpace(movieDesc[0])
area := strings.TrimSpace(movieDesc[1])
tag := strings.TrimSpace(movieDesc[2])
star := s.Find(".bd .star .rating_num").Text()
comment := strings.TrimSpace(s.Find(".bd .star span").Eq(3).Text())
compile := regexp.MustCompile("[0-9]")
comment = strings.Join(compile.FindAllString(comment, -1), "")
quote := s.Find(".quote .inq").Text()
...
log.Printf("i: %d, movie: %v", i, movie)
movies = append(movies, movie)
})
return movies
}
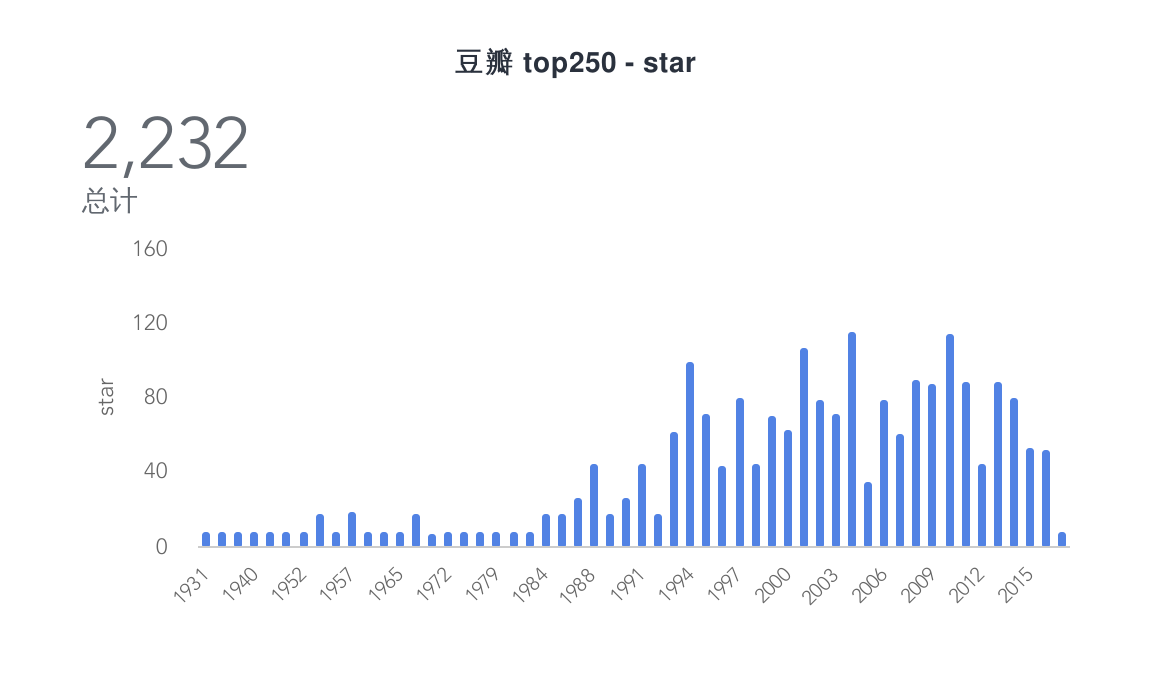
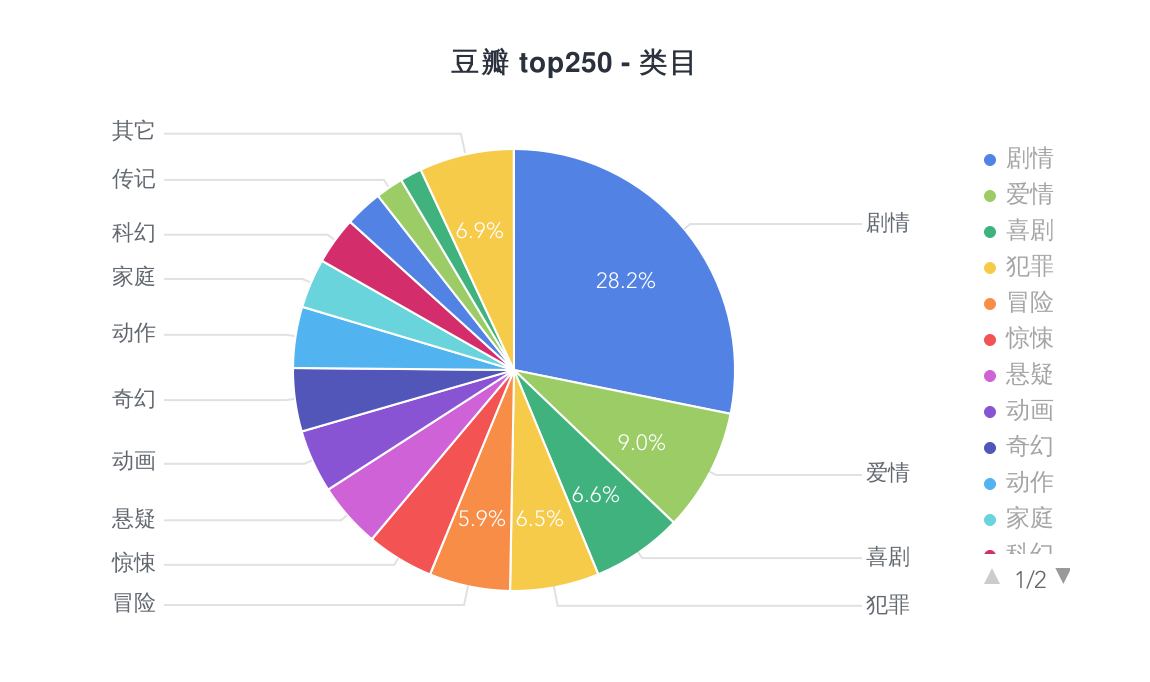
数据

Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].