dantleech / Fink
Licence: mit
PHP Link Checker
Stars: ✭ 157
Labels
Projects that are alternatives of or similar to Fink
Digger
Digger is a powerful and flexible web crawler implemented by pure golang
Stars: ✭ 130 (-17.2%)
Mutual labels: spider
Bilibili User Information Spider
B站3亿用户信息爬虫(mid号,昵称,性别,关注,粉丝,等级)
Stars: ✭ 136 (-13.38%)
Mutual labels: spider
Amazonbigspider
😱Full Automatic Amazon Distributed Spider | 亚马逊分布式四国际站采集选款产品|账号admin,密码adminadmin
Stars: ✭ 140 (-10.83%)
Mutual labels: spider
Netease Music Spider
netease-music-spider is a sipder that you can find beautiful girlfriend or handsome boyfriend.
Stars: ✭ 147 (-6.37%)
Mutual labels: spider
Python3 Spider
Python爬虫实战 - 模拟登陆各大网站 包含但不限于:滑块验证、拼多多、美团、百度、bilibili、大众点评、淘宝,如果喜欢请start ❤️
Stars: ✭ 2,129 (+1256.05%)
Mutual labels: spider
Abot
Cross Platform C# web crawler framework built for speed and flexibility. Please star this project! +1.
Stars: ✭ 1,961 (+1149.04%)
Mutual labels: spider
Fp Server
Free proxy server, continuously crawling and providing proxies, based on Tornado and Scrapy. 免费代理服务器,基于Tornado和Scrapy,在本地搭建属于自己的代理池
Stars: ✭ 154 (-1.91%)
Mutual labels: spider
Awesome Web Scraper
A collection of awesome web scaper, crawler.
Stars: ✭ 147 (-6.37%)
Mutual labels: spider
Fink

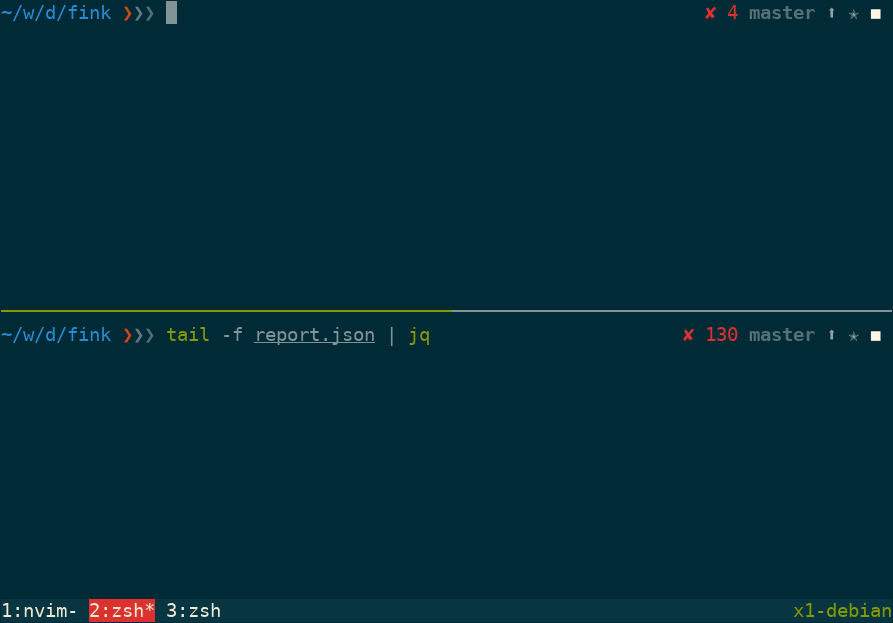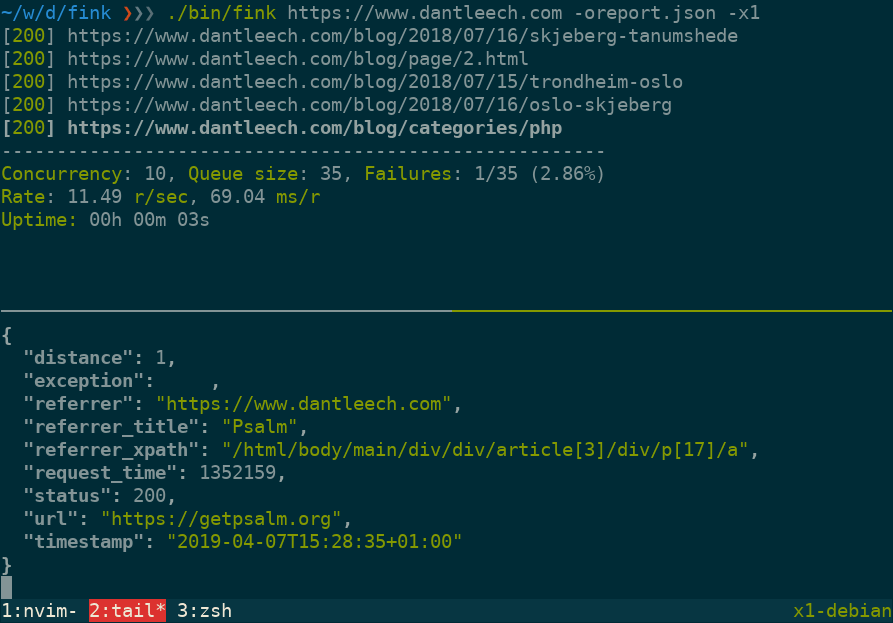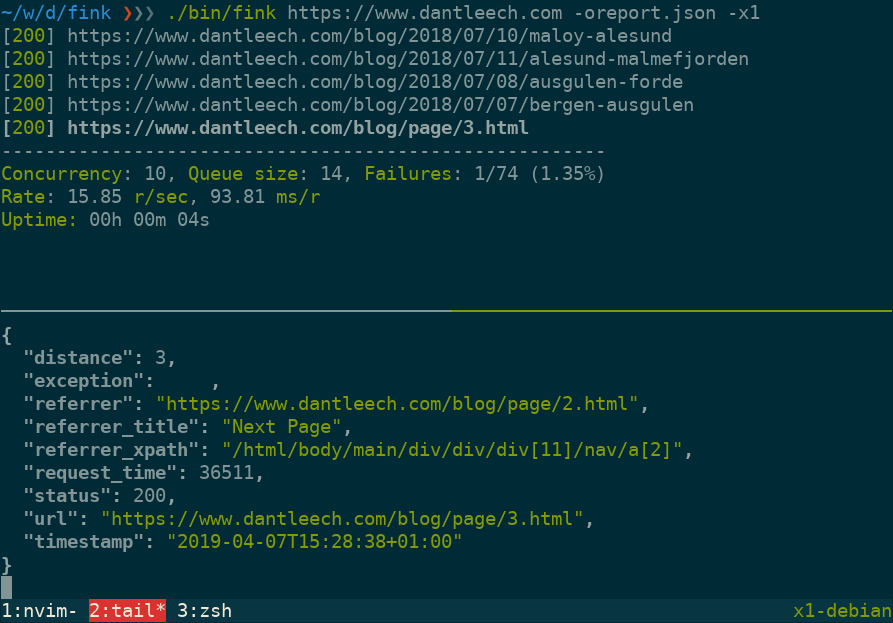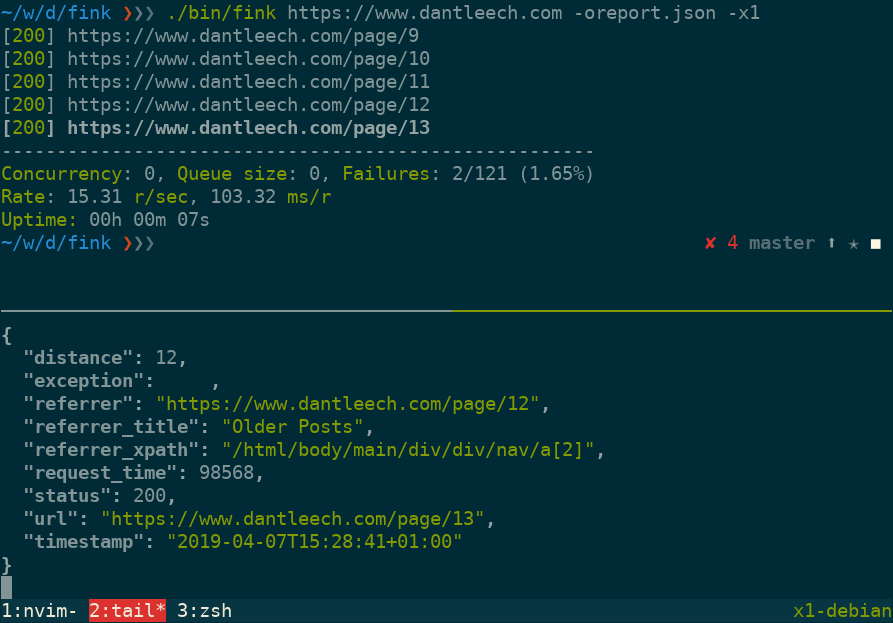
Fink (pronounced "Phpink") is a command line tool, written in PHP, for checking HTTP links.
- Check websites for broken links or error pages.
- Asynchronous HTTP requests.
Installation
Install as a stand-alone tool or as a project dependency:
Installing as a project dependency
$ composer require dantleech/fink --dev
Installing from a PHAR
Download the PHAR from the Releases page.
Building your own PHAR with Box
You can build your own PHAR by cloning this repository and running:
$ ./vendor/bin/box compile
Usage
Run the command with a single URL to start crawling:
$ ./vendor/bin/fink https://www.example.com
Use --output=somefile to log verbose information for each URL in JSON format, including:
-
url: The tested URL. -
status: The HTTP status code. -
referrer: The page which linked to the URL. -
referrer_title: The value (e.g. link title) of the referring element. -
referrer_xpath: The path to the node in the referring document. -
distance: The number of links away from the start document. -
request_time: Number of microseconds taken to make the request. -
timestamp: The time that the request was made. -
exception: Any runtime exception encountered (e.g. malformed URL, etc).
Arguments
-
url(multiple) Specify one or more base URLs to crawl (mandatory).
Options
-
--client-max-body-size: 'Max body size for HTTP client (in bytes). -
--client-max-header-size: 'Max header size for HTTP client (in bytes). -
--client-redirects=5: Set the maximum number of times the client should redirect (0to never redirect). -
--client-security-level=1: Set the default SSL security level -
--client-timeout=15000: Set the maximum amount of time (in milliseconds) the client should wait for a response, defaults to 15,000 (15 seconds). -
--concurrency: Number of simultaneous HTTP requests to use. -
--display-bufsize=10: Set the number of URLs to consider when showing the display. -
--display=+memory: Set, add or remove elements of the runtime display (prefix with-or+to modify the default set). -
--exclude-url=logout: (multiple) Exclude URLs matching the given PCRE pattern. -
--header="Foo: Bar": (multiple) Specify custom header(s). -
--help: Display available options. -
--include-link=foobar.html: Include given link as if it were linked from the base URL. -
--insecure: Do not verify SSL certificates. -
--load-cookies: Load from a cookies.txt. -
--max-distance: Maximum allowed distance from base URL (if not specified then there is no limitation). -
--max-external-distance: Limit the external (disjoint) distance from the base URL. -
--no-dedupe: Do not filter duplicate URLs (can result in a non-terminating process). -
--output=out.json: Output JSON report for each URL to given file (truncates existing content). -
--publisher=csv: Set the publisher (defaults tojson) can be eitherjsonorcsv. -
--rate: Set a maximum number of requests to make in a second. -
--stdout: Stream to STDOUT directly, disables display and any specified outfile.
Examples
Crawl a single website
$ fink http://www.example.com --max-external-distance=0
Crawl a single website and check the status of external links
$ fink http://www.example.com --max-external-distance=1
Use jq to analyse results
jq is a tool which can be used to query and manipulate JSON data.
$ fink http://www.example.com -x0 -oreport.json
$ cat report.json| jq -c '. | select(.status==404) | {url: .url, referrer: .referrer}' | jq
Crawl pages behind a login
# create a cookies file for later re-use (simulate a login in this case via HTTP-POST)
$ curl -L --cookie-jar mycookies.txt -d username=myLogin -d password=MyP4ssw0rd https://www.example.org/my/login/url
# re-use the cookies file with your fink crawl command
$ fink https://www.example.org/myaccount --load-cookies=mycookies.txt
note: its not possible to create the cookie jar on computer A, store it and read it in again on e.g. a linux server. you need to create the cookie file from the very same ip, because otherwise server side session handling might not continue the http-session because of a IP mismatch
Exit Codes
-
0: All URLs were successful. -
1: Unexpected runtime error. -
2: At least one URL failed to resolve successfully.
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].