forthespada / Interviewguide
Projects that are alternatives of or similar to Interviewguide
[TOC]
InterviewGuide
计算机校招、社招面试常见八股文整理,也是《逆袭进大厂》的唯一仓库.目前已收录 C/C++ 、操作系统、数据结构、计算机网络、MySQL、Redis等面试资料,未来打算继续收录Java、Python、Go等面试常见问题,坚持将此仓库维护下去。
📙 PDF下载地址与仓库事宜
📖PDF下载方式: 请移步本人公众号『拓跋阿秀』下回复关键字『逆袭进大厂』即可下载最新PDF版本,不断更新迭代最新版本~
🙏 本仓库脱胎于阿秀 2021 年秋招时期总结的面试笔记,我自己也是凭借这份笔记成功体验到一份 offer 收割机 的快乐,阿秀秋招总结可看秋招总结文章,现将个人笔记整理开源出来,造福每位像我这样的渣渣~
由于本人水平有限,仓库内容如有错误,欢迎提交 issue,虚心接受每一位好心人的建议与意见。
另仓库中的全部知识点均来自本人学习总结、读书笔记、经典书籍、网络博文等,阿秀已经尽自己最大能力找到当时搜集面试题时的出处并注明了。如有遗漏与侵权,请 issue 提出,感激不尽。
转载请注明出处,不得用于商业目的。
📚 目录
😧C/C++
1、在main执行之前和之后执行的代码可能是什么?
main函数执行之前,主要就是初始化系统相关资源:
- 设置栈指针
- 初始化静态
static变量和global全局变量,即.data段的内容 - 将未初始化部分的全局变量赋初值:数值型
short,int,long等为0,bool为FALSE,指针为NULL等等,即.bss段的内容 - 全局对象初始化,在
main之前调用构造函数,这是可能会执行前的一些代码 - 将main函数的参数
argc,argv等传递给main函数,然后才真正运行main函数 - attribute((constructor))
main函数执行之后:
- 全局对象的析构函数会在main函数之后执行;
- 可以用
atexit注册一个函数,它会在main 之后执行; - attribute((destructor))
2、结构体内存对齐问题?
-
结构体内成员按照声明顺序存储,第一个成员地址和整个结构体地址相同。
-
未特殊说明时,按结构体中size最大的成员对齐(若有double成员,按8字节对齐。)
3、指针和引用的区别
- 指针是一个变量,存储的是一个地址,引用跟原来的变量实质上是同一个东西,是原变量的别名
- 指针可以有多级,引用只有一级
- 指针可以为空,引用不能为NULL且在定义时必须初始化
- 指针在初始化后可以改变指向,而引用在初始化之后不可再改变
- sizeof指针得到的是本指针的大小,sizeof引用得到的是引用所指向变量的大小
- 当把指针作为参数进行传递时,也是将实参的一个拷贝传递给形参,两者指向的地址相同,但不是同一个变量,在函数中改变这个变量的指向不影响实参,而引用却可以。
- 引用本质是一个指针,同样会占4字节内存;指针是具体变量,需要占用存储空间(,具体情况还要具体分析)。
- 引用在声明时必须初始化为另一变量,一旦出现必须为typename refname &varname形式;指针声明和定义可以分开,可以先只声明指针变量而不初始化,等用到时再指向具体变量。
- 引用一旦初始化之后就不可以再改变(变量可以被引用为多次,但引用只能作为一个变量引用);指针变量可以重新指向别的变量。
- 不存在指向空值的引用,必须有具体实体;但是存在指向空值的指针。
参考代码:
void test(int *p)
{
int a=1;
p=&a;
cout<<p<<" "<<*p<<endl;
}
int main(void)
{
int *p=NULL;
test(p);
if(p==NULL)
cout<<"指针p为NULL"<<endl;
return 0;
}
//运行结果为:
//0x22ff44 1
//指针p为NULL
void testPTR(int* p) {
int a = 12;
p = &a;
}
void testREFF(int& p) {
int a = 12;
p = a;
}
void main()
{
int a = 10;
int* b = &a;
testPTR(b);//改变指针指向,但是没改变指针的所指的内容
cout << a << endl;// 10
cout << *b << endl;// 10
a = 10;
testREFF(a);
cout << a << endl;//12
}
在编译器看来, int a = 10; int &b = a; 等价于 int * const b = &a; 而 b = 20; 等价于 *b = 20; 自动转换为指针和自动解引用.
4、堆和栈的区别
-
申请方式不同。
- 栈由系统自动分配。
-
堆是自己申请和释放的。
-
申请大小限制不同。
-
栈顶和栈底是之前预设好的,栈是向栈底扩展,大小固定,可以通过ulimit -a查看,由ulimit -s修改。
-
堆向高地址扩展,是不连续的内存区域,大小可以灵活调整。
-
-
申请效率不同。
-
栈由系统分配,速度快,不会有碎片。
-
堆由程序员分配,速度慢,且会有碎片。
栈空间默认是4M, 堆区一般是 1G - 4G
-
| 堆 | 栈 | |
|---|---|---|
| 管理方式 | 堆中资源由程序员控制(容易产生memory leak) | 栈资源由编译器自动管理,无需手工控制 |
| 内存管理机制 | 系统有一个记录空闲内存地址的链表,当系统收到程序申请时,遍历该链表,寻找第一个空间大于申请空间的堆结点,删 除空闲结点链表中的该结点,并将该结点空间分配给程序(大多数系统会在这块内存空间首地址记录本次分配的大小,这样delete才能正确释放本内存空间,另外系统会将多余的部分重新放入空闲链表中) | 只要栈的剩余空间大于所申请空间,系统为程序提供内存,否则报异常提示栈溢出。(这一块理解一下链表和队列的区别,不连续空间和连续空间的区别,应该就比较好理解这两种机制的区别了) |
| 空间大小 | 堆是不连续的内存区域(因为系统是用链表来存储空闲内存地址,自然不是连续的),堆大小受限于计算机系统中有效的虚拟内存(32bit 系统理论上是4G),所以堆的空间比较灵活,比较大 | 栈是一块连续的内存区域,大小是操作系统预定好的,windows下栈大小是2M(也有是1M,在 编译时确定,VC中可设置) |
| 碎片问题 | 对于堆,频繁的new/delete会造成大量碎片,使程序效率降低 | 对于栈,它是有点类似于数据结构上的一个先进后出的栈,进出一一对应,不会产生碎片。(看到这里我突然明白了为什么面试官在问我堆和栈的区别之前先问了我栈和队列的区别) |
| 生长方向 | 堆向上,向高地址方向增长。 | 栈向下,向低地址方向增长。 |
| 分配方式 | 堆都是动态分配(没有静态分配的堆) | 栈有静态分配和动态分配,静态分配由编译器完成(如局部变量分配),动态分配由alloca函数分配,但栈的动态分配的资源由编译器进行释放,无需程序员实现。 |
| 分配效率 | 堆由C/C++函数库提供,机制很复杂。所以堆的效率比栈低很多。 | 栈是其系统提供的数据结构,计算机在底层对栈提供支持,分配专门 寄存器存放栈地址,栈操作有专门指令。 |
形象的比喻
栈就像我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
《C++中堆(heap)和栈(stack)的区别》:https://blog.csdn.net/qq_34175893/article/details/83502412
5、区别以下指针类型?
int *p[10]
int (*p)[10]
int *p(int)
int (*p)(int)
-
int *p[10]表示指针数组,强调数组概念,是一个数组变量,数组大小为10,数组内每个元素都是指向int类型的指针变量。
-
int (*p)[10]表示数组指针,强调是指针,只有一个变量,是指针类型,不过指向的是一个int类型的数组,这个数组大小是10。
-
int *p(int)是函数声明,函数名是p,参数是int类型的,返回值是int *类型的。
-
int (*p)(int)是函数指针,强调是指针,该指针指向的函数具有int类型参数,并且返回值是int类型的。
6、基类的虚函数表存放在内存的什么区,虚表指针vptr的初始化时间
首先整理一下虚函数表的特征:
-
虚函数表是全局共享的元素,即全局仅有一个,在编译时就构造完成
-
虚函数表类似一个数组,类对象中存储vptr指针,指向虚函数表,即虚函数表不是函数,不是程序代码,不可能存储在代码段
-
虚函数表存储虚函数的地址,即虚函数表的元素是指向类成员函数的指针,而类中虚函数的个数在编译时期可以确定,即虚函数表的大小可以确定,即大小是在编译时期确定的,不必动态分配内存空间存储虚函数表,所以不在堆中
根据以上特征,虚函数表类似于类中静态成员变量.静态成员变量也是全局共享,大小确定,因此最有可能存在全局数据区,测试结果显示:
虚函数表vtable在Linux/Unix中存放在可执行文件的只读数据段中(rodata),这与微软的编译器将虚函数表存放在常量段存在一些差别
由于虚表指针vptr跟虚函数密不可分,对于有虚函数或者继承于拥有虚函数的基类,对该类进行实例化时,在构造函数执行时会对虚表指针进行初始化,并且存在对象内存布局的最前面。
《虚函数表存放在哪里》:https://blog.csdn.net/u013270326/article/details/82830656
一般分为五个区域:栈区、堆区、函数区(存放函数体等二进制代码)、全局静态区、常量区
C++中虚函数表位于只读数据段(.rodata),也就是C++内存模型中的常量区;而虚函数则位于代码段(.text),也就是C++内存模型中的代码区。
7、new / delete 与 malloc / free的异同
相同点
- 都可用于内存的动态申请和释放
不同点
- 前者是C++运算符,后者是C/C++语言标准库函数
- new自动计算要分配的空间大小,malloc需要手工计算
- new是类型安全的,malloc不是。例如:
int *p = new float[2]; //编译错误
int *p = (int*)malloc(2 * sizeof(double));//编译无错误
- new调用名为operator new的标准库函数分配足够空间并调用相关对象的构造函数,delete对指针所指对象运行适当的析构函数;然后通过调用名为operator delete的标准库函数释放该对象所用内存。后者均没有相关调用
- 后者需要库文件支持,前者不用
- new是封装了malloc,直接free不会报错,但是这只是释放内存,而不会析构对象
8、new和delete是如何实现的?
- new的实现过程是:首先调用名为operator new的标准库函数,分配足够大的原始为类型化的内存,以保存指定类型的一个对象;接下来运行该类型的一个构造函数,用指定初始化构造对象;最后返回指向新分配并构造后的的对象的指针
- delete的实现过程:对指针指向的对象运行适当的析构函数;然后通过调用名为operator delete的标准库函数释放该对象所用内存
9、malloc和new的区别?
-
malloc和free是标准库函数,支持覆盖;new和delete是运算符,并且支持重载。
-
malloc仅仅分配内存空间,free仅仅回收空间,不具备调用构造函数和析构函数功能,用malloc分配空间存储类的对象存在风险;new和delete除了分配回收功能外,还会调用构造函数和析构函数。
-
malloc和free返回的是void类型指针(必须进行类型转换),new和delete返回的是具体类型指针。
9.1、delete和delete[]区别?(补充)
- delete只会调用一次析构函数。
- delete[]会调用数组中每个元素的析构函数。
10、宏定义和函数有何区别?
-
宏在编译时完成替换,之后被替换的文本参与编译,相当于直接插入了代码,运行时不存在函数调用,执行起来更快;函数调用在运行时需要跳转到具体调用函数。
-
宏定义属于在结构中插入代码,没有返回值;函数调用具有返回值。
-
宏定义参数没有类型,不进行类型检查;函数参数具有类型,需要检查类型。
-
宏定义不要在最后加分号。
11、宏定义和typedef区别?
-
宏主要用于定义常量及书写复杂的内容;typedef主要用于定义类型别名。
-
宏替换发生在编译阶段之前,属于文本插入替换;typedef是编译的一部分。
-
宏不检查类型;typedef会检查数据类型。
-
宏不是语句,不在在最后加分号;typedef是语句,要加分号标识结束。
-
注意对指针的操作,typedef char * p_char和#define p_char char *区别巨大。
12、变量声明和定义区别?
-
声明仅仅是把变量的声明的位置及类型提供给编译器,并不分配内存空间;定义要在定义的地方为其分配存储空间。
-
相同变量可以在多处声明(外部变量extern),但只能在一处定义。
13、哪几种情况必须用到初始化成员列表?
-
初始化一个const成员。
-
初始化一个reference成员。
-
调用一个基类的构造函数,而该函数有一组参数。
-
调用一个数据成员对象的构造函数,而该函数有一组参数。
14、strlen和sizeof区别?
-
sizeof是运算符,并不是函数,结果在编译时得到而非运行中获得;strlen是字符处理的库函数。
-
sizeof参数可以是任何数据的类型或者数据(sizeof参数不退化);strlen的参数只能是字符指针且结尾是'\0'的字符串。
-
因为sizeof值在编译时确定,所以不能用来得到动态分配(运行时分配)存储空间的大小。
int main(int argc, char const *argv[]){
const char* str = "name";
sizeof(str); // 取的是指针str的长度,是8
strlen(str); // 取的是这个字符串的长度,不包含结尾的 \0。大小是4
return 0;
}
15、常量指针和指针常量区别?
-
常量指针是一个指针,读成常量的指针,指向一个只读变量。如int const *p或const int *p。
-
指针常量是一个不能给改变指向的指针。指针是个常亮,不能中途改变指向,如int *const p。
16、a和&a有什么区别?
假设数组int a[10];
int (*p)[10] = &a;
- a是数组名,是数组首元素地址,+1表示地址值加上一个int类型的大小,如果a的值是0x00000001,加1操作后变为0x00000005。*(a + 1) = a[1]。
- &a是数组的指针,其类型为int (*)[10](就是前面提到的数组指针),其加1时,系统会认为是数组首地址加上整个数组的偏移(10个int型变量),值为数组a尾元素后一个元素的地址。
- 若(int *)p ,此时输出 *p时,其值为a[0]的值,因为被转为int *类型,解引用时按照int类型大小来读取。
17、数组名和指针(这里为指向数组首元素的指针)区别?
-
二者均可通过增减偏移量来访问数组中的元素。
-
数组名不是真正意义上的指针,可以理解为常指针,所以数组名没有自增、自减等操作。
-
当数组名当做形参传递给调用函数后,就失去了原有特性,退化成一般指针,多了自增、自减操作,但sizeof运算符不能再得到原数组的大小了。
18、野指针和悬空指针
都是是指向无效内存区域(这里的无效指的是"不安全不可控")的指针,访问行为将会导致未定义行为。
-
野指针
野指针,指的是没有被初始化过的指针int main(void) { int* p; // 未初始化 std::cout<< *p << std::endl; // 未初始化就被使用 return 0; }
因此,为了防止出错,对于指针初始化时都是赋值为
nullptr,这样在使用时编译器就会直接报错,产生非法内存访问。 -
悬空指针
悬空指针,指针最初指向的内存已经被释放了的一种指针。int main(void) { int * p = nullptr; int* p2 = new int; p = p2; delete p2; }
此时 p和p2就是悬空指针,指向的内存已经被释放。继续使用这两个指针,行为不可预料。需要设置为
p=p2=nullptr。此时再使用,编译器会直接保错。避免野指针比较简单,但悬空指针比较麻烦。c++引入了智能指针,C++智能指针的本质就是避免悬空指针的产生。
产生原因及解决办法:
野指针:指针变量未及时初始化 => 定义指针变量及时初始化,要么置空。
悬空指针:指针free或delete之后没有及时置空 => 释放操作后立即置空。
19、迭代器失效的情况
以vector为例:
插入元素:
1、尾后插入:size < capacity时,首迭代器不失效尾迭代失效(未重新分配空间),size == capacity时,所有迭代器均失效(需要重新分配空间)。
2、中间插入:中间插入:size < capacity时,首迭代器不失效但插入元素之后所有迭代器失效,size == capacity时,所有迭代器均失效。
删除元素:
尾后删除:只有尾迭代失效。
中间删除:删除位置之后所有迭代失效。
deque 和 vector 的情况类似,
而list双向链表每一个节点内存不连续, 删除节点仅当前迭代器失效,erase返回下一个有效迭代器;
map/set等关联容器底层是红黑树删除节点不会影响其他节点的迭代器, 使用递增方法获取下一个迭代器 mmp.erase(iter++);
unordered_(hash) 迭代器意义不大, rehash之后, 迭代器应该也是全部失效.
20、C和C++的区别
- C++中new和delete是对内存分配的运算符,取代了C中的malloc和free。
- 标准C++中的字符串类取代了标准C函数库头文件中的字符数组处理函数(C中没有字符串类型)。
- C++中用来做控制态输入输出的iostream类库替代了标准C中的stdio函数库。
- C++中的try/catch/throw异常处理机制取代了标准C中的setjmp()和longjmp()函数。
- 在C++中,允许有相同的函数名,不过它们的参数类型不能完全相同,这样这些函数就可以相互区别开来。而这在C语言中是不允许的。也就是C++可以重载,C语言不允许。
- C++语言中,允许变量定义语句在程序中的任何地方,只要在是使用它之前就可以;而C语言中,必须要在函数开头部分。而且C++允许重复定义变量,C语言也是做不到这一点的
- 在C++中,除了值和指针之外,新增了引用。引用型变量是其他变量的一个别名,我们可以认为他们只是名字不相同,其他都是相同的。
- C++相对与C增加了一些关键字,如:bool、using、dynamic_cast、namespace等等
《C语言与C++有什么区别?》https://www.cnblogs.com/ITziyuan/p/9487760.html
21、C++与Java的区别
语言特性
-
Java语言给开发人员提供了更为简洁的语法;完全面向对象,由于JVM可以安装到任何的操作系统上,所以说它的可移植性强
-
Java语言中没有指针的概念,引入了真正的数组。不同于C++中利用指针实现的“伪数组”,Java引入了真正的数组,同时将容易造成麻烦的指针从语言中去掉,这将有利于防止在C++程序中常见的因为数组操作越界等指针操作而对系统数据进行非法读写带来的不安全问题
-
C++也可以在其他系统运行,但是需要不同的编码(这一点不如Java,只编写一次代码,到处运行),例如对一个数字,在windows下是大端存储,在unix中则为小端存储。Java程序一般都是生成字节码,在JVM里面运行得到结果
-
Java用接口(Interface)技术取代C++程序中的多继承性。接口与多继承有同样的功能,但是省却了多继承在实现和维护上的复杂性
垃圾回收
- C++用析构函数回收垃圾,写C和C++程序时一定要注意内存的申请和释放
- Java语言不使用指针,内存的分配和回收都是自动进行的,程序员无须考虑内存碎片的问题
应用场景
- Java在桌面程序上不如C++实用,C++可以直接编译成exe文件,指针是c++的优势,可以直接对内存的操作,但同时具有危险性 。(操作内存的确是一项非常危险的事情,一旦指针指向的位置发生错误,或者误删除了内存中某个地址单元存放的重要数据,后果是可想而知的)
- Java在Web 应用上具有C++ 无可比拟的优势,具有丰富多样的框架
- 对于底层程序的编程以及控制方面的编程,C++很灵活,因为有句柄的存在
《C++和java的区别和联系》:https://www.cnblogs.com/tanrong/p/8503202.html
22、C++中struct和class的区别
相同点
- 两者都拥有成员函数、公有和私有部分
- 任何可以使用class完成的工作,同样可以使用struct完成
不同点
-
两者中如果不对成员不指定公私有,struct默认是公有的,class则默认是私有的
-
class默认是private继承,而struct模式是public继承
引申:C++和C的struct区别
-
C语言中:struct是用户自定义数据类型(UDT);C++中struct是抽象数据类型(ADT),支持成员函数的定义,(C++中的struct能继承,能实现多态)
-
C中struct是没有权限的设置的,且struct中只能是一些变量的集合体,可以封装数据却不可以隐藏数据,而且成员不可以是函数
-
C++中,struct增加了访问权限,且可以和类一样有成员函数,成员默认访问说明符为public(为了与C兼容)
-
struct作为类的一种特例是用来自定义数据结构的。一个结构标记声明后,在C中必须在结构标记前加上struct,才能做结构类型名(除:typedef struct class{};);C++中结构体标记(结构体名)可以直接作为结构体类型名使用,此外结构体struct在C++中被当作类的一种特例
《struct结构在C和C++中的区别》:https://blog.csdn.net/mm_hh/article/details/70456240
23、define宏定义和const的区别
编译阶段
- define是在编译的预处理阶段起作用,而const是在编译、运行的时候起作用
安全性
- define只做替换,不做类型检查和计算,也不求解,容易产生错误,一般最好加上一个大括号包含住全部的内容,要不然很容易出错
- const常量有数据类型,编译器可以对其进行类型安全检查
内存占用
-
define只是将宏名称进行替换,在内存中会产生多分相同的备份。const在程序运行中只有一份备份,且可以执行常量折叠,能将复杂的的表达式计算出结果放入常量表
-
宏替换发生在编译阶段之前,属于文本插入替换;const作用发生于编译过程中。
-
宏不检查类型;const会检查数据类型。
-
宏定义的数据没有分配内存空间,只是插入替换掉;const定义的变量只是值不能改变,但要分配内存空间。
24、C++中const和static的作用
static
- 不考虑类的情况
- 隐藏。所有不加static的全局变量和函数具有全局可见性,可以在其他文件中使用,加了之后只能在该文件所在的编译模块中使用
- 默认初始化为0,包括未初始化的全局静态变量与局部静态变量,都存在全局未初始化区
- 静态变量在函数内定义,始终存在,且只进行一次初始化,具有记忆性,其作用范围与局部变量相同,函数退出后仍然存在,但不能使用
- 考虑类的情况
- static成员变量:只与类关联,不与类的对象关联。定义时要分配空间,不能在类声明中初始化,必须在类定义体外部初始化,初始化时不需要标示为static;可以被非static成员函数任意访问。
- static成员函数:不具有this指针,无法访问类对象的非static成员变量和非static成员函数;不能被声明为const、虚函数和volatile;可以被非static成员函数任意访问
const
-
不考虑类的情况
-
const常量在定义时必须初始化,之后无法更改
-
const形参可以接收const和非const类型的实参,例如
// i 可以是 int 型或者 const int 型 void fun(const int& i){ //... }
-
-
考虑类的情况
- const成员变量:不能在类定义外部初始化,只能通过构造函数初始化列表进行初始化,并且必须有构造函数;不同类对其const数据成员的值可以不同,所以不能在类中声明时初始化
- const成员函数:const对象不可以调用非const成员函数;非const对象都可以调用;不可以改变非mutable(用该关键字声明的变量可以在const成员函数中被修改)数据的值
25、C++的顶层const和底层const
概念区分
- 顶层const:指的是const修饰的变量本身是一个常量,无法修改,指的是指针,就是 * 号的右边
- 底层const:指的是const修饰的变量所指向的对象是一个常量,指的是所指变量,就是 * 号的左边
举个例子
int a = 10;
int* const b1 = &a; //顶层const,b1本身是一个常量
const int* b2 = &a; //底层const,b2本身可变,所指的对象是常量
const int b3 = 20; //顶层const,b3是常量不可变
const int* const b4 = &a; //前一个const为底层,后一个为顶层,b4不可变
const int& b5 = a; //用于声明引用变量,都是底层const
区分作用
- 执行对象拷贝时有限制,常量的底层const不能赋值给非常量的底层const
- 使用命名的强制类型转换函数const_cast时,只能改变运算对象的底层const
《C++ 顶层const与底层const总结》:https://www.jianshu.com/p/fbbcf11100f6
《C++的顶层const和底层const浅析》:https://blog.csdn.net/qq_37059483/article/details/78811231
const int a;
int const a;
const int *a;
int *const a;
-
int const a和const int a均表示定义常量类型a。
-
const int *a,其中a为指向int型变量的指针,const在 * 左侧,表示a指向不可变常量。(看成const (*a),对引用加const)
-
int *const a,依旧是指针类型,表示a为指向整型数据的常指针。(看成const(a),对指针const)
26、类的对象存储空间?
-
非静态成员的数据类型大小之和。
-
编译器加入的额外成员变量(如指向虚函数表的指针)。
-
为了边缘对齐优化加入的padding。
空类(无非静态数据成员)的对象的size为1, 当作为基类时, size为0.
27、final和override关键字
override
当在父类中使用了虚函数时候,你可能需要在某个子类中对这个虚函数进行重写,以下方法都可以:
class A
{
virtual void foo();
}
class B : public A
{
void foo(); //OK
virtual void foo(); // OK
void foo() override; //OK
}
如果不使用override,当你手一抖,将**foo()写成了f00()**会怎么样呢?结果是编译器并不会报错,因为它并不知道你的目的是重写虚函数,而是把它当成了新的函数。如果这个虚函数很重要的话,那就会对整个程序不利。所以,override的作用就出来了,它指定了子类的这个虚函数是重写的父类的,如果你名字不小心打错了的话,编译器是不会编译通过的:
class A
{
virtual void foo();
};
class B : public A
{
virtual void f00(); //OK,这个函数是B新增的,不是继承的
virtual void f0o() override; //Error, 加了override之后,这个函数一定是继承自A的,A找不到就报错
};
final
当不希望某个类被继承,或不希望某个虚函数被重写,可以在类名和虚函数后添加final关键字,添加final关键字后被继承或重写,编译器会报错。例子如下:
class Base
{
virtual void foo();
};
class A : public Base
{
void foo() final; // foo 被override并且是最后一个override,在其子类中不可以重写
};
class B final : A // 指明B是不可以被继承的
{
void foo() override; // Error: 在A中已经被final了
};
class C : B // Error: B is final
{
};
《C++:override和final》:https://www.cnblogs.com/whlook/p/6501918.html
28、拷贝初始化和直接初始化
- 当用于类类型对象时,初始化的拷贝形式和直接形式有所不同:直接初始化直接调用与实参匹配的构造函数,拷贝初始化总是调用拷贝构造函数。拷贝初始化首先使用指定构造函数创建一个临时对象,然后用拷贝构造函数将那个临时对象拷贝到正在创建的对象。举例如下
string str1("I am a string");//语句1 直接初始化
string str2(str1);//语句2 直接初始化,str1是已经存在的对象,直接调用构造函数对str2进行初始化
string str3 = "I am a string";//语句3 拷贝初始化,先为字符串”I am a string“创建临时对象,再把临时对象作为参数,使用拷贝构造函数构造str3
string str4 = str1;//语句4 拷贝初始化,这里相当于隐式调用拷贝构造函数,而不是调用赋值运算符函数
-
为了提高效率,允许编译器跳过创建临时对象这一步,直接调用构造函数构造要创建的对象,这样就完全等价于直接初始化了(语句1和语句3等价)。但是需要辨别两种情况。
- 当拷贝构造函数为private时:语句3和语句4在编译时会报错
- 使用explicit修饰构造函数时:如果构造函数存在隐式转换,编译时会报错
C++的直接初始化与复制初始化的区别:https://blog.csdn.net/qq936836/article/details/83450218
29、初始化和赋值的区别
- 对于简单类型来说,初始化和赋值没什么区别
- 对于类和复杂数据类型来说,这两者的区别就大了,举例如下:
class A{
public:
int num1;
int num2;
public:
A(int a=0, int b=0):num1(a),num2(b){};
A(const A& a){};
//重载 = 号操作符函数
A& operator=(const A& a){
num1 = a.num1 + 1;
num2 = a.num2 + 1;
return *this;
};
};
int main(){
A a(1,1);
A a1 = a; //拷贝初始化操作,调用拷贝构造函数
A b;
b = a;//赋值操作,对象a中,num1 = 1,num2 = 1;对象b中,num1 = 2,num2 = 2
return 0;
}
30、extern"C"的用法
为了能够正确的在C++代码中调用C语言的代码:在程序中加上extern "C"后,相当于告诉编译器这部分代码是C语言写的,因此要按照C语言进行编译,而不是C++;
哪些情况下使用extern "C":
(1)C++代码中调用C语言代码;
(2)在C++中的头文件中使用;
(3)在多个人协同开发时,可能有人擅长C语言,而有人擅长C++;
举个例子,C++中调用C代码:
#ifndef __MY_HANDLE_H__
#define __MY_HANDLE_H__
extern "C"{
typedef unsigned int result_t;
typedef void* my_handle_t;
my_handle_t create_handle(const char* name);
result_t operate_on_handle(my_handle_t handle);
void close_handle(my_handle_t handle);
}
- 参考的blog中有一篇google code上的文章,专门写extern "C"的,有兴趣的读者不妨去看看
《extern "C"的功能和用法研究》:https://blog.csdn.net/sss_369/article/details/84060561
综上,总结出使用方法**,在C语言的头文件中,对其外部函数只能指定为extern类型,C语言中不支持extern "C"声明,在.c文件中包含了extern "C"时会出现编译语法错误。**所以使用extern "C"全部都放在于cpp程序相关文件或其头文件中。
总结出如下形式:
(1)C++调用C函数:
//xx.h
extern int add(...)
//xx.c
int add(){
}
//xx.cpp
extern "C" {
#include "xx.h"
}
(2)C调用C++函数
//xx.h
extern "C"{
int add();
}
//xx.cpp
int add(){
}
//xx.c
extern int add();
31、模板函数和模板类的特例化
引入原因
编写单一的模板,它能适应多种类型的需求,使每种类型都具有相同的功能,但对于某种特定类型,如果要实现其特有的功能,单一模板就无法做到,这时就需要模板特例化
定义
对单一模板提供的一个特殊实例,它将一个或多个模板参数绑定到特定的类型或值上
(1)模板函数特例化
必须为原函数模板的每个模板参数都提供实参,且使用关键字template后跟一个空尖括号对<>,表明将原模板的所有模板参数提供实参,举例如下:
template<typename T> //模板函数
int compare(const T &v1,const T &v2)
{
if(v1 > v2) return -1;
if(v2 > v1) return 1;
return 0;
}
//模板特例化,满足针对字符串特定的比较,要提供所有实参,这里只有一个T
template<>
int compare(const char* const &v1,const char* const &v2)
{
return strcmp(p1,p2);
}
本质
特例化的本质是实例化一个模板,而非重载它。特例化不影响参数匹配。参数匹配都以最佳匹配为原则。例如,此处如果是compare(3,5),则调用普通的模板,若为compare(“hi”,”haha”)则调用特例化版本(因为这个cosnt char*相对于T,更匹配实参类型),注意二者函数体的语句不一样了,实现不同功能。
注意
模板及其特例化版本应该声明在同一个头文件中,且所有同名模板的声明应该放在前面,后面放特例化版本。
(2)类模板特例化
原理类似函数模板,**不过在类中,我们可以对模板进行特例化,也可以对类进行部分特例化。**对类进行特例化时,仍然用template<>表示是一个特例化版本,例如:
template<>
class hash<sales_data>
{
size_t operator()(sales_data& s);
//里面所有T都换成特例化类型版本sales_data
//按照最佳匹配原则,若T != sales_data,就用普通类模板,否则,就使用含有特定功能的特例化版本。
};
类模板的部分特例化
不必为所有模板参数提供实参,可以指定一部分而非所有模板参数,一个类模板的部分特例化本身仍是一个模板,使用它时还必须为其特例化版本中未指定的模板参数提供实参(特例化时类名一定要和原来的模板相同,只是参数类型不同,按最佳匹配原则,哪个最匹配,就用相应的模板)
特例化类中的部分成员
可以特例化类中的部分成员函数而不是整个类,举个例子:
template<typename T>
class Foo
{
void Bar();
void Barst(T a)();
};
template<>
void Foo<int>::Bar()
{
//进行int类型的特例化处理
cout << "我是int型特例化" << endl;
}
Foo<string> fs;
Foo<int> fi;//使用特例化
fs.Bar();//使用的是普通模板,即Foo<string>::Bar()
fi.Bar();//特例化版本,执行Foo<int>::Bar()
//Foo<string>::Bar()和Foo<int>::Bar()功能不同
《类和函数模板特例化》:https://blog.csdn.net/wang664626482/article/details/52372789
32、C和C++的类型安全
什么是类型安全?
类型安全很大程度上可以等价于内存安全,类型安全的代码不会试图访问自己没被授权的内存区域。“类型安全”常被用来形容编程语言,其根据在于该门编程语言是否提供保障类型安全的机制;有的时候也用“类型安全”形容某个程序,判别的标准在于该程序是否隐含类型错误。类型安全的编程语言与类型安全的程序之间,没有必然联系。好的程序员可以使用类型不那么安全的语言写出类型相当安全的程序,相反的,差一点儿的程序员可能使用类型相当安全的语言写出类型不太安全的程序。绝对类型安全的编程语言暂时还没有。
(1)C的类型安全
C只在局部上下文中表现出类型安全,比如试图从一种结构体的指针转换成另一种结构体的指针时,编译器将会报告错误,除非使用显式类型转换。然而,C中相当多的操作是不安全的。以下是两个十分常见的例子:
- printf格式输出

上述代码中,使用%d控制整型数字的输出,没有问题,但是改成%f时,明显输出错误,再改成%s时,运行直接报segmentation fault错误
- malloc函数的返回值
malloc是C中进行内存分配的函数,它的返回类型是void*即空类型指针,常常有这样的用法char* pStr=(char*)malloc(100*sizeof(char)),这里明显做了显式的类型转换。类型匹配尚且没有问题,但是一旦出现int* pInt=(int*)malloc(100*sizeof(char))就很可能带来一些问题,而这样的转换C并不会提示错误。
(2)C++的类型安全
如果C++使用得当,它将远比C更有类型安全性。相比于C语言,C++提供了一些新的机制保障类型安全:
-
操作符new返回的指针类型严格与对象匹配,而不是void*
-
C中很多以void*为参数的函数可以改写为C++模板函数,而模板是支持类型检查的;
-
引入const关键字代替#define constants,它是有类型、有作用域的,而#define constants只是简单的文本替换
-
一些#define宏可被改写为inline函数,结合函数的重载,可在类型安全的前提下支持多种类型,当然改写为模板也能保证类型安全
-
C++提供了dynamic_cast关键字,使得转换过程更加安全,因为dynamic_cast比static_cast涉及更多具体的类型检查。
例1:使用void*进行类型转换

例2:不同类型指针之间转换
#include<iostream>
using namespace std;
class Parent{};
class Child1 : public Parent
{
public:
int i;
Child1(int e):i(e){}
};
class Child2 : public Parent
{
public:
double d;
Child2(double e):d(e){}
};
int main()
{
Child1 c1(5);
Child2 c2(4.1);
Parent* pp;
Child1* pc1;
pp=&c1;
pc1=(Child1*)pp; // 类型向下转换 强制转换,由于类型仍然为Child1*,不造成错误
cout<<pc1->i<<endl; //输出:5
pp=&c2;
pc1=(Child1*)pp; //强制转换,且类型发生变化,将造成错误
cout<<pc1->i<<endl;// 输出:1717986918
return 0;
}
上面两个例子之所以引起类型不安全的问题,是因为程序员使用不得当。第一个例子用到了空类型指针void*,第二个例子则是在两个类型指针之间进行强制转换。因此,想保证程序的类型安全性,应尽量避免使用空类型指针void*,尽量不对两种类型指针做强制转换。
33、为什么析构函数一般写成虚函数
由于类的多态性,基类指针可以指向派生类的对象,如果删除该基类的指针,就会调用该指针指向的派生类析构函数,而派生类的析构函数又自动调用基类的析构函数,这样整个派生类的对象完全被释放。如果析构函数不被声明成虚函数,则编译器实施静态绑定,在删除基类指针时,只会调用基类的析构函数而不调用派生类析构函数,这样就会造成派生类对象析构不完全,造成内存泄漏。所以将析构函数声明为虚函数是十分必要的。在实现多态时,当用基类操作派生类,在析构时防止只析构基类而不析构派生类的状况发生,要将基类的析构函数声明为虚函数。举个例子:
#include <iostream>
using namespace std;
class Parent{
public:
Parent(){
cout << "Parent construct function" << endl;
};
~Parent(){
cout << "Parent destructor function" <<endl;
}
};
class Son : public Parent{
public:
Son(){
cout << "Son construct function" << endl;
};
~Son(){
cout << "Son destructor function" <<endl;
}
};
int main()
{
Parent* p = new Son();
delete p;
p = NULL;
return 0;
}
//运行结果:
//Parent construct function
//Son construct function
//Parent destructor function
将基类的析构函数声明为虚函数:
#include <iostream>
using namespace std;
class Parent{
public:
Parent(){
cout << "Parent construct function" << endl;
};
virtual ~Parent(){
cout << "Parent destructor function" <<endl;
}
};
class Son : public Parent{
public:
Son(){
cout << "Son construct function" << endl;
};
~Son(){
cout << "Son destructor function" <<endl;
}
};
int main()
{
Parent* p = new Son();
delete p;
p = NULL;
return 0;
}
//运行结果:
//Parent construct function
//Son construct function
//Son destructor function
//Parent destructor function
34、构造函数能否声明为虚函数或者纯虚函数,析构函数呢?
析构函数:
- 析构函数可以为虚函数,并且一般情况下基类析构函数要定义为虚函数。
- 只有在基类析构函数定义为虚函数时,调用操作符delete销毁指向对象的基类指针时,才能准确调用派生类的析构函数(从该级向上按序调用虚函数),才能准确销毁数据。
- 析构函数可以是纯虚函数,含有纯虚函数的类是抽象类,此时不能被实例化。但派生类中可以根据自身需求重新改写基类中的纯虚函数。
构造函数:
- 构造函数不能定义为虚函数。在构造函数中可以调用虚函数,不过此时调用的是正在构造的类中的虚函数,而不是子类的虚函数,因为此时子类尚未构造好。
35、C++中的重载、重写(覆盖)和隐藏的区别
(1)重载(overload)
重载是指在同一范围定义中的同名成员函数才存在重载关系。主要特点是函数名相同,参数类型和数目有所不同,不能出现参数个数和类型均相同,仅仅依靠返回值不同来区分的函数。重载和函数成员是否是虚函数无关。举个例子:
class A{
...
virtual int fun();
void fun(int);
void fun(double, double);
static int fun(char);
...
}
(2)重写(覆盖)(override)
重写指的是在派生类中覆盖基类中的同名函数,重写就是重写函数体,要求基类函数必须是虚函数且:
- 与基类的虚函数有相同的参数个数
- 与基类的虚函数有相同的参数类型
- 与基类的虚函数有相同的返回值类型
举个例子:
//父类
class A{
public:
virtual int fun(int a){}
}
//子类
class B : public A{
public:
//重写,一般加override可以确保是重写父类的函数
virtual int fun(int a) override{}
}
重载与重写的区别:
- 重写是父类和子类之间的垂直关系,重载是不同函数之间的水平关系
- 重写要求参数列表相同,重载则要求参数列表不同,返回值不要求
- 重写关系中,调用方法根据对象类型决定,重载根据调用时实参表与形参表的对应关系来选择函数体
(3)隐藏(hide)
隐藏指的是某些情况下,派生类中的函数屏蔽了基类中的同名函数,包括以下情况:
- 两个函数参数相同,但是基类函数不是虚函数。**和重写的区别在于基类函数是否是虚函数。**举个例子:
//父类
class A{
public:
void fun(int a){
cout << "A中的fun函数" << endl;
}
};
//子类
class B : public A{
public:
//隐藏父类的fun函数
void fun(int a){
cout << "B中的fun函数" << endl;
}
};
int main(){
B b;
b.fun(2); //调用的是B中的fun函数
b.A::fun(2); //调用A中fun函数
return 0;
}
- 两个函数参数不同,无论基类函数是不是虚函数,都会被隐藏。和重载的区别在于两个函数不在同一个类中。举个例子:
//父类
class A{
public:
virtual void fun(int a){
cout << "A中的fun函数" << endl;
}
};
//子类
class B : public A{
public:
//隐藏父类的fun函数
virtual void fun(char* a){
cout << "A中的fun函数" << endl;
}
};
int main(){
B b;
b.fun(2); //报错,调用的是B中的fun函数,参数类型不对
b.A::fun(2); //调用A中fun函数
return 0;
}
36、C++的多态如何实现
C++的多态性,一言以蔽之就是:
在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据所指对象的实际类型来调用相应的函数,如果对象类型是派生类,就调用派生类的函数,如果对象类型是基类,就调用基类的函数。
举个例子:
#include <iostream>
using namespace std;
class Base{
public:
virtual void fun(){
cout << " Base::func()" <<endl;
}
};
class Son1 : public Base{
public:
virtual void fun() override{
cout << " Son1::func()" <<endl;
}
};
class Son2 : public Base{
};
int main()
{
Base* base = new Son1;
base->fun();
base = new Son2;
base->fun();
delete base;
base = NULL;
return 0;
}
// 运行结果
// Son1::func()
// Base::func()
例子中,Base为基类,其中的函数为虚函数。子类1继承并重写了基类的函数,子类2继承基类但没有重写基类的函数,从结果分析子类体现了多态性,那么为什么会出现多态性,其底层的原理是什么?这里需要引出虚表和虚基表指针的概念。
虚表:虚函数表的缩写,类中含有virtual关键字修饰的方法时,编译器会自动生成虚表
虚表指针:在含有虚函数的类实例化对象时,对象地址的前四个字节存储的指向虚表的指针
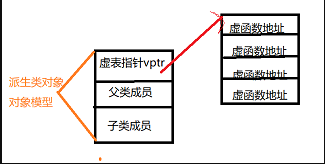
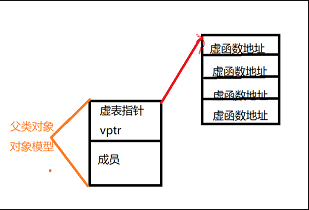
上图中展示了虚表和虚表指针在基类对象和派生类对象中的模型,下面阐述实现多态的过程:
**(1)**编译器在发现基类中有虚函数时,会自动为每个含有虚函数的类生成一份虚表,该表是一个一维数组,虚表里保存了虚函数的入口地址
(2)编译器会在每个对象的前四个字节中保存一个虚表指针,即vptr,指向对象所属类的虚表。在构造时,根据对象的类型去初始化虚指针vptr,从而让vptr指向正确的虚表,从而在调用虚函数时,能找到正确的函数
**(3)**所谓的合适时机,在派生类定义对象时,程序运行会自动调用构造函数,在构造函数中创建虚表并对虚表初始化。在构造子类对象时,会先调用父类的构造函数,此时,编译器只“看到了”父类,并为父类对象初始化虚表指针,令它指向父类的虚表;当调用子类的构造函数时,为子类对象初始化虚表指针,令它指向子类的虚表
**(4)**当派生类对基类的虚函数没有重写时,派生类的虚表指针指向的是基类的虚表;当派生类对基类的虚函数重写时,派生类的虚表指针指向的是自身的虚表;当派生类中有自己的虚函数时,在自己的虚表中将此虚函数地址添加在后面
这样指向派生类的基类指针在运行时,就可以根据派生类对虚函数重写情况动态的进行调用,从而实现多态性。
《C++实现多态的原理》:https://blog.csdn.net/qq_37954088/article/details/79947898
37、C++有哪几种的构造函数
C++中的构造函数可以分为4类:
- 默认构造函数
- 初始化构造函数(有参数)
- 拷贝构造函数
- 移动构造函数(move和右值引用)
- 委托构造函数
- 转换构造函数
举个例子:
#include <iostream>
using namespace std;
class Student{
public:
Student(){//默认构造函数,没有参数
this->age = 20;
this->num = 1000;
};
Student(int a, int n):age(a), num(n){}; //初始化构造函数,有参数和参数列表
Student(const Student& s){//拷贝构造函数,这里与编译器生成的一致
this->age = s.age;
this->num = s.num;
};
Student(int r){ //转换构造函数,形参是其他类型变量,且只有一个形参
this->age = r;
this->num = 1002;
};
~Student(){}
public:
int age;
int num;
};
int main(){
Student s1;
Student s2(18,1001);
int a = 10;
Student s3(a);
Student s4(s3);
printf("s1 age:%d, num:%d\n", s1.age, s1.num);
printf("s2 age:%d, num:%d\n", s2.age, s2.num);
printf("s3 age:%d, num:%d\n", s3.age, s3.num);
printf("s2 age:%d, num:%d\n", s4.age, s4.num);
return 0;
}
//运行结果
//s1 age:20, num:1000
//s2 age:18, num:1001
//s3 age:10, num:1002
//s2 age:10, num:1002
- 默认构造函数和初始化构造函数在定义类的对象,完成对象的初始化工作
- 复制构造函数用于复制本类的对象
- 转换构造函数用于将其他类型的变量,隐式转换为本类对象
《浅谈C++中的几种构造函数》:https://blog.csdn.net/zxc024000/article/details/51153743
38、浅拷贝和深拷贝的区别
浅拷贝
浅拷贝只是拷贝一个指针,并没有新开辟一个地址,拷贝的指针和原来的指针指向同一块地址,如果原来的指针所指向的资源释放了,那么再释放浅拷贝的指针的资源就会出现错误。
深拷贝
深拷贝不仅拷贝值,还开辟出一块新的空间用来存放新的值,即使原先的对象被析构掉,释放内存了也不会影响到深拷贝得到的值。在自己实现拷贝赋值的时候,如果有指针变量的话是需要自己实现深拷贝的。
#include <iostream>
#include <string.h>
using namespace std;
class Student
{
private:
int num;
char *name;
public:
Student(){
name = new char(20);
cout << "Student" << endl;
};
~Student(){
cout << "~Student " << &name << endl;
delete name;
name = NULL;
};
Student(const Student &s){//拷贝构造函数
//浅拷贝,当对象的name和传入对象的name指向相同的地址
name = s.name;
//深拷贝
//name = new char(20);
//memcpy(name, s.name, strlen(s.name));
cout << "copy Student" << endl;
};
};
int main()
{
{// 花括号让s1和s2变成局部对象,方便测试
Student s1;
Student s2(s1);// 复制对象
}
system("pause");
return 0;
}
//浅拷贝执行结果:
//Student
//copy Student
//~Student 0x7fffed0c3ec0
//~Student 0x7fffed0c3ed0
//*** Error in `/tmp/815453382/a.out': double free or corruption (fasttop): 0x0000000001c82c20 ***
//深拷贝执行结果:
//Student
//copy Student
//~Student 0x7fffebca9fb0
//~Student 0x7fffebca9fc0
从执行结果可以看出,浅拷贝在对象的拷贝创建时存在风险,即被拷贝的对象析构释放资源之后,拷贝对象析构时会再次释放一个已经释放的资源,深拷贝的结果是两个对象之间没有任何关系,各自成员地址不同。
《C++面试题之浅拷贝和深拷贝的区别》:https://blog.csdn.net/caoshangpa/article/details/79226270
39、内联函数和宏定义的区别
内联(inline)函数和普通函数相比可以加快程序运行的速度,因为不需要中断调用,在编译的时候内联函数可以直接嵌入到目标代码中。
内联函数适用场景
- 使用宏定义的地方都可以使用inline函数
- 作为类成员接口函数来读写类的私有成员或者保护成员,会提高效率
为什么不能把所有的函数写成内联函数
内联函数以代码复杂为代价,它以省去函数调用的开销来提高执行效率。所以一方面如果内联函数体内代码执行时间相比函数调用开销较大,则没有太大的意义;另一方面每一处内联函数的调用都要复制代码,消耗更多的内存空间,因此以下情况不宜使用内联函数:
- 函数体内的代码比较长,将导致内存消耗代价
- 函数体内有循环,函数执行时间要比函数调用开销大
主要区别
- 内联函数在编译时展开,宏在预编译时展开
- 内联函数直接嵌入到目标代码中,宏是简单的做文本替换
- 内联函数有类型检测、语法判断等功能,而宏没有
- 内联函数是函数,宏不是
- 宏定义时要注意书写(参数要括起来)否则容易出现歧义,内联函数不会产生歧义
- 内联函数代码是被放到符号表中,使用时像宏一样展开,没有调用的开销,效率很高;
《inline函数和宏定义区别 整理》:https://blog.csdn.net/wangliang888888/article/details/77990650
-
在使用时,宏只做简单字符串替换(编译前)。而内联函数可以进行参数类型检查(编译时),且具有返回值。
-
内联函数本身是函数,强调函数特性,具有重载等功能。
-
内联函数可以作为某个类的成员函数,这样可以使用类的保护成员和私有成员,进而提升效率。而当一个表达式涉及到类保护成员或私有成员时,宏就不能实现了。
40、构造函数、析构函数、虚函数可否声明为内联函数
首先,将这些函数声明为内联函数,在语法上没有错误。因为inline同register一样,只是个建议,编译器并不一定真正的内联。
register关键字:这个关键字请求编译器尽可能的将变量存在CPU内部寄存器中,而不是通过内存寻址访问,以提高效率
举个例子:
#include <iostream>
using namespace std;
class A
{
public:
inline A() {
cout << "inline construct()" <<endl;
}
inline ~A() {
cout << "inline destruct()" <<endl;
}
inline virtual void virtualFun() {
cout << "inline virtual function" <<endl;
}
};
int main()
{
A a;
a.virtualFun();
return 0;
}
//输出结果
//inline construct()
//inline virtual function
//inline destruct()
构造函数和析构函数声明为内联函数是没有意义的
《Effective C++》中所阐述的是:将构造函数和析构函数声明为inline是没有什么意义的,即编译器并不真正对声明为inline的构造和析构函数进行内联操作,因为编译器会在构造和析构函数中添加额外的操作(申请/释放内存,构造/析构对象等),致使构造函数/析构函数并不像看上去的那么精简。其次,class中的函数默认是inline型的,编译器也只是有选择性的inline,将构造函数和析构函数声明为内联函数是没有什么意义的。
将虚函数声明为inline,要分情况讨论
有的人认为虚函数被声明为inline,但是编译器并没有对其内联,他们给出的理由是inline是编译期决定的,而虚函数是运行期决定的,即在不知道将要调用哪个函数的情况下,如何将函数内联呢?
上述观点看似正确,其实不然,如果虚函数在编译器就能够决定将要调用哪个函数时,就能够内联,那么什么情况下编译器可以确定要调用哪个函数呢,答案是当用对象调用虚函数(此时不具有多态性)时,就内联展开
综上,当是指向派生类的指针(多态性)调用声明为inline的虚函数时,不会内联展开;当是对象本身调用虚函数时,会内联展开,当然前提依然是函数并不复杂的情况下
《构造函数、析构函数、虚函数可否内联,有何意义》:https://www.cnblogs.com/helloweworld/archive/2013/06/14/3136705.html
41、auto、decltype和decltype(auto)的用法
(1)auto
C++11新标准引入了auto类型说明符,用它就能让编译器替我们去分析表达式所属的类型。和原来那些只对应某种特定的类型说明符(例如 int)不同,
**auto 让编译器通过初始值来进行类型推演。从而获得定义变量的类型,所以说 auto 定义的变量必须有初始值。**举个例子:
//普通;类型
int a = 1, b = 3;
auto c = a + b;// c为int型
//const类型
const int i = 5;
auto j = i; // 变量i是顶层const, 会被忽略, 所以j的类型是int
auto k = &i; // 变量i是一个常量, 对常量取地址是一种底层const, 所以b的类型是const int*
const auto l = i; //如果希望推断出的类型是顶层const的, 那么就需要在auto前面加上cosnt
//引用和指针类型
int x = 2;
int& y = x;
auto z = y; //z是int型不是int& 型
auto& p1 = y; //p1是int&型
auto p2 = &x; //p2是指针类型int*
(2)decltype
有的时候我们还会遇到这种情况,**我们希望从表达式中推断出要定义变量的类型,但却不想用表达式的值去初始化变量。**还有可能是函数的返回类型为某表达式的值类型。在这些时候auto显得就无力了,所以C++11又引入了第二种类型说明符decltype,它的作用是选择并返回操作数的数据类型。在此过程中,编译器只是分析表达式并得到它的类型,却不进行实际的计算表达式的值。
int func() {return 0};
//普通类型
decltype(func()) sum = 5; // sum的类型是函数func()的返回值的类型int, 但是这时不会实际调用函数func()
int a = 0;
decltype(a) b = 4; // a的类型是int, 所以b的类型也是int
//不论是顶层const还是底层const, decltype都会保留
const int c = 3;
decltype(c) d = c; // d的类型和c是一样的, 都是顶层const
int e = 4;
const int* f = &e; // f是底层const
decltype(f) g = f; // g也是底层const
//引用与指针类型
//1. 如果表达式是引用类型, 那么decltype的类型也是引用
const int i = 3, &j = i;
decltype(j) k = 5; // k的类型是 const int&
//2. 如果表达式是引用类型, 但是想要得到这个引用所指向的类型, 需要修改表达式:
int i = 3, &r = i;
decltype(r + 0) t = 5; // 此时是int类型
//3. 对指针的解引用操作返回的是引用类型
int i = 3, j = 6, *p = &i;
decltype(*p) c = j; // c是int&类型, c和j绑定在一起
//4. 如果一个表达式的类型不是引用, 但是我们需要推断出引用, 那么可以加上一对括号, 就变成了引用类型了
int i = 3;
decltype((i)) j = i; // 此时j的类型是int&类型, j和i绑定在了一起
(3)decltype(auto)
decltype(auto)是C++14新增的类型指示符,可以用来声明变量以及指示函数返回类型。在使用时,会将“=”号左边的表达式替换掉auto,再根据decltype的语法规则来确定类型。举个例子:
int e = 4;
const int* f = &e; // f是底层const
decltype(auto) j = f;//j的类型是const int* 并且指向的是e
《auto和decltype的用法总结》:https://www.cnblogs.com/XiangfeiAi/p/4451904.html
《C++11新特性中auto 和 decltype 区别和联系》:https://www.jb51.net/article/103666.htm
42、public,protected和private访问和继承权限/public/protected/private的区别?
-
public的变量和函数在类的内部外部都可以访问。
-
protected的变量和函数只能在类的内部和其派生类中访问。
-
private修饰的元素只能在类内访问。
(一)访问权限
派生类可以继承基类中除了构造/析构、赋值运算符重载函数之外的成员,但是这些成员的访问属性在派生过程中也是可以调整的,三种派生方式的访问权限如下表所示:注意外部访问并不是真正的外部访问,而是在通过派生类的对象对基类成员的访问。

派生类对基类成员的访问形象有如下两种:
- 内部访问:由派生类中新增的成员函数对从基类继承来的成员的访问
- 外部访问:在派生类外部,通过派生类的对象对从基类继承来的成员的访问
(二)继承权限
public继承
公有继承的特点是基类的公有成员和保护成员作为派生类的成员时,都保持原有的状态,而基类的私有成员任然是私有的,不能被这个派生类的子类所访问
protected继承
保护继承的特点是基类的所有公有成员和保护成员都成为派生类的保护成员,并且只能被它的派生类成员函数或友元函数访问,基类的私有成员仍然是私有的,访问规则如下表

private继承
私有继承的特点是基类的所有公有成员和保护成员都成为派生类的私有成员,并不被它的派生类的子类所访问,基类的成员只能由自己派生类访问,无法再往下继承,访问规则如下表
43、如何用代码判断大小端存储
大端存储:字数据的高字节存储在低地址中
小端存储:字数据的低字节存储在低地址中
例如:32bit的数字0x12345678
所以在Socket编程中,往往需要将操作系统所用的小端存储的IP地址转换为大端存储,这样才能进行网络传输
小端模式中的存储方式为:

大端模式中的存储方式为:

了解了大小端存储的方式,如何在代码中进行判断呢?下面介绍两种判断方式:
方式一:使用强制类型转换-这种法子不错
#include <iostream>
using namespace std;
int main()
{
int a = 0x1234;
//由于int和char的长度不同,借助int型转换成char型,只会留下低地址的部分
char c = (char)(a);
if (c == 0x12)
cout << "big endian" << endl;
else if(c == 0x34)
cout << "little endian" << endl;
}
方式二:巧用union联合体
#include <iostream>
using namespace std;
//union联合体的重叠式存储,endian联合体占用内存的空间为每个成员字节长度的最大值
union endian
{
int a;
char ch;
};
int main()
{
endian value;
value.a = 0x1234;
//a和ch共用4字节的内存空间
if (value.ch == 0x12)
cout << "big endian"<<endl;
else if (value.ch == 0x34)
cout << "little endian"<<endl;
}
《写程序判断系统是大端序还是小端序》:https://www.cnblogs.com/zhoudayang/p/5985563.html
44、volatile、mutable和explicit关键字的用法
(1)volatile
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
当要求使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。
volatile定义变量的值是易变的,每次用到这个变量的值的时候都要去重新读取这个变量的值,而不是读寄存器内的备份。多线程中被几个任务共享的变量需要定义为volatile类型。
volatile 指针
volatile 指针和 const 修饰词类似,const 有常量指针和指针常量的说法,volatile 也有相应的概念
修饰由指针指向的对象、数据是 const 或 volatile 的:
const char* cpch;
volatile char* vpch;
指针自身的值——一个代表地址的整数变量,是 const 或 volatile 的:
char* const pchc;
char* volatile pchv;
注意:
- 可以把一个非volatile int赋给volatile int,但是不能把非volatile对象赋给一个volatile对象。
- 除了基本类型外,对用户定义类型也可以用volatile类型进行修饰。
- C++中一个有volatile标识符的类只能访问它接口的子集,一个由类的实现者控制的子集。用户只能用const_cast来获得对类型接口的完全访问。此外,volatile向const一样会从类传递到它的成员。
多线程下的volatile
有些变量是用volatile关键字声明的。当两个线程都要用到某一个变量且该变量的值会被改变时,应该用volatile声明,**该关键字的作用是防止优化编译器把变量从内存装入CPU寄存器中。**如果变量被装入寄存器,那么两个线程有可能一个使用内存中的变量,一个使用寄存器中的变量,这会造成程序的错误执行。volatile的意思是让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值。
(2)mutable
mutable的中文意思是“可变的,易变的”,跟constant(既C++中的const)是反义词。在C++中,mutable也是为了突破const的限制而设置的。被mutable修饰的变量,将永远处于可变的状态,即使在一个const函数中。我们知道,如果类的成员函数不会改变对象的状态,那么这个成员函数一般会声明成const的。但是,有些时候,我们需要在const函数里面修改一些跟类状态无关的数据成员,那么这个函数就应该被mutable来修饰,并且放在函数后后面关键字位置。
(3)explicit
explicit关键字用来修饰类的构造函数,被修饰的构造函数的类,不能发生相应的隐式类型转换,只能以显示的方式进行类型转换,注意以下几点:
-
explicit 关键字只能用于类内部的构造函数声明上
-
explicit 关键字作用于单个参数的构造函数
-
被explicit修饰的构造函数的类,不能发生相应的隐式类型转换
45、什么情况下会调用拷贝构造函数
- 用类的一个实例化对象去初始化另一个对象的时候
- 函数的参数是类的对象时(非引用传递)
- 函数的返回值是函数体内局部对象的类的对象时 ,此时虽然发生(Named return Value优化)NRV优化,但是由于返回方式是值传递,所以会在返回值的地方调用拷贝构造函数
另:第三种情况在Linux g++ 下则不会发生拷贝构造函数,不仅如此即使返回局部对象的引用,依然不会发生拷贝构造函数
总结就是:即使发生NRA优化的情况下,Linux+ g++的环境是不管值返回方式还是引用方式返回的方式都不会发生拷贝构造函数,而Windows + VS2019在值返回的情况下发生拷贝构造函数,引用返回方式则不发生拷贝构造函数。
在c++编译器发生NRV优化,如果是引用返回的形式则不会调用拷贝构造函数,如果是值传递的方式依然会发生拷贝构造函数。
在VS2019下进行下述实验:
举个例子:
class A
{
public:
A() {};
A(const A& a)
{
cout << "copy constructor is called" << endl;
};
~A() {};
};
void useClassA(A a) {}
A getClassA()//此时会发生拷贝构造函数的调用,虽然发生NRV优化,但是依然调用拷贝构造函数
{
A a;
return a;
}
//A& getClassA2()// VS2019下,此时编辑器会进行(Named return Value优化)NRV优化,不调用拷贝构造函数 ,如果是引用传递的方式返回当前函数体内生成的对象时,并不发生拷贝构造函数的调用
//{
// A a;
// return a;
//}
int main()
{
A a1, a2,a3,a4;
A a2 = a1; //调用拷贝构造函数,对应情况1
useClassA(a1);//调用拷贝构造函数,对应情况2
a3 = getClassA();//发生NRV优化,但是值返回,依然会有拷贝构造函数的调用 情况3
a4 = getClassA2(a1);//发生NRV优化,且引用返回自身,不会调用
return 0;
}
情况1比较好理解
情况2的实现过程是,调用函数时先根据传入的实参产生临时对象,再用拷贝构造去初始化这个临时对象,在函数中与形参对应,函数调用结束后析构临时对象
情况3在执行return时,理论的执行过程是:产生临时对象,调用拷贝构造函数把返回对象拷贝给临时对象,函数执行完先析构局部变量,再析构临时对象, 依然会调用拷贝构造函数
《C++拷贝构造函数详解》:https://www.cnblogs.com/alantu2018/p/8459250.html
46、C++中有几种类型的new
在C++中,new有三种典型的使用方法:plain new,nothrow new和placement new
(1)plain new
言下之意就是普通的new,就是我们常用的new,在C++中定义如下:
void* operator new(std::size_t) throw(std::bad_alloc);
void operator delete(void *) throw();
因此plain new在空间分配失败的情况下,抛出异常std::bad_alloc而不是返回NULL,因此通过判断返回值是否为NULL是徒劳的,举个例子:
#include <iostream>
#include <string>
using namespace std;
int main()
{
try
{
char *p = new char[10e11];
delete p;
}
catch (const std::bad_alloc &ex)
{
cout << ex.what() << endl;
}
return 0;
}
//执行结果:bad allocation
(2)nothrow new
nothrow new在空间分配失败的情况下是不抛出异常,而是返回NULL,定义如下:
void * operator new(std::size_t,const std::nothrow_t&) throw();
void operator delete(void*) throw();
举个例子:
#include <iostream>
#include <string>
using namespace std;
int main()
{
char *p = new(nothrow) char[10e11];
if (p == NULL)
{
cout << "alloc failed" << endl;
}
delete p;
return 0;
}
//运行结果:alloc failed
(3)placement new
这种new允许在一块已经分配成功的内存上重新构造对象或对象数组。placement new不用担心内存分配失败,因为它根本不分配内存,它做的唯一一件事情就是调用对象的构造函数。定义如下:
void* operator new(size_t,void*);
void operator delete(void*,void*);
使用placement new需要注意两点:
-
palcement new的主要用途就是反复使用一块较大的动态分配的内存来构造不同类型的对象或者他们的数组
-
placement new构造起来的对象数组,要显式的调用他们的析构函数来销毁(析构函数并不释放对象的内存),千万不要使用delete,这是因为placement new构造起来的对象或数组大小并不一定等于原来分配的内存大小,使用delete会造成内存泄漏或者之后释放内存时出现运行时错误。
举个例子:
#include <iostream>
#include <string>
using namespace std;
class ADT{
int i;
int j;
public:
ADT(){
i = 10;
j = 100;
cout << "ADT construct i=" << i << "j="<<j <<endl;
}
~ADT(){
cout << "ADT destruct" << endl;
}
};
int main()
{
char *p = new(nothrow) char[sizeof ADT + 1];
if (p == NULL) {
cout << "alloc failed" << endl;
}
ADT *q = new(p) ADT; //placement new:不必担心失败,只要p所指对象的的空间足够ADT创建即可
//delete q;//错误!不能在此处调用delete q;
q->ADT::~ADT();//显示调用析构函数
delete[] p;
return 0;
}
//输出结果:
//ADT construct i=10j=100
//ADT destruct
《【C++】几种类型的new介绍》:https://www.jianshu.com/p/9b57e769c3cb
47、C++中NULL和nullptr区别
算是为了与C语言进行兼容而定义的一个问题吧
NULL来自C语言,一般由宏定义实现,而 nullptr 则是C++11的新增关键字。在C语言中,NULL被定义为(void)0,而在C++语言中,NULL则被定义为整数0*。编译器一般对其实际定义如下:
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
在C++中指针必须有明确的类型定义。但是将NULL定义为0带来的另一个问题是无法与整数的0区分。因为C++中允许有函数重载,所以可以试想如下函数定义情况:
#include <iostream>
using namespace std;
void fun(char* p) {
cout << "char*" << endl;
}
void fun(int p) {
cout << "int" << endl;
}
int main()
{
fun(NULL);
return 0;
}
//输出结果:int
那么在传入NULL参数时,会把NULL当做整数0来看,如果我们想调用参数是指针的函数,该怎么办呢?。nullptr在C++11被引入用于解决这一问题,nullptr可以明确区分整型和指针类型,能够根据环境自动转换成相应的指针类型,但不会被转换为任何整型,所以不会造成参数传递错误。
nullptr的一种实现方式如下:
const class nullptr_t{
public:
template<class T> inline operator T*() const{ return 0; }
template<class C, class T> inline operator T C::*() const { return 0; }
private:
void operator&() const;
} nullptr = {};
以上通过模板类和运算符重载的方式来对不同类型的指针进行实例化从而解决了(void*)指针带来参数类型不明的问题,**另外由于nullptr是明确的指针类型,所以不会与整形变量相混淆。**但nullptr仍然存在一定问题,例如:
#include <iostream>
using namespace std;
void fun(char* p)
{
cout<< "char* p" <<endl;
}
void fun(int* p)
{
cout<< "int* p" <<endl;
}
void fun(int p)
{
cout<< "int p" <<endl;
}
int main()
{
fun((char*)nullptr);//语句1
fun(nullptr);//语句2
fun(NULL);//语句3
return 0;
}
//运行结果:
//语句1:char* p
//语句2:报错,有多个匹配
//3:int p
在这种情况下存在对不同指针类型的函数重载,此时如果传入nullptr指针则仍然存在无法区分应实际调用哪个函数,这种情况下必须显示的指明参数类型。
《NULL和nullptr区别》:https://blog.csdn.net/qq_39380590/article/details/82563571
48、简要说明C++的内存分区
C++中的内存分区,分别是堆、栈、自由存储区、全局/静态存储区、常量存储区和代码区。如下图所示
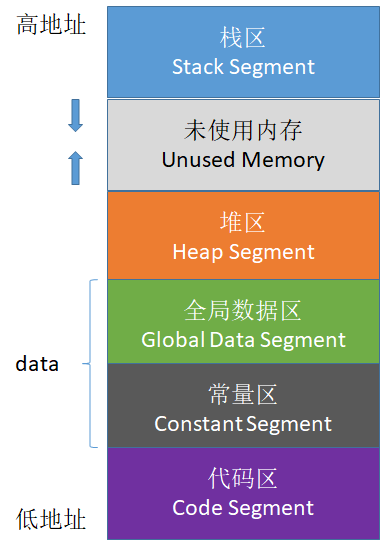
栈:在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限
堆:就是那些由 new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个 delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收
自由存储区:就是那些由malloc等分配的内存块,它和堆是十分相似的,不过它是用free来结束自己的生命的
全局/静态存储区:全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量和静态变量又分为初始化的和未初始化的,在C++里面没有这个区分了,它们共同占用同一块内存区,在该区定义的变量若没有初始化,则会被自动初始化,例如int型变量自动初始为0
常量存储区:这是一块比较特殊的存储区,这里面存放的是常量,不允许修改
代码区:存放函数体的二进制代码
《C/C++内存管理详解》:https://chenqx.github.io/2014/09/25/Cpp-Memory-Management/
49、C++的异常处理的方法
在程序执行过程中,由于程序员的疏忽或是系统资源紧张等因素都有可能导致异常,任何程序都无法保证绝对的稳定,常见的异常有:
- 数组下标越界
- 除法计算时除数为0
- 动态分配空间时空间不足
- ...
如果不及时对这些异常进行处理,程序多数情况下都会崩溃。
(1)try、throw和catch关键字
C++中的异常处理机制主要使用try、throw和catch三个关键字,其在程序中的用法如下:
#include <iostream>
using namespace std;
int main()
{
double m = 1, n = 0;
try {
cout << "before dividing." << endl;
if (n == 0)
throw - 1; //抛出int型异常
else if (m == 0)
throw - 1.0; //拋出 double 型异常
else
cout << m / n << endl;
cout << "after dividing." << endl;
}
catch (double d) {
cout << "catch (double)" << d << endl;
}
catch (...) {
cout << "catch (...)" << endl;
}
cout << "finished" << endl;
return 0;
}
//运行结果
//before dividing.
//catch (...)
//finished
代码中,对两个数进行除法计算,其中除数为0。可以看到以上三个关键字,程序的执行流程是先执行try包裹的语句块,如果执行过程中没有异常发生,则不会进入任何catch包裹的语句块,如果发生异常,则使用throw进行异常抛出,再由catch进行捕获,throw可以抛出各种数据类型的信息,代码中使用的是数字,也可以自定义异常class。**catch根据throw抛出的数据类型进行精确捕获(不会出现类型转换),如果匹配不到就直接报错,可以使用catch(...)的方式捕获任何异常(不推荐)。**当然,如果catch了异常,当前函数如果不进行处理,或者已经处理了想通知上一层的调用者,可以在catch里面再throw异常。
(2)函数的异常声明列表
有时候,程序员在定义函数的时候知道函数可能发生的异常,可以在函数声明和定义时,指出所能抛出异常的列表,写法如下:
int fun() throw(int,double,A,B,C){...};
这种写法表名函数可能会抛出int,double型或者A、B、C三种类型的异常,如果throw中为空,表明不会抛出任何异常,如果没有throw则可能抛出任何异常
(3)C++标准异常类 exception
C++ 标准库中有一些类代表异常,这些类都是从 exception 类派生而来的,如下图所示
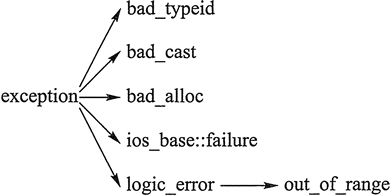
- bad_typeid:使用typeid运算符,如果其操作数是一个多态类的指针,而该指针的值为 NULL,则会拋出此异常,例如:
#include <iostream>
#include <typeinfo>
using namespace std;
class A{
public:
virtual ~A();
};
using namespace std;
int main() {
A* a = NULL;
try {
cout << typeid(*a).name() << endl; // Error condition
}
catch (bad_typeid){
cout << "Object is NULL" << endl;
}
return 0;
}
//运行结果:bject is NULL
- bad_cast:在用 dynamic_cast 进行从多态基类对象(或引用)到派生类的引用的强制类型转换时,如果转换是不安全的,则会拋出此异常
- bad_alloc:在用 new 运算符进行动态内存分配时,如果没有足够的内存,则会引发此异常
- out_of_range:用 vector 或 string的at 成员函数根据下标访问元素时,如果下标越界,则会拋出此异常
《C++异常处理(try catch throw)完全攻略》:http://c.biancheng.net/view/422.html
50、static的用法和作用?
1.先来介绍它的第一条也是最重要的一条:隐藏。(static函数,static变量均可)
当同时编译多个文件时,所有未加static前缀的全局变量和函数都具有全局可见性。
2.static的第二个作用是保持变量内容的持久。(static变量中的记忆功能和全局生存期)存储在静态数据区的变量会在程序刚开始运行时就完成初始化,也是唯一的一次初始化。共有两种变量存储在静态存储区:全局变量和static变量,只不过和全局变量比起来,static可以控制变量的可见范围,说到底static还是用来隐藏的。
3.static的第三个作用是默认初始化为0(static变量)
其实全局变量也具备这一属性,因为全局变量也存储在静态数据区。在静态数据区,内存中所有的字节默认值都是0x00,某些时候这一特点可以减少程序员的工作量。
4.static的第四个作用:C++中的类成员声明static
-
函数体内static变量的作用范围为该函数体,不同于auto变量,该变量的内存只被分配一次,因此其值在下次调用时仍维持上次的值;
-
在模块内的static全局变量可以被模块内所用函数访问,但不能被模块外其它函数访问;
-
在模块内的static函数只可被这一模块内的其它函数调用,这个函数的使用范围被限制在声明它的模块内;
-
在类中的static成员变量属于整个类所拥有,对类的所有对象只有一份拷贝;
-
在类中的static成员函数属于整个类所拥有,这个函数不接收this指针,因而只能访问类的static成员变量。
类内:
-
static类对象必须要在类外进行初始化,static修饰的变量先于对象存在,所以static修饰的变量要在类外初始化;
-
由于static修饰的类成员属于类,不属于对象,因此static类成员函数是没有this指针的,this指针是指向本对象的指针。正因为没有this指针,所以static类成员函数不能访问非static的类成员,只能访问 static修饰的类成员;
-
static成员函数不能被virtual修饰,static成员不属于任何对象或实例,所以加上virtual没有任何实际意义;静态成员函数没有this指针,虚函数的实现是为每一个对象分配一个vptr指针,而vptr是通过this指针调用的,所以不能为virtual;虚函数的调用关系,this->vptr->ctable->virtual function
51、静态变量什么时候初始化
-
初始化只有一次,但是可以多次赋值,在主程序之前,编译器已经为其分配好了内存。
-
静态局部变量和全局变量一样,数据都存放在全局区域,所以在主程序之前,编译器已经为其分配好了内存,但在C和C++中静态局部变量的初始化节点又有点不太一样。在C中,初始化发生在代码执行之前,编译阶段分配好内存之后,就会进行初始化,所以我们看到在C语言中无法使用变量对静态局部变量进行初始化,在程序运行结束,变量所处的全局内存会被全部回收。
-
而在C++中,初始化时在执行相关代码时才会进行初始化,主要是由于C++引入对象后,要进行初始化必须执行相应构造函数和析构函数,在构造函数或析构函数中经常会需要进行某些程序中需要进行的特定操作,并非简单地分配内存。所以C++标准定为全局或静态对象是有首次用到时才会进行构造,并通过atexit()来管理。在程序结束,按照构造顺序反方向进行逐个析构。所以在C++中是可以使用变量对静态局部变量进行初始化的。
52、const关键字?
-
阻止一个变量被改变,可以使用const关键字。在定义该const变量时,通常需要对它进行初始化,因为以后就没有机会再去改变它了;
-
对指针来说,可以指定指针本身为const,也可以指定指针所指的数据为const,或二者同时指定为const;
-
在一个函数声明中,const可以修饰形参,表明它是一个输入参数,在函数内部不能改变其值;
-
对于类的成员函数,若指定其为const类型,则表明其是一个常函数,不能修改类的成员变量,类的常对象只能访问类的常成员函数;
-
对于类的成员函数,有时候必须指定其返回值为const类型,以使得其返回值不为“左值”。
-
const成员函数可以访问非const对象的非const数据成员、const数据成员,也可以访问const对象内的所有数据成员;
-
非const成员函数可以访问非const对象的非const数据成员、const数据成员,但不可以访问const对象的任意数据成员;
-
一个没有明确声明为const的成员函数被看作是将要修改对象中数据成员的函数,而且编译器不允许它为一个const对象所调用。因此const对象只能调用const成员函数。
-
const类型变量可以通过类型转换符const_cast将const类型转换为非const类型;
-
const类型变量必须定义的时候进行初始化,因此也导致如果类的成员变量有const类型的变量,那么该变量必须在类的初始化列表中进行初始化;
-
对于函数值传递的情况,因为参数传递是通过复制实参创建一个临时变量传递进函数的,函数内只能改变临时变量,但无法改变实参。则这个时候无论加不加const对实参不会产生任何影响。但是在引用或指针传递函数调用中,因为传进去的是一个引用或指针,这样函数内部可以改变引用或指针所指向的变量,这时const 才是实实在在地保护了实参所指向的变量。因为在编译阶段编译器对调用函数的选择是根据实参进行的,所以,只有引用传递和指针传递可以用是否加const来重载。一个拥有顶层const的形参无法和另一个没有顶层const的形参区分开来。
53、指针和const的用法
-
当const修饰指针时,由于const的位置不同,它的修饰对象会有所不同。
-
int *const p2中const修饰p2的值,所以理解为p2的值不可以改变,即p2只能指向固定的一个变量地址,但可以通过*p2读写这个变量的值。顶层指针表示指针本身是一个常量
-
int const *p1或者const int *p1两种情况中const修饰*p1,所以理解为*p1的值不可以改变,即不可以给*p1赋值改变p1指向变量的值,但可以通过给p赋值不同的地址改变这个指针指向。
底层指针表示指针所指向的变量是一个常量。
54、形参与实参的区别?
-
形参变量只有在被调用时才分配内存单元,在调用结束时, 即刻释放所分配的内存单元。因此,形参只有在函数内部有效。 函数调用结束返回主调函数后则不能再使用该形参变量。
-
实参可以是常量、变量、表达式、函数等, 无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值, 以便把这些值传送给形参。 因此应预先用赋值,输入等办法使实参获得确定值,会产生一个临时变量。
-
实参和形参在数量上,类型上,顺序上应严格一致, 否则会发生“类型不匹配”的错误。
-
函数调用中发生的数据传送是单向的。 即只能把实参的值传送给形参,而不能把形参的值反向地传送给实参。 因此在函数调用过程中,形参的值发生改变,而实参中的值不会变化。
-
当形参和实参不是指针类型时,在该函数运行时,形参和实参是不同的变量,他们在内存中位于不同的位置,形参将实参的内容复制一份,在该函数运行结束的时候形参被释放,而实参内容不会改变。
55、值传递、指针传递、引用传递的区别和效率
-
值传递:有一个形参向函数所属的栈拷贝数据的过程,如果值传递的对象是类对象 或是大的结构体对象,将耗费一定的时间和空间。(传值)
-
指针传递:同样有一个形参向函数所属的栈拷贝数据的过程,但拷贝的数据是一个固定为4字节的地址。(传值,传递的是地址值)
-
引用传递:同样有上述的数据拷贝过程,但其是针对地址的,相当于为该数据所在的地址起了一个别名。(传地址)
-
效率上讲,指针传递和引用传递比值传递效率高。一般主张使用引用传递,代码逻辑上更加紧凑、清晰。
56、什么是类的继承?
- 类与类之间的关系
has-A包含关系,用以描述一个类由多个部件类构成,实现has-A关系用类的成员属性表示,即一个类的成员属性是另一个已经定义好的类;
use-A,一个类使用另一个类,通过类之间的成员函数相互联系,定义友元或者通过传递参数的方式来实现;
is-A,继承关系,关系具有传递性;
- 继承的相关概念
所谓的继承就是一个类继承了另一个类的属性和方法,这个新的类包含了上一个类的属性和方法,被称为子类或者派生类,被继承的类称为父类或者基类;
- 继承的特点
子类拥有父类的所有属性和方法,子类可以拥有父类没有的属性和方法,子类对象可以当做父类对象使用;
- 继承中的访问控制
public、protected、private
-
继承中的构造和析构函数
-
继承中的兼容性原则
57、什么是内存池,如何实现
https://www.bilibili.com/video/BV1Kb411B7N8?p=25 C++内存管理:P23-26
内存池(Memory Pool) 是一种内存分配方式。通常我们习惯直接使用new、malloc 等申请内存,这样做的缺点在于:由于所申请内存块的大小不定,当频繁使用时会造成大量的内存碎片并进而降低性能。内存池则是在真正使用内存之前,先申请分配一定数量的、大小相等(一般情况下)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块, 若内存块不够再继续申请新的内存。这样做的一个显著优点是尽量避免了内存碎片,使得内存分配效率得到提升。
这里简单描述一下《STL源码剖析》中的内存池实现机制:
allocate包装malloc,deallocate包装free
一般是一次20*2个的申请,先用一半,留着一半,为什么也没个说法,侯捷在STL那边书里说好像是C++委员会成员认为20是个比较好的数字,既不大也不小
- 首先客户端会调用malloc()配置一定数量的区块(固定大小的内存块,通常为8的倍数),假设40个32bytes的区块,其中20个区块(一半)给程序实际使用,1个区块交出,另外19个处于维护状态。剩余20个(一半)留给内存池,此时一共有(20*32byte)
- 客户端之后有有内存需求,想申请(20*64bytes)的空间,这时内存池只有(20*32bytes),就先将(10*64bytes)个区块返回,1个区块交出,另外9个处于维护状态,此时内存池空空如也
- 接下来如果客户端还有内存需求,就必须再调用malloc()配置空间,此时新申请的区块数量会增加一个随着配置次数越来越大的附加量,同样一半提供程序使用,另一半留给内存池。申请内存的时候用永远是先看内存池有无剩余,有的话就用上,然后挂在0-15号某一条链表上,要不然就重新申请。
- 如果整个堆的空间都不够了,就会在原先已经分配区块中寻找能满足当前需求的区块数量,能满足就返回,不能满足就向客户端报bad_alloc异常
《STL源码解析》侯捷 P68
allocator就是用来分配内存的,最重要的两个函数是allocate和deallocate,就是用来申请内存和回收内存的,外部(一般指容器)调用的时候只需要知道这些就够了。内部实现,目前的所有编译器都是直接调用的::operator new()和::operator delete(),说白了就是和直接使用new运算符的效果是一样的,所以老师说它们都没做任何特殊处理。
最开始GC2.9之前:
new和 operator new 的区别:new 是个运算符,编辑器会调用 operator new(0)
operator new()里面有调用malloc的操作,那同样的 operator delete()里面有调用的free的操作
GC2.9的alloc的一个比较好的分配器的实现规则
维护一条0-15号的一共16条链表,其中0表示8 bytes ,1表示 16 bytes,2表示 24bytes。。。。而15 表示 16* 8 = 128bytes,如果在申请时并不是8的倍数,那就找刚好能满足内存大小的那个位置。比如想申请 12,那就是找16了,想申请 20 ,那就找 24 了
但是现在GC4.9及其之后 也还有,变成_pool_alloc这个名字了,不再是默认的了,你需要自己去指定它可以自己指定,比如说vector<string,__gnu_cxx::pool_alloc> vec;这样来使用它,现在用的又回到以前那种对malloc和free的包装形式了
58、从汇编层去解释一下引用
9: int x = 1;
00401048 mov dword ptr [ebp-4],1
10: int &b = x;
0040104F lea eax,[ebp-4]
00401052 mov dword ptr [ebp-8],eax
x的地址为ebp-4,b的地址为ebp-8,因为栈内的变量内存是从高往低进行分配的,所以b的地址比x的低。
lea eax,[ebp-4] 这条语句将x的地址ebp-4放入eax寄存器
mov dword ptr [ebp-8],eax 这条语句将eax的值放入b的地址
ebp-8中上面两条汇编的作用即:将x的地址存入变量b中,这不和将某个变量的地址存入指针变量是一样的吗?所以从汇编层次来看,的确引用是通过指针来实现的。
59、深拷贝与浅拷贝是怎么回事?
- 浅复制 :只是拷贝了基本类型的数据,而引用类型数据,复制后也是会发生引用,我们把这种拷贝叫做“(浅复制)浅拷贝”,换句话说,浅复制仅仅是指向被复制的内存地址,如果原地址中对象被改变了,那么浅复制出来的对象也会相应改变。
深复制 :在计算机中开辟了一块新的内存地址用于存放复制的对象。
- 在某些状况下,类内成员变量需要动态开辟堆内存,如果实行位拷贝,也就是把对象里的值完全复制给另一个对象,如A=B。这时,如果B中有一个成员变量指针已经申请了内存,那A中的那个成员变量也指向同一块内存。这就出现了问题:当B把内存释放了(如:析构),这时A内的指针就是野指针了,出现运行错误。
60、C++模板是什么,你知道底层怎么实现的?
-
编译器并不是把函数模板处理成能够处理任意类的函数;编译器从函数模板通过具体类型产生不同的函数;编译器会对函数模板进行两次编译:在声明的地方对模板代码本身进行编译,在调用的地方对参数替换后的代码进行编译。
-
这是因为函数模板要被实例化后才能成为真正的函数,在使用函数模板的源文件中包含函数模板的头文件,如果该头文件中只有声明,没有定义,那编译器无法实例化该模板,最终导致链接错误。
61、new和malloc的区别?
1、 new/delete是C++关键字,需要编译器支持。malloc/free是库函数,需要头文件支持;
2、 使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要显式地指出所需内存的尺寸。
3、 new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。
4、 new内存分配失败时,会抛出bac_alloc异常。malloc分配内存失败时返回NULL。
5、 new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。malloc/free是库函数,只能动态的申请和释放内存,无法强制要求其做自定义类型对象构造和析构工作。
62、delete p、delete [] p、allocator都有什么作用?
1、 动态数组管理new一个数组时,[]中必须是一个整数,但是不一定是常量整数,普通数组必须是一个常量整数;
2、 new动态数组返回的并不是数组类型,而是一个元素类型的指针;
3、 delete[]时,数组中的元素按逆序的顺序进行销毁;
4、 new在内存分配上面有一些局限性,new的机制是将内存分配和对象构造组合在一起,同样的,delete也是将对象析构和内存释放组合在一起的。allocator将这两部分分开进行,allocator申请一部分内存,不进行初始化对象,只有当需要的时候才进行初始化操作。
63、new和delete的实现原理, delete是如何知道释放内存的大小的额?
1、 new简单类型直接调用operator new分配内存;
而对于复杂结构,先调用operator new分配内存,然后在分配的内存上调用构造函数;
对于简单类型,new[]计算好大小后调用operator new;
对于复杂数据结构,new[]先调用operator new[]分配内存,然后在p的前四个字节写入数组大小n,然后调用n次构造函数,针对复杂类型,new[]会额外存储数组大小;
① new表达式调用一个名为operator new(operator new[])函数,分配一块足够大的、原始的、未命名的内存空间;
② 编译器运行相应的构造函数以构造这些对象,并为其传入初始值;
③ 对象被分配了空间并构造完成,返回一个指向该对象的指针。
2、 delete简单数据类型默认只是调用free函数;复杂数据类型先调用析构函数再调用operator delete;针对简单类型,delete和delete[]等同。假设指针p指向new[]分配的内存。因为要4字节存储数组大小,实际分配的内存地址为[p-4],系统记录的也是这个地址。delete[]实际释放的就是p-4指向的内存。而delete会直接释放p指向的内存,这个内存根本没有被系统记录,所以会崩溃。
3、 需要在 new [] 一个对象数组时,需要保存数组的维度,C++ 的做法是在分配数组空间时多分配了 4 个字节的大小,专门保存数组的大小,在 delete [] 时就可以取出这个保存的数,就知道了需要调用析构函数多少次了。
64、malloc申请的存储空间能用delete释放吗
不能,malloc /free主要为了兼容C,new和delete 完全可以取代malloc /free的。
malloc /free的操作对象都是必须明确大小的,而且不能用在动态类上。
new 和delete会自动进行类型检查和大小,malloc/free不能执行构造函数与析构函数,所以动态对象它是不行的。
当然从理论上说使用malloc申请的内存是可以通过delete释放的。不过一般不这样写的。而且也不能保证每个C++的运行时都能正常。
65、malloc与free的实现原理?
1、 在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk、mmap、,munmap这些系统调用实现的;
2、 brk是将数据段(.data)的最高地址指针_edata往高地址推,mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系;
3、 malloc小于128k的内存,使用brk分配内存,将_edata往高地址推;malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配;brk分配的内存需要等到高地址内存释放以后才能释放,而mmap分配的内存可以单独释放。当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩。
4、 malloc是从堆里面申请内存,也就是说函数返回的指针是指向堆里面的一块内存。操作系统中有一个记录空闲内存地址的链表。当操作系统收到程序的申请时,就会遍历该链表,然后就寻找第一个空间大于所申请空间的堆结点,然后就将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
66、malloc、realloc、calloc的区别
- malloc函数
void* malloc(unsigned int num_size);
int *p = malloc(20*sizeof(int));申请20个int类型的空间;
- calloc函数
void* calloc(size_t n,size_t size);
int *p = calloc(20, sizeof(int));
省去了人为空间计算;malloc申请的空间的值是随机初始化的,calloc申请的空间的值是初始化为0的;
- realloc函数
void realloc(void *p, size_t new_size);
给动态分配的空间分配额外的空间,用于扩充容量。
67、类成员初始化方式?构造函数的执行顺序 ?为什么用成员初始化列表会快一些?
- 赋值初始化,通过在函数体内进行赋值初始化;列表初始化,在冒号后使用初始化列表进行初始化。
这两种方式的主要区别在于:
对于在函数体中初始化,是在所有的数据成员被分配内存空间后才进行的。
列表初始化是给数据成员分配内存空间时就进行初始化,就是说分配一个数据成员只要冒号后有此数据成员的赋值表达式(此表达式必须是括号赋值表达式),那么分配了内存空间后在进入函数体之前给数据成员赋值,就是说初始化这个数据成员此时函数体还未执行。
- 一个派生类构造函数的执行顺序如下:
① 虚拟基类的构造函数(多个虚拟基类则按照继承的顺序执行构造函数)。
② 基类的构造函数(多个普通基类也按照继承的顺序执行构造函数)。
③ 类类型的成员对象的构造函数(按照初始化顺序)
④ 派生类自己的构造函数。
- 方法一是在构造函数当中做赋值的操作,而方法二是做纯粹的初始化操作。我们都知道,C++的赋值操作是会产生临时对象的。临时对象的出现会降低程序的效率。
68、成员列表初始化?
- 必须使用成员初始化的四种情况
① 当初始化一个引用成员时;
② 当初始化一个常量成员时;
③ 当调用一个基类的构造函数,而它拥有一组参数时;
④ 当调用一个成员类的构造函数,而它拥有一组参数时;
- 成员初始化列表做了什么
① 编译器会一一操作初始化列表,以适当的顺序在构造函数之内安插初始化操作,并且在任何显示用户代码之前;
② list中的项目顺序是由类中的成员声明顺序决定的,不是由初始化列表的顺序决定的;
69、什么是内存泄露,如何检测与避免
内存泄露
一般我们常说的内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定)内存块,使用完后必须显式释放的内存。应用程序般使用malloc,、realloc、 new等函数从堆中分配到块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用,我们就说这块内存泄漏了
避免内存泄露的几种方式
- 计数法:使用new或者malloc时,让该数+1,delete或free时,该数-1,程序执行完打印这个计数,如果不为0则表示存在内存泄露
- 一定要将基类的析构函数声明为虚函数
- 对象数组的释放一定要用delete []
- 有new就有delete,有malloc就有free,保证它们一定成对出现
检测工具
- Linux下可以使用Valgrind工具
- Windows下可以使用CRT库
70、对象复用的了解,零拷贝的了解
对象复用
对象复用其本质是一种设计模式:Flyweight享元模式。
通过将对象存储到“对象池”中实现对象的重复利用,这样可以避免多次创建重复对象的开销,节约系统资源。
零拷贝
零拷贝就是一种避免 CPU 将数据从一块存储拷贝到另外一块存储的技术。
零拷贝技术可以减少数据拷贝和共享总线操作的次数。
在C++中,vector的一个成员函数**emplace_back()**很好地体现了零拷贝技术,它跟push_back()函数一样可以将一个元素插入容器尾部,区别在于:使用push_back()函数需要调用拷贝构造函数和转移构造函数,而使用emplace_back()插入的元素原地构造,不需要触发拷贝构造和转移构造,效率更高。举个例子:
#include <vector>
#include <string>
#include <iostream>
using namespace std;
struct Person
{
string name;
int age;
//初始构造函数
Person(string p_name, int p_age): name(std::move(p_name)), age(p_age)
{
cout << "I have been constructed" <<endl;
}
//拷贝构造函数
Person(const Person& other): name(std::move(other.name)), age(other.age)
{
cout << "I have been copy constructed" <<endl;
}
//转移构造函数
Person(Person&& other): name(std::move(other.name)), age(other.age)
{
cout << "I have been moved"<<endl;
}
};
int main()
{
vector<Person> e;
cout << "emplace_back:" <<endl;
e.emplace_back("Jane", 23); //不用构造类对象
vector<Person> p;
cout << "push_back:"<<endl;
p.push_back(Person("Mike",36));
return 0;
}
//输出结果:
//emplace_back:
//I have been constructed
//push_back:
//I have been constructed
//I am being moved.
71、解释一下什么是trivial destructor
“trivial destructor”一般是指用户没有自定义析构函数,而由系统生成的,这种析构函数在《STL源码解析》中成为“无关痛痒”的析构函数。
反之,用户自定义了析构函数,则称之为“non-trivial destructor”,这种析构函数如果申请了新的空间一定要显式的释放,否则会造成内存泄露
对于trivial destructor,如果每次都进行调用,显然对效率是一种伤害,如何进行判断呢?《STL源码解析》中给出的说明是:
首先利用value_type()获取所指对象的型别,再利用__type_traits判断该型别的析构函数是否trivial,若是(__true_type),则什么也不做,若为(__false_type),则去调用destory()函数
也就是说,在实际的应用当中,STL库提供了相关的判断方法**__type_traits**,感兴趣的读者可以自行查阅使用方式。除了trivial destructor,还有trivial construct、trivial copy construct等,如果能够对是否trivial进行区分,可以采用内存处理函数memcpy()、malloc()等更加高效的完成相关操作,提升效率。
《C++中的 trivial destructor》:https://blog.csdn.net/wudishine/article/details/12307611
72、介绍面向对象的三大特性,并且举例说明
三大特性:继承、封装和多态
(1)继承
让某种类型对象获得另一个类型对象的属性和方法。
它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展
常见的继承有三种方式:
- 实现继承:指使用基类的属性和方法而无需额外编码的能力
- 接口继承:指仅使用属性和方法的名称、但是子类必须提供实现的能力
- 可视继承:指子窗体(类)使用基窗体(类)的外观和实现代码的能力(C++里好像不怎么用)
例如,将人定义为一个抽象类,拥有姓名、性别、年龄等公共属性,吃饭、睡觉、走路等公共方法,在定义一个具体的人时,就可以继承这个抽象类,既保留了公共属性和方法,也可以在此基础上扩展跳舞、唱歌等特有方法
(2)封装
数据和代码捆绑在一起,避免外界干扰和不确定性访问。
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏,例如:将公共的数据或方法使用public修饰,而不希望被访问的数据或方法采用private修饰。
(3)多态
同一事物表现出不同事物的能力,即向不同对象发送同一消息,不同的对象在接收时会产生不同的行为**(重载实现编译时多态,虚函数实现运行时多态)**。
多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单一句话:允许将子类类型的指针赋值给父类类型的指针
实现多态有二种方式:覆盖(override),重载(overload)。覆盖:是指子类重新定义父类的虚函数的做法。重载:是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。例如:基类是一个抽象对象——人,那教师、运动员也是人,而使用这个抽象对象既可以表示教师、也可以表示运动员。
《C++封装继承多态总结》:https://blog.csdn.net/IOT_SHUN/article/details/79674293
73、C++中类的数据成员和成员函数内存分布情况
C++类是由结构体发展得来的,所以他们的成员变量(C语言的结构体只有成员变量)的内存分配机制是一样的。下面我们以类来说明问题,如果类的问题通了,结构体也也就没问题啦。 类分为成员变量和成员函数,我们先来讨论成员变量。
一个类对象的地址就是类所包含的这一片内存空间的首地址,这个首地址也就对应具体某一个成员变量的地址。(在定义类对象的同时这些成员变量也就被定义了),举个例子:
#include <iostream>
using namespace std;
class Person
{
public:
Person()
{
this->age = 23;
}
void printAge()
{
cout << this->age <<endl;
}
~Person(){}
public:
int age;
};
int main()
{
Person p;
cout << "对象地址:"<< &p <<endl;
cout << "age地址:"<< &(p.age) <<endl;
cout << "对象大小:"<< sizeof(p) <<endl;
cout << "age大小:"<< sizeof(p.age) <<endl;
return 0;
}
//输出结果
//对象地址:0x7fffec0f15a8
//age地址:0x7fffec0f15a8
//对象大小:4
//age大小:4
从代码运行结果来看,对象的大小和对象中数据成员的大小是一致的,也就是说,成员函数不占用对象的内存。这是因为所有的函数都是存放在代码区的,不管是全局函数,还是成员函数。要是成员函数占用类的对象空间,那么将是多么可怕的事情:定义一次类对象就有成员函数占用一段空间。 我们再来补充一下静态成员函数的存放问题:静态成员函数与一般成员函数的唯一区别就是没有this指针,因此不能访问非静态数据成员,就像我前面提到的,所有函数都存放在代码区,静态函数也不例外。所有有人一看到 static 这个单词就主观的认为是存放在全局数据区,那是不对的。
《C++类对象成员变量和函数内存分配的问题》:https://blog.csdn.net/z2664836046/article/details/78967313
74、成员初始化列表的概念,为什么用它会快一些?
成员初始化列表的概念
在类的构造函数中,不在函数体内对成员变量赋值,而是在构造函数的花括号前面使用冒号和初始化列表赋值
效率
用初始化列表会快一些的原因是,对于类型,它少了一次调用构造函数的过程,而在函数体中赋值则会多一次调用。而对于内置数据类型则没有差别。举个例子:
#include <iostream>
using namespace std;
class A
{
public:
A()
{
cout << "默认构造函数A()" << endl;
}
A(int a)
{
value = a;
cout << "A(int "<<value<<")" << endl;
}
A(const A& a)
{
value = a.value;
cout << "拷贝构造函数A(A& a): "<<value << endl;
}
int value;
};
class B
{
public:
B() : a(1)
{
b = A(2);
}
A a;
A b;
};
int main()
{
B b;
}
//输出结果:
//A(int 1)
//默认构造函数A()
//A(int 2)
从代码运行结果可以看出,在构造函数体内部初始化的对象b多了一次构造函数的调用过程,而对象a则没有。由于对象成员变量的初始化动作发生在进入构造函数之前,对于内置类型没什么影响,但如果有些成员是类,那么在进入构造函数之前,会先调用一次默认构造函数,进入构造函数后所做的事其实是一次赋值操作(对象已存在),所以如果是在构造函数体内进行赋值的话,等于是一次默认构造加一次赋值,而初始化列表只做一次赋值操作。
《为什么用成员初始化列表会快一些?》:https://blog.csdn.net/JackZhang_123/article/details/82590368
75、(超重要)构造函数为什么不能为虚函数?析构函数为什么要虚函数?
**1、 从存储空间角度,**虚函数相应一个指向vtable虚函数表的指针,这大家都知道,但是这个指向vtable的指针事实上是存储在对象的内存空间的。
问题出来了,假设构造函数是虚的,就须要通过 vtable来调用,但是对象还没有实例化,也就是内存空间还没有,怎么找vtable呢?所以构造函数不能是虚函数。
**2、 从使用角度,**虚函数主要用于在信息不全的情况下,能使重载的函数得到相应的调用。
构造函数本身就是要初始化实例,那使用虚函数也没有实际意义呀。
所以构造函数没有必要是虚函数。虚函数的作用在于通过父类的指针或者引用来调用它的时候可以变成调用子类的那个成员函数。而构造函数是在创建对象时自己主动调用的,不可能通过父类的指针或者引用去调用,因此也就规定构造函数不能是虚函数。
**3、构造函数不须要是虚函数,也不同意是虚函数,**由于创建一个对象时我们总是要明白指定对象的类型,虽然我们可能通过实验室的基类的指针或引用去訪问它但析构却不一定,我们往往通过基类的指针来销毁对象。这时候假设析构函数不是虚函数,就不能正确识别对象类型从而不能正确调用析构函数。
**4、从实现上看,**vbtl在构造函数调用后才建立,因而构造函数不可能成为虚函数从实际含义上看,在调用构造函数时还不能确定对象的真实类型(由于子类会调父类的构造函数);并且构造函数的作用是提供初始化,在对象生命期仅仅运行一次,不是对象的动态行为,也没有必要成为虚函数。
5、当一个构造函数被调用时,它做的首要的事情之中的一个是初始化它的VPTR。
因此,它仅仅能知道它是“当前”类的,而全然忽视这个对象后面是否还有继承者。当编译器为这个构造函数产生代码时,它是为这个类的构造函数产生代码——既不是为基类,也不是为它的派生类(由于类不知道谁继承它)。所以它使用的VPTR必须是对于这个类的VTABLE。
并且,仅仅要它是最后的构造函数调用,那么在这个对象的生命期内,VPTR将保持被初始化为指向这个VTABLE, 但假设接着另一个更晚派生的构造函数被调用,这个构造函数又将设置VPTR指向它的 VTABLE,等.直到最后的构造函数结束。
VPTR的状态是由被最后调用的构造函数确定的。这就是为什么构造函数调用是从基类到更加派生类顺序的还有一个理由。可是,当这一系列构造函数调用正发生时,每一个构造函数都已经设置VPTR指向它自己的VTABLE。假设函数调用使用虚机制,它将仅仅产生通过它自己的VTABLE的调用,而不是最后的VTABLE(全部构造函数被调用后才会有最后的VTABLE)。
因为构造函数本来就是为了明确初始化对象成员才产生的,然而virtual function主要是为了再不完全了解细节的情况下也能正确处理对象。另外,virtual函数是在不同类型的对象产生不同的动作,现在对象还没有产生,如何使用virtual函数来完成你想完成的动作。
直接的讲,C++中基类采用virtual虚析构函数是为了防止内存泄漏。
具体地说,如果派生类中申请了内存空间,并在其析构函数中对这些内存空间进行释放。假设基类中采用的是非虚析构函数,当删除基类指针指向的派生类对象时就不会触发动态绑定,因而只会调用基类的析构函数,而不会调用派生类的析构函数。那么在这种情况下,派生类中申请的空间就得不到释放从而产生内存泄漏。
所以,为了防止这种情况的发生,C++中基类的析构函数应采用virtual虚析构函数。
76、析构函数的作用,如何起作用?
- 构造函数只是起初始化值的作用,但实例化一个对象的时候,可以通过实例去传递参数,从主函数传递到其他的函数里面,这样就使其他的函数里面有值了。
规则,只要你一实例化对象,系统自动回调用一个构造函数就是你不写,编译器也自动调用一次。
- 析构函数与构造函数的作用相反,用于撤销对象的一些特殊任务处理,可以是释放对象分配的内存空间;特点:析构函数与构造函数同名,但该函数前面加~。
析构函数没有参数,也没有返回值,而且不能重载,在一个类中只能有一个析构函数。 当撤销对象时,编译器也会自动调用析构函数。
每一个类必须有一个析构函数,用户可以自定义析构函数,也可以是编译器自动生成默认的析构函数。一般析构函数定义为类的公有成员。
77、构造函数和析构函数可以调用虚函数吗,为什么
-
在C++中,提倡不在构造函数和析构函数中调用虚函数;
-
构造函数和析构函数调用虚函数时都不使用动态联编,如果在构造函数或析构函数中调用虚函数,则运行的是为构造函数或析构函数自身类型定义的版本;
-
因为父类对象会在子类之前进行构造,此时子类部分的数据成员还未初始化,因此调用子类的虚函数时不安全的,故而C++不会进行动态联编;
-
析构函数是用来销毁一个对象的,在销毁一个对象时,先调用子类的析构函数,然后再调用基类的析构函数。所以在调用基类的析构函数时,派生类对象的数据成员已经销毁,这个时候再调用子类的虚函数没有任何意义。
78、构造函数、析构函数的执行顺序?构造函数和拷贝构造的内部都干了啥?
1) 构造函数顺序
① 基类构造函数。如果有多个基类,则构造函数的调用顺序是某类在类派生表中出现的顺序,而不是它们在成员初始化表中的顺序。
② 成员类对象构造函数。如果有多个成员类对象则构造函数的调用顺序是对象在类中被声明的顺序,而不是它们出现在成员初始化表中的顺序。
③ 派生类构造函数。
2) 析构函数顺序
① 调用派生类的析构函数;
② 调用成员类对象的析构函数;
③ 调用基类的析构函数。
79、虚析构函数的作用,父类的析构函数是否要设置为虚函数?
- C++中基类采用virtual虚析构函数是为了防止内存泄漏。
具体地说,如果派生类中申请了内存空间,并在其析构函数中对这些内存空间进行释放。
假设基类中采用的是非虚析构函数,当删除基类指针指向的派生类对象时就不会触发动态绑定,因而只会调用基类的析构函数,而不会调用派生类的析构函数。
那么在这种情况下,派生类中申请的空间就得不到释放从而产生内存泄漏。
所以,为了防止这种情况的发生,C++中基类的析构函数应采用virtual虚析构函数。
- 纯虚析构函数一定得定义,因为每一个派生类析构函数会被编译器加以扩张,以静态调用的方式调用其每一个虚基类以及上一层基类的析构函数。
因此,缺乏任何一个基类析构函数的定义,就会导致链接失败,最好不要把虚析构函数定义为纯虚析构函数。
80、构造函数析构函数可否抛出异常
- C++只会析构已经完成的对象,对象只有在其构造函数执行完毕才算是完全构造妥当。在构造函数中发生异常,控制权转出构造函数之外。
因此,在对象b的构造函数中发生异常,对象b的析构函数不会被调用。因此会造成内存泄漏。
-
用auto_ptr对象来取代指针类成员,便对构造函数做了强化,免除了抛出异常时发生资源泄漏的危机,不再需要在析构函数中手动释放资源;
-
如果控制权基于异常的因素离开析构函数,而此时正有另一个异常处于作用状态,C++会调用terminate函数让程序结束;
-
如果异常从析构函数抛出,而且没有在当地进行捕捉,那个析构函数便是执行不全的。如果析构函数执行不全,就是没有完成他应该执行的每一件事情。
81、构造函数一般不定义为虚函数的原因
(1)创建一个对象时需要确定对象的类型,而虚函数是在运行时动态确定其类型的。在构造一个对象时,由于对象还未创建成功,编译器无法知道对象的实际类型
(2)虚函数的调用需要虚函数表指针vptr,而该指针存放在对象的内存空间中,若构造函数声明为虚函数,那么由于对象还未创建,还没有内存空间,更没有虚函数表vtable地址用来调用虚构造函数了
(3)虚函数的作用在于通过父类的指针或者引用调用它的时候能够变成调用子类的那个成员函数。而构造函数是在创建对象时自动调用的,不可能通过父类或者引用去调用,因此就规定构造函数不能是虚函数
(4)析构函数一般都要声明为虚函数,这个应该是老生常谈了,这里不再赘述
《为什么C++不能有虚构造函数,却可以有虚析构函数》:https://dwz.cn/lnfW9H6m
82、类什么时候会析构?
-
对象生命周期结束,被销毁时;
-
delete指向对象的指针时,或delete指向对象的基类类型指针,而其基类虚构函数是虚函数时;
-
对象i是对象o的成员,o的析构函数被调用时,对象i的析构函数也被调用。
83、构造函数或者析构函数中可以调用虚函数吗
简要结论:
- 从语法上讲,调用完全没有问题。
- 但是从效果上看,往往不能达到需要的目的。
《Effective C++》的解释是: 派生类对象构造期间进入基类的构造函数时,对象类型变成了基类类型,而不是派生类类型。 同样,进入基类析构函数时,对象也是基类类型。
举个例子:
#include<iostream>
using namespace std;
class Base
{
public:
Base()
{
Function();
}
virtual void Function()
{
cout << "Base::Fuction" << endl;
}
~Base()
{
Function();
}
};
class A : public Base
{
public:
A()
{
Function();
}
virtual void Function()
{
cout << "A::Function" << endl;
}
~A()
{
Function();
}
};
int main()
{
Base* a = new Base;
delete a;
cout << "-------------------------" <<endl;
Base* b = new A;//语句1
delete b;
}
//输出结果
//Base::Fuction
//Base::Fuction
//-------------------------
//Base::Fuction
//A::Function
//Base::Fuction
语句1讲道理应该体现多态性,执行类A中的构造和析构函数,从实验结果来看,语句1并没有体现,执行流程是先构造基类,所以先调用基类的构造函数,构造完成再执行A自己的构造函数,析构时也是调用基类的析构函数,也就是说构造和析构中调用虚函数并不能达到目的,应该避免
《构造函数或者析构函数中调用虚函数会怎么样?》:https://dwz.cn/TaJTJONX
84、智能指针的原理、常用的智能指针及实现
原理
智能指针是一个类,用来存储指向动态分配对象的指针,负责自动释放动态分配的对象,防止堆内存泄漏。动态分配的资源,交给一个类对象去管理,当类对象声明周期结束时,自动调用析构函数释放资源
常用的智能指针
(1) shared_ptr
实现原理:采用引用计数器的方法,允许多个智能指针指向同一个对象,每当多一个指针指向该对象时,指向该对象的所有智能指针内部的引用计数加1,每当减少一个智能指针指向对象时,引用计数会减1,当计数为0的时候会自动的释放动态分配的资源。
- 智能指针将一个计数器与类指向的对象相关联,引用计数器跟踪共有多少个类对象共享同一指针
- 每次创建类的新对象时,初始化指针并将引用计数置为1
- 当对象作为另一对象的副本而创建时,拷贝构造函数拷贝指针并增加与之相应的引用计数
- 对一个对象进行赋值时,赋值操作符减少左操作数所指对象的引用计数(如果引用计数为减至0,则删除对象),并增加右操作数所指对象的引用计数
- 调用析构函数时,构造函数减少引用计数(如果引用计数减至0,则删除基础对象)
(2) unique_ptr
unique_ptr采用的是独享所有权语义,一个非空的unique_ptr总是拥有它所指向的资源。转移一个unique_ptr将会把所有权全部从源指针转移给目标指针,源指针被置空;所以unique_ptr不支持普通的拷贝和赋值操作,不能用在STL标准容器中;局部变量的返回值除外(因为编译器知道要返回的对象将要被销毁);如果你拷贝一个unique_ptr,那么拷贝结束后,这两个unique_ptr都会指向相同的资源,造成在结束时对同一内存指针多次释放而导致程序崩溃。
(3) weak_ptr
weak_ptr:弱引用。 引用计数有一个问题就是互相引用形成环(环形引用),这样两个指针指向的内存都无法释放。需要使用weak_ptr打破环形引用。weak_ptr是一个弱引用,它是为了配合shared_ptr而引入的一种智能指针,它指向一个由shared_ptr管理的对象而不影响所指对象的生命周期,也就是说,它只引用,不计数。如果一块内存被shared_ptr和weak_ptr同时引用,当所有shared_ptr析构了之后,不管还有没有weak_ptr引用该内存,内存也会被释放。所以weak_ptr不保证它指向的内存一定是有效的,在使用之前使用函数lock()检查weak_ptr是否为空指针。
(4) auto_ptr
主要是为了解决“有异常抛出时发生内存泄漏”的问题 。因为发生异常而无法正常释放内存。
auto_ptr有拷贝语义,拷贝后源对象变得无效,这可能引发很严重的问题;而unique_ptr则无拷贝语义,但提供了移动语义,这样的错误不再可能发生,因为很明显必须使用std::move()进行转移。
auto_ptr不支持拷贝和赋值操作,不能用在STL标准容器中。STL容器中的元素经常要支持拷贝、赋值操作,在这过程中auto_ptr会传递所有权,所以不能在STL中使用。
智能指针shared_ptr代码实现:
template<typename T>
class SharedPtr
{
public:
SharedPtr(T* ptr = NULL):_ptr(ptr), _pcount(new int(1))
{}
SharedPtr(const SharedPtr& s):_ptr(s._ptr), _pcount(s._pcount){
*(_pcount)++;
}
SharedPtr<T>& operator=(const SharedPtr& s){
if (this != &s)
{
if (--(*(this->_pcount)) == 0)
{
delete this->_ptr;
delete this->_pcount;
}
_ptr = s._ptr;
_pcount = s._pcount;
*(_pcount)++;
}
return *this;
}
T& operator*()
{
return *(this->_ptr);
}
T* operator->()
{
return this->_ptr;
}
~SharedPtr()
{
--(*(this->_pcount));
if (this->_pcount == 0)
{
delete _ptr;
_ptr = NULL;
delete _pcount;
_pcount = NULL;
}
}
private:
T* _ptr;
int* _pcount;//指向引用计数的指针
};
《智能指针的原理及实现》:https://blog.csdn.net/lizhentao0707/article/details/81156384
85、构造函数的几种关键字
default
default关键字可以显式要求编译器生成合成构造函数,防止在调用时相关构造函数类型没有定义而报错
#include <iostream>
using namespace std;
class CString
{
public:
CString() = default; //语句1
//构造函数
CString(const char* pstr) : _str(pstr){}
void* operator new() = delete;//这样不允许使用new关键字
//析构函数
~CString(){}
public:
string _str;
};
int main()
{
auto a = new CString(); //语句2
cout << "Hello World" <<endl;
return 0;
}
//运行结果
//Hello World
如果没有加语句1,语句2会报错,表示找不到参数为空的构造函数,将其设置为default可以解决这个问题
delete
delete关键字可以删除构造函数、赋值运算符函数等,这样在使用的时候会得到友善的提示
#include <iostream>
using namespace std;
class CString
{
public:
void* operator new() = delete;//这样不允许使用new关键字
//析构函数
~CString(){}
};
int main()
{
auto a = new CString(); //语句1
cout << "Hello World" <<endl;
return 0;
}
在执行语句1时,会提示new方法已经被删除,如果将new设置为私有方法,则会报惨不忍睹的错误,因此使用delete关键字可以更加人性化的删除一些默认方法
0
将虚函数定义为纯虚函数(纯虚函数无需定义,= 0只能出现在类内部虚函数的声明语句处;当然,也可以为纯虚函数提供定义,不过函数体必须定义在类的外部)
《C++构造函数的default和delete》:https://blog.csdn.net/u010591680/article/details/71101737
86、C++的四种强制转换reinterpret_cast/const_cast/static_cast /dynamic_cast
reinterpret_cast
reinterpret_cast (expression)
type-id 必须是一个指针、引用、算术类型、函数指针或者成员指针。它可以用于类型之间进行强制转换。
const_cast
const_cast<type_id> (expression)
该运算符用来修改类型的const或volatile属性。除了const 或volatile修饰之外, type_id和expression的类型是一样的。用法如下:
-
常量指针被转化成非常量的指针,并且仍然指向原来的对象
-
常量引用被转换成非常量的引用,并且仍然指向原来的对象
-
const_cast一般用于修改底指针。如const char *p形式
static_cast
static_cast < type-id > (expression)
该运算符把expression转换为type-id类型,但没有运行时类型检查来保证转换的安全性。它主要有如下几种用法:
-
用于类层次结构中基类(父类)和派生类(子类)之间指针或引用引用的转换
-
进行上行转换(把派生类的指针或引用转换成基类表示)是安全的
-
进行下行转换(把基类指针或引用转换成派生类表示)时,由于没有动态类型检查,所以是不安全的
-
-
用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。这种转换的安全性也要开发人员来保证。
-
把空指针转换成目标类型的空指针
-
把任何类型的表达式转换成void类型
注意:static_cast不能转换掉expression的const、volatile、或者__unaligned属性。
dynamic_cast
有类型检查,基类向派生类转换比较安全,但是派生类向基类转换则不太安全
dynamic_cast (expression)
该运算符把expression转换成type-id类型的对象。type-id 必须是类的指针、类的引用或者void*
如果 type-id 是类指针类型,那么expression也必须是一个指针,如果 type-id 是一个引用,那么 expression 也必须是一个引用
dynamic_cast运算符可以在执行期决定真正的类型,也就是说expression必须是多态类型。如果下行转换是安全的(也就说,如果基类指针或者引用确实指向一个派生类对象)这个运算符会传回适当转型过的指针。如果 如果下行转换不安全,这个运算符会传回空指针(也就是说,基类指针或者引用没有指向一个派生类对象)
dynamic_cast主要用于类层次间的上行转换和下行转换,还可以用于类之间的交叉转换
在类层次间进行上行转换时,dynamic_cast和static_cast的效果是一样的
在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全
举个例子:
#include <bits/stdc++.h>
using namespace std;
class Base
{
public:
Base() :b(1) {}
virtual void fun() {};
int b;
};
class Son : public Base
{
public:
Son() :d(2) {}
int d;
};
int main()
{
int n = 97;
//reinterpret_cast
int *p = &n;
//以下两者效果相同
char *c = reinterpret_cast<char*> (p);
char *c2 = (char*)(p);
cout << "reinterpret_cast输出:"<< *c2 << endl;
//const_cast
const int *p2 = &n;
int *p3 = const_cast<int*>(p2);
*p3 = 100;
cout << "const_cast输出:" << *p3 << endl;
Base* b1 = new Son;
Base* b2 = new Base;
//static_cast
Son* s1 = static_cast<Son*>(b1); //同类型转换
Son* s2 = static_cast<Son*>(b2); //下行转换,不安全
cout << "static_cast输出:"<< endl;
cout << s1->d << endl;
cout << s2->d << endl; //下行转换,原先父对象没有d成员,输出垃圾值
//dynamic_cast
Son* s3 = dynamic_cast<Son*>(b1); //同类型转换
Son* s4 = dynamic_cast<Son*>(b2); //下行转换,安全
cout << "dynamic_cast输出:" << endl;
cout << s3->d << endl;
if(s4 == nullptr)
cout << "s4指针为nullptr" << endl;
else
cout << s4->d << endl;
return 0;
}
//输出结果
//reinterpret_cast输出:a
//const_cast输出:100
//static_cast输出:
//2
//-33686019
//dynamic_cast输出:
//2
//s4指针为nullptr
从输出结果可以看出,在进行下行转换时,dynamic_cast安全的,如果下行转换不安全的话其会返回空指针,这样在进行操作的时候可以预先判断。而使用static_cast下行转换存在不安全的情况也可以转换成功,但是直接使用转换后的对象进行操作容易造成错误。
87、C++函数调用的压栈过程
从代码入手,解释这个过程:
#include <iostream>
using namespace std;
int f(int n)
{
cout << n << endl;
return n;
}
void func(int param1, int param2)
{
int var1 = param1;
int var2 = param2;
printf("var1=%d,var2=%d", f(var1), f(var2));//如果将printf换为cout进行输出,输出结果则刚好相反
}
int main(int argc, char* argv[])
{
func(1, 2);
return 0;
}
//输出结果
//2
//1
//var1=1,var2=2
当函数从入口函数main函数开始执行时,编译器会将我们操作系统的运行状态,main函数的返回地址、main的参数、mian函数中的变量、进行依次压栈;
当main函数开始调用func()函数时,编译器此时会将main函数的运行状态进行压栈,再将func()函数的返回地址、func()函数的参数从右到左、func()定义变量依次压栈;
当func()调用f()的时候,编译器此时会将func()函数的运行状态进行压栈,再将的返回地址、f()函数的参数从右到左、f()定义变量依次压栈
从代码的输出结果可以看出,函数f(var1)、f(var2)依次入栈,而后先执行f(var2),再执行f(var1),最后打印整个字符串,将栈中的变量依次弹出,最后主函数返回。
《C/C++函数调用过程分析》:https://www.cnblogs.com/biyeymyhjob/archive/2012/07/20/2601204.html
《C/C++函数调用的压栈模型》:https://blog.csdn.net/m0_37717595/article/details/80368411
88、说说移动构造函数
-
我们用对象a初始化对象b,后对象a我们就不在使用了,但是对象a的空间还在呀(在析构之前),既然拷贝构造函数,实际上就是把a对象的内容复制一份到b中,那么为什么我们不能直接使用a的空间呢?这样就避免了新的空间的分配,大大降低了构造的成本。这就是移动构造函数设计的初衷;
-
拷贝构造函数中,对于指针,我们一定要采用深层复制,而移动构造函数中,对于指针,我们采用浅层复制。浅层复制之所以危险,是因为两个指针共同指向一片内存空间,若第一个指针将其释放,另一个指针的指向就不合法了。
所以我们只要避免第一个指针释放空间就可以了。避免的方法就是将第一个指针(比如a->value)置为NULL,这样在调用析构函数的时候,由于有判断是否为NULL的语句,所以析构a的时候并不会回收a->value指向的空间;
- 移动构造函数的参数和拷贝构造函数不同,拷贝构造函数的参数是一个左值引用,但是移动构造函数的初值是一个右值引用。意味着,移动构造函数的参数是一个右值或者将亡值的引用。也就是说,只用用一个右值,或者将亡值初始化另一个对象的时候,才会调用移动构造函数。而那个move语句,就是将一个左值变成一个将亡值。
89、C++中将临时变量作为返回值时的处理过程
首先需要明白一件事情,临时变量,在函数调用过程中是被压到程序进程的栈中的,当函数退出时,临时变量出栈,即临时变量已经被销毁,临时变量占用的内存空间没有被清空,但是可以被分配给其他变量,所以有可能在函数退出时,该内存已经被修改了,对于临时变量来说已经是没有意义的值了
C语言里规定:16bit程序中,返回值保存在ax寄存器中,32bit程序中,返回值保持在eax寄存器中,如果是64bit返回值,edx寄存器保存高32bit,eax寄存器保存低32bit
由此可见,函数调用结束后,返回值被临时存储到寄存器中,并没有放到堆或栈中,也就是说与内存没有关系了。当退出函数的时候,临时变量可能被销毁,但是返回值却被放到寄存器中与临时变量的生命周期没有关系
如果我们需要返回值,一般使用赋值语句就可以了
《【C++】临时变量不能作为函数的返回值?》:https://www.wandouip.com/t5i204349/
(栈上的内存分配、拷贝过程)
90、关于this指针你知道什么?全说出来
-
this指针是类的指针,指向对象的首地址。
-
this指针只能在成员函数中使用,在全局函数、静态成员函数中都不能用this。
-
this指针只有在成员函数中才有定义,且存储位置会因编译器不同有不同存储位置。
this指针的用处
一个对象的this指针并不是对象本身的一部分,不会影响sizeof(对象)的结果。this作用域是在类内部,当在类的非静态成员函数中访问类的非静态成员的时候(全局函数,静态函数中不能使用this指针),编译器会自动将对象本身的地址作为一个隐含参数传递给函数。也就是说,即使你没有写上this指针,编译器在编译的时候也是加上this的,它作为非静态成员函数的隐含形参,对各成员的访问均通过this进行
this指针的使用
一种情况就是,在类的非静态成员函数中返回类对象本身的时候,直接使用 return *this;
另外一种情况是当形参数与成员变量名相同时用于区分,如this->n = n (不能写成n = n)
类的this指针有以下特点
(1)this只能在成员函数中使用,全局函数、静态函数都不能使用this。实际上,成员函数默认第一个参数为T * const this
如:
class A{
public:
int func(int p){}
};
其中,func的原型在编译器看来应该是:
int func(A * const this,int p);
(2)由此可见,this在成员函数的开始前构造,在成员函数的结束后清除。这个生命周期同任何一个函数的参数是一样的,没有任何区别。当调用一个类的成员函数时,编译器将类的指针作为函数的this参数传递进去。如:
A a;
a.func(10);
//此处,编译器将会编译成:
A::func(&a,10);
看起来和静态函数没差别,对吗?不过,区别还是有的。编译器通常会对this指针做一些优化,因此,this指针的传递效率比较高,例如VC通常是通过ecx(计数寄存器)传递this参数的。
91、几个this指针的易混问题
A. this指针是什么时候创建的?
this在成员函数的开始执行前构造,在成员的执行结束后清除。
但是如果class或者struct里面没有方法的话,它们是没有构造函数的,只能当做C的struct使用。采用TYPE xx的方式定义的话,在栈里分配内存,这时候this指针的值就是这块内存的地址。采用new的方式创建对象的话,在堆里分配内存,new操作符通过eax(累加寄存器)返回分配的地址,然后设置给指针变量。之后去调用构造函数(如果有构造函数的话),这时将这个内存块的地址传给ecx,之后构造函数里面怎么处理请看上面的回答
B. this指针存放在何处?堆、栈、全局变量,还是其他?
this指针会因编译器不同而有不同的放置位置。可能是栈,也可能是寄存器,甚至全局变量。在汇编级别里面,一个值只会以3种形式出现:立即数、寄存器值和内存变量值。不是存放在寄存器就是存放在内存中,它们并不是和高级语言变量对应的。
C. this指针是如何传递类中的函数的?绑定?还是在函数参数的首参数就是this指针?那么,this指针又是如何找到“类实例后函数的”?
大多数编译器通过ecx(寄数寄存器)寄存器传递this指针。事实上,这也是一个潜规则。一般来说,不同编译器都会遵从一致的传参规则,否则不同编译器产生的obj就无法匹配了。
在call之前,编译器会把对应的对象地址放到eax中。this是通过函数参数的首参来传递的。this指针在调用之前生成,至于“类实例后函数”,没有这个说法。类在实例化时,只分配类中的变量空间,并没有为函数分配空间。自从类的函数定义完成后,它就在那儿,不会跑的
D. this指针是如何访问类中的变量的?
如果不是类,而是结构体的话,那么,如何通过结构指针来访问结构中的变量呢?如果你明白这一点的话,就很容易理解这个问题了。
在C++中,类和结构是只有一个区别的:类的成员默认是private,而结构是public。
this是类的指针,如果换成结构体,那this就是结构的指针了。
E.我们只有获得一个对象后,才能通过对象使用this指针。如果我们知道一个对象this指针的位置,可以直接使用吗?
**this指针只有在成员函数中才有定义。**因此,你获得一个对象后,也不能通过对象使用this指针。所以,我们无法知道一个对象的this指针的位置(只有在成员函数里才有this指针的位置)。当然,在成员函数里,你是可以知道this指针的位置的(可以通过&this获得),也可以直接使用它。
F.每个类编译后,是否创建一个类中函数表保存函数指针,以便用来调用函数?
普通的类函数(不论是成员函数,还是静态函数)都不会创建一个函数表来保存函数指针。只有虚函数才会被放到函数表中。但是,即使是虚函数,如果编译期就能明确知道调用的是哪个函数,编译器就不会通过函数表中的指针来间接调用,而是会直接调用该函数。正是由于this指针的存在,用来指向不同的对象,从而确保不同对象之间调用相同的函数可以互不干扰
《C++中this指针的用法详解》http://blog.chinaunix.net/uid-21411227-id-1826942.html
92、构造函数、拷贝构造函数和赋值操作符的区别
构造函数
对象不存在,没用别的对象初始化,在创建一个新的对象时调用构造函数
拷贝构造函数
对象不存在,但是使用别的已经存在的对象来进行初始化
赋值运算符
对象存在,用别的对象给它赋值,这属于重载“=”号运算符的范畴,“=”号两侧的对象都是已存在的
举个例子:
#include <iostream>
using namespace std;
class A
{
public:
A()
{
cout << "我是构造函数" << endl;
}
A(const A& a)
{
cout << "我是拷贝构造函数" << endl;
}
A& operator = (A& a)
{
cout << "我是赋值操作符" << endl;
return *this;
}
~A() {};
};
int main()
{
A a1; //调用构造函数
A a2 = a1; //调用拷贝构造函数
a2 = a1; //调用赋值操作符
return 0;
}
//输出结果
//我是构造函数
//我是拷贝构造函数
//我是赋值操作符
93、拷贝构造函数和赋值运算符重载的区别?
-
拷贝构造函数是函数,赋值运算符是运算符重载。
-
拷贝构造函数会生成新的类对象,赋值运算符不能。
-
拷贝构造函数是直接构造一个新的类对象,所以在初始化对象前不需要检查源对象和新建对象是否相同;赋值运算符需要上述操作并提供两套不同的复制策略,另外赋值运算符中如果原来的对象有内存分配则需要先把内存释放掉。
-
形参传递是调用拷贝构造函数(调用的被赋值对象的拷贝构造函数),但并不是所有出现"="的地方都是使用赋值运算符,如下:
Student s; Student s1 = s; // 调用拷贝构造函数 Student s2; s2 = s; // 赋值运算符操作
注:类中有指针变量时要重写析构函数、拷贝构造函数和赋值运算符
94、智能指针的作用;
-
C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。
-
智能指针在C++11版本之后提供,包含在头文件中,shared_ptr、unique_ptr、weak_ptr。shared_ptr多个指针指向相同的对象。shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,自动删除所指向的堆内存。shared_ptr内部的引用计数是线程安全的,但是对象的读取需要加锁。
-
初始化。智能指针是个模板类,可以指定类型,传入指针通过构造函数初始化。也可以使用make_shared函数初始化。不能将指针直接赋值给一个智能指针,一个是类,一个是指针。例如std::shared_ptr p4 = new int(1);的写法是错误的
拷贝和赋值。拷贝使得对象的引用计数增加1,赋值使得原对象引用计数减1,当计数为0时,自动释放内存。后来指向的对象引用计数加1,指向后来的对象
-
unique_ptr“唯一”拥有其所指对象,同一时刻只能有一个unique_ptr指向给定对象(通过禁止拷贝语义、只有移动语义来实现)。相比与原始指针unique_ptr用于其RAII的特性,使得在出现异常的情况下,动态资源能得到释放。unique_ptr指针本身的生命周期:从unique_ptr指针创建时开始,直到离开作用域。离开作用域时,若其指向对象,则将其所指对象销毁(默认使用delete操作符,用户可指定其他操作)。unique_ptr指针与其所指对象的关系:在智能指针生命周期内,可以改变智能指针所指对象,如创建智能指针时通过构造函数指定、通过reset方法重新指定、通过release方法释放所有权、通过移动语义转移所有权。
-
智能指针类将一个计数器与类指向的对象相关联,引用计数跟踪该类有多少个对象共享同一指针。每次创建类的新对象时,初始化指针并将引用计数置为1;当对象作为另一对象的副本而创建时,拷贝构造函数拷贝指针并增加与之相应的引用计数;对一个对象进行赋值时,赋值操作符减少左操作数所指对象的引用计数(如果引用计数为减至0,则删除对象),并增加右操作数所指对象的引用计数;调用析构函数时,构造函数减少引用计数(如果引用计数减至0,则删除基础对象)。
-
weak_ptr 是一种不控制对象生命周期的智能指针, 它指向一个 shared_ptr 管理的对象. 进行该对象的内存管理的是那个强引用的 shared_ptr. weak_ptr只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作, 它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少.
95、说说你了解的auto_ptr作用
-
auto_ptr的出现,主要是为了解决“有异常抛出时发生内存泄漏”的问题;抛出异常,将导致指针p所指向的空间得不到释放而导致内存泄漏;
-
auto_ptr构造时取得某个对象的控制权,在析构时释放该对象。我们实际上是创建一个auto_ptr类型的局部对象,该局部对象析构时,会将自身所拥有的指针空间释放,所以不会有内存泄漏;
-
auto_ptr的构造函数是explicit,阻止了一般指针隐式转换为 auto_ptr的构造,所以不能直接将一般类型的指针赋值给auto_ptr类型的对象,必须用auto_ptr的构造函数创建对象;
-
由于auto_ptr对象析构时会删除它所拥有的指针,所以使用时避免多个auto_ptr对象管理同一个指针;
-
Auto_ptr内部实现,析构函数中删除对象用的是delete而不是delete[],所以auto_ptr不能管理数组;
-
auto_ptr支持所拥有的指针类型之间的隐式类型转换。
-
可以通过*和->运算符对auto_ptr所有用的指针进行提领操作;
-
T* get(),获得auto_ptr所拥有的指针;T* release(),释放auto_ptr的所有权,并将所有用的指针返回。
96、智能指针的循环引用
循环引用是指使用多个智能指针share_ptr时,出现了指针之间相互指向,从而形成环的情况,有点类似于死锁的情况,这种情况下,智能指针往往不能正常调用对象的析构函数,从而造成内存泄漏。举个例子:
#include <iostream>
using namespace std;
template <typename T>
class Node
{
public:
Node(const T& value)
:_pPre(NULL)
, _pNext(NULL)
, _value(value)
{
cout << "Node()" << endl;
}
~Node()
{
cout << "~Node()" << endl;
cout << "this:" << this << endl;
}
shared_ptr<Node<T>> _pPre;
shared_ptr<Node<T>> _pNext;
T _value;
};
void Funtest()
{
shared_ptr<Node<int>> sp1(new Node<int>(1));
shared_ptr<Node<int>> sp2(new Node<int>(2));
cout << "sp1.use_count:" << sp1.use_count() << endl;
cout << "sp2.use_count:" << sp2.use_count() << endl;
sp1->_pNext = sp2; //sp1的引用+1
sp2->_pPre = sp1; //sp2的引用+1
cout << "sp1.use_count:" << sp1.use_count() << endl;
cout << "sp2.use_count:" << sp2.use_count() << endl;
}
int main()
{
Funtest();
system("pause");
return 0;
}
//输出结果
//Node()
//Node()
//sp1.use_count:1
//sp2.use_count:1
//sp1.use_count:2
//sp2.use_count:2
从上面shared_ptr的实现中我们知道了只有当引用计数减减之后等于0,析构时才会释放对象,而上述情况造成了一个僵局,那就是析构对象时先析构sp2,可是由于sp2的空间sp1还在使用中,所以sp2.use_count减减之后为1,不释放,sp1也是相同的道理,由于sp1的空间sp2还在使用中,所以sp1.use_count减减之后为1,也不释放。sp1等着sp2先释放,sp2等着sp1先释放,二者互不相让,导致最终都没能释放,内存泄漏。
在实际编程过程中,应该尽量避免出现智能指针之前相互指向的情况,如果不可避免,可以使用使用弱指针——weak_ptr,它不增加引用计数,只要出了作用域就会自动析构。
《C++ 智能指针(及循环引用问题)》:https://blog.csdn.net/m0_37968340/article/details/76737395
97、什么是虚拟继承
由于C++支持多继承,除了public、protected和private三种继承方式外,还支持虚拟(virtual)继承,举个例子:
#include <iostream>
using namespace std;
class A{}
class B : virtual public A{};
class C : virtual public A{};
class D : public B, public C{};
int main()
{
cout << "sizeof(A):" << sizeof A <<endl; // 1,空对象,只有一个占位
cout << "sizeof(B):" << sizeof B <<endl; // 4,一个bptr指针,省去占位,不需要对齐
cout << "sizeof(C):" << sizeof C <<endl; // 4,一个bptr指针,省去占位,不需要对齐
cout << "sizeof(D):" << sizeof D <<endl; // 8,两个bptr,省去占位,不需要对齐
}
上述代码所体现的关系是,B和C虚拟继承A,D又公有继承B和C,这种方式是一种菱形继承或者钻石继承,可以用如下图来表示


**虚拟继承的情况下,无论基类被继承多少次,只会存在一个实体。**虚拟继承基类的子类中,子类会增加某种形式的指针,或者指向虚基类子对象,或者指向一个相关的表格;表格中存放的不是虚基类子对象的地址,就是其偏移量,此类指针被称为bptr,如上图所示。如果既存在vptr又存在bptr,某些编译器会将其优化,合并为一个指针
98、如何获得结构成员相对于结构开头的字节偏移量
使用<stddef.h>头文件中的,offsetof宏。
举个例子:
#include <iostream>
#include <stddef.h>
using namespace std;
struct S
{
int x;
char y;
int z;
double a;
};
int main()
{
cout << offsetof(S, x) << endl; // 0
cout << offsetof(S, y) << endl; // 4
cout << offsetof(S, z) << endl; // 8
cout << offsetof(S, a) << endl; // 12
return 0;
}
在VS2019 + win下 并不是这样的
cout << offsetof(S, x) << endl; // 0
cout << offsetof(S, y) << endl; // 4
cout << offsetof(S, z) << endl; // 8
cout << offsetof(S, a) << endl; // 16 这里是 16的位置,因为 double是8字节,需要找一个8的倍数对齐,
当然了,如果加上 #pragma pack(4)指定 4字节对齐就可以了
#pragma pack(4)
struct S
{
int x;
char y;
int z;
double a;
};
void test02()
{
cout << offsetof(S, x) << endl; // 0
cout << offsetof(S, y) << endl; // 4
cout << offsetof(S, z) << endl; // 8
cout << offsetof(S, a) << endl; // 12
}
S结构体中各个数据成员的内存空间划分如下所示,需要注意内存对齐

99、静态类型和动态类型,静态绑定和动态绑定的介绍
- 静态类型:对象在声明时采用的类型,在编译期既已确定;
- 动态类型:通常是指一个指针或引用目前所指对象的类型,是在运行期决定的;
- 静态绑定:绑定的是静态类型,所对应的函数或属性依赖于对象的静态类型,发生在编译期;
- 动态绑定:绑定的是动态类型,所对应的函数或属性依赖于对象的动态类型,发生在运行期;
从上面的定义也可以看出,非虚函数一般都是静态绑定,而虚函数都是动态绑定(如此才可实现多态性)。 举个例子:
#include <iostream>
using namespace std;
class A
{
public:
/*virtual*/ void func() { std::cout << "A::func()\n"; }
};
class B : public A
{
public:
void func() { std::cout << "B::func()\n"; }
};
class C : public A
{
public:
void func() { std::cout << "C::func()\n"; }
};
int main()
{
C* pc = new C(); //pc的静态类型是它声明的类型C*,动态类型也是C*;
B* pb = new B(); //pb的静态类型和动态类型也都是B*;
A* pa = pc; //pa的静态类型是它声明的类型A*,动态类型是pa所指向的对象pc的类型C*;
pa = pb; //pa的动态类型可以更改,现在它的动态类型是B*,但其静态类型仍是声明时候的A*;
C *pnull = NULL; //pnull的静态类型是它声明的类型C*,没有动态类型,因为它指向了NULL;
pa->func(); //A::func() pa的静态类型永远都是A*,不管其指向的是哪个子类,都是直接调用A::func();
pc->func(); //C::func() pc的动、静态类型都是C*,因此调用C::func();
pnull->func(); //C::func() 不用奇怪为什么空指针也可以调用函数,因为这在编译期就确定了,和指针空不空没关系;
return 0;
}
如果将A类中的virtual注释去掉,则运行结果是:
pa->func(); //B::func() 因为有了virtual虚函数特性,pa的动态类型指向B*,因此先在B中查找,找到后直接调用;
pc->func(); //C::func() pc的动、静态类型都是C*,因此也是先在C中查找;
pnull->func(); //空指针异常,因为是func是virtual函数,因此对func的调用只能等到运行期才能确定,然后才发现pnull是空指针;
在上面的例子中,
-
如果基类A中的func不是virtual函数,那么不论pa、pb、pc指向哪个子类对象,对func的调用都是在定义pa、pb、pc时的静态类型决定,早已在编译期确定了。
-
同样的空指针也能够直接调用no-virtual函数而不报错(这也说明一定要做空指针检查啊!),因此静态绑定不能实现多态;
-
如果func是虚函数,那所有的调用都要等到运行时根据其指向对象的类型才能确定,比起静态绑定自然是要有性能损失的,但是却能实现多态特性;
本文代码里都是针对指针的情况来分析的,但是对于引用的情况同样适用。
至此总结一下静态绑定和动态绑定的区别:
-
静态绑定发生在编译期,动态绑定发生在运行期;
-
对象的动态类型可以更改,但是静态类型无法更改;
-
要想实现动态,必须使用动态绑定;
-
在继承体系中只有虚函数使用的是动态绑定,其他的全部是静态绑定;
建议:
绝对不要重新定义继承而来的非虚(non-virtual)函数(《Effective C++ 第三版》条款36),因为这样导致函数调用由对象声明时的静态类型确定了,而和对象本身脱离了关系,没有多态,也这将给程序留下不可预知的隐患和莫名其妙的BUG;另外,在动态绑定也即在virtual函数中,要注意默认参数的使用。当缺省参数和virtual函数一起使用的时候一定要谨慎,不然出了问题怕是很难排查。 看下面的代码:
#include <iostream>
using namespace std;
class E
{
public:
virtual void func(int i = 0)
{
std::cout << "E::func()\t" << i << "\n";
}
};
class F : public E
{
public:
virtual void func(int i = 1)
{
std::cout << "F::func()\t" << i << "\n";
}
};
void test2()
{
F* pf = new F();
E* pe = pf;
pf->func(); //F::func() 1 正常,就该如此;
pe->func(); //F::func() 0 哇哦,这是什么情况,调用了子类的函数,却使用了基类中参数的默认值!
}
int main()
{
test2();
return 0;
}
《C++中的静态绑定和动态绑定》:https://www.cnblogs.com/lizhenghn/p/3657717.html
100、C++ 11有哪些新特性?
- nullptr替代 NULL
- 引入了 auto 和 decltype 这两个关键字实现了类型推导
- 基于范围的 for 循环for(auto& i : res){}
- 类和结构体的中初始化列表
- Lambda 表达式(匿名函数)
- std::forward_list(单向链表)
- 右值引用和move语义
- ...
101、引用是否能实现动态绑定,为什么可以实现?
可以。
引用在创建的时候必须初始化,在访问虚函数时,编译器会根据其所绑定的对象类型决定要调用哪个函数。注意只能调用虚函数。
举个例子:
#include <iostream>
using namespace std;
class Base
{
public:
virtual void fun()
{
cout << "base :: fun()" << endl;
}
};
class Son : public Base
{
public:
virtual void fun()
{
cout << "son :: fun()" << endl;
}
void func()
{
cout << "son :: not virtual function" <<endl;
}
};
int main()
{
Son s;
Base& b = s; // 基类类型引用绑定已经存在的Son对象,引用必须初始化
s.fun(); //son::fun()
b.fun(); //son :: fun()
return 0;
}
需要说明的是虚函数才具有动态绑定,上面代码中,Son类中还有一个非虚函数func(),这在b对象中是无法调用的,如果使用基类指针来指向子类也是一样的。
102、全局变量和局部变量有什么区别?
生命周期不同:全局变量随主程序创建和创建,随主程序销毁而销毁;局部变量在局部函数内部,甚至局部循环体等内部存在,退出就不存在;
使用方式不同:通过声明后全局变量在程序的各个部分都可以用到;局部变量分配在堆栈区,只能在局部使用。
操作系统和编译器通过内存分配的位置可以区分两者,全局变量分配在全局数据段并且在程序开始运行的时候被加载。局部变量则分配在堆栈里面 。
《C++经典面试题》:https://www.cnblogs.com/yjd_hycf_space/p/7495640.html
103、指针加减计算要注意什么?
指针加减本质是对其所指地址的移动,移动的步长跟指针的类型是有关系的,因此在涉及到指针加减运算需要十分小心,加多或者减多都会导致指针指向一块未知的内存地址,如果再进行操作就会很危险。
举个例子:
#include <iostream>
using namespace std;
int main()
{
int *a, *b, c;
a = (int*)0x500;
b = (int*)0x520;
c = b - a;
printf("%d\n", c); // 8
a += 0x020;
c = b - a;
printf("%d\n", c); // -24
return 0;
}
首先变量a和b都是以16进制的形式初始化,将它们转成10进制分别是1280(5*16^2=1280)和1312(5*16^2+2*16=1312), 那么它们的差值为32,也就是说a和b所指向的地址之间间隔32个位,但是考虑到是int类型占4位,所以c的值为32/4=8
a自增16进制0x20之后,其实际地址变为1280 + 2*16*4 = 1408,(因为一个int占4位,所以要乘4),这样它们的差值就变成了1312 - 1280 = -96,所以c的值就变成了-96/4 = -24
遇到指针的计算,需要明确的是指针每移动一位,它实际跨越的内存间隔是指针类型的长度,建议都转成10进制计算,计算结果除以类型长度取得结果
104、 怎样判断两个浮点数是否相等?
对两个浮点数判断大小和是否相等不能直接用==来判断,会出错!明明相等的两个数比较反而是不相等!对于两个浮点数比较只能通过相减并与预先设定的精度比较,记得要取绝对值!浮点数与0的比较也应该注意。与浮点数的表示方式有关。
105、方法调用的原理(栈,汇编)
-
机器用栈来传递过程参数、存储返回信息、保存寄存器用于以后恢复,以及本地存储。而为单个过程分配的那部分栈称为帧栈;帧栈可以认为是程序栈的一段,它有两个端点,一个标识起始地址,一个标识着结束地址,两个指针结束地址指针esp,开始地址指针ebp;
-
由一系列栈帧构成,这些栈帧对应一个过程,而且每一个栈指针+4的位置存储函数返回地址;每一个栈帧都建立在调用者的下方,当被调用者执行完毕时,这一段栈帧会被释放。由于栈帧是向地址递减的方向延伸,因此如果我们将栈指针减去一定的值,就相当于给栈帧分配了一定空间的内存。如果将栈指针加上一定的值,也就是向上移动,那么就相当于压缩了栈帧的长度,也就是说内存被释放了。
-
过程实现
① 备份原来的帧指针,调整当前的栈帧指针到栈指针位置;
② 建立起来的栈帧就是为被调用者准备的,当被调用者使用栈帧时,需要给临时变量分配预留内存;
③ 使用建立好的栈帧,比如读取和写入,一般使用mov,push以及pop指令等等。
④ 恢复被调用者寄存器当中的值,这一过程其实是从栈帧中将备份的值再恢复到寄存器,不过此时这些值可能已经不在栈顶了
⑤ 恢复被调用者寄存器当中的值,这一过程其实是从栈帧中将备份的值再恢复到寄存器,不过此时这些值可能已经不在栈顶了。
⑥ 释放被调用者的栈帧,释放就意味着将栈指针加大,而具体的做法一般是直接将栈指针指向帧指针,因此会采用类似下面的汇编代码处理。
⑦ 恢复调用者的栈帧,恢复其实就是调整栈帧两端,使得当前栈帧的区域又回到了原始的位置。
⑧ 弹出返回地址,跳出当前过程,继续执行调用者的代码。
- 过程调用和返回指令
① call指令
② leave指令
③ ret指令
106、C++中的指针参数传递和引用参数传递有什么区别?底层原理你知道吗?
1) 指针参数传递本质上是值传递,它所传递的是一个地址值。
值传递过程中,被调函数的形式参数作为被调函数的局部变量处理,会在栈中开辟内存空间以存放由主调函数传递进来的实参值,从而形成了实参的一个副本(替身)。
值传递的特点是,被调函数对形式参数的任何操作都是作为局部变量进行的,不会影响主调函数的实参变量的值(形参指针变了,实参指针不会变)。
2) 引用参数传递过程中,被调函数的形式参数也作为局部变量在栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。
被调函数对形参(本体)的任何操作都被处理成间接寻址,即通过栈中存放的地址访问主调函数中的实参变量(根据别名找到主调函数中的本体)。
因此,被调函数对形参的任何操作都会影响主调函数中的实参变量。
3) 引用传递和指针传递是不同的,虽然他们都是在被调函数栈空间上的一个局部变量,但是任何对于引用参数的处理都会通过一个间接寻址的方式操作到主调函数中的相关变量。
而对于指针传递的参数,如果改变被调函数中的指针地址,它将应用不到主调函数的相关变量。如果想通过指针参数传递来改变主调函数中的相关变量(地址),那就得使用指向指针的指针或者指针引用。
4) 从编译的角度来讲,程序在编译时分别将指针和引用添加到符号表上,符号表中记录的是变量名及变量所对应地址。
指针变量在符号表上对应的地址值为指针变量的地址值,而引用在符号表上对应的地址值为引用对象的地址值(与实参名字不同,地址相同)。
符号表生成之后就不会再改,因此指针可以改变其指向的对象(指针变量中的值可以改),而引用对象则不能修改。
107、类如何实现只能静态分配和只能动态分配
-
前者是把new、delete运算符重载为private属性。后者是把构造、析构函数设为protected属性,再用子类来动态创建
-
建立类的对象有两种方式:
① 静态建立,静态建立一个类对象,就是由编译器为对象在栈空间中分配内存;
② 动态建立,A *p = new A();动态建立一个类对象,就是使用new运算符为对象在堆空间中分配内存。这个过程分为两步,第一步执行operator new()函数,在堆中搜索一块内存并进行分配;第二步调用类构造函数构造对象;
- 只有使用new运算符,对象才会被建立在堆上,因此只要限制new运算符就可以实现类对象只能建立在栈上,可以将new运算符设为私有。
108、如果想将某个类用作基类,为什么该类必须定义而非声明?
派生类中包含并且可以使用它从基类继承而来的成员,为了使用这些成员,派生类必须知道他们是什么。
109、什么情况会自动生成默认构造函数?
- 带有默认构造函数的类成员对象,如果一个类没有任何构造函数,但它含有一个成员对象,而后者有默认构造函数,那么编译器就为该类合成出一个默认构造函数。
不过这个合成操作只有在构造函数真正被需要的时候才会发生;
如果一个类A含有多个成员类对象的话,那么类A的每一个构造函数必须调用每一个成员对象的默认构造函数而且必须按照类对象在类A中的声明顺序进行;
-
带有默认构造函数的基类,如果一个没有任务构造函数的派生类派生自一个带有默认构造函数基类,那么该派生类会合成一个构造函数调用上一层基类的默认构造函数;
-
带有一个虚函数的类
-
带有一个虚基类的类
-
合成的默认构造函数中,只有基类子对象和成员类对象会被初始化。所有其他的非静态数据成员都不会被初始化。
110、抽象基类为什么不能创建对象?
抽象类是一种特殊的类,它是为了抽象和设计的目的为建立的,它处于继承层次结构的较上层。
(1)抽象类的定义: 称带有纯虚函数的类为抽象类。
(2)抽象类的作用: 抽象类的主要作用是将有关的操作作为结果接口组织在一个继承层次结构中,由它来为派生类提供一个公共的根,派生类将具体实现在其基类中作为接口的操作。所以派生类实际上刻画了一组子类的操作接口的通用语义,这些语义也传给子类,子类可以具体实现这些语义,也可以再将这些语义传给自己的子类。
(3)使用抽象类时注意: 抽象类只能作为基类来使用,其纯虚函数的实现由派生类给出。如果派生类中没有重新定义纯虚函数,而只是继承基类的纯虚函数,则这个派生类仍然还是一个抽象类。如果派生类中给出了基类纯虚函数的实现,则该派生类就不再是抽象类了,它是一个可以建立对象的具体的类。
抽象类是不能定义对象的。一个纯虚函数不需要(但是可以)被定义。
一、纯虚函数定义 纯虚函数是一种特殊的虚函数,它的一般格式如下:
class <类名>
{
virtual <类型><函数名>(<参数表>)=0;
…
};
在许多情况下,在基类中不能对虚函数给出有意义的实现,而把它声明为纯虚函数,它的实现留给该基类的派生类去做。这就是纯虚函数的作用。 纯虚函数可以让类先具有一个操作名称,而没有操作内容,让派生类在继承时再去具体地给出定义。凡是含有纯虚函数的类叫做抽象类。这种类不能声明对象,只是作为基类为派生类服务。除非在派生类中完全实现基类中所有的的纯虚函数,否则,派生类也变成了抽象类,不能实例化对象。
二、纯虚函数引入原因 1、为了方便使用多态特性,我们常常需要在基类中定义虚拟函数。 2、在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔 雀等子类,但动物本身生成对象明显不合常理。 为了解决上述问题,引入了纯虚函数的概念,将函数定义为纯虚函数(方法:virtual ReturnType Function()= 0;)。若要使派生类为非抽象类,则编译器要求在派生类中,必须对纯虚函数予以重载以实现多态性。同时含有纯虚函数的类称为抽象类,它不能生成对象。这样就很好地解决了上述两个问题。 例如,绘画程序中,shape作为一个基类可以派生出圆形、矩形、正方形、梯形等, 如果我要求面积总和的话,那么会可以使用一个 shape * 的数组,只要依次调用派生类的area()函数了。如果不用接口就没法定义成数组,因为既可以是circle ,也可以是square ,而且以后还可能加上rectangle,等等.
三、相似概念 1、多态性
指相同对象收到不同消息或不同对象收到相同消息时产生不同的实现动作。C++支持两种多态性:编译时多态性,运行时多态性。 a.编译时多态性:通过重载函数实现 b.运行时多态性:通过虚函数实现。 2、虚函数 虚函数是在基类中被声明为virtual,并在派生类中重新定义的成员函数,可实现成员函数的动态重载。 3、抽象类 包含纯虚函数的类称为抽象类。由于抽象类包含了没有定义的纯虚函数,所以不能定义抽象类的对象。
111、 继承机制中对象之间如何转换?指针和引用之间如何转换?
-
向上类型转换
将派生类指针或引用转换为基类的指针或引用被称为向上类型转换,向上类型转换会自动进行,而且向上类型转换是安全的。
-
向下类型转换
将基类指针或引用转换为派生类指针或引用被称为向下类型转换,向下类型转换不会自动进行,因为一个基类对应几个派生类,所以向下类型转换时不知道对应哪个派生类,所以在向下类型转换时必须加动态类型识别技术。RTTI技术,用dynamic_cast进行向下类型转换。
112、知道C++中的组合吗?它与继承相比有什么优缺点吗?
一:继承
继承是Is a 的关系,比如说Student继承Person,则说明Student is a Person。继承的优点是子类可以重写父类的方法来方便地实现对父类的扩展。
继承的缺点有以下几点:
①:父类的内部细节对子类是可见的。
②:子类从父类继承的方法在编译时就确定下来了,所以无法在运行期间改变从父类继承的方法的行为。
③:如果对父类的方法做了修改的话(比如增加了一个参数),则子类的方法必须做出相应的修改。所以说子类与父类是一种高耦合,违背了面向对象思想。
二:组合
组合也就是设计类的时候把要组合的类的对象加入到该类中作为自己的成员变量。
组合的优点:
①:当前对象只能通过所包含的那个对象去调用其方法,所以所包含的对象的内部细节对当前对象时不可见的。
②:当前对象与包含的对象是一个低耦合关系,如果修改包含对象的类中代码不需要修改当前对象类的代码。
③:当前对象可以在运行时动态的绑定所包含的对象。可以通过set方法给所包含对象赋值。
组合的缺点:①:容易产生过多的对象。②:为了能组合多个对象,必须仔细对接口进行定义。
113、函数指针?
- 什么是函数指针?
函数指针指向的是特殊的数据类型,函数的类型是由其返回的数据类型和其参数列表共同决定的,而函数的名称则不是其类型的一部分。
一个具体函数的名字,如果后面不跟调用符号(即括号),则该名字就是该函数的指针(注意:大部分情况下,可以这么认为,但这种说法并不很严格)。
- 函数指针的声明方法
int (*pf)(const int&, const int&); (1)
上面的pf就是一个函数指针,指向所有返回类型为int,并带有两个const int&参数的函数。注意*pf两边的括号是必须的,否则上面的定义就变成了:
int *pf(const int&, const int&); (2)
而这声明了一个函数pf,其返回类型为int *, 带有两个const int&参数。
- 为什么有函数指针
函数与数据项相似,函数也有地址。我们希望在同一个函数中通过使用相同的形参在不同的时间使用产生不同的效果。
-
一个函数名就是一个指针,它指向函数的代码。一个函数地址是该函数的进入点,也就是调用函数的地址。函数的调用可以通过函数名,也可以通过指向函数的指针来调用。函数指针还允许将函数作为变元传递给其他函数;
-
两种方法赋值:
指针名 = 函数名; 指针名 = &函数名
114、 内存泄漏的后果?如何监测?解决方法?
- 内存泄漏
内存泄漏是指由于疏忽或错误造成了程序未能释放掉不再使用的内存的情况。内存泄漏并非指内存在物理上消失,而是应用程序分配某段内存后,由于设计错误,失去了对该段内存的控制;
- 后果
只发生一次小的内存泄漏可能不被注意,但泄漏大量内存的程序将会出现各种证照:性能下降到内存逐渐用完,导致另一个程序失败;
- 如何排除
使用工具软件BoundsChecker,BoundsChecker是一个运行时错误检测工具,它主要定位程序运行时期发生的各种错误;
调试运行DEBUG版程序,运用以下技术:CRT(C run-time libraries)、运行时函数调用堆栈、内存泄漏时提示的内存分配序号(集成开发环境OUTPUT窗口),综合分析内存泄漏的原因,排除内存泄漏。
- 解决方法
智能指针。
- 检查、定位内存泄漏
检查方法:在main函数最后面一行,加上一句_CrtDumpMemoryLeaks()。调试程序,自然关闭程序让其退出,查看输出:
输出这样的格式{453}normal block at 0x02432CA8,868 bytes long
被{}包围的453就是我们需要的内存泄漏定位值,868 bytes long就是说这个地方有868比特内存没有释放。
定位代码位置
在main函数第一行加上_CrtSetBreakAlloc(453);意思就是在申请453这块内存的位置中断。然后调试程序,程序中断了,查看调用堆栈。加上头文件#include <crtdbg.h>
115、使用智能指针管理内存资源,RAII是怎么回事?
- RAII全称是“Resource Acquisition is Initialization”,直译过来是“资源获取即初始化”,也就是说在构造函数中申请分配资源,在析构函数中释放资源。
因为C++的语言机制保证了,当一个对象创建的时候,自动调用构造函数,当对象超出作用域的时候会自动调用析构函数。所以,在RAII的指导下,我们应该使用类来管理资源,将资源和对象的生命周期绑定。
- 智能指针(std::shared_ptr和std::unique_ptr)即RAII最具代表的实现,使用智能指针,可以实现自动的内存管理,再也不需要担心忘记delete造成的内存泄漏。
毫不夸张的来讲,有了智能指针,代码中几乎不需要再出现delete了。
116、手写实现智能指针类
- 智能指针是一个数据类型,一般用模板实现,模拟指针行为的同时还提供自动垃圾回收机制。它会自动记录SmartPointer<T*>对象的引用计数,一旦T类型对象的引用计数为0,就释放该对象。
除了指针对象外,我们还需要一个引用计数的指针设定对象的值,并将引用计数计为1,需要一个构造函数。新增对象还需要一个构造函数,析构函数负责引用计数减少和释放内存。
通过覆写赋值运算符,才能将一个旧的智能指针赋值给另一个指针,同时旧的引用计数减1,新的引用计数加1
- 一个构造函数、拷贝构造函数、复制构造函数、析构函数、移走函数;
117、说一说你理解的内存对齐以及原因
1、 分配内存的顺序是按照声明的顺序。
2、 每个变量相对于起始位置的偏移量必须是该变量类型大小的整数倍,不是整数倍空出内存,直到偏移量是整数倍为止。
3、 最后整个结构体的大小必须是里面变量类型最大值的整数倍。
添加了#pragma pack(n)后规则就变成了下面这样:
1、 偏移量要是n和当前变量大小中较小值的整数倍
2、 整体大小要是n和最大变量大小中较小值的整数倍
3、 n值必须为1,2,4,8…,为其他值时就按照默认的分配规则
118、 结构体变量比较是否相等
- 重载了 “==” 操作符
struct foo {
int a;
int b;
bool operator==(const foo& rhs) *//* *操作运算符重载*
{
return( a == rhs.a) && (b == rhs.b);
}
};
-
元素的话,一个个比;
-
指针直接比较,如果保存的是同一个实例地址,则(p1==p2)为真;
119、 函数调用过程栈的变化,返回值和参数变量哪个先入栈?
1、调用者函数把被调函数所需要的参数按照与被调函数的形参顺序相反的顺序压入栈中,即:从右向左依次把被调函数所需要的参数压入栈; 2、调用者函数使用call指令调用被调函数,并把call指令的下一条指令的地址当成返回地址压入栈中(这个压栈操作隐含在call指令中); 3、在被调函数中,被调函数会先保存调用者函数的栈底地址(push ebp),然后再保存调用者函数的栈顶地址,即:当前被调函数的栈底地址(mov ebp,esp); 4、在被调函数中,从ebp的位置处开始存放被调函数中的局部变量和临时变量,并且这些变量的地址按照定义时的顺序依次减小,即:这些变量的地址是按照栈的延伸方向排列的,先定义的变量先入栈,后定义的变量后入栈;
120、define、const、typedef、inline的使用方法?他们之间有什么区别?
一、const与#define的区别:
-
const定义的常量是变量带类型,而#define定义的只是个常数不带类型;
-
define只在预处理阶段起作用,简单的文本替换,而const在编译、链接过程中起作用;
-
define只是简单的字符串替换没有类型检查。而const是有数据类型的,是要进行判断的,可以避免一些低级错误;
-
define预处理后,占用代码段空间,const占用数据段空间;
-
const不能重定义,而define可以通过#undef取消某个符号的定义,进行重定义;
-
define独特功能,比如可以用来防止文件重复引用。
二、 #define和别名typedef的区别
-
执行时间不同,typedef在编译阶段有效,typedef有类型检查的功能;#define是宏定义,发生在预处理阶段,不进行类型检查;
-
功能差异,typedef用来定义类型的别名,定义与平台无关的数据类型,与struct的结合使用等。#define不只是可以为类型取别名,还可以定义常量、变量、编译开关等。
-
作用域不同,#define没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用。而typedef有自己的作用域。
三、 define与inline的区别
-
#define是关键字,inline是函数;
-
宏定义在预处理阶段进行文本替换,inline函数在编译阶段进行替换;
-
inline函数有类型检查,相比宏定义比较安全;
121、你知道printf函数的实现原理是什么吗?
在C/C++中,对函数参数的扫描是从后向前的。
C/C++的函数参数是通过压入堆栈的方式来给函数传参数的(堆栈是一种先进后出的数据结构),最先压入的参数最后出来,在计算机的内存中,数据有2块,一块是堆,一块是栈(函数参数及局部变量在这里),而栈是从内存的高地址向低地址生长的,控制生长的就是堆栈指针了,最先压入的参数是在最上面,就是说在所有参数的最后面,最后压入的参数在最下面,结构上看起来是第一个,所以最后压入的参数总是能够被函数找到,因为它就在堆栈指针的上方。
printf的第一个被找到的参数就是那个字符指针,就是被双引号括起来的那一部分,函数通过判断字符串里控制参数的个数来判断参数个数及数据类型,通过这些就可算出数据需要的堆栈指针的偏移量了,下面给出printf("%d,%d",a,b);(其中a、b都是int型的)的汇编代码.
122、说一说你了解的关于lambda函数的全部知识
-
利用lambda表达式可以编写内嵌的匿名函数,用以替换独立函数或者函数对象;
-
每当你定义一个lambda表达式后,编译器会自动生成一个匿名类(这个类当然重载了()运算符),我们称为闭包类型(closure type)。那么在运行时,这个lambda表达式就会返回一个匿名的闭包实例,其实一个右值。所以,我们上面的lambda表达式的结果就是一个个闭包。闭包的一个强大之处是其可以通过传值或者引用的方式捕捉其封装作用域内的变量,前面的方括号就是用来定义捕捉模式以及变量,我们又将其称为lambda捕捉块。
-
lambda表达式的语法定义如下:
[capture] (parameters) mutable ->return-type {statement};
- lambda必须使用尾置返回来指定返回类型,可以忽略参数列表和返回值,但必须永远包含捕获列表和函数体;
123、将字符串“hello world”从开始到打印到屏幕上的全过程?
1.用户告诉操作系统执行HelloWorld程序(通过键盘输入等)
2.操作系统:找到helloworld程序的相关信息,检查其类型是否是可执行文件;并通过程序首部信息,确定代码和数据在可执行文件中的位置并计算出对应的磁盘块地址。
3.操作系统:创建一个新进程,将HelloWorld可执行文件映射到该进程结构,表示由该进程执行helloworld程序。
4.操作系统:为helloworld程序设置cpu上下文环境,并跳到程序开始处。
5.执行helloworld程序的第一条指令,发生缺页异常
6.操作系统:分配一页物理内存,并将代码从磁盘读入内存,然后继续执行helloworld程序
7.helloword程序执行puts函数(系统调用),在显示器上写一字符串
8.操作系统:找到要将字符串送往的显示设备,通常设备是由一个进程控制的,所以,操作系统将要写的字符串送给该进程
9.操作系统:控制设备的进程告诉设备的窗口系统,它要显示该字符串,窗口系统确定这是一个合法的操作,然后将字符串转换成像素,将像素写入设备的存储映像区
10.视频硬件将像素转换成显示器可接收和一组控制数据信号
11.显示器解释信号,激发液晶屏
12.OK,我们在屏幕上看到了HelloWorld
124、模板类和模板函数的区别是什么?
函数模板的实例化是由编译程序在处理函数调用时自动完成的,而类模板的实例化必须由程序员在程序中显式地指定。即函数模板允许隐式调用和显式调用而类模板只能显示调用。在使用时类模板必须加,而函数模板不必
125、为什么模板类一般都是放在一个h文件中
- 模板定义很特殊。由template<…>处理的任何东西都意味着编译器在当时不为它分配存储空间,它一直处于等待状态直到被一个模板实例告知。在编译器和连接器的某一处,有一机制能去掉指定模板的多重定义。
所以为了容易使用,几乎总是在头文件中放置全部的模板声明和定义。
- 在分离式编译的环境下,编译器编译某一个.cpp文件时并不知道另一个.cpp文件的存在,也不会去查找(当遇到未决符号时它会寄希望于连接器)。这种模式在没有模板的情况下运行良好,但遇到模板时就傻眼了,因为模板仅在需要的时候才会实例化出来。
所以,当编译器只看到模板的声明时,它不能实例化该模板,只能创建一个具有外部连接的符号并期待连接器能够将符号的地址决议出来。
然而当实现该模板的.cpp文件中没有用到模板的实例时,编译器懒得去实例化,所以,整个工程的.obj中就找不到一行模板实例的二进制代码,于是连接器也黔驴技穷了。
126、C++中类成员的访问权限和继承权限问题
- 三种访问权限
① public:用该关键字修饰的成员表示公有成员,该成员不仅可以在类内可以被 访问,在类外也是可以被访问的,是类对外提供的可访问接口;
② private:用该关键字修饰的成员表示私有成员,该成员仅在类内可以被访问,在类体外是隐藏状态;
③ protected:用该关键字修饰的成员表示保护成员,保护成员在类体外同样是隐藏状态,但是对于该类的派生类来说,相当于公有成员,在派生类中可以被访问。
- 三种继承方式
① 若继承方式是public,基类成员在派生类中的访问权限保持不变,也就是说,基类中的成员访问权限,在派生类中仍然保持原来的访问权限;
② 若继承方式是private,基类所有成员在派生类中的访问权限都会变为私有(private)权限;
③ 若继承方式是protected,基类的共有成员和保护成员在派生类中的访问权限都会变为保护(protected)权限,私有成员在派生类中的访问权限仍然是私有(private)权限。
127、cout和printf有什么区别?
cout<<是一个函数,cout<<后可以跟不同的类型是因为cout<<已存在针对各种类型数据的重载,所以会自动识别数据的类型。输出过程会首先将输出字符放入缓冲区,然后输出到屏幕。
cout是有缓冲输出:
cout < < "abc " < <endl;
或cout < < "abc\n ";cout < <flush; 这两个才是一样的.
flush立即强迫缓冲输出。 printf是无缓冲输出。有输出时立即输出
128、你知道重载运算符吗?
1、 我们只能重载已有的运算符,而无权发明新的运算符;对于一个重载的运算符,其优先级和结合律与内置类型一致才可以;不能改变运算符操作数个数;
2、 两种重载方式:成员运算符和非成员运算符,成员运算符比非成员运算符少一个参数;下标运算符、箭头运算符必须是成员运算符;
3、 引入运算符重载,是为了实现类的多态性;
4、 当重载的运算符是成员函数时,this绑定到左侧运算符对象。成员运算符函数的参数数量比运算符对象的数量少一个;至少含有一个类类型的参数;
5、 从参数的个数推断到底定义的是哪种运算符,当运算符既是一元运算符又是二元运算符(+,-,*,&);
6、 下标运算符必须是成员函数,下标运算符通常以所访问元素的引用作为返回值,同时最好定义下标运算符的常量版本和非常量版本;
7、 箭头运算符必须是类的成员,解引用通常也是类的成员;重载的箭头运算符必须返回类的指针;
129、当程序中有函数重载时,函数的匹配原则和顺序是什么?
-
名字查找
-
确定候选函数
-
寻找最佳匹配
130、定义和声明的区别
如果是指变量的声明和定义 从编译原理上来说,声明是仅仅告诉编译器,有个某类型的变量会被使用,但是编译器并不会为它分配任何内存。而定义就是分配了内存。
如果是指函数的声明和定义 声明:一般在头文件里,对编译器说:这里我有一个函数叫function() 让编译器知道这个函数的存在。 定义:一般在源文件里,具体就是函数的实现过程 写明函数体。
131、全局变量和static变量的区别
1、全局变量(外部变量)的说明之前再冠以static就构成了静态的全局变量。
全局变量本身就是静态存储方式,静态全局变量当然也是静态存储方式。
这两者在存储方式上并无不同。这两者的区别在于非静态全局变量的作用域是整个源程序,当一个源程序由多个原文件组成时,非静态的全局变量在各个源文件中都是有效的。
而静态全局变量则限制了其作用域,即只在定义该变量的源文件内有效,在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其他源文件中引起错误。
static全局变量与普通的全局变量的区别是static全局变量只初始化一次,防止在其他文件单元被引用。
2.static函数与普通函数有什么区别? static函数与普通的函数作用域不同。尽在本文件中。只在当前源文件中使用的函数应该说明为内部函数(static),内部函数应该在当前源文件中说明和定义。
对于可在当前源文件以外使用的函数应该在一个头文件中说明,要使用这些函数的源文件要包含这个头文件。 static函数与普通函数最主要区别是static函数在内存中只有一份,普通静态函数在每个被调用中维持一份拷贝程序的局部变量存在于(堆栈)中,全局变量存在于(静态区)中,动态申请数据存在于(堆)
132、 静态成员与普通成员的区别是什么?
- 生命周期
静态成员变量从类被加载开始到类被卸载,一直存在;
普通成员变量只有在类创建对象后才开始存在,对象结束,它的生命期结束;
- 共享方式
静态成员变量是全类共享;普通成员变量是每个对象单独享用的;
- 定义位置
普通成员变量存储在栈或堆中,而静态成员变量存储在静态全局区;
- 初始化位置
普通成员变量在类中初始化;静态成员变量在类外初始化;
- 默认实参
可以使用静态成员变量作为默认实参,
133、说一下你理解的 ifdef endif代表着什么?
-
一般情况下,源程序中所有的行都参加编译。但是有时希望对其中一部分内容只在满足一定条件才进行编译,也就是对一部分内容指定编译的条件,这就是“条件编译”。有时,希望当满足某条件时对一组语句进行编译,而当条件不满足时则编译另一组语句。
-
条件编译命令最常见的形式为:
\#ifdef 标识符
程序段1
\#else
程序段2
\#endif
它的作用是:当标识符已经被定义过(一般是用#define命令定义),则对程序段1进行编译,否则编译程序段2。 其中#else部分也可以没有,即:
\#ifdef
程序段1
\#denif
- 在一个大的软件工程里面,可能会有多个文件同时包含一个头文件,当这些文件编译链接成一个可执行文件上时,就会出现大量“重定义”错误。
在头文件中使用#define、#ifndef、#ifdef、#endif能避免头文件重定义。
134、隐式转换,如何消除隐式转换?
1、C++的基本类型中并非完全的对立,部分数据类型之间是可以进行隐式转换的。所谓隐式转换,是指不需要用户干预,编译器私下进行的类型转换行为。很多时候用户可能都不知道进行了哪些转换
2、C++面向对象的多态特性,就是通过父类的类型实现对子类的封装。通过隐式转换,你可以直接将一个子类的对象使用父类的类型进行返回。在比如,数值和布尔类型的转换,整数和浮点数的转换等。某些方面来说,隐式转换给C++程序开发者带来了不小的便捷。C++是一门强类型语言,类型的检查是非常严格的。
3、 基本数据类型 基本数据类型的转换以取值范围的作为转换基础(保证精度不丢失)。隐式转换发生在从小->大的转换中。比如从char转换为int。从int->long。自定义对象 子类对象可以隐式的转换为父类对象。
4、 C++中提供了explicit关键字,在构造函数声明的时候加上explicit关键字,能够禁止隐式转换。
5、如果构造函数只接受一个参数,则它实际上定义了转换为此类类型的隐式转换机制。可以通过将构造函数声明为explicit加以制止隐式类型转换,关键字explicit只对一个实参的构造函数有效,需要多个实参的构造函数不能用于执行隐式转换,所以无需将这些构造函数指定为explicit。
135、 虚函数的内存结构,那菱形继承的虚函数内存结构呢
参考:https://blog.csdn.net/haoel/article/details/1948051/
菱形继承的定义是:两个子类继承同一父类,而又有子类同时继承这两个子类。例如a,b两个类同时继承c,但是又有一个d类同时继承a,b类。
136、多继承的优缺点,作为一个开发者怎么看待多继承
-
C++允许为一个派生类指定多个基类,这样的继承结构被称做多重继承。
-
多重继承的优点很明显,就是对象可以调用多个基类中的接口;
-
如果派生类所继承的多个基类有相同的基类,而派生类对象需要调用这个祖先类的接口方法,就会容易出现二义性
-
加上全局符确定调用哪一份拷贝。比如pa.Author::eat()调用属于Author的拷贝。
-
使用虚拟继承,使得多重继承类Programmer_Author只拥有Person类的一份拷贝。
137、迭代器:++it、it++哪个好,为什么
- 前置返回一个引用,后置返回一个对象
// ++i实现代码为:
int& operator++()
{
*this += 1;
return *this;
}
- 前置不会产生临时对象,后置必须产生临时对象,临时对象会导致效率降低
//i++实现代码为:
int operator++(int)
{
int temp = *this;
++*this;
return temp;
}
138、C++如何处理多个异常的?
-
C++中的异常情况: 语法错误(编译错误):比如变量未定义、括号不匹配、关键字拼写错误等等编译器在编译时能发现的错误,这类错误可以及时被编译器发现,而且可以及时知道出错的位置及原因,方便改正。 运行时错误:比如数组下标越界、系统内存不足等等。这类错误不易被程序员发现,它能通过编译且能进入运行,但运行时会出错,导致程序崩溃。为了有效处理程序运行时错误,C++中引入异常处理机制来解决此问题。
-
C++异常处理机制: 异常处理基本思想:执行一个函数的过程中发现异常,可以不用在本函数内立即进行处理, 而是抛出该异常,让函数的调用者直接或间接处理这个问题。 C++异常处理机制由3个模块组成:try(检查)、throw(抛出)、catch(捕获) 抛出异常的语句格式为:throw 表达式;如果try块中程序段发现了异常则抛出异常。
try
{
可能抛出异常的语句;(检查)
}
catch(类型名[形参名])//捕获特定类型的异常
{
//处理1;
}
catch(类型名[形参名])//捕获特定类型的异常
{
//处理2;
}
catch(…)//捕获所有类型的异常
{
}
139、模板和实现可不可以不写在一个文件里面?为什么?
因为在编译时模板并不能生成真正的二进制代码,而是在编译调用模板类或函数的CPP文件时才会去找对应的模板声明和实现,在这种情况下编译器是不知道实现模板类或函数的CPP文件的存在,所以它只能找到模板类或函数的声明而找不到实现,而只好创建一个符号寄希望于链接程序找地址。
但模板类或函数的实现并不能被编译成二进制代码,结果链接程序找不到地址只好报错了。 《C++编程思想》第15章(第300页)说明了原因:模板定义很特殊。由template<…>处理的任何东西都意味着编译器在当时不为它分配存储空间,
它一直处于等待状态直到被一个模板实例告知。在编译器和连接器的某一处,有一机制能去掉指定模板的多重定义。所以为了容易使用,几乎总是在头文件中放置全部的模板声明和定义。
140、在成员函数中调用delete this会出现什么问题?对象还可以使用吗?
1、在类对象的内存空间中,只有数据成员和虚函数表指针,并不包含代码内容,类的成员函数单独放在代码段中。在调用成员函数时,隐含传递一个this指针,让成员函数知道当前是哪个对象在调用它。当调用delete this时,类对象的内存空间被释放。在delete this之后进行的其他任何函数调用,只要不涉及到this指针的内容,都能够正常运行。一旦涉及到this指针,如操作数据成员,调用虚函数等,就会出现不可预期的问题。
2、为什么是不可预期的问题?
delete this之后不是释放了类对象的内存空间了么,那么这段内存应该已经还给系统,不再属于这个进程。照这个逻辑来看,应该发生指针错误,无访问权限之类的令系统崩溃的问题才对啊?这个问题牵涉到操作系统的内存管理策略。delete this释放了类对象的内存空间,但是内存空间却并不是马上被回收到系统中,可能是缓冲或者其他什么原因,导致这段内存空间暂时并没有被系统收回。此时这段内存是可以访问的,你可以加上100,加上200,但是其中的值却是不确定的。当你获取数据成员,可能得到的是一串很长的未初始化的随机数;访问虚函数表,指针无效的可能性非常高,造成系统崩溃。
3、 如果在类的析构函数中调用delete this,会发生什么?
会导致堆栈溢出。原因很简单,delete的本质是“为将被释放的内存调用一个或多个析构函数,然后,释放内存”。显然,delete this会去调用本对象的析构函数,而析构函数中又调用delete this,形成无限递归,造成堆栈溢出,系统崩溃。
141、如何在不使用额外空间的情况下,交换两个数?你有几种方法
1) 算术
x = x + y;
y = x - y;
x = x - y;
2) 异或
x = x^y;// 只能对int,char..
y = x^y;
x = x^y;
x ^= y ^= x;
142、你知道strcpy和memcpy的区别是什么吗?
1、复制的内容不同。strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。 2、复制的方法不同。strcpy不需要指定长度,它遇到被复制字符的串结束符"\0"才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。 3、用途不同。通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy
143、程序在执行int main(int argc, char *argv[])时的内存结构,你了解吗?
参数的含义是程序在命令行下运行的时候,需要输入argc 个参数,每个参数是以char 类型输入的,依次存在数组里面,数组是 argv[],所有的参数在指针
char * 指向的内存中,数组的中元素的个数为 argc 个,第一个参数为程序的名称。
144、volatile关键字的作用?
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。声明时语法:int volatile vInt; 当要求使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。
volatile用在如下的几个地方:
- 中断服务程序中修改的供其它程序检测的变量需要加volatile;
- 多任务环境下各任务间共享的标志应该加volatile;
- 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
145、如果有一个空类,它会默认添加哪些函数?
1) Empty(); // 缺省构造函数//
2) Empty( const Empty& ); // 拷贝构造函数//
3) ~Empty(); // 析构函数//
4) Empty& operator=( const Empty& ); // 赋值运算符//
146、C++中标准库是什么?
- C++ 标准库可以分为两部分:
标准函数库: 这个库是由通用的、独立的、不属于任何类的函数组成的。函数库继承自 C 语言。
面向对象类库: 这个库是类及其相关函数的集合。
-
输入/输出 I/O、字符串和字符处理、数学、时间、日期和本地化、动态分配、其他、宽字符函数
-
标准的 C++ I/O 类、String 类、数值类、STL 容器类、STL 算法、STL 函数对象、STL 迭代器、STL 分配器、本地化库、异常处理类、杂项支持库
147、你知道const char* 与string之间的关系是什么吗?
-
string 是c++标准库里面其中一个,封装了对字符串的操作,实际操作过程我们可以用const char*给string类初始化
-
三者的转化关系如下所示:
a) string转const char*
string s = “abc”;
const char* c_s = s.c_str();
b) const char* 转string,直接赋值即可
const char* c_s = “abc”;
string s(c_s);
c) string 转char*
string s = “abc”;
char* c;
const int len = s.length();
c = new char[len+1];
strcpy(c,s.c_str());
d) char* 转string
char* c = “abc”;
string s(c);
e) const char* 转char*
const char* cpc = “abc”;
char* pc = new char[strlen(cpc)+1];
strcpy(pc,cpc);
f) char* 转const char*,直接赋值即可
char* pc = “abc”;
const char* cpc = pc;
148、为什么拷贝构造函数必须传引用不能传值?
- 拷贝构造函数的作用就是用来复制对象的,在使用这个对象的实例来初始化这个对象的一个新的实例。
- 参数传递过程到底发生了什么? 将地址传递和值传递统一起来,归根结底还是传递的是"值"(地址也是值,只不过通过它可以找到另一个值)! i)值传递: 对于内置数据类型的传递时,直接赋值拷贝给形参(注意形参是函数内局部变量); 对于类类型的传递时,需要首先调用该类的拷贝构造函数来初始化形参(局部对象);
如void foo(class_type obj_local){}, 如果调用foo(obj); 首先class_type obj_local(obj) ,这样就定义了局部变量obj_local供函数内部使用
ii)引用传递: 无论对内置类型还是类类型,传递引用或指针最终都是传递的地址值!而地址总是指针类型(属于简单类型), 显然参数传递时,按简单类型的赋值拷贝,而不会有拷贝构造函数的调用(对于类类型). 上述1) 2)回答了为什么拷贝构造函数使用值传递会产生无限递归调用,内存溢出。
拷贝构造函数用来初始化一个非引用类类型对象,如果用传值的方式进行传参数,那么构造实参需要调用拷贝构造函数,而拷贝构造函数需要传递实参,所以会一直递归。
149、你知道空类的大小是多少吗?
-
C++空类的大小不为0,不同编译器设置不一样,vs设置为1;
-
C++标准指出,不允许一个对象(当然包括类对象)的大小为0,不同的对象不能具有相同的地址;
-
带有虚函数的C++类大小不为1,因为每一个对象会有一个vptr指向虚函数表,具体大小根据指针大小确定;
-
C++中要求对于类的每个实例都必须有独一无二的地址,那么编译器自动为空类分配一个字节大小,这样便保证了每个实例均有独一无二的内存地址。
150、你什么情况用指针当参数,什么时候用引用,为什么?
- 使用引用参数的主要原因有两个:
程序员能修改调用函数中的数据对象
通过传递引用而不是整个数据–对象,可以提高程序的运行速度
- 一般的原则: 对于使用引用的值而不做修改的函数:
如果数据对象很小,如内置数据类型或者小型结构,则按照值传递;
如果数据对象是数组,则使用指针(唯一的选择),并且指针声明为指向const的指针;
如果数据对象是较大的结构,则使用const指针或者引用,已提高程序的效率。这样可以节省结构所需的时间和空间;
如果数据对象是类对象,则使用const引用(传递类对象参数的标准方式是按照引用传递);
- 对于修改函数中数据的函数:
如果数据是内置数据类型,则使用指针
如果数据对象是数组,则只能使用指针
如果数据对象是结构,则使用引用或者指针
如果数据是类对象,则使用引用
151、静态函数能定义为虚函数吗?常函数呢?说说你的理解
1、static成员不属于任何类对象或类实例,所以即使给此函数加上virutal也是没有任何意义的。
2、静态与非静态成员函数之间有一个主要的区别,那就是静态成员函数没有this指针。
虚函数依靠vptr和vtable来处理。vptr是一个指针,在类的构造函数中创建生成,并且只能用this指针来访问它,因为它是类的一个成员,并且vptr指向保存虚函数地址的vtable.对于静态成员函数,它没有this指针,所以无法访问vptr。
这就是为何static函数不能为virtual,虚函数的调用关系:this -> vptr -> vtable ->virtual function
152、this指针调用成员变量时,堆栈会发生什么变化?
当在类的非静态成员函数访问类的非静态成员时,编译器会自动将对象的地址传给作为隐含参数传递给函数,这个隐含参数就是this指针。
即使你并没有写this指针,编译器在链接时也会加上this的,对各成员的访问都是通过this的。
例如你建立了类的多个对象时,在调用类的成员函数时,你并不知道具体是哪个对象在调用,此时你可以通过查看this指针来查看具体是哪个对象在调用。This指针首先入栈,然后成员函数的参数从右向左进行入栈,最后函数返回地址入栈。
153、你知道静态绑定和动态绑定吗?讲讲?
-
对象的静态类型:对象在声明时采用的类型。是在编译期确定的。
-
对象的动态类型:目前所指对象的类型。是在运行期决定的。对象的动态类型可以更改,但是静态类型无法更改。
-
静态绑定:绑定的是对象的静态类型,某特性(比如函数依赖于对象的静态类型,发生在编译期。
-
动态绑定:绑定的是对象的动态类型,某特性(比如函数依赖于对象的动态类型,发生在运行期。
154、如何设计一个类计算子类的个数?
1、为类设计一个static静态变量count作为计数器;
2、类定义结束后初始化count;
3、在构造函数中对count进行+1;
4、 设计拷贝构造函数,在进行拷贝构造函数中进行count +1,操作;
5、设计复制构造函数,在进行复制函数中对count+1操作;
6、在析构函数中对count进行-1;
155、怎么快速定位错误出现的地方
1、如果是简单的错误,可以直接双击错误列表里的错误项或者生成输出的错误信息中带行号的地方就可以让编辑窗口定位到错误的位置上。
2、对于复杂的模板错误,最好使用生成输出窗口。
多数情况下出发错误的位置是最靠后的引用位置。如果这样确定不了错误,就需要先把自己写的代码里的引用位置找出来,然后逐个分析了。
156、虚函数的代价?
-
带有虚函数的类,每一个类会产生一个虚函数表,用来存储指向虚成员函数的指针,增大类;
-
带有虚函数的类的每一个对象,都会有有一个指向虚表的指针,会增加对象的空间大小;
-
不能再是内敛的函数,因为内敛函数在编译阶段进行替代,而虚函数表示等待,在运行阶段才能确定到低是采用哪种函数,虚函数不能是内敛函数。
157、类对象的大小受哪些因素影响?
-
类的非静态成员变量大小,静态成员不占据类的空间,成员函数也不占据类的空间大小;
-
内存对齐另外分配的空间大小,类内的数据也是需要进行内存对齐操作的;
-
虚函数的话,会在类对象插入vptr指针,加上指针大小;
-
当该该类是某类的派生类,那么派生类继承的基类部分的数据成员也会存在在派生类中的空间中,也会对派生类进行扩展。
158、移动构造函数听说过吗?说说
-
有时候我们会遇到这样一种情况,我们用对象a初始化对象b后对象a我们就不在使用了,但是对象a的空间还在呀(在析构之前),既然拷贝构造函数,实际上就是把a对象的内容复制一份到b中,那么为什么我们不能直接使用a的空间呢?这样就避免了新的空间的分配,大大降低了构造的成本。这就是移动构造函数设计的初衷;
-
拷贝构造函数中,对于指针,我们一定要采用深层复制,而移动构造函数中,对于指针,我们采用浅层复制;
-
C++引入了移动构造函数,专门处理这种,用a初始化b后,就将a析构的情况;
-
与拷贝类似,移动也使用一个对象的值设置另一个对象的值。但是,又与拷贝不同的是,移动实现的是对象值真实的转移(源对象到目的对象):源对象将丢失其内容,其内容将被目的对象占有。移动操作的发生的时候,是当移动值的对象是未命名的对象的时候。这里未命名的对象就是那些临时变量,甚至都不会有名称。典型的未命名对象就是函数的返回值或者类型转换的对象。使用临时对象的值初始化另一个对象值,不会要求对对象的复制:因为临时对象不会有其它使用,因而,它的值可以被移动到目的对象。做到这些,就要使用移动构造函数和移动赋值:当使用一个临时变量对象进行构造初始化的时候,调用移动构造函数。类似的,使用未命名的变量的值赋给一个对象时,调用移动赋值操作;
Example6 (Example6&& x) : ptr(x.ptr)
{
x.ptr = nullptr;
}
// move assignment
Example6& operator= (Example6&& x)
{
delete ptr;
ptr = x.ptr;
x.ptr=nullptr;
return *this;
}
159、 什么时候合成构造函数?都说一说,你知道的都说一下
-
如果一个类没有任何构造函数,但他含有一个成员对象,该成员对象含有默认构造函数,那么编译器就为该类合成一个默认构造函数,因为不合成一个默认构造函数那么该成员对象的构造函数不能调用;
-
没有任何构造函数的类派生自一个带有默认构造函数的基类,那么需要为该派生类合成一个构造函数,只有这样基类的构造函数才能被调用;
-
带有虚函数的类,虚函数的引入需要进入虚表,指向虚表的指针,该指针是在构造函数中初始化的,所以没有构造函数的话该指针无法被初始化;
-
带有一个虚基类的类
还有一点需要注意的是:
-
并不是任何没有构造函数的类都会合成一个构造函数
-
编译器合成出来的构造函数并不会显示设定类内的每一个成员变量
160、那什么时候需要合成拷贝构造函数呢?
有三种情况会以一个对象的内容作为另一个对象的初值:
-
对一个对象做显示的初始化操作,X xx = x;
-
当对象被当做参数交给某个函数时;
-
当函数传回一个类对象时;
-
如果一个类没有拷贝构造函数,但是含有一个类类型的成员变量,该类型含有拷贝构造函数,此时编译器会为该类合成一个拷贝构造函数;
-
如果一个类没有拷贝构造函数,但是该类继承自含有拷贝构造函数的基类,此时编译器会为该类合成一个拷贝构造函数;
-
如果一个类没有拷贝构造函数,但是该类声明或继承了虚函数,此时编译器会为该类合成一个拷贝构造函数;
-
如果一个类没有拷贝构造函数,但是该类含有虚基类,此时编译器会为该类合成一个拷贝构造函数;
161、成员初始化列表会在什么时候用到?它的调用过程是什么?
-
当初始化一个引用成员变量时;
-
初始化一个const成员变量时;
-
当调用一个基类的构造函数,而构造函数拥有一组参数时;
-
当调用一个成员类的构造函数,而他拥有一组参数;
-
编译器会一一操作初始化列表,以适当顺序在构造函数之内安插初始化操作,并且在任何显示用户代码前。list中的项目顺序是由类中的成员声明顺序决定的,不是初始化列表中的排列顺序决定的。
162、构造函数的执行顺序是什么?
-
在派生类构造函数中,所有的虚基类及上一层基类的构造函数调用;
-
对象的vptr被初始化;
-
如果有成员初始化列表,将在构造函数体内扩展开来,这必须在vptr被设定之后才做;
-
执行程序员所提供的代码;
163、一个类中的全部构造函数的扩展过程是什么?
-
记录在成员初始化列表中的数据成员初始化操作会被放在构造函数的函数体内,并与成员的声明顺序为顺序;
-
如果一个成员并没有出现在成员初始化列表中,但它有一个默认构造函数,那么默认构造函数必须被调用;
-
如果class有虚表,那么它必须被设定初值;
-
所有上一层的基类构造函数必须被调用;
-
所有虚基类的构造函数必须被调用。
164、哪些函数不能是虚函数?把你知道的都说一说
-
构造函数,构造函数初始化对象,派生类必须知道基类函数干了什么,才能进行构造;当有虚函数时,每一个类有一个虚表,每一个对象有一个虚表指针,虚表指针在构造函数中初始化;
-
内联函数,内联函数表示在编译阶段进行函数体的替换操作,而虚函数意味着在运行期间进行类型确定,所以内联函数不能是虚函数;
-
静态函数,静态函数不属于对象属于类,静态成员函数没有this指针,因此静态函数设置为虚函数没有任何意义。
-
友元函数,友元函数不属于类的成员函数,不能被继承。对于没有继承特性的函数没有虚函数的说法。
-
普通函数,普通函数不属于类的成员函数,不具有继承特性,因此普通函数没有虚函数。
165、说一说strcpy、sprintf与memcpy这三个函数的不同之处
- 操作对象不同
① strcpy的两个操作对象均为字符串
② sprintf的操作源对象可以是多种数据类型,目的操作对象是字符串
③ memcpy的两个对象就是两个任意可操作的内存地址,并不限于何种数据类型。
- 执行效率不同
memcpy最高,strcpy次之,sprintf的效率最低。
- 实现功能不同
① strcpy主要实现字符串变量间的拷贝
② sprintf主要实现其他数据类型格式到字符串的转化
③ memcpy主要是内存块间的拷贝。
166、将引用作为函数参数有哪些好处?
- 传递引用给函数与传递指针的效果是一样的。
这时,被调函数的形参就成为原来主调函数中的实参变量或对象的一个别名来使用,所以在被调函数中对形参变量的操作就是对其相应的目标对象(在主调函数中)的操作。
- 使用引用传递函数的参数,在内存中并没有产生实参的副本,它是直接对实参操作;
而使用一般变量传递函数的参数,当发生函数调用时,需要给形参分配存储单元,形参变量是实参变量的副本;
如果传递的是对象,还将调用拷贝构造函数。因此,当参数传递的数据较大时,用引用比用一般变量传递参数的效率和所占空间都好。
- 使用指针作为函数的参数虽然也能达到与使用引用的效果,但是,在被调函数中同样要给形参分配存储单元,且需要重复使用"*指针变量名"的形式进行运算,这很容易产生错误且程序的阅读性较差;
另一方面,在主调函数的调用点处,必须用变量的地址作为实参。而引用更容易使用,更清晰。
167、你知道数组和指针的区别吗?
-
数组在内存中是连续存放的,开辟一块连续的内存空间;数组所占存储空间:sizeof(数组名);数组大小:sizeof(数组名)/sizeof(数组元素数据类型);
-
用运算符sizeof 可以计算出数组的容量(字节数)。sizeof(p),p 为指针得到的是一个指针变量的字节数,而不是p 所指的内存容量。
-
编译器为了简化对数组的支持,实际上是利用指针实现了对数组的支持。具体来说,就是将表达式中的数组元素引用转换为指针加偏移量的引用。
-
在向函数传递参数的时候,如果实参是一个数组,那用于接受的形参为对应的指针。也就是传递过去是数组的首地址而不是整个数组,能够提高效率;
-
在使用下标的时候,两者的用法相同,都是原地址加上下标值,不过数组的原地址就是数组首元素的地址是固定的,指针的原地址就不是固定的。
168、如何阻止一个类被实例化?有哪些方法?
-
将类定义为抽象基类或者将构造函数声明为private;
-
不允许类外部创建类对象,只能在类内部创建对象
169、 如何禁止程序自动生成拷贝构造函数?
-
为了阻止编译器默认生成拷贝构造函数和拷贝赋值函数,我们需要手动去重写这两个函数,某些情况下,为了避免调用拷贝构造函数和拷贝赋值函数,我们需要将他们设置成private,防止被调用。
-
类的成员函数和friend函数还是可以调用private函数,如果这个private函数只声明不定义,则会产生一个连接错误;
-
针对上述两种情况,我们可以定一个base类,在base类中将拷贝构造函数和拷贝赋值函数设置成private,那么派生类中编译器将不会自动生成这两个函数,且由于base类中该函数是私有的,因此,派生类将阻止编译器执行相关的操作。
170、你知道Denug和release的区别是什么吗?
-
调试版本,包含调试信息,所以容量比Release大很多,并且不进行任何优化(优化会使调试复杂化,因为源代码和生成的指令间关系会更复杂),便于程序员调试。Debug模式下生成两个文件,除了.exe或.dll文件外,还有一个.pdb文件,该文件记录了代码中断点等调试信息;
-
发布版本,不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的。(调试信息可在单独的PDB文件中生成)。Release模式下生成一个文件.exe或.dll文件。
-
实际上,Debug 和 Release 并没有本质的界限,他们只是一组编译选项的集合,编译器只是按照预定的选项行动。事实上,我们甚至可以修改这些选项,从而得到优化过的调试版本或是带跟踪语句的发布版本。
171、main函数的返回值有什么值得考究之处吗?
程序运行过程入口点main函数,main()函数返回值类型必须是int,这样返回值才能传递给程序激活者(如操作系统)表示程序正常退出。
main(int args, char **argv) 参数的传递。参数的处理,一般会调用getopt()函数处理,但实践中,这仅仅是一部分,不会经常用到的技能点。
172、模板会写吗?写一个比较大小的模板函数
#include<iostream>
using namespace std;
template<typename type1,typename type2>//函数模板
type1 Max(type1 a,type2 b)
{
return a > b ? a : b;
}
void main()
{
cout<<"Max = "<<Max(5.5,'a')<<endl;
}
173、智能指针出现循环引用怎么解决?
弱指针用于专门解决shared_ptr循环引用的问题,weak_ptr不会修改引用计数,即其存在与否并不影响对象的引用计数器。循环引用就是:两个对象互相使用一个shared_ptr成员变量指向对方。弱引用并不对对象的内存进行管理,在功能上类似于普通指针,然而一个比较大的区别是,弱引用能检测到所管理的对象是否已经被释放,从而避免访问非法内存。
174、strcpy函数和strncpy函数的区别?哪个函数更安全?
- 函数原型
char* strcpy(char* strDest, const char* strSrc)
char* strncpy(char* strDest, const char* strSrc, int pos)
-
strcpy函数: 如果参数 dest 所指的内存空间不够大,可能会造成缓冲溢出(buffer Overflow)的错误情况,在编写程序时请特别留意,或者用strncpy()来取代。 strncpy函数:用来复制源字符串的前n个字符,src 和 dest 所指的内存区域不能重叠,且 dest 必须有足够的空间放置n个字符。
-
如果目标长>指定长>源长,则将源长全部拷贝到目标长,自动加上’\0’ 如果指定长<源长,则将源长中按指定长度拷贝到目标字符串,不包括’\0’ 如果指定长>目标长,运行时错误 ;
175、static_cast比C语言中的转换强在哪里?
-
更加安全;
-
更直接明显,能够一眼看出是什么类型转换为什么类型,容易找出程序中的错误;可清楚地辨别代码中每个显式的强制转;可读性更好,能体现程序员的意图
176、成员函数里memset(this,0,sizeof(*this))会发生什么
-
有时候类里面定义了很多int,char,struct等c语言里的那些类型的变量,我习惯在构造函数中将它们初始化为0,但是一句句的写太麻烦,所以直接就memset(this, 0, sizeof *this);将整个对象的内存全部置为0。对于这种情形可以很好的工作,但是下面几种情形是不可以这么使用的;
-
类含有虚函数表:这么做会破坏虚函数表,后续对虚函数的调用都将出现异常;
-
类中含有C++类型的对象:例如,类中定义了一个list的对象,由于在构造函数体的代码执行之前就对list对象完成了初始化,假设list在它的构造函数里分配了内存,那么我们这么一做就破坏了list对象的内存。
177、你知道回调函数吗?它的作用?
-
当发生某种事件时,系统或其他函数将会自动调用你定义的一段函数;
-
回调函数就相当于一个中断处理函数,由系统在符合你设定的条件时自动调用。为此,你需要做三件事:1,声明;2,定义;3,设置触发条件,就是在你的函数中把你的回调函数名称转化为地址作为一个参数,以便于系统调用;
-
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用为调用它所指向的函数时,我们就说这是回调函数;
-
因为可以把调用者与被调用者分开。调用者不关心谁是被调用者,所有它需知道的,只是存在一个具有某种特定原型、某些限制条件(如返回值为int)的被调用函数。
178、什么是一致性哈希?
一致性哈希
一致性哈希是一种哈希算法,就是在移除或者增加一个结点时,能够尽可能小的改变已存在key的映射关系
尽可能少的改变已有的映射关系,一般是沿着顺时针进行操作,回答之前可以先想想,真实情况如何处理
一致性哈希将整个哈希值空间组织成一个虚拟的圆环,假设哈希函数的值空间为0~2^32-1,整个哈希空间环如下左图所示
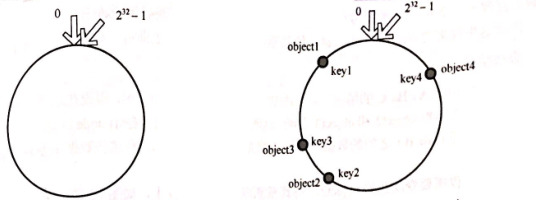
一致性hash的基本思想就是使用相同的hash算法将数据和结点都映射到图中的环形哈希空间中,上右图显示了4个数据object1-object4在环上的分布图
结点和数据映射
假如有一批服务器,可以根据IP或者主机名作为关键字进行哈希,根据结果映射到哈希环中,3台服务器分别是nodeA-nodeC
现在有一批的数据object1-object4需要存在服务器上,则可以使用相同的哈希算法对数据进行哈希,其结果必然也在环上,可以沿着顺时针方向寻找,找到一个结点(服务器)则将数据存在这个结点上,这样数据和结点就产生了一对一的关联,如下图所示:
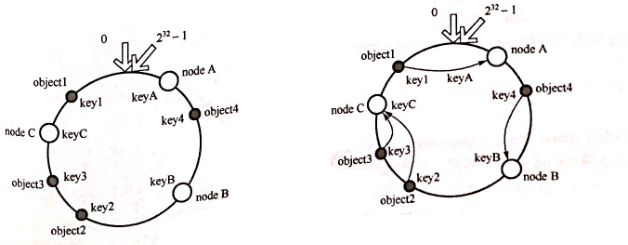
移除结点
如果一台服务器出现问题,如上图中的nodeB,则受影响的是其逆时针方向至下一个结点之间的数据,只需将这些数据映射到它顺时针方向的第一个结点上即可,下左图
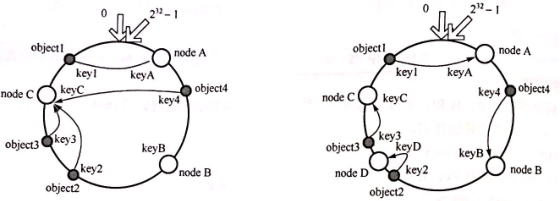
添加结点
如果新增一台服务器nodeD,受影响的是其逆时针方向至下一个结点之间的数据,将这些数据映射到nodeD上即可,见上右图
虚拟结点
假设仅有2台服务器:nodeA和nodeC,nodeA映射了1条数据,nodeC映射了3条,这样数据分布是不平衡的。引入虚拟结点,假设结点复制个数为2,则nodeA变成:nodeA1和nodeA2,nodeC变成:nodeC1和nodeC2,映射情况变成如下:
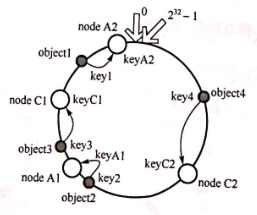
这样数据分布就均衡多了,平衡性有了很大的提高
《程序员求职宝典》王道论坛
179、什么是纯虚函数,与虚函数的区别
虚函数和纯虚函数区别?
-
虚函数是为了实现动态编联产生的,目的是通过基类类型的指针指向不同对象时,自动调用相应的、和基类同名的函数(使用同一种调用形式,既能调用派生类又能调用基类的同名函数)。虚函数需要在基类中加上virtual修饰符修饰,因为virtual会被隐式继承,所以子类中相同函数都是虚函数。当一个成员函数被声明为虚函数之后,其派生类中同名函数自动成为虚函数,在派生类中重新定义此函数时要求函数名、返回值类型、参数个数和类型全部与基类函数相同。
-
纯虚函数只是相当于一个接口名,但含有纯虚函数的类不能够实例化。
纯虚函数首先是虚函数,其次它没有函数体,取而代之的是用“=0”。
既然是虚函数,它的函数指针会被存在虚函数表中,由于纯虚函数并没有具体的函数体,因此它在虚函数表中的值就为0,而具有函数体的虚函数则是函数的具体地址。
一个类中如果有纯虚函数的话,称其为抽象类。抽象类不能用于实例化对象,否则会报错。抽象类一般用于定义一些公有的方法。子类继承抽象类也必须实现其中的纯虚函数才能实例化对象。
举个例子:
#include <iostream>
using namespace std;
class Base
{
public:
virtual void fun1()
{
cout << "普通虚函数" << endl;
}
virtual void fun2() = 0;
virtual ~Base() {}
};
class Son : public Base
{
public:
virtual void fun2()
{
cout << "子类实现的纯虚函数" << endl;
}
};
int main()
{
Base* b = new Son;
b->fun1(); //普通虚函数
b->fun2(); //子类实现的纯虚函数
return 0;
}
180、C++从代码到可执行程序经历了什么?
(1)预编译
主要处理源代码文件中的以“#”开头的预编译指令。处理规则见下:
-
删除所有的#define,展开所有的宏定义。
-
处理所有的条件预编译指令,如“#if”、“#endif”、“#ifdef”、“#elif”和“#else”。
-
处理“#include”预编译指令,将文件内容替换到它的位置,这个过程是递归进行的,文件中包含其他 文件。
-
删除所有的注释,“//”和“/**/”。
-
保留所有的#pragma 编译器指令,编译器需要用到他们,如:#pragma once 是为了防止有文件被重 复引用。
-
添加行号和文件标识,便于编译时编译器产生调试用的行号信息,和编译时产生编译错误或警告是 能够显示行号。
(2)编译
把预编译之后生成的xxx.i或xxx.ii文件,进行一系列词法分析、语法分析、语义分析及优化后,生成相应 的汇编代码文件。
- 词法分析:利用类似于“有限状态机”的算法,将源代码程序输入到扫描机中,将其中的字符序列分 割成一系列的记号。
- 语法分析:语法分析器对由扫描器产生的记号,进行语法分析,产生语法树。由语法分析器输出的 语法树是一种以表达式为节点的树。
- 语义分析:语法分析器只是完成了对表达式语法层面的分析,语义分析器则对表达式是否有意义进 行判断,其分析的语义是静态语义——在编译期能分期的语义,相对应的动态语义是在运行期才能确定 的语义。
- 优化:源代码级别的一个优化过程。
- 目标代码生成:由代码生成器将中间代码转换成目标机器代码,生成一系列的代码序列——汇编语言 表示。
- 目标代码优化:目标代码优化器对上述的目标机器代码进行优化:寻找合适的寻址方式、使用位移 来替代乘法运算、删除多余的指令等。
(3)汇编
将汇编代码转变成机器可以执行的指令(机器码文件)。 汇编器的汇编过程相对于编译器来说更简单,没 有复杂的语法,也没有语义,更不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译过 来,汇编过程有汇编器as完成。经汇编之后,产生目标文件(与可执行文件格式几乎一样)xxx.o(Windows 下)、xxx.obj(Linux下)。
(4)链接
将不同的源文件产生的目标文件进行链接,从而形成一个可以执行的程序。链接分为静态链接和动态链 接:
静态链接
函数和数据被编译进一个二进制文件。在使用静态库的情况下,在编译链接可执行文件时,链接器从库 中复制这些函数和数据并把它们和应用程序的其它模块组合起来创建最终的可执行文件。
空间浪费:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个 目标文件都有依赖,会出现同一个目标文件都在内存存在多个副本;
更新困难:每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。
运行速度快:但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西, 在执行的时候运行速度快。
动态链接
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形 成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
共享库:就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多分,副 本,而是这多个程序在执行时共享同一份副本;
更新方便:更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运 行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。
性能损耗:因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损 失。
《操作系统(三)》:https://www.nowcoder.com/tutorial/93/675fd4af3ab34b2db0ae650855aa52d5
181、为什么友元函数必须在类内部声明?
因为编译器必须能够读取这个结构的声明以理解这个数据类型的大、行为等方面的所有规则。
有一条规则在任何关系中都很重要,那就是谁可以访问我的私有部分。
182、用C语言实现C++的继承
#include <iostream>
using namespace std;
//C++中的继承与多态
struct A
{
virtual void fun() //C++中的多态:通过虚函数实现
{
cout<<"A:fun()"<<endl;
}
int a;
};
struct B:public A //C++中的继承:B类公有继承A类
{
virtual void fun() //C++中的多态:通过虚函数实现(子类的关键字virtual可加可不加)
{
cout<<"B:fun()"<<endl;
}
int b;
};
//C语言模拟C++的继承与多态
typedef void (*FUN)(); //定义一个函数指针来实现对成员函数的继承
struct _A //父类
{
FUN _fun; //由于C语言中结构体不能包含函数,故只能用函数指针在外面实现
int _a;
};
struct _B //子类
{
_A _a_; //在子类中定义一个基类的对象即可实现对父类的继承
int _b;
};
void _fA() //父类的同名函数
{
printf("_A:_fun()\n");
}
void _fB() //子类的同名函数
{
printf("_B:_fun()\n");
}
void Test()
{
//测试C++中的继承与多态
A a; //定义一个父类对象a
B b; //定义一个子类对象b
A* p1 = &a; //定义一个父类指针指向父类的对象
p1->fun(); //调用父类的同名函数
p1 = &b; //让父类指针指向子类的对象
p1->fun(); //调用子类的同名函数
//C语言模拟继承与多态的测试
_A _a; //定义一个父类对象_a
_B _b; //定义一个子类对象_b
_a._fun = _fA; //父类的对象调用父类的同名函数
_b._a_._fun = _fB; //子类的对象调用子类的同名函数
_A* p2 = &_a; //定义一个父类指针指向父类的对象
p2->_fun(); //调用父类的同名函数
p2 = (_A*)&_b; //让父类指针指向子类的对象,由于类型不匹配所以要进行强转
p2->_fun(); //调用子类的同名函数
}
183、动态编译与静态编译
-
静态编译,编译器在编译可执行文件时,把需要用到的对应动态链接库中的部分提取出来,连接到可执行文件中去,使可执行文件在运行时不需要依赖于动态链接库;
-
动态编译的可执行文件需要附带一个动态链接库,在执行时,需要调用其对应动态链接库的命令。所以其优点一方面是缩小了执行文件本身的体积,另一方面是加快了编译速度,节省了系统资源。缺点是哪怕是很简单的程序,只用到了链接库的一两条命令,也需要附带一个相对庞大的链接库;二是如果其他计算机上没有安装对应的运行库,则用动态编译的可执行文件就不能运行。
184、hello.c 程序的编译过程
以下是一个 hello.c 程序:
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}
在 Unix 系统上,由编译器把源文件转换为目标文件。
gcc -o hello hello.c
这个过程大致如下:

- 预处理阶段:处理以 # 开头的预处理命令;
- 编译阶段:翻译成汇编文件;
- 汇编阶段:将汇编文件翻译成可重定位目标文件;
- 链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
静态链接
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
- 符号解析:每个符号对应于一个函数、一个全局变量或一个静态变量,符号解析的目的是将每个符号引用与一个符号定义关联起来。
- 重定位:链接器通过把每个符号定义与一个内存位置关联起来,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
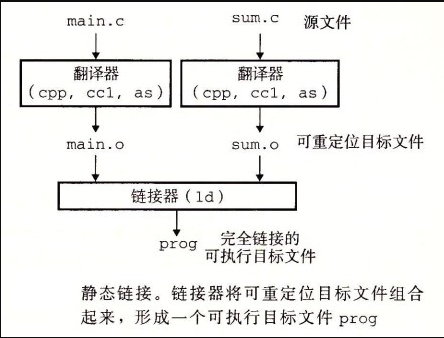
目标文件
- 可执行目标文件:可以直接在内存中执行;
- 可重定位目标文件:可与其它可重定位目标文件在链接阶段合并,创建一个可执行目标文件;
- 共享目标文件:这是一种特殊的可重定位目标文件,可以在运行时被动态加载进内存并链接;
动态链接
静态库有以下两个问题:
- 当静态库更新时那么整个程序都要重新进行链接;
- 对于 printf 这种标准函数库,如果每个程序都要有代码,这会极大浪费资源。
共享库是为了解决静态库的这两个问题而设计的,在 Linux 系统中通常用 .so 后缀来表示,Windows 系统上它们被称为 DLL。它具有以下特点:
- 在给定的文件系统中一个库只有一个文件,所有引用该库的可执行目标文件都共享这个文件,它不会被复制到引用它的可执行文件中;
- 在内存中,一个共享库的 .text 节(已编译程序的机器代码)的一个副本可以被不同的正在运行的进程共享。
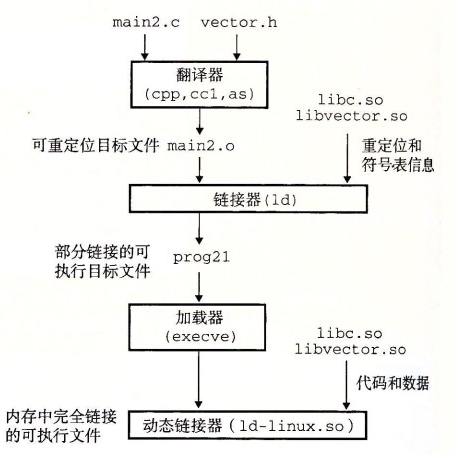
源代码-->预处理-->编译-->优化-->汇编-->链接-->可执行文件
- 预处理
读取c源程序,对其中的伪指令(以#开头的指令)和特殊符号进行处理。包括宏定义替换、条件编译指令、头文件包含指令、特殊符号。 预编译程序所完成的基本上是对源程序的“替代”工作。经过此种替代,生成一个没有宏定义、没有条件编译指令、没有特殊符号的输出文件。.i预处理后的c文件,.ii预处理后的C++文件。
- 编译阶段
编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。.s文件
- 汇编过程
汇编过程实际上指把汇编语言代码翻译成目标机器指令的过程。对于被翻译系统处理的每一个C语言源程序,都将最终经过这一处理而得到相应的目标文件。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。.o目标文件
- 链接阶段
链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够诶操作系统装入执行的统一整体。
185、介绍一下几种典型的锁
读写锁
- 多个读者可以同时进行读
- 写者必须互斥(只允许一个写者写,也不能读者写者同时进行)
- 写者优先于读者(一旦有写者,则后续读者必须等待,唤醒时优先考虑写者)
互斥锁
一次只能一个线程拥有互斥锁,其他线程只有等待
互斥锁是在抢锁失败的情况下主动放弃CPU进入睡眠状态直到锁的状态改变时再唤醒,而操作系统负责线程调度,为了实现锁的状态发生改变时唤醒阻塞的线程或者进程,需要把锁交给操作系统管理,所以互斥锁在加锁操作时涉及上下文的切换。互斥锁实际的效率还是可以让人接受的,加锁的时间大概100ns左右,而实际上互斥锁的一种可能的实现是先自旋一段时间,当自旋的时间超过阀值之后再将线程投入睡眠中,因此在并发运算中使用互斥锁(每次占用锁的时间很短)的效果可能不亚于使用自旋锁
条件变量
互斥锁一个明显的缺点是他只有两种状态:锁定和非锁定。而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,他常和互斥锁一起使用,以免出现竞态条件。当条件不满足时,线程往往解开相应的互斥锁并阻塞线程然后等待条件发生变化。一旦其他的某个线程改变了条件变量,他将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。总的来说互斥锁是线程间互斥的机制,条件变量则是同步机制。
自旋锁
如果进线程无法取得锁,进线程不会立刻放弃CPU时间片,而是一直循环尝试获取锁,直到获取为止。如果别的线程长时期占有锁那么自旋就是在浪费CPU做无用功,但是自旋锁一般应用于加锁时间很短的场景,这个时候效率比较高。
《互斥锁、读写锁、自旋锁、条件变量的特点总结》:https://blog.csdn.net/RUN32875094/article/details/80169978
186、说一下C++左值引用和右值引用
C++11正是通过引入右值引用来优化性能,具体来说是通过移动语义来避免无谓拷贝的问题,通过move语义来将临时生成的左值中的资源无代价的转移到另外一个对象中去,通过完美转发来解决不能按照参数实际类型来转发的问题(同时,完美转发获得的一个好处是可以实现移动语义)。
-
在C++11中所有的值必属于左值、右值两者之一,右值又可以细分为纯右值、将亡值。在C++11中可以取地址的、有名字的就是左值,反之,不能取地址的、没有名字的就是右值(将亡值或纯右值)。举个例子,int a = b+c, a 就是左值,其有变量名为a,通过&a可以获取该变量的地址;表达式b+c、函数int func()的返回值是右值,在其被赋值给某一变量前,我们不能通过变量名找到它,&(b+c)这样的操作则不会通过编译。
-
C++11对C++98中的右值进行了扩充。在C++11中右值又分为纯右值(prvalue,Pure Rvalue)和将亡值(xvalue,eXpiring Value)。其中纯右值的概念等同于我们在C++98标准中右值的概念,指的是临时变量和不跟对象关联的字面量值;将亡值则是C++11新增的跟右值引用相关的表达式,这样表达式通常是将要被移动的对象(移为他用),比如返回右值引用T&&的函数返回值、std::move的返回值,或者转换为T&&的类型转换函数的返回值。将亡值可以理解为通过“盗取”其他变量内存空间的方式获取到的值。在确保其他变量不再被使用、或即将被销毁时,通过“盗取”的方式可以避免内存空间的释放和分配,能够延长变量值的生命期。
-
左值引用就是对一个左值进行引用的类型。右值引用就是对一个右值进行引用的类型,事实上,由于右值通常不具有名字,我们也只能通过引用的方式找到它的存在。右值引用和左值引用都是属于引用类型。无论是声明一个左值引用还是右值引用,都必须立即进行初始化。而其原因可以理解为是引用类型本身自己并不拥有所绑定对象的内存,只是该对象的一个别名。左值引用是具名变量值的别名,而右值引用则是不具名(匿名)变量的别名。左值引用通常也不能绑定到右值,但常量左值引用是个“万能”的引用类型。它可以接受非常量左值、常量左值、右值对其进行初始化。不过常量左值所引用的右值在它的“余生”中只能是只读的。相对地,非常量左值只能接受非常量左值对其进行初始化。
-
右值值引用通常不能绑定到任何的左值,要想绑定一个左值到右值引用,通常需要std::move()将左值强制转换为右值。
左值和右值
左值:表示的是可以获取地址的表达式,它能出现在赋值语句的左边,对该表达式进行赋值。但是修饰符const的出现使得可以声明如下的标识符,它可以取得地址,但是没办法对其进行赋值
const int& a = 10;
右值:表示无法获取地址的对象,有常量值、函数返回值、lambda表达式等。无法获取地址,但不表示其不可改变,当定义了右值的右值引用时就可以更改右值。
左值引用和右值引用
左值引用:传统的C++中引用被称为左值引用
右值引用:C++11中增加了右值引用,右值引用关联到右值时,右值被存储到特定位置,右值引用指向该特定位置,也就是说,右值虽然无法获取地址,但是右值引用是可以获取地址的,该地址表示临时对象的存储位置
这里主要说一下右值引用的特点:
- 特点1:通过右值引用的声明,右值又“重获新生”,其生命周期与右值引用类型变量的生命周期一样长,只要该变量还活着,该右值临时量将会一直存活下去
- 特点2:右值引用独立于左值和右值。意思是右值引用类型的变量可能是左值也可能是右值
- 特点3:T&& t在发生自动类型推断的时候,它是左值还是右值取决于它的初始化。
举个例子:
#include <bits/stdc++.h>
using namespace std;
template<typename T>
void fun(T&& t)
{
cout << t << endl;
}
int getInt()
{
return 5;
}
int main() {
int a = 10;
int& b = a; //b是左值引用
int& c = 10; //错误,c是左值不能使用右值初始化
int&& d = 10; //正确,右值引用用右值初始化
int&& e = a; //错误,e是右值引用不能使用左值初始化
const int& f = a; //正确,左值常引用相当于是万能型,可以用左值或者右值初始化
const int& g = 10;//正确,左值常引用相当于是万能型,可以用左值或者右值初始化
const int&& h = 10; //正确,右值常引用
const int& aa = h;//正确
int& i = getInt(); //错误,i是左值引用不能使用临时变量(右值)初始化
int&& j = getInt(); //正确,函数返回值是右值
fun(10); //此时fun函数的参数t是右值
fun(a); //此时fun函数的参数t是左值
return 0;
}
《c++右值引用以及使用》:https://www.cnblogs.com/likaiming/p/9045642.html
《从4行代码看右值引用》:https://www.cnblogs.com/likaiming/p/9029908.html
187、STL中hashtable的实现?
STL中的hashtable使用的是开链法解决hash冲突问题,如下图所示。
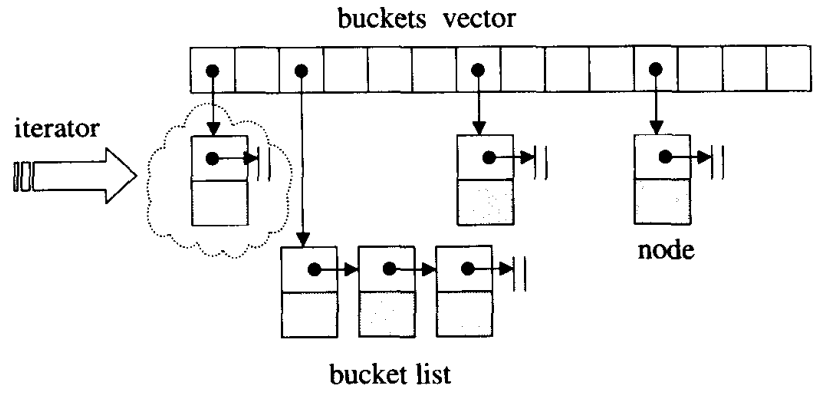
hashtable中的bucket所维护的list既不是list也不是slist,而是其自己定义的由hashtable_node数据结构组成的linked-list,而bucket聚合体本身使用vector进行存储。hashtable的迭代器只提供前进操作,不提供后退操作
在hashtable设计bucket的数量上,其内置了28个质数[53, 97, 193,...,429496729],在创建hashtable时,会根据存入的元素个数选择大于等于元素个数的质数作为hashtable的容量(vector的长度),其中每个bucket所维护的linked-list长度也等于hashtable的容量。如果插入hashtable的元素个数超过了bucket的容量,就要进行重建table操作,即找出下一个质数,创建新的buckets vector,重新计算元素在新hashtable的位置。
《STL源码解析》侯捷
188、简单说一下STL中的traits技法
traits技法利用“内嵌型别“的编程技巧与编译器的template参数推导功能,增强C++未能提供的关于型别认证方面的能力。常用的有iterator_traits和type_traits。
iterator_traits
被称为特性萃取机,能够方面的让外界获取以下5中型别:
- value_type:迭代器所指对象的型别
- difference_type:两个迭代器之间的距离
- pointer:迭代器所指向的型别
- reference:迭代器所引用的型别
- iterator_category:三两句说不清楚,建议看书
type_traits
关注的是型别的特性,例如这个型别是否具备non-trivial defalt ctor(默认构造函数)、non-trivial copy ctor(拷贝构造函数)、non-trivial assignment operator(赋值运算符) 和non-trivial dtor(析构函数),如果答案是否定的,可以采取直接操作内存的方式提高效率,一般来说,type_traits支持以下5中类型的判断:
__type_traits<T>::has_trivial_default_constructor
__type_traits<T>::has_trivial_copy_constructor
__type_traits<T>::has_trivial_assignment_operator
__type_traits<T>::has_trivial_destructor
__type_traits<T>::is_POD_type
由于编译器只针对class object形式的参数进行参数推到,因此上式的返回结果不应该是个bool值,实际上使用的是一种空的结构体:
struct __true_type{};
struct __false_type{};
这两个结构体没有任何成员,不会带来其他的负担,又能满足需求,可谓一举两得
当然,如果我们自行定义了一个Shape类型,也可以针对这个Shape设计type_traits的特化版本
template<> struct __type_traits<Shape>{
typedef __true_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type;
};
《STL源码解析》侯捷 P103-P110
189、STL的两级空间配置器
1、首先明白为什么需要二级空间配置器?
我们知道动态开辟内存时,要在堆上申请,但若是我们需要
频繁的在堆开辟释放内存,则就会在堆上造成很多外部碎片,浪费了内存空间;
每次都要进行调用malloc、free函数等操作,使空间就会增加一些附加信息,降低了空间利用率;
随着外部碎片增多,内存分配器在找不到合适内存情况下需要合并空闲块,浪费了时间,大大降低了效率。
于是就设置了二级空间配置器,当开辟内存<=128bytes时,即视为开辟小块内存,则调用二级空间配置器。
关于STL中一级空间配置器和二级空间配置器的选择上,一般默认选择的为二级空间配置器。 如果大于128字节再转去一级配置器器。
一级配置器
一级空间配置器中重要的函数就是allocate、deallocate、reallocate 。 一级空间配置器是以malloc(),free(),realloc()等C函数执行实际的内存配置 。大致过程是:
1、直接allocate分配内存,其实就是malloc来分配内存,成功则直接返回,失败就调用处理函数
2、如果用户自定义了内存分配失败的处理函数就调用,没有的话就返回异常
3、如果自定义了处理函数就进行处理,完事再继续分配试试
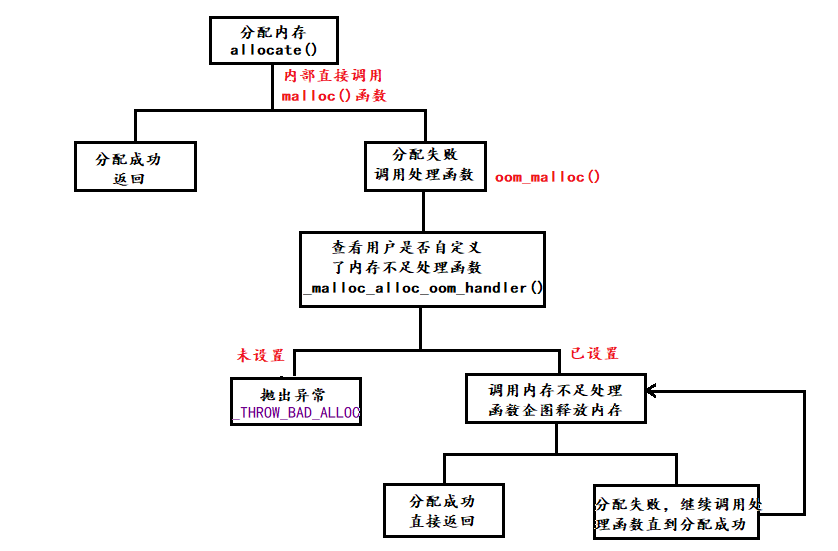
二级配置器
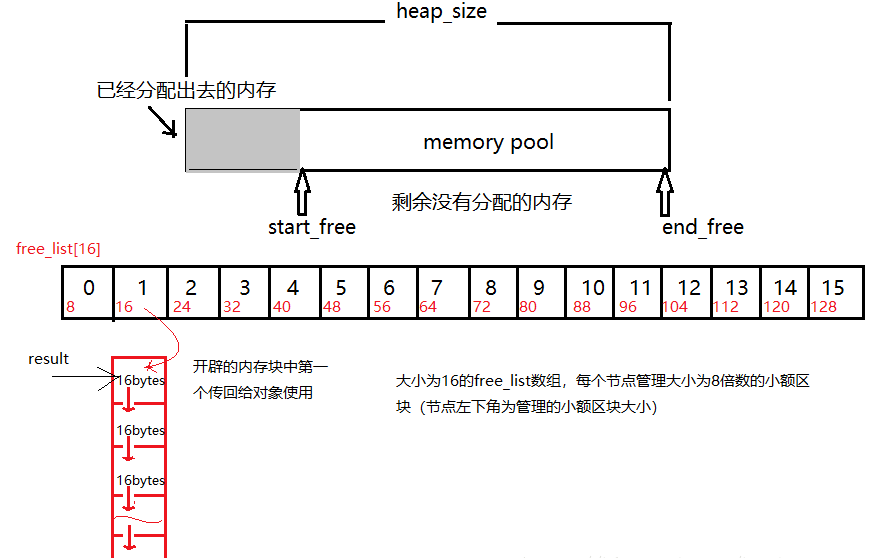
1、维护16条链表,分别是0-15号链表,最小8字节,以8字节逐渐递增,最大128字节,你传入一个字节参数,表示你需要多大的内存,会自动帮你校对到第几号链表(如需要13bytes空间,我们会给它分配16bytes大小),在找到第你个链表后查看链表是否为空,如果不为空直接从对应的free_list中拔出,将已经拨出的指针向后移动一位。
2、对应的free_list为空,先看其内存池是不是空时,如果内存池不为空: (1)先检验它剩余空间是否够20个节点大小(即所需内存大小(提升后) * 20),若足够则直接从内存池中拿出20个节点大小空间,将其中一个分配给用户使用,另外19个当作自由链表中的区块挂在相应的free_list下,这样下次再有相同大小的内存需求时,可直接拨出。 (2)如果不够20个节点大小,则看它是否能满足1个节点大小,如果够的话则直接拿出一个分配给用户,然后从剩余的空间中分配尽可能多的节点挂在相应的free_list中。 (3)如果连一个节点内存都不能满足的话,则将内存池中剩余的空间挂在相应的free_list中(找到相应的free_list),然后再给内存池申请内存,转到3。 3、内存池为空,申请内存 此时二级空间配置器会使用malloc()从heap上申请内存,(一次所申请的内存大小为2 * 所需节点内存大小(提升后)* 20 + 一段额外空间),申请40块,一半拿来用,一半放内存池中。 4、malloc没有成功 在第三种情况下,如果malloc()失败了,说明heap上没有足够空间分配给我们了,这时,二级空间配置器会从比所需节点空间大的free_list中一一搜索,从比它所需节点空间大的free_list中拔除一个节点来使用。如果这也没找到,说明比其大的free_list中都没有自由区块了,那就要调用一级适配器了。
释放时调用deallocate()函数,若释放的n>128,则调用一级空间配置器,否则就直接将内存块挂上自由链表的合适位置。
STL二级空间配置器虽然解决了外部碎片与提高了效率,但它同时增加了一些缺点:
1.因为自由链表的管理问题,它会把我们需求的内存块自动提升为8的倍数,这时若你需要1个字节,它会给你8个字节,即浪费了7个字节,所以它又引入了内部碎片的问题,若相似情况出现很多次,就会造成很多内部碎片;
2.二级空间配置器是在堆上申请大块的狭义内存池,然后用自由链表管理,供现在使用,在程序执行过程中,它将申请的内存一块一块都挂在自由链表上,即不会还给操作系统,并且它的实现中所有成员全是静态的,所以它申请的所有内存只有在进程结束才会释放内存,还给操作系统,由此带来的问题有:1.即我不断的开辟小块内存,最后整个堆上的空间都被挂在自由链表上,若我想开辟大块内存就会失败;2.若自由链表上挂很多内存块没有被使用,当前进程又占着内存不释放,这时别的进程在堆上申请不到空间,也不可以使用当前进程的空闲内存,由此就会引发多种问题。
一级分配器
GC4.9之后就没有第一级了,只有第二级
二级分配器
——default_alloc_template 剖析
有个自动调整的函数:你传入一个字节参数,表示你需要多大的内存,会自动帮你校对到第几号链表(0-15号链表,最小8字节 最大128字节)
allocate函数:如果要分配的内存大于128字节,就转用第一级分配器,否则也就是小于128字节。那么首先判断落在第几号链表,定位到了,先判断链表是不是空,如果是空就需要充值,(调节到8的倍数,默认一次申请20个区块,当然了也要判断20个是不是能够申请到,如果只申请到一个那就直接返回好了,不止一个的话,把第2到第n个挨个挂到当前链表上,第一个返回回去给容器用,n是不大于20的,当然了如果不在1-20之间,那就是内存碎片了,那就先把碎片挂到某一条链表上,然后再重新malloc了,malloc 2*20个块)去内存池去拿或者重新分配。不为空的话
190、 vector与list的区别与应用?怎么找某vector或者list的倒数第二个元素
-
vector数据结构 vector和数组类似,拥有一段连续的内存空间,并且起始地址不变。因此能高效的进行随机存取,时间复杂度为o(1);但因为内存空间是连续的,所以在进行插入和删除操作时,会造成内存块的拷贝,时间复杂度为o(n)。另外,当数组中内存空间不够时,会重新申请一块内存空间并进行内存拷贝。连续存储结构:vector是可以实现动态增长的对象数组,支持对数组高效率的访问和在数组尾端的删除和插入操作,在中间和头部删除和插入相对不易,需要挪动大量的数据。它与数组最大的区别就是vector不需程序员自己去考虑容量问题,库里面本身已经实现了容量的动态增长,而数组需要程序员手动写入扩容函数进形扩容。
-
list数据结构 list是由双向链表实现的,因此内存空间是不连续的。只能通过指针访问数据,所以list的随机存取非常没有效率,时间复杂度为o(n);但由于链表的特点,能高效地进行插入和删除。非连续存储结构:list是一个双链表结构,支持对链表的双向遍历。每个节点包括三个信息:元素本身,指向前一个元素的节点(prev)和指向下一个元素的节点(next)。因此list可以高效率的对数据元素任意位置进行访问和插入删除等操作。由于涉及对额外指针的维护,所以开销比较大。
区别:
vector的随机访问效率高,但在插入和删除时(不包括尾部)需要挪动数据,不易操作。list的访问要遍历整个链表,它的随机访问效率低。但对数据的插入和删除操作等都比较方便,改变指针的指向即可。list是单向的,vector是双向的。vector中的迭代器在使用后就失效了,而list的迭代器在使用之后还可以继续使用。
int mySize = vec.size();vec.at(mySize -2);
list不提供随机访问,所以不能用下标直接访问到某个位置的元素,要访问list里的元素只能遍历,不过你要是只需要访问list的最后N个元素的话,可以用反向迭代器来遍历:
191、STL 中vector删除其中的元素,迭代器如何变化?为什么是两倍扩容?释放空间?
size()函数返回的是已用空间大小,capacity()返回的是总空间大小,capacity()-size()则是剩余的可用空间大小。当size()和capacity()相等,说明vector目前的空间已被用完,如果再添加新元素,则会引起vector空间的动态增长。
由于动态增长会引起重新分配内存空间、拷贝原空间、释放原空间,这些过程会降低程序效率。因此,可以使用reserve(n)预先分配一块较大的指定大小的内存空间,这样当指定大小的内存空间未使用完时,是不会重新分配内存空间的,这样便提升了效率。只有当n>capacity()时,调用reserve(n)才会改变vector容量。
resize()成员函数只改变元素的数目,不改变vector的容量。
1、空的vector对象,size()和capacity()都为0
2、当空间大小不足时,新分配的空间大小为原空间大小的2倍。
3、使用reserve()预先分配一块内存后,在空间未满的情况下,不会引起重新分配,从而提升了效率。
4、当reserve()分配的空间比原空间小时,是不会引起重新分配的。
5、resize()函数只改变容器的元素数目,未改变容器大小。
6、用reserve(size_type)只是扩大capacity值,这些内存空间可能还是“野”的,如果此时使用“[ ]”来访问,则可能会越界。而resize(size_type new_size)会真正使容器具有new_size个对象。
不同的编译器,vector有不同的扩容大小。在vs下是1.5倍,在GCC下是2倍;
空间和时间的权衡。简单来说, 空间分配的多,平摊时间复杂度低,但浪费空间也多。
使用k=2增长因子的问题在于,每次扩展的新尺寸必然刚好大于之前分配的总和,也就是说,之前分配的内存空间不可能被使用。这样对内存不友好。最好把增长因子设为(1,2)
对比可以发现采用采用成倍方式扩容,可以保证常数的时间复杂度,而增加指定大小的容量只能达到O(n)的时间复杂度,因此,使用成倍的方式扩容。
如何释放空间
由于vector的内存占用空间只增不减,比如你首先分配了10,000个字节,然后erase掉后面9,999个,留下一个有效元素,但是内存占用仍为10,000个。所有内存空间是在vector析构时候才能被系统回收。empty()用来检测容器是否为空的,clear()可以清空所有元素。但是即使clear(),vector所占用的内存空间依然如故,无法保证内存的回收。
如果需要空间动态缩小,可以考虑使用deque。如果vector,可以用swap()来帮助你释放内存。
vector(Vec).swap(Vec);
将Vec的内存空洞清除;
vector().swap(Vec);
清空Vec的内存;
192、容器内部删除一个元素
- 顺序容器
erase迭代器不仅使所指向被删除的迭代器失效,而且使被删元素之后的所有迭代器失效(list除外),所以不能使用erase(it++)的方式,但是erase的返回值是下一个有效迭代器;
It = c.erase(it);
- 关联容器
erase迭代器只是被删除元素的迭代器失效,但是返回值是void,所以要采用erase(it++)的方式删除迭代器;
c.erase(it++)
193、STL迭代器如何实现
1、 迭代器是一种抽象的设计理念,通过迭代器可以在不了解容器内部原理的情况下遍历容器,除此之外,STL中迭代器一个最重要的作用就是作为容器与STL算法的粘合剂。
2、 迭代器的作用就是提供一个遍历容器内部所有元素的接口,因此迭代器内部必须保存一个与容器相关联的指针,然后重载各种运算操作来遍历,其中最重要的是*运算符与->运算符,以及++、--等可能需要重载的运算符重载。这和C++中的智能指针很像,智能指针也是将一个指针封装,然后通过引用计数或是其他方法完成自动释放内存的功能。
3、最常用的迭代器的相应型别有五种:value type、difference type、pointer、reference、iterator catagoly;
194、map、set是怎么实现的,红黑树是怎么能够同时实现这两种容器? 为什么使用红黑树?
-
他们的底层都是以红黑树的结构实现,因此插入删除等操作都在O(logn时间内完成,因此可以完成高效的插入删除;
-
在这里我们定义了一个模版参数,如果它是key那么它就是set,如果它是map,那么它就是map;底层是红黑树,实现map的红黑树的节点数据类型是key+value,而实现set的节点数据类型是value
-
因为map和set要求是自动排序的,红黑树能够实现这一功能,而且时间复杂度比较低。
195、如何在共享内存上使用stl标准库?
- 想像一下把STL容器,例如map, vector, list等等,放入共享内存中,IPC一旦有了这些强大的通用数据结构做辅助,无疑进程间通信的能力一下子强大了很多。
我们没必要再为共享内存设计其他额外的数据结构,另外,STL的高度可扩展性将为IPC所驱使。STL容器被良好的封装,默认情况下有它们自己的内存管理方案。
当一个元素被插入到一个STL列表(list)中时,列表容器自动为其分配内存,保存数据。考虑到要将STL容器放到共享内存中,而容器却自己在堆上分配内存。
一个最笨拙的办法是在堆上构造STL容器,然后把容器复制到共享内存,并且确保所有容器的内部分配的内存指向共享内存中的相应区域,这基本是个不可能完成的任务。
- 假设进程A在共享内存中放入了数个容器,进程B如何找到这些容器呢?
一个方法就是进程A把容器放在共享内存中的确定地址上(fixed offsets),则进程B可以从该已知地址上获取容器。另外一个改进点的办法是,进程A先在共享内存某块确定地址上放置一个map容器,然后进程A再创建其他容器,然后给其取个名字和地址一并保存到这个map容器里。
进程B知道如何获取该保存了地址映射的map容器,然后同样再根据名字取得其他容器的地址。
196、map插入方式有几种?
1) 用insert函数插入pair数据,
mapStudent.insert(pair<int, string>(1, "student_one"));
2) 用insert函数插入value_type数据
mapStudent.insert(map<int, string>::value_type (1, "student_one"));
3) 在insert函数中使用make_pair()函数
mapStudent.insert(make_pair(1, "student_one"));
4) 用数组方式插入数据
mapStudent[1] = "student_one";
197、STL中unordered_map(hash_map)和map的区别,hash_map如何解决冲突以及扩容
-
unordered_map和map类似,都是存储的key-value的值,可以通过key快速索引到value。不同的是unordered_map不会根据key的大小进行排序,
-
存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的,而map中的元素是按照二叉搜索树存储,进行中序遍历会得到有序遍历。
-
所以使用时map的key需要定义operator<。而unordered_map需要定义hash_value函数并且重载operator==。但是很多系统内置的数据类型都自带这些,
-
那么如果是自定义类型,那么就需要自己重载operator<或者hash_value()了。
-
如果需要内部元素自动排序,使用map,不需要排序使用unordered_map
-
unordered_map的底层实现是hash_table;
-
hash_map底层使用的是hash_table,而hash_table使用的开链法进行冲突避免,所有hash_map采用开链法进行冲突解决。
-
**什么时候扩容:**当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值---即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
-
**扩容(resize)**就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。
198、vector越界访问下标,map越界访问下标?vector删除元素时会不会释放空间?
- 通过下标访问vector中的元素时不会做边界检查,即便下标越界。
也就是说,下标与first迭代器相加的结果超过了finish迭代器的位置,程序也不会报错,而是返回这个地址中存储的值。
如果想在访问vector中的元素时首先进行边界检查,可以使用vector中的at函数。通过使用at函数不但可以通过下标访问vector中的元素,而且在at函数内部会对下标进行边界检查。
-
map的下标运算符[]的作用是:将key作为下标去执行查找,并返回相应的值;如果不存在这个key,就将一个具有该key和value的某人值插入这个map。
-
erase()函数,只能删除内容,不能改变容量大小;
erase成员函数,它删除了itVect迭代器指向的元素,并且返回要被删除的itVect之后的迭代器,迭代器相当于一个智能指针;clear()函数,只能清空内容,不能改变容量大小;如果要想在删除内容的同时释放内存,那么你可以选择deque容器。
199、map中[]与find的区别?
-
map的下标运算符[]的作用是:将关键码作为下标去执行查找,并返回对应的值;如果不存在这个关键码,就将一个具有该关键码和值类型的默认值的项插入这个map。
-
map的find函数:用关键码执行查找,找到了返回该位置的迭代器;如果不存在这个关键码,就返回尾迭代器。
200、 STL中list与queue之间的区别
-
list不再能够像vector一样以普通指针作为迭代器,因为其节点不保证在存储空间中连续存在;
-
list插入操作和结合才做都不会造成原有的list迭代器失效;
-
list不仅是一个双向链表,而且还是一个环状双向链表,所以它只需要一个指针;
-
list不像vector那样有可能在空间不足时做重新配置、数据移动的操作,所以插入前的所有迭代器在插入操作之后都仍然有效;
-
deque是一种双向开口的连续线性空间,所谓双向开口,意思是可以在头尾两端分别做元素的插入和删除操作;可以在头尾两端分别做元素的插入和删除操作;
-
deque和vector最大的差异,一在于deque允许常数时间内对起头端进行元素的插入或移除操作,二在于deque没有所谓容量概念,因为它是动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来,deque没有所谓的空间保留功能。
201、STL中的allocator,deallocator
-
第一级配置器直接使用malloc()、free()和relloc(),第二级配置器视情况采用不同的策略:当配置区块超过128bytes时,视之为足够大,便调用第一级配置器;当配置器区块小于128bytes时,为了降低额外负担,使用复杂的内存池整理方式,而不再用一级配置器;
-
第二级配置器主动将任何小额区块的内存需求量上调至8的倍数,并维护16个free-list,各自管理大小为8~128bytes的小额区块;
-
空间配置函数allocate(),首先判断区块大小,大于128就直接调用第一级配置器,小于128时就检查对应的free-list。如果free-list之内有可用区块,就直接拿来用,如果没有可用区块,就将区块大小调整至8的倍数,然后调用refill(),为free-list重新分配空间;
-
空间释放函数deallocate(),该函数首先判断区块大小,大于128bytes时,直接调用一级配置器,小于128bytes就找到对应的free-list然后释放内存。
202、STL中hash_map扩容发生什么?
-
hash table表格内的元素称为桶(bucket),而由桶所链接的元素称为节点(node),其中存入桶元素的容器为stl本身很重要的一种序列式容器——vector容器。之所以选择vector为存放桶元素的基础容器,主要是因为vector容器本身具有动态扩容能力,无需人工干预。
-
向前操作:首先尝试从目前所指的节点出发,前进一个位置(节点),由于节点被安置于list内,所以利用节点的next指针即可轻易完成前进操作,如果目前正巧是list的尾端,就跳至下一个bucket身上,那正是指向下一个list的头部节点。
203、常见容器性质总结?
1.vector 底层数据结构为数组 ,支持快速随机访问
2.list 底层数据结构为双向链表,支持快速增删
3.deque 底层数据结构为一个中央控制器和多个缓冲区,详细见STL源码剖析P146,支持首尾(中间不能)快速增删,也支持随机访问
deque是一个双端队列(double-ended queue),也是在堆中保存内容的.它的保存形式如下:
[堆1] --> [堆2] -->[堆3] --> ...
每个堆保存好几个元素,然后堆和堆之间有指针指向,看起来像是list和vector的结合品.
4.stack 底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时
5.queue 底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时(stack和queue其实是适配器,而不叫容器,因为是对容器的再封装)
6.priority_queue 的底层数据结构一般为vector为底层容器,堆heap为处理规则来管理底层容器实现
7.set 底层数据结构为红黑树,有序,不重复
8.multiset 底层数据结构为红黑树,有序,可重复
9.map 底层数据结构为红黑树,有序,不重复
10.multimap 底层数据结构为红黑树,有序,可重复
11.unordered_set 底层数据结构为hash表,无序,不重复
12.unordered_multiset 底层数据结构为hash表,无序,可重复
13.unordered_map 底层数据结构为hash表,无序,不重复
14.unordered_multimap 底层数据结构为hash表,无序,可重复
204、vector的增加删除都是怎么做的?为什么是1.5或者是2倍?
-
新增元素:vector通过一个连续的数组存放元素,如果集合已满,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,在插入新增的元素;
-
对vector的任何操作,一旦引起空间重新配置,指向原vector的所有迭代器就都失效了 ;
-
初始时刻vector的capacity为0,塞入第一个元素后capacity增加为1;
-
不同的编译器实现的扩容方式不一样,VS2015中以1.5倍扩容,GCC以2倍扩容。
对比可以发现采用采用成倍方式扩容,可以保证常数的时间复杂度,而增加指定大小的容量只能达到O(n)的时间复杂度,因此,使用成倍的方式扩容。
-
考虑可能产生的堆空间浪费,成倍增长倍数不能太大,使用较为广泛的扩容方式有两种,以2二倍的方式扩容,或者以1.5倍的方式扩容。
-
以2倍的方式扩容,导致下一次申请的内存必然大于之前分配内存的总和,导致之前分配的内存不能再被使用,所以最好倍增长因子设置为(1,2)之间:
-
向量容器vector的成员函数pop_back()可以删除最后一个元素.
-
而函数erase()可以删除由一个iterator指出的元素,也可以删除一个指定范围的元素。
-
还可以采用通用算法remove()来删除vector容器中的元素.
-
不同的是:采用remove一般情况下不会改变容器的大小,而pop_back()与erase()等成员函数会改变容器的大小。
205、说一下STL每种容器对应的迭代器
| 容器 | 迭代器 |
|---|---|
| vector、deque | 随机访问迭代器 |
| stack、queue、priority_queue | 无 |
| list、(multi)set/map | 双向迭代器 |
| unordered_(multi)set/map、forward_list | 前向迭代器 |
206、STL中vector的实现
vector是一种序列式容器,其数据安排以及操作方式与array非常类似,两者的唯一差别就是对于空间运用的灵活性,众所周知,array占用的是静态空间,一旦配置了就不可以改变大小,如果遇到空间不足的情况还要自行创建更大的空间,并手动将数据拷贝到新的空间中,再把原来的空间释放。vector则使用灵活的动态空间配置,维护一块连续的线性空间,在空间不足时,可以自动扩展空间容纳新元素,做到按需供给。其在扩充空间的过程中仍然需要经历:重新配置空间,移动数据,释放原空间等操作。这里需要说明一下动态扩容的规则:以原大小的两倍配置另外一块较大的空间(或者旧长度+新增元素的个数),源码:
const size_type len = old_size + max(old_size, n);
Vector扩容倍数与平台有关,在Win + VS 下是 1.5倍,在 Linux + GCC 下是 2 倍
测试代码:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
//在Linux + GCC下
vector<int> res(2,0);
cout << res.capacity() <<endl; //2
res.push_back(1);
cout << res.capacity() <<endl;//4
res.push_back(2);
res.push_back(3);
cout << res.capacity() <<endl;//8
return 0;
//在 win 10 + VS2019下
vector<int> res(2,0);
cout << res.capacity() <<endl; //2
res.push_back(1);
cout << res.capacity() <<endl;//3
res.push_back(2);
res.push_back(3);
cout << res.capacity() <<endl;//6
}
运行上述代码,一开始配置了一块长度为2的空间,接下来插入一个数据,长度变为原来的两倍,为4,此时已占用的长度为3,再继续两个数据,此时长度变为8,可以清晰的看到空间的变化过程
需要注意的是,频繁对vector调用push_back()对性能是有影响的,这是因为每插入一个元素,如果空间够用的话还能直接插入,若空间不够用,则需要重新配置空间,移动数据,释放原空间等操作,对程序性能会造成一定的影响
《STL源码剖析》 侯捷 P115-128
207、STL中slist的实现
list是双向链表,而slist(single linked list)是单向链表,它们的主要区别在于:前者的迭代器是双向的Bidirectional iterator,后者的迭代器属于单向的Forward iterator。虽然slist的很多功能不如list灵活,但是其所耗用的空间更小,操作更快。
根据STL的习惯,插入操作会将新元素插入到指定位置之前,而非之后,然而slist是不能回头的,只能往后走,因此在slist的其他位置插入或者移除元素是十分不明智的,但是在slist开头却是可取的,slist特别提供了insert_after()和erase_after供灵活应用。考虑到效率问题,slist只提供push_front()操作,元素插入到slist后,存储的次序和输入的次序是相反的
slist的单向迭代器如下图所示:
slist默认采用alloc空间配置器配置节点的空间,其数据结构主要代码如下
template <class T, class Allco = alloc>
class slist
{
...
private:
...
static list_node* create_node(const value_type& x){}//配置空间、构造元素
static void destroy_node(list_node* node){}//析构函数、释放空间
private:
list_node_base head; //头部
public:
iterator begin(){}
iterator end(){}
size_type size(){}
bool empty(){}
void swap(slist& L){}//交换两个slist,只需要换head即可
reference front(){} //取头部元素
void push_front(const value& x){}//头部插入元素
void pop_front(){}//从头部取走元素
...
}
举个例子:
#include <forward_list>
#include <algorithm>
#include <iostream>
using namespace std;
int main()
{
forward_list<int> fl;
fl.push_front(1);
fl.push_front(3);
fl.push_front(2);
fl.push_front(6);
fl.push_front(5);
forward_list<int>::iterator ite1 = fl.begin();
forward_list<int>::iterator ite2 = fl.end();
for(;ite1 != ite2; ++ite1)
{
cout << *ite1 <<" "; // 5 6 2 3 1
}
cout << endl;
ite1 = find(fl.begin(), fl.end(), 2); //寻找2的位置
if (ite1 != ite2)
fl.insert_after(ite1, 99);
for (auto it : fl)
{
cout << it << " "; //5 6 2 99 3 1
}
cout << endl;
ite1 = find(fl.begin(), fl.end(), 6); //寻找6的位置
if (ite1 != ite2)
fl.erase_after(ite1);
for (auto it : fl)
{
cout << it << " "; //5 6 99 3 1
}
cout << endl;
return 0;
}
需要注意的是C++标准委员会没有采用slist的名称,forward_list在C++ 11中出现,它与slist的区别是没有size()方法。
《STL源码剖析》 侯捷
208、STL中list的实现
相比于vector的连续线型空间,list显得复杂许多,但是它的好处在于插入或删除都只作用于一个元素空间,因此list对空间的运用是十分精准的,对任何位置元素的插入和删除都是常数时间。list不能保证节点在存储空间中连续存储,也拥有迭代器,迭代器的“++”、“--”操作对于的是指针的操作,list提供的迭代器类型是双向迭代器:Bidirectional iterators。
list节点的结构见如下源码:
template <class T>
struct __list_node{
typedef void* void_pointer;
void_pointer prev;
void_pointer next;
T data;
}
从源码可看出list显然是一个双向链表。list与vector的另一个区别是,在插入和接合操作之后,都不会造成原迭代器失效,而vector可能因为空间重新配置导致迭代器失效。
此外list也是一个环形链表,因此只要一个指针便能完整表现整个链表。list中node节点指针始终指向尾端的一个空白节点,因此是一种“前闭后开”的区间结构
list的空间管理默认采用alloc作为空间配置器,为了方便的以节点大小为配置单位,还定义一个list_node_allocator函数可一次性配置多个节点空间
由于list的双向特性,其支持在头部(front)和尾部(back)两个方向进行push和pop操作,当然还支持erase,splice,sort,merge,reverse,sort等操作,这里不再详细阐述。
《STL源码剖析》 侯捷 P128-142
209、STL中的deque的实现
vector是单向开口(尾部)的连续线性空间,deque则是一种双向开口的连续线性空间,虽然vector也可以在头尾进行元素操作,但是其头部操作的效率十分低下(主要是涉及到整体的移动)
deque和vector的最大差异一个是deque运行在常数时间内对头端进行元素操作,二是deque没有容量的概念,它是动态地以分段连续空间组合而成,可以随时增加一段新的空间并链接起来
deque虽然也提供随机访问的迭代器,但是其迭代器并不是普通的指针,其复杂程度比vector高很多,因此除非必要,否则一般使用vector而非deque。如果需要对deque排序,可以先将deque中的元素复制到vector中,利用sort对vector排序,再将结果复制回deque
deque由一段一段的定量连续空间组成,一旦需要增加新的空间,只要配置一段定量连续空间拼接在头部或尾部即可,因此deque的最大任务是如何维护这个整体的连续性
deque的数据结构如下:
class deque
{
...
protected:
typedef pointer* map_pointer;//指向map指针的指针
map_pointer map;//指向map
size_type map_size;//map的大小
public:
...
iterator begin();
itertator end();
...
}
deque内部有一个指针指向map,map是一小块连续空间,其中的每个元素称为一个节点,node,每个node都是一个指针,指向另一段较大的连续空间,称为缓冲区,这里就是deque中实际存放数据的区域,默认大小512bytes。整体结构如上图所示。
deque的迭代器数据结构如下:
struct __deque_iterator
{
...
T* cur;//迭代器所指缓冲区当前的元素
T* first;//迭代器所指缓冲区第一个元素
T* last;//迭代器所指缓冲区最后一个元素
map_pointer node;//指向map中的node
...
}
从deque的迭代器数据结构可以看出,为了保持与容器联结,迭代器主要包含上述4个元素
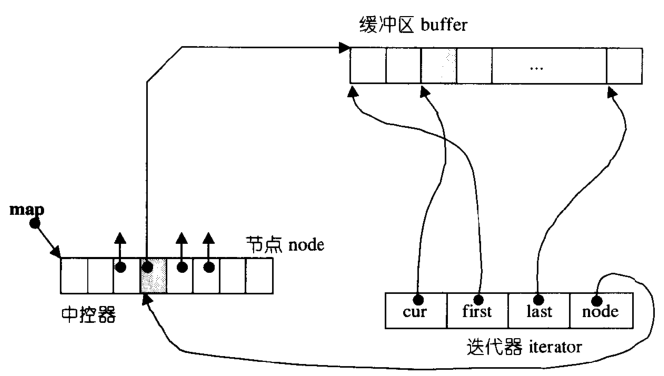
deque迭代器的“++”、“--”操作是远比vector迭代器繁琐,其主要工作在于缓冲区边界,如何从当前缓冲区跳到另一个缓冲区,当然deque内部在插入元素时,如果map中node数量全部使用完,且node指向的缓冲区也没有多余的空间,这时会配置新的map(2倍于当前+2的数量)来容纳更多的node,也就是可以指向更多的缓冲区。在deque删除元素时,也提供了元素的析构和空闲缓冲区空间的释放等机制。
《STL源码剖析》 侯捷 P143-164
210、STL中stack和queue的实现
stack
stack(栈)是一种先进后出(First In Last Out)的数据结构,只有一个入口和出口,那就是栈顶,除了获取栈顶元素外,没有其他方法可以获取到内部的其他元素,其结构图如下:
stack这种单向开口的数据结构很容易由双向开口的deque和list形成,只需要根据stack的性质对应移除某些接口即可实现,stack的源码如下:
template <class T, class Sequence = deque<T> >
class stack
{
...
protected:
Sequence c;
public:
bool empty(){return c.empty();}
size_type size() const{return c.size();}
reference top() const {return c.back();}
const_reference top() const{return c.back();}
void push(const value_type& x){c.push_back(x);}
void pop(){c.pop_back();}
};
从stack的数据结构可以看出,其所有操作都是围绕Sequence完成,而Sequence默认是deque数据结构。stack这种“修改某种接口,形成另一种风貌”的行为,成为adapter(配接器)。常将其归类为container adapter而非container
stack除了默认使用deque作为其底层容器之外,也可以使用双向开口的list,只需要在初始化stack时,将list作为第二个参数即可。由于stack只能操作顶端的元素,因此其内部元素无法被访问,也不提供迭代器。
queue
queue(队列)是一种先进先出(First In First Out)的数据结构,只有一个入口和一个出口,分别位于最底端和最顶端,出口元素外,没有其他方法可以获取到内部的其他元素,其结构图如下:
类似的,queue这种“先进先出”的数据结构很容易由双向开口的deque和list形成,只需要根据queue的性质对应移除某些接口即可实现,queue的源码如下:
template <class T, class Sequence = deque<T> >
class queue
{
...
protected:
Sequence c;
public:
bool empty(){return c.empty();}
size_type size() const{return c.size();}
reference front() const {return c.front();}
const_reference front() const{return c.front();}
void push(const value_type& x){c.push_back(x);}
void pop(){c.pop_front();}
};
从queue的数据结构可以看出,其所有操作都也都是是围绕Sequence完成,Sequence默认也是deque数据结构。queue也是一类container adapter。
同样,queue也可以使用list作为底层容器,不具有遍历功能,没有迭代器。
《STL源码剖析》 侯捷
211、STL中的heap的实现
heap(堆)并不是STL的容器组件,是priority queue(优先队列)的底层实现机制,因为binary max heap(大根堆)总是最大值位于堆的根部,优先级最高。
binary heap本质是一种complete binary tree(完全二叉树),整棵binary tree除了最底层的叶节点之外,都是填满的,但是叶节点从左到右不会出现空隙,如下图所示就是一颗完全二叉树
完全二叉树内没有任何节点漏洞,是非常紧凑的,这样的一个好处是可以使用array来存储所有的节点,因为当其中某个节点位于$i$处,其左节点必定位于$2i$处,右节点位于$2i+1$处,父节点位于$i/2$(向下取整)处。这种以array表示tree的方式称为隐式表述法。
因此我们可以使用一个array和一组heap算法来实现max heap(每个节点的值大于等于其子节点的值)和min heap(每个节点的值小于等于其子节点的值)。由于array不能动态的改变空间大小,用vector代替array是一个不错的选择。
那heap算法有哪些?常见有的插入、弹出、排序和构造算法,下面一一进行描述。
push_heap插入算法
由于完全二叉树的性质,新插入的元素一定是位于树的最底层作为叶子节点,并填补由左至右的第一个空格。事实上,在刚执行插入操作时,新元素位于底层vector的end()处,之后是一个称为percolate up(上溯)的过程,举个例子如下图:
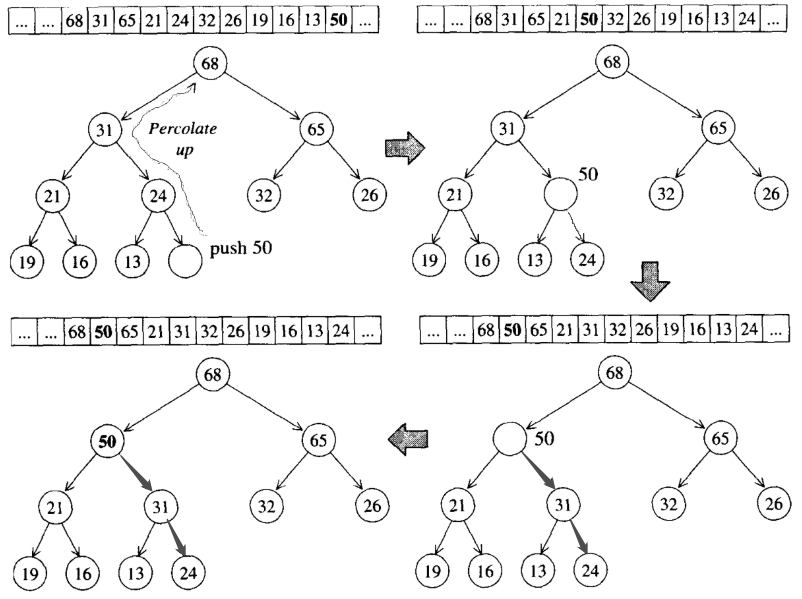
新元素50在插入堆中后,先放在vector的end()存着,之后执行上溯过程,调整其根结点的位置,以便满足max heap的性质,如果了解大根堆的话,这个原理跟大根堆的调整过程是一样的。
pop_heap算法
heap的pop操作实际弹出的是根节点吗,但在heap内部执行pop_heap时,只是将其移动到vector的最后位置,然后再为这个被挤走的元素找到一个合适的安放位置,使整颗树满足完全二叉树的条件。这个被挤掉的元素首先会与根结点的两个子节点比较,并与较大的子节点更换位置,如此一直往下,直到这个被挤掉的元素大于左右两个子节点,或者下放到叶节点为止,这个过程称为percolate down(下溯)。举个例子:
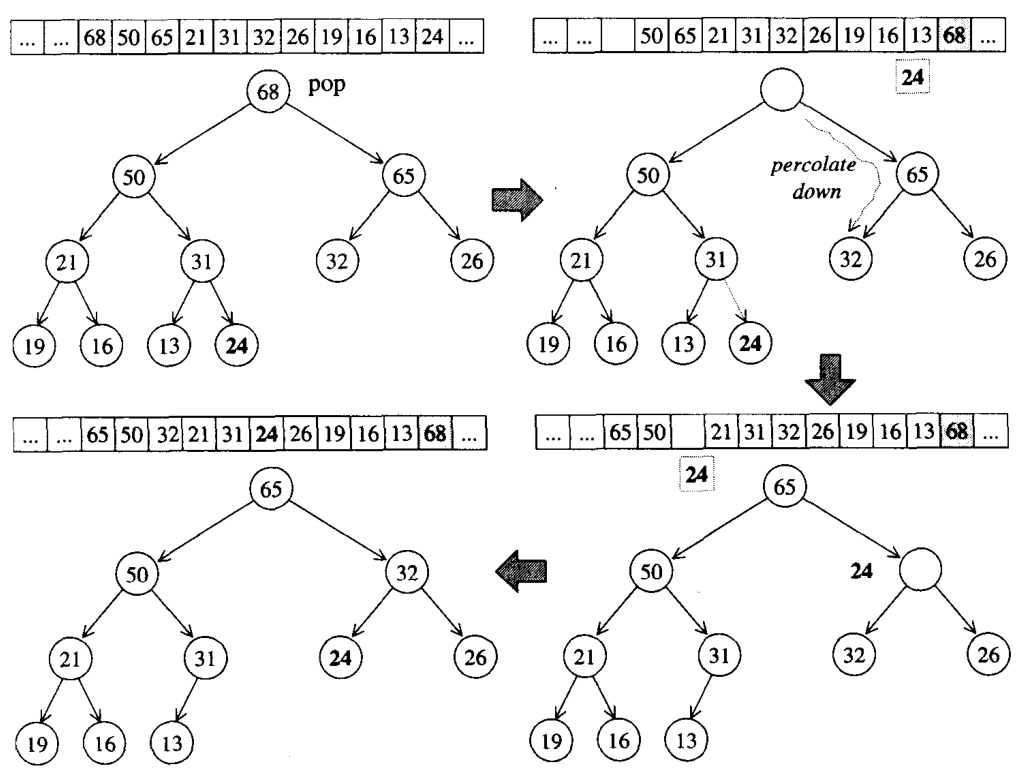
根节点68被pop之后,移到了vector的最底部,将24挤出,24被迫从根节点开始与其子节点进行比较,直到找到合适的位置安身,需要注意的是pop之后元素并没有被移走,如果要将其移走,可以使用pop_back()。
sort算法
一言以蔽之,因为pop_heap可以将当前heap中的最大值置于底层容器vector的末尾,heap范围减1,那么不断的执行pop_heap直到树为空,即可得到一个递增序列。
make_heap算法
将一段数据转化为heap,一个一个数据插入,调用上面说的两种percolate算法即可。
代码实测:
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
vector<int> v = { 0,1,2,3,4,5,6 };
make_heap(v.begin(), v.end()); //以vector为底层容器
for (auto i : v)
{
cout << i << " "; // 6 4 5 3 1 0 2
}
cout << endl;
v.push_back(7);
push_heap(v.begin(), v.end());
for (auto i : v)
{
cout << i << " "; // 7 6 5 4 1 0 2 3
}
cout << endl;
pop_heap(v.begin(), v.end());
cout << v.back() << endl; // 7
v.pop_back();
for (auto i : v)
{
cout << i << " "; // 6 4 5 3 1 0 2
}
cout << endl;
sort_heap(v.begin(), v.end());
for (auto i : v)
{
cout << i << " "; // 0 1 2 3 4 5 6
}
return 0;
}
《STL源码剖析》 侯捷
212、STL中的priority_queue的实现
priority_queue,优先队列,是一个拥有权值观念的queue,它跟queue一样是顶部入口,底部出口,在插入元素时,元素并非按照插入次序排列,它会自动根据权值(通常是元素的实值)排列,权值最高,排在最前面,如下图所示。
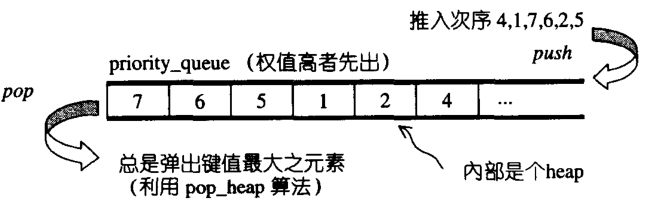
默认情况下,priority_queue使用一个max-heap完成,底层容器使用的是一般为vector为底层容器,堆heap为处理规则来管理底层容器实现 。priority_queue的这种实现机制导致其不被归为容器,而是一种容器配接器。关键的源码如下:
template <class T, class Squence = vector<T>,
class Compare = less<typename Sequence::value_tyoe> >
class priority_queue{
...
protected:
Sequence c; // 底层容器
Compare comp; // 元素大小比较标准
public:
bool empty() const {return c.empty();}
size_type size() const {return c.size();}
const_reference top() const {return c.front()}
void push(const value_type& x)
{
c.push_heap(x);
push_heap(c.begin(), c.end(),comp);
}
void pop()
{
pop_heap(c.begin(), c.end(),comp);
c.pop_back();
}
};
priority_queue的所有元素,进出都有一定的规则,只有queue顶端的元素(权值最高者),才有机会被外界取用,它没有遍历功能,也不提供迭代器
举个例子:
#include <queue>
#include <iostream>
using namespace std;
int main()
{
int ia[9] = {0,4,1,2,3,6,5,8,7 };
priority_queue<int> pq(ia, ia + 9);
cout << pq.size() <<endl; // 9
for(int i = 0; i < pq.size(); i++)
{
cout << pq.top() << " "; // 8 8 8 8 8 8 8 8 8
}
cout << endl;
while (!pq.empty())
{
cout << pq.top() << ' ';// 8 7 6 5 4 3 2 1 0
pq.pop();
}
return 0;
}
《STL源码剖析》 侯捷
213、STL中set的实现?
STL中的容器可分为序列式容器(sequence)和关联式容器(associative),set属于关联式容器。
set的特性是,所有元素都会根据元素的值自动被排序(默认升序),set元素的键值就是实值,实值就是键值,set不允许有两个相同的键值
set不允许迭代器修改元素的值,其迭代器是一种constance iterators
标准的STL set以RB-tree(红黑树)作为底层机制,几乎所有的set操作行为都是转调用RB-tree的操作行为,这里补充一下红黑树的特性:
- 每个节点不是红色就是黑色
- 根结点为黑色
- 如果节点为红色,其子节点必为黑
- 任一节点至(NULL)树尾端的任何路径,所含的黑节点数量必相同
关于红黑树的具体操作过程,比较复杂读者可以翻阅《算法导论》详细了解。
举个例子:
#include <set>
#include <iostream>
using namespace std;
int main()
{
int i;
int ia[5] = { 1,2,3,4,5 };
set<int> s(ia, ia + 5);
cout << s.size() << endl; // 5
cout << s.count(3) << endl; // 1
cout << s.count(10) << endl; // 0
s.insert(3); //再插入一个3
cout << s.size() << endl; // 5
cout << s.count(3) << endl; // 1
s.erase(1);
cout << s.size() << endl; // 4
set<int>::iterator b = s.begin();
set<int>::iterator e = s.end();
for (; b != e; ++b)
cout << *b << " "; // 2 3 4 5
cout << endl;
b = find(s.begin(), s.end(), 5);
if (b != s.end())
cout << "5 found" << endl; // 5 found
b = s.find(2);
if (b != s.end())
cout << "2 found" << endl; // 2 found
b = s.find(1);
if (b == s.end())
cout << "1 not found" << endl; // 1 not found
return 0;
}
关联式容器尽量使用其自身提供的find()函数查找指定的元素,效率更高,因为STL提供的find()函数是一种顺序搜索算法。
《STL源码剖析》 侯捷
214、STL中map的实现
map的特性是所有元素会根据键值进行自动排序。map中所有的元素都是pair,拥有键值(key)和实值(value)两个部分,并且不允许元素有相同的key
一旦map的key确定了,那么是无法修改的,但是可以修改这个key对应的value,因此map的迭代器既不是constant iterator,也不是mutable iterator
标准STL map的底层机制是RB-tree(红黑树),另一种以hash table为底层机制实现的称为hash_map。map的架构如下图所示
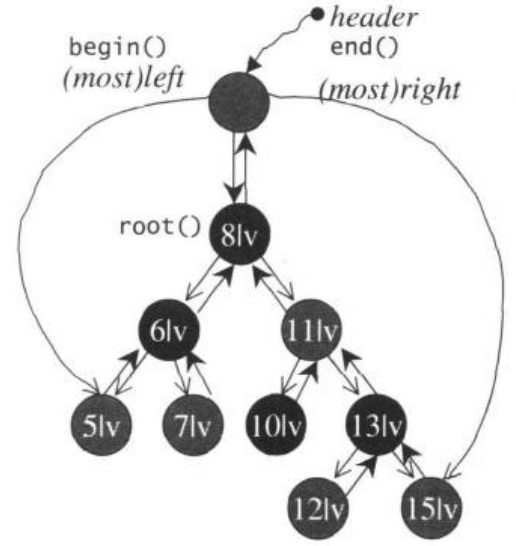
map的在构造时缺省采用递增排序key,也使用alloc配置器配置空间大小,需要注意的是在插入元素时,调用的是红黑树中的insert_unique()方法,而非insert_euqal()(multimap使用)
举个例子:
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main()
{
map<string, int> maps;
//插入若干元素
maps["jack"] = 1;
maps["jane"] = 2;
maps["july"] = 3;
//以pair形式插入
pair<string, int> p("david", 4);
maps.insert(p);
//迭代输出元素
map<string, int>::iterator iter = maps.begin();
for (; iter != maps.end(); ++iter)
{
cout << iter->first << " ";
cout << iter->second << "--"; //david 4--jack 1--jane 2--july 3--
}
cout << endl;
//使用subscipt操作取实值
int num = maps["july"];
cout << num << endl; // 3
//查找某key
iter = maps.find("jane");
if(iter != maps.end())
cout << iter->second << endl; // 2
//修改实值
iter->second = 100;
int num2 = maps["jane"]; // 100
cout << num2 << endl;
return 0;
}
需要注意的是subscript(下标)操作既可以作为左值运用(修改内容)也可以作为右值运用(获取实值)。例如:
maps["abc"] = 1; //左值运用
int num = masp["abd"]; //右值运用
无论如何,subscript操作符都会先根据键值找出实值,源码如下:
...
T& operator[](const key_type& k)
{
return (*((insert(value_type(k, T()))).first)).second;
}
...
代码运行过程是:首先根据键值和实值做出一个元素,这个元素的实值未知,因此产生一个与实值型别相同的临时对象替代:
value_type(k, T());
再将这个对象插入到map中,并返回一个pair:
pair<iterator,bool> insert(value_type(k, T()));
pair第一个元素是迭代器,指向当前插入的新元素,如果插入成功返回true,此时对应左值运用,根据键值插入实值。插入失败(重复插入)返回false,此时返回的是已经存在的元素,则可以取到它的实值
(insert(value_type(k, T()))).first; //迭代器
*((insert(value_type(k, T()))).first); //解引用
(*((insert(value_type(k, T()))).first)).second; //取出实值
由于这个实值是以引用方式传递,因此作为左值或者右值都可以
《STL源码剖析》 侯捷
215、set和map的区别,multimap和multiset的区别
set只提供一种数据类型的接口,但是会将这一个元素分配到key和value上,而且它的compare_function用的是 identity()函数,这个函数是输入什么输出什么,这样就实现了set机制,set的key和value其实是一样的了。其实他保存的是两份元素,而不是只保存一份元素
map则提供两种数据类型的接口,分别放在key和value的位置上,他的比较function采用的是红黑树的comparefunction(),保存的确实是两份元素。
他们两个的insert都是采用红黑树的insert_unique() 独一无二的插入 。
multimap和map的唯一区别就是:multimap调用的是红黑树的insert_equal(),可以重复插入而map调用的则是独一无二的插入insert_unique(),multiset和set也一样,底层实现都是一样的,只是在插入的时候调用的方法不一样。
红黑树概念
面试时候现场写红黑树代码的概率几乎为0,但是红黑树一些基本概念还是需要掌握的。
1、它是二叉排序树(继承二叉排序树特显):
-
若左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值。
-
若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值。
-
左、右子树也分别为二叉排序树。
2、它满足如下几点要求:
-
树中所有节点非红即黑。
-
根节点必为黑节点。
-
红节点的子节点必为黑(黑节点子节点可为黑)。
-
从根到NULL的任何路径上黑结点数相同。
3、查找时间一定可以控制在O(logn)。
216、STL中unordered_map和map的区别和应用场景
map支持键值的自动排序,底层机制是红黑树,红黑树的查询和维护时间复杂度均为$O(logn)$,但是空间占用比较大,因为每个节点要保持父节点、孩子节点及颜色的信息
unordered_map是C++ 11新添加的容器,底层机制是哈希表,通过hash函数计算元素位置,其查询时间复杂度为O(1),维护时间与bucket桶所维护的list长度有关,但是建立hash表耗时较大
从两者的底层机制和特点可以看出:map适用于有序数据的应用场景,unordered_map适用于高效查询的应用场景
217、hashtable中解决冲突有哪些方法?
记住前三个:
线性探测
使用hash函数计算出的位置如果已经有元素占用了,则向后依次寻找,找到表尾则回到表头,直到找到一个空位
开链
每个表格维护一个list,如果hash函数计算出的格子相同,则按顺序存在这个list中
再散列
发生冲突时使用另一种hash函数再计算一个地址,直到不冲突
二次探测
使用hash函数计算出的位置如果已经有元素占用了,按照$1^2$、$2^2$、$3^2$...的步长依次寻找,如果步长是随机数序列,则称之为伪随机探测
公共溢出区
一旦hash函数计算的结果相同,就放入公共溢出区
😥操作系统
1、进程、线程和协程的区别和联系
| 进程 | 线程 | 协程 | |
|---|---|---|---|
| 定义 | 资源分配和拥有的基本单位 | 程序执行的基本单位 | 用户态的轻量级线程,线程内部调度的基本单位 |
| 切换情况 | 进程CPU环境(栈、寄存器、页表和文件句柄等)的保存以及新调度的进程CPU环境的设置 | 保存和设置程序计数器、少量寄存器和栈的内容 | 先将寄存器上下文和栈保存,等切换回来的时候再进行恢复 |
| 切换者 | 操作系统 | 操作系统 | 用户 |
| 切换过程 | 用户态->内核态->用户态 | 用户态->内核态->用户态 | 用户态(没有陷入内核) |
| 调用栈 | 内核栈 | 内核栈 | 用户栈 |
| 拥有资源 | CPU资源、内存资源、文件资源和句柄等 | 程序计数器、寄存器、栈和状态字 | 拥有自己的寄存器上下文和栈 |
| 并发性 | 不同进程之间切换实现并发,各自占有CPU实现并行 | 一个进程内部的多个线程并发执行 | 同一时间只能执行一个协程,而其他协程处于休眠状态,适合对任务进行分时处理 |
| 系统开销 | 切换虚拟地址空间,切换内核栈和硬件上下文,CPU高速缓存失效、页表切换,开销很大 | 切换时只需保存和设置少量寄存器内容,因此开销很小 | 直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快 |
| 通信方面 | 进程间通信需要借助操作系统 | 线程间可以直接读写进程数据段(如全局变量)来进行通信 | 共享内存、消息队列 |
1、进程是资源调度的基本单位,运行一个可执行程序会创建一个或多个进程,进程就是运行起来的可执行程序
2、线程是程序执行的基本单位,是轻量级的进程。每个进程中都有唯一的主线程,且只能有一个,主线程和进程是相互依存的关系,主线程结束进程也会结束。多提一句:协程是用户态的轻量级线程,线程内部调度的基本单位
2、线程与进程的比较
1、线程启动速度快,轻量级
2、线程的系统开销小
3、线程使用有一定难度,需要处理数据一致性问题
4、同一线程共享的有堆、全局变量、静态变量、指针,引用、文件等,而独自占有栈
3、一个进程可以创建多少线程,和什么有关?
理论上,一个进程可用虚拟空间是2G,默认情况下,线程的栈的大小是1MB,所以理论上最多只能创建2048个线程。如果要创建多于2048的话,必须修改编译器的设置。
因此,一个进程可以创建的线程数由可用虚拟空间和线程的栈的大小共同决定,只要虚拟空间足够,那么新线程的建立就会成功。如果需要创建超过2K以上的线程,减小你线程栈的大小就可以实现了,虽然在一般情况下,你不需要那么多的线程。过多的线程将会导致大量的时间浪费在线程切换上,给程序运行效率带来负面影响。
《一个进程到底能创建多少线程》:https://www.cnblogs.com/Leo_wl/p/5969621.html
4、外中断和异常有什么区别?
外中断是指由 CPU 执行指令以外的事件引起,如 I/O 完成中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求。此外还有时钟中断、控制台中断等。
而异常时由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
5、进程线程模型你知道多少?
对于进程和线程的理解和把握可以说基本奠定了对系统的认知和把控能力。其核心意义绝不仅仅是“线程是调度的基本单位,进程是资源分配的基本单位”这么简单。
多线程
我们这里讨论的是用户态的多线程模型,同一个进程内部有多个线程,所有的线程共享同一个进程的内存空间,进程中定义的全局变量会被所有的线程共享,比如有全局变量int i = 10,这一进程中所有并发运行的线程都可以读取和修改这个i的值,而多个线程被CPU调度的顺序又是不可控的,所以对临界资源的访问尤其需要注意安全。
我们必须知道,**做一次简单的i = i + 1在计算机中并不是原子操作,涉及内存取数,计算和写入内存几个环节,**而线程的切换有可能发生在上述任何一个环节中间,所以不同的操作顺序很有可能带来意想不到的结果。
但是,虽然线程在安全性方面会引入许多新挑战,但是线程带来的好处也是有目共睹的。首先,原先顺序执行的程序(暂时不考虑多进程)可以被拆分成几个独立的逻辑流,这些逻辑流可以独立完成一些任务(最好这些任务是不相关的)。
比如 QQ 可以一个线程处理聊天一个线程处理上传文件,两个线程互不干涉,在用户看来是同步在执行两个任务,试想如果线性完成这个任务的话,在数据传输完成之前用户聊天被一直阻塞会是多么尴尬的情况。
对于线程,我认为弄清以下两点非常重要:
-
线程之间有无先后访问顺序(线程依赖关系)
-
多个线程共享访问同一变量(同步互斥问题)
另外,我们通常只会去说同一进程的多个线程共享进程的资源,但是每个线程特有的部分却很少提及,除了标识线程的tid,每个线程还有自己独立的栈空间,线程彼此之间是无法访问其他线程栈上内容的。
而作为处理机调度的最小单位,线程调度只需要保存线程栈、寄存器数据和PC即可,相比进程切换开销要小很多。
线程相关接口不少,主要需要了解各个参数意义和返回值意义。
-
线程创建和结束
-
背景知识:
在一个文件内的多个函数通常都是按照main函数中出现的顺序来执行,但是在分时系统下,我们可以让每个函数都作为一个逻辑流并发执行,最简单的方式就是采用多线程策略。在main函数中调用多线程接口创建线程,每个线程对应特定的函数(操作),这样就可以不按照main函数中各个函数出现的顺序来执行,避免了忙等的情况。线程基本操作的接口如下。
-
相关接口:
-
创建线程:int pthread_create(pthread_t *pthread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *agr);
创建一个新线程,pthread和start_routine不可或缺,分别用于标识线程和执行体入口,其他可以填NULL。
-
pthread:用来返回线程的tid,*pthread值即为tid,类型pthread_t == unsigned long int。
-
attr:指向线程属性结构体的指针,用于改变所创线程的属性,填NULL使用默认值。
-
start_routine:线程执行函数的首地址,传入函数指针。
-
arg:通过地址传递来传递函数参数,这里是无符号类型指针,可以传任意类型变量的地址,在被传入函数中先强制类型转换成所需类型即可。
-
-
获得线程ID:pthread_t pthread_self();
调用时,会打印线程ID。
-
等待线程结束:int pthread_join(pthread_t tid, void** retval);
主线程调用,等待子线程退出并回收其资源,类似于进程中wait/waitpid回收僵尸进程,调用pthread_join的线程会被阻塞。
-
tid:创建线程时通过指针得到tid值。
-
retval:指向返回值的指针。
-
-
结束线程:pthread_exit(void *retval);
子线程执行,用来结束当前线程并通过retval传递返回值,该返回值可通过pthread_join获得。
- retval:同上。
-
分离线程:int pthread_detach(pthread_t tid);
主线程、子线程均可调用。主线程中pthread_detach(tid),子线程中pthread_detach(pthread_self()),调用后和主线程分离,子线程结束时自己立即回收资源。
- tid:同上。
-
-
-
线程属性值修改
-
背景知识:
线程属性对象类型为pthread_attr_t,结构体定义如下:
typedef struct{ int etachstate; // 线程分离的状态 int schedpolicy; // 线程调度策略 struct sched_param schedparam; // 线程的调度参数 int inheritsched; // 线程的继承性 int scope; // 线程的作用域 // 以下为线程栈的设置 size_t guardsize; // 线程栈末尾警戒缓冲大小 int stackaddr_set; // 线程的栈设置 void * stackaddr; // 线程栈的位置 size_t stacksize; // 线程栈大小 }pthread_arrt_t; -
相关接口:
对上述结构体中各参数大多有:pthread_attr_get()和pthread_attr_set()系统调用函数来设置和获取。这里不一一罗列。
-
多进程
每一个进程是资源分配的基本单位。
进程结构由以下几个部分组成:代码段、堆栈段、数据段。代码段是静态的二进制代码,多个程序可以共享。
实际上在父进程创建子进程之后,父、子进程除了pid外,几乎所有的部分几乎一样。
父、子进程共享全部数据,但并不是说他们就是对同一块数据进行操作,子进程在读写数据时会通过写时复制机制将公共的数据重新拷贝一份,之后在拷贝出的数据上进行操作。
如果子进程想要运行自己的代码段,还可以通过调用execv()函数重新加载新的代码段,之后就和父进程独立开了。
我们在shell中执行程序就是通过shell进程先fork()一个子进程再通过execv()重新加载新的代码段的过程。
-
进程创建与结束
-
背景知识:
进程有两种创建方式,一种是操作系统创建的一种是父进程创建的。从计算机启动到终端执行程序的过程为:0号进程 -> 1号内核进程 -> 1号用户进程(init进程) -> getty进程 -> shell进程 -> 命令行执行进程。所以我们在命令行中通过 ./program执行可执行文件时,所有创建的进程都是shell进程的子进程,这也就是为什么shell一关闭,在shell中执行的进程都自动被关闭的原因。从shell进程到创建其他子进程需要通过以下接口。
-
相关接口:
-
创建进程:pid_t fork(void);
返回值:出错返回-1;父进程中返回pid > 0;子进程中pid == 0
-
结束进程:void exit(int status);
- status是退出状态,保存在全局变量中S?,通常0表示正常退出。
-
获得PID:pid_t getpid(void);
返回调用者pid。
-
获得父进程PID:pid_t getppid(void);
返回父进程pid。
-
-
其他补充:
-
正常退出方式:exit()、_exit()、return(在main中)。
exit()和_exit()区别:exit()是对__exit()的封装,都会终止进程并做相关收尾工作,最主要的区别是_exit()函数关闭全部描述符和清理函数后不会刷新流,但是exit()会在调用_exit()函数前刷新数据流。
return和exit()区别:exit()是函数,但有参数,执行完之后控制权交给系统。return若是在调用函数中,执行完之后控制权交给调用进程,若是在main函数中,控制权交给系统。
-
异常退出方式:abort()、终止信号。
-
-
-
Linux进程控制
-
进程地址空间(地址空间)
虚拟存储器为每个进程提供了独占系统地址空间的假象。
尽管每个进程地址空间内容不尽相同,但是他们的都有相似的结构。X86 Linux进程的地址空间底部是保留给用户程序的,包括文本、数据、堆、栈等,其中文本区和数据区是通过存储器映射方式将磁盘中可执行文件的相应段映射至虚拟存储器地址空间中。
有一些"敏感"的地址需要注意下,对于32位进程来说,代码段从0x08048000开始。从0xC0000000开始到0xFFFFFFFF是内核地址空间,通常情况下代码运行在用户态(使用0x00000000 ~ 0xC00000000的用户地址空间),当发生系统调用、进程切换等操作时CPU控制寄存器设置模式位,进入内和模式,在该状态(超级用户模式)下进程可以访问全部存储器位置和执行全部指令。
也就说32位进程的地址空间都是4G,但用户态下只能访问低3G的地址空间,若要访问3G ~ 4G的地址空间则只有进入内核态才行。
-
进程控制块(处理机)
进程的调度实际就是内核选择相应的进程控制块,被选择的进程控制块中包含了一个进程基本的信息。
-
上下文切换
内核管理所有进程控制块,而进程控制块记录了进程全部状态信息。每一次进程调度就是一次上下文切换,所谓的上下文本质上就是当前运行状态,主要包括通用寄存器、浮点寄存器、状态寄存器、程序计数器、用户栈和内核数据结构(页表、进程表、文件表)等。
进程执行时刻,内核可以决定抢占当前进程并开始新的进程,这个过程由内核调度器完成,当调度器选择了某个进程时称为该进程被调度,该过程通过上下文切换来改变当前状态。
一次完整的上下文切换通常是进程原先运行于用户态,之后因系统调用或时间片到切换到内核态执行内核指令,完成上下文切换后回到用户态,此时已经切换到进程B。
6、进程调度算法你了解多少?
1、 先来先服务 first-come first-serverd(FCFS)
非抢占式的调度算法,按照请求的顺序进行调度。
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
2、 短作业优先 shortest job first(SJF)
非抢占式的调度算法,按估计运行时间最短的顺序进行调度。
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
3、最短剩余时间优先 shortest remaining time next(SRTN)
最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。
如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
4、时间片轮转
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。
当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
时间片轮转算法的效率和时间片的大小有很大关系:
- 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
- 而如果时间片过长,那么实时性就不能得到保证。
5、优先级调度
为每个进程分配一个优先级,按优先级进行调度。
为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
6、多级反馈队列
一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8,..。进程在第一个队列没执行完,就会被移到下一个队列。
这种方式下,之前的进程只需要交换 7 次。每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
7、Linux下进程间通信方式?
-
管道:
-
无名管道(内存文件):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程之间使用。进程的亲缘关系通常是指父子进程关系。
-
有名管道(FIFO文件,借助文件系统):有名管道也是半双工的通信方式,但是允许在没有亲缘关系的进程之间使用,管道是先进先出的通信方式。
-
-
共享内存:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的IPC方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与信号量,配合使用来实现进程间的同步和通信。
-
消息队列:消息队列是有消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
-
套接字:适用于不同机器间进程通信,在本地也可作为两个进程通信的方式。
-
信号:用于通知接收进程某个事件已经发生,比如按下ctrl + C就是信号。
-
信号量:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,实现进程、线程的对临界区的同步及互斥访问。
8、Linux下同步机制?
-
POSIX信号量:可用于进程同步,也可用于线程同步。
-
POSIX互斥锁 + 条件变量:只能用于线程同步。
-
线程和进程的区别?
-
调度:线程是调度的基本单位(PC,状态码,通用寄存器,线程栈及栈指针);进程是拥有资源的基本单位(打开文件,堆,静态区,代码段等)。
-
并发性:一个进程内多个线程可以并发(最好和CPU核数相等);多个进程可以并发。
-
拥有资源:线程不拥有系统资源,但一个进程的多个线程可以共享隶属进程的资源;进程是拥有资源的独立单位。
-
系统开销:线程创建销毁只需要处理PC值,状态码,通用寄存器值,线程栈及栈指针即可;进程创建和销毁需要重新分配及销毁task_struct结构。
-
9、如果系统中具有快表后,那么地址的转换过程变成什么样了?
①CPU给出逻辑地址,由某个硬件算得页号、页内偏移量,将页号与快表中的所有页号进行比较。②如果找到匹配的页号,说明要访问的页表项在快表中有副本,则直接从中取出该页对应的内存块号,再将内存块号与页内偏移量拼接形成物理地址,最后,访问该物理地址对应的内存单元。因此,若快表命中,则访问某个逻辑地址仅需一次访存即可。 ③如果没有找到匹配的页号,则需要访问内存中的页表,找到对应页表项,得到页面存放的内存块号,再将内存块号与页内偏移量拼接形成物理地址,最后,访问该物理地址对应的内存单元。因此,若快表未命中,则访问某个逻辑地址需要两次访存(注意:在找到页表项后,应同时将其存入快表,以便后面可能的再次访问。但若快表已满,则必须按照-定的算法对旧的页表项进行替换)
由于查询快表的速度比查询页表的速度快很多,因此只要快表命中,就可以节省很多时间。 因为局部性原理,–般来说快表的命中率可以达到90%以上。
例:某系统使用基本分页存储管理,并采用了具有快表的地址变换机构。访问- -次快表耗时1us, 访问一次内存耗时100us。若快表的命中率为90%,那么访问一个逻辑地址的平均耗时是多少? (1+100) * 0.9 + (1+100+100) * 0.1 = 111 us 有的系统支持快表和慢表同时查找,如果是这样,平均耗时应该是(1+100) * 0.9+ (100+100) *0.1=110.9 us 若未采用快表机制,则访问一个逻辑地址需要100+100 = 200us 显然,引入快表机制后,访问一个逻辑地址的速度快多了。
10、内存交换和覆盖有什么区别?
交换技术主要是在不同进程(或作业)之间进行,而覆盖则用于同一程序或进程中。
11、动态分区分配算法有哪几种?可以分别说说吗?
1、首次适应算法
算法思想:每次都从低地址开始查找,找到第–个能满足大小的空闲分区。
如何实现:空闲分区以地址递增的次序排列。每次分配内存时顺序查找空闲分区链( 或空闲分[表),找到大小能满足要求的第-一个空闲分区。
2、最佳适应算法
算法思想:由于动态分区分配是一种连续分配方式,为各进程分配的空间必须是连续的一整片区域。因此为了保证当“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片的空闲区,即,优先使用更小的空闲区。
如何实现:空闲分区按容量递增次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第-一个空闲分区。
3、最坏适应算法
又称最大适应算法(Largest Fit)
算法思想:为了解决最佳适应算法的问题—即留下太多难以利用的小碎片,可以在每次分配时优先使用最大的连续空闲区,这样分配后剩余的空闲区就不会太小,更方便使用。
如何实现:空闲分区按容量递减次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第-一个空闲分区。
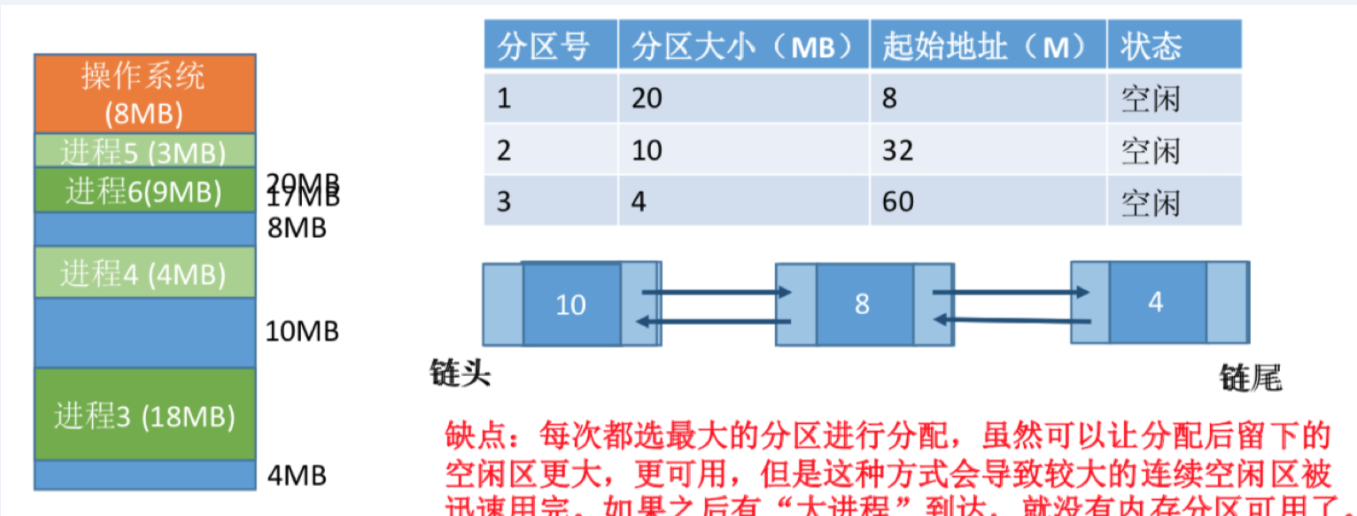
4、邻近适应算法
算法思想:首次适应算法每次都从链头开始查找的。这可能会导致低地址部分出现很多小的空闲分区,而每次分配查找时,都要经过这些分区,因此也增加了查找的开销。如果每次都从上次查找结束的位置开始检索,就能解决上述问题。
如何实现:空闲分区以地址递增的顺序排列(可排成-一个循环链表)。每次分配内存时从上次查找结束的位置开始查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
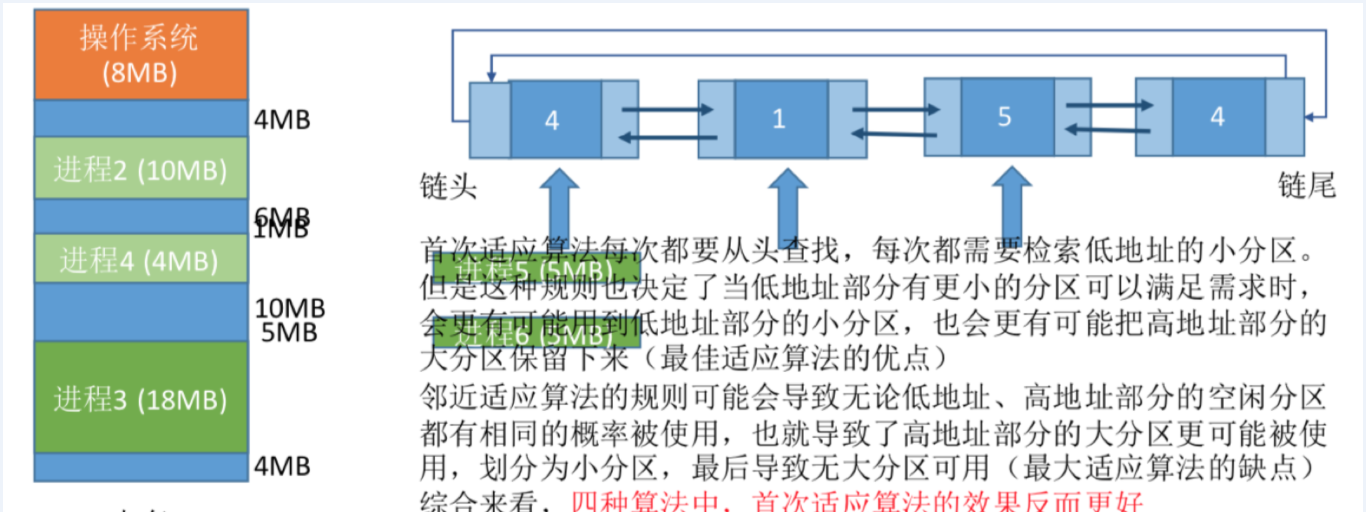
5、总结
首次适应不仅最简单,通常也是最好最快,不过首次适应算法会使得内存低地址部分出现很多小的空闲分区,而每次查找都要经过这些分区,因此也增加了查找的开销。邻近算法试图解决这个问题,但实际上,它常常会导致在内存的末尾分配空间分裂成小的碎片,它通常比首次适应算法结果要差。
最佳导致大量碎片,最坏导致没有大的空间。
进过实验,首次适应比最佳适应要好,他们都比最坏好。
| 算法 | 算法思想 | 分区排列顺序 | 优点 | 缺点 |
|---|---|---|---|---|
| 首次适应 | 从头到尾找适合的分区 | 空闲分区以地址递增次序排列 | 综合看性能最好。算法开销小,回收分区后一.般不需要对空闲分区队列重新排序 | |
| 最佳适应 | 优先使用更小的分区,以保留更多大分区 | 空闲分区以容量递增次序排列 | 会有更多的大分区被保留下来,更能满足大进程需求 | 会产生很多太小的、难以利用的碎片;算法开销大,回收分区后可能需要对空闲分区队列重新排序 |
| 最坏适应 | 优先使用更大的分区,以防止产生太小的不可用的碎片 | 空闲分区以容量递减次序排列 | 可以减少难以利用的小碎片 | 大分区容易被用完,不利于大进程;算法开销大(原因同上) |
| 邻近适应 | 由首次适应演变而来,每次从上次查找结束位置开始查找 | 空闲分区以地址递增次序排列(可排列成循环链表) | 不用每次都从低地址的小分区开始检索。算法开销小(原因同首次适应算法) | 会使高地址的大分区也被用完 |
12、虚拟技术你了解吗?
虚拟技术把一个物理实体转换为多个逻辑实体。
主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
多进程与多线程:多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
13、进程状态的切换你知道多少?
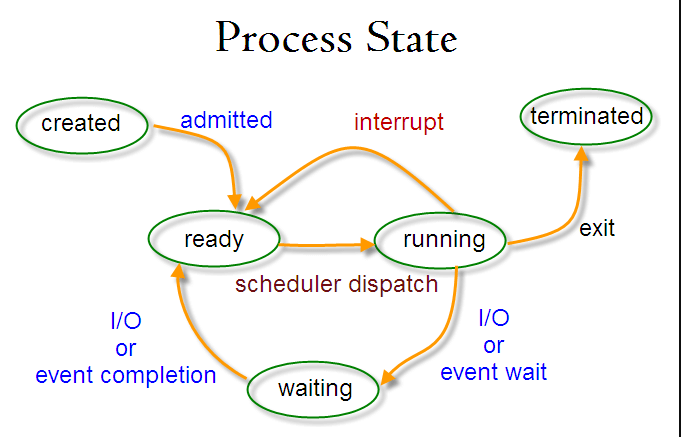
- 就绪状态(ready):等待被调度
- 运行状态(running)
- 阻塞状态(waiting):等待资源
应该注意以下内容:
- 只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
- 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
14、一个程序从开始运行到结束的完整过程,你能说出来多少?
四个过程:
(1)预编译 主要处理源代码文件中的以“#”开头的预编译指令。处理规则见下 1、删除所有的#define,展开所有的宏定义。 2、处理所有的条件预编译指令,如“#if”、“#endif”、“#ifdef”、“#elif”和“#else”。 3、处理“#include”预编译指令,将文件内容替换到它的位置,这个过程是递归进行的,文件中包含其他 文件。 4、删除所有的注释,“//”和“/**/”。 5、保留所有的#pragma 编译器指令,编译器需要用到他们,如:#pragma once 是为了防止有文件被重 复引用。 6、添加行号和文件标识,便于编译时编译器产生调试用的行号信息,和编译时产生编译错误或警告是 能够显示行号。
(2)编译 把预编译之后生成的xxx.i或xxx.ii文件,进行一系列词法分析、语法分析、语义分析及优化后,生成相应 的汇编代码文件。 1、词法分析:利用类似于“有限状态机”的算法,将源代码程序输入到扫描机中,将其中的字符序列分 割成一系列的记号。 2、语法分析:语法分析器对由扫描器产生的记号,进行语法分析,产生语法树。由语法分析器输出的 语法树是一种以表达式为节点的树。 3、语义分析:语法分析器只是完成了对表达式语法层面的分析,语义分析器则对表达式是否有意义进 行判断,其分析的语义是静态语义——在编译期能分期的语义,相对应的动态语义是在运行期才能确定 的语义。 4、优化:源代码级别的一个优化过程。 5、目标代码生成:由代码生成器将中间代码转换成目标机器代码,生成一系列的代码序列——汇编语言 表示。 6、目标代码优化:目标代码优化器对上述的目标机器代码进行优化:寻找合适的寻址方式、使用位移 来替代乘法运算、删除多余的指令等。 (3)汇编 将汇编代码转变成机器可以执行的指令(机器码文件)。 汇编器的汇编过程相对于编译器来说更简单,没 有复杂的语法,也没有语义,更不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译过 来,汇编过程有汇编器as完成。经汇编之后,产生目标文件(与可执行文件格式几乎一样)xxx.o(Linux 下)、xxx.obj(Windows下)。 (4)链接 将不同的源文件产生的目标文件进行链接,从而形成一个可以执行的程序。链接分为静态链接和动态链 接: 1、静态链接: 函数和数据被编译进一个二进制文件。在使用静态库的情况下,在编译链接可执行文件时,链接器从库 中复制这些函数和数据并把它们和应用程序的其它模块组合起来创建最终的可执行文件。 空间浪费:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个 目标文件都有依赖,会出现同一个目标文件都在内存存在多个副本; 更新困难:每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。 运行速度快:但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西, 在执行的时候运行速度快。 2、动态链接: 动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形 成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。 共享库:就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多份副 本,而是这多个程序在执行时共享同一份副本; 更新方便:更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运 行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。 性能损耗:因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损 失。
《操作系统(三)》:https://www.nowcoder.com/tutorial/93/675fd4af3ab34b2db0ae650855aa52d5
15、通过例子讲解逻辑地址转换为物理地址的基本过程
可以借助进程的页表将逻辑地址转换为物理地址。
通常会在系统中设置一个页表寄存器(PTR),存放页表在内存中的起始地址F和页表长度M。进程未执行时,页表的始址和页表长度放在进程控制块(PCB) 中,当进程被调度时,操作系统内核会把它们放到页表寄存器中。
注意:页面大小是2的整数幂 设页面大小为L,逻辑地址A到物理地址E的变换过程如下:
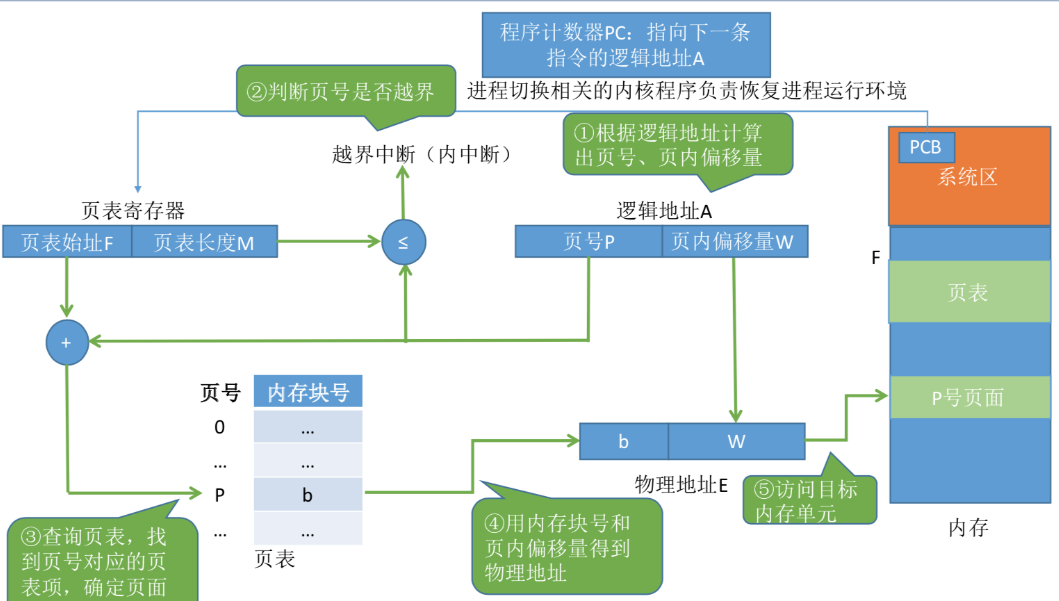
 例:若页面大小L为1K字节,页号2对应的内存块号b=8,将逻辑地址A=2500转换为物理地址E。
等价描述:某系统按字节寻址,逻辑地址结构中,页内偏移量占10位(说明一个页面的大小为2^10B = 1KB),页号2对应的内存块号 b=8,将逻辑地址A=2500转换为物理地址E。
例:若页面大小L为1K字节,页号2对应的内存块号b=8,将逻辑地址A=2500转换为物理地址E。
等价描述:某系统按字节寻址,逻辑地址结构中,页内偏移量占10位(说明一个页面的大小为2^10B = 1KB),页号2对应的内存块号 b=8,将逻辑地址A=2500转换为物理地址E。
①计算页号、页内偏移量 页号P=A/L = 2500/1024 = 2; 页内偏移量W= A%L = 2500%1024 = 452
②根据题中条件可知,页号2没有越界,其存放的内存块号b=8
③物理地址E=b*L+W=8 * 1024+ 425 = 8644
在分页存储管理(页式管理)的系统中,只要确定了每个页面的大小,逻辑地址结构就确定了。因此,页式管理中地址是-维的。即,只要给出一个逻辑地址,系统就可以自动地算出页号、页内偏移量两个部分,并不需要显式地告诉系统这个逻辑地址中,页内偏移量占多少位。
16、进程同步的四种方法?
1. 临界区
对临界资源进行访问的那段代码称为临界区。
为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
// entry section
// critical section;
// exit section
2. 同步与互斥
- 同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。
- 互斥:多个进程在同一时刻只有一个进程能进入临界区。
3. 信号量
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
- down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
- up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0 表示临界区已经加锁,1 表示临界区解锁。
typedef int semaphore;
semaphore mutex = 1;
void P1() {
down(&mutex);
// 临界区
up(&mutex);
}
void P2() {
down(&mutex);
// 临界区
up(&mutex);
}
使用信号量实现生产者-消费者问题
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。
其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。
消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}
4. 管程
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
monitor ProducerConsumer
integer i;
condition c;
procedure insert();
begin
// ...
end;
procedure remove();
begin
// ...
end;
end monitor;
管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
管程引入了 条件变量 以及相关的操作:wait() 和 signal() 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
使用管程实现生产者-消费者问题
// 管程
monitor ProducerConsumer
condition full, empty;
integer count := 0;
condition c;
procedure insert(item: integer);
begin
if count = N then wait(full);
insert_item(item);
count := count + 1;
if count = 1 then signal(empty);
end;
function remove: integer;
begin
if count = 0 then wait(empty);
remove = remove_item;
count := count - 1;
if count = N -1 then signal(full);
end;
end monitor;
// 生产者客户端
procedure producer
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item);
end
end;
// 消费者客户端
procedure consumer
begin
while true do
begin
item = ProducerConsumer.remove;
consume_item(item);
end
end;
17、操作系统在对内存进行管理的时候需要做些什么?
- 操作系统负责内存空间的分配与回收。
- 操作系统需要提供某种技术从逻辑上对内存空间进行扩充。
- 操作系统需要提供地址转换功能,负责程序的逻辑地址与物理地址的转换。
- 操作系统需要提供内存保护功能。保证各进程在各自存储空间内运行,互不干扰
18、进程通信方法(Linux和windows下),线程通信方法(Linux和windows下)
进程通信方法
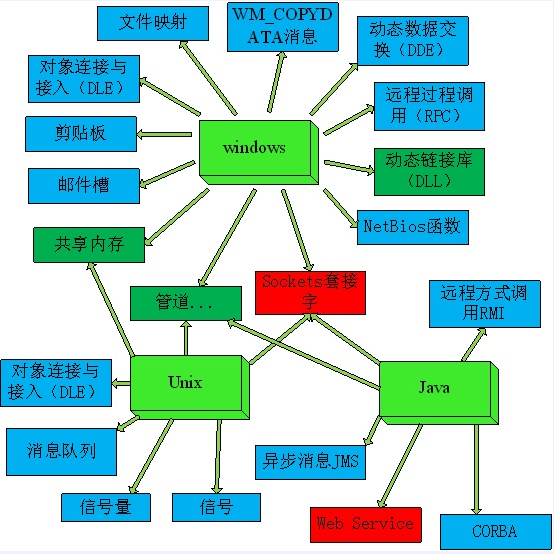
| 名称及方式 |
|---|
| 管道(pipe):允许一个进程和另一个与它有共同祖先的进程之间进行通信 |
| 命名管道(FIFO):类似于管道,但是它可以用于任何两个进程之间的通信,命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建 |
| 消息队列(MQ):消息队列是消息的连接表,包括POSIX消息对和System V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能成该无格式字节流以及缓冲区大小受限等缺点; |
| 信号量(semaphore):信号量主要作为进程间以及同进程不同线程之间的同步手段; |
| 共享内存(shared memory):它使得多个进程可以访问同一块内存空间,**是最快的可用IPC形式。**这是针对其他通信机制运行效率较低而设计的。它往往与其他通信机制,如信号量结合使用,以达到进程间的同步及互斥 |
| 信号(signal):信号是比较复杂的通信方式,用于通知接收进程有某种事情发生,除了用于进程间通信外,进程还可以发送信号给进程本身 |
| 内存映射(mapped memory):内存映射允许任何多个进程间通信,每一个使用该机制的进程通过把一个共享的文件映射到自己的进程地址空间来实现它 |
| Socket:它是更为通用的进程间通信机制,可用于不同机器之间的进程间通信 |
线程通信方法
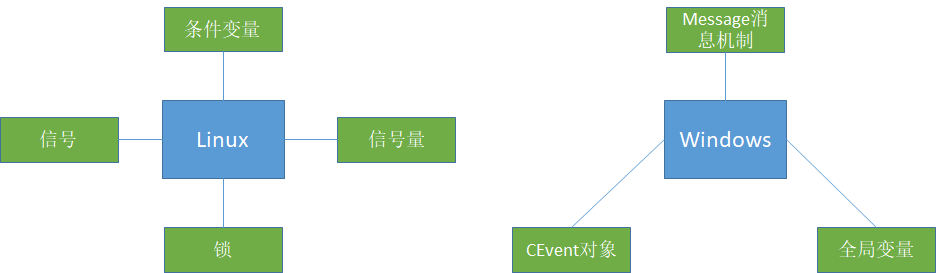
| 名称及含义 |
|---|
| Linux: |
| 信号:类似进程间的信号处理 |
| 锁机制:互斥锁、读写锁和自旋锁 |
| 条件变量:使用通知的方式解锁,与互斥锁配合使用 |
| 信号量:包括无名线程信号量和命名线程信号量 |
| Windows: |
| 全局变量:需要有多个线程来访问一个全局变量时,通常我们会在这个全局变量前加上volatile声明,以防编译器对此变量进行优化 |
| Message消息机制:常用的Message通信的接口主要有两个:PostMessage和PostThreadMessage,PostMessage为线程向主窗口发送消息。而PostThreadMessage是任意两个线程之间的通信接口。 |
| CEvent对象:CEvent为MFC中的一个对象,可以通过对CEvent的触发状态进行改变,从而实现线程间的通信和同步,这个主要是实现线程直接同步的一种方法。 |
19、程间通信有哪几种方式?把你知道的都说出来
Linux几乎支持全部UNIX进程间通信方法,包括管道(有名管道和无名管道)、消息队列、共享内存、信号量和套接字。其中前四个属于同一台机器下进程间的通信,套接字则是用于网络通信。
管道
-
无名管道
-
无名管道特点:
-
无名管道是一种特殊的文件,这种文件只存在于内存中。
-
无名管道只能用于父子进程或兄弟进程之间,必须用于具有亲缘关系的进程间的通信。
-
无名管道只能由一端向另一端发送数据,是半双工方式,如果双方需要同时收发数据需要两个管道。
-
-
相关接口:
-
int pipe(int fd[2]);
- fd[2]:管道两端用fd[0]和fd[1]来描述,读的一端用fd[0]表示,写的一端用fd[1]表示。通信双方的进程中写数据的一方需要把fd[0]先close掉,读的一方需要先把fd[1]给close掉。
-
-
-
有名管道:
-
有名管道特点:
-
有名管道是FIFO文件,存在于文件系统中,可以通过文件路径名来指出。
-
有名管道可以在不具有亲缘关系的进程间进行通信。
-
-
相关接口:
-
int mkfifo(const char *pathname, mode_t mode);
-
pathname:即将创建的FIFO文件路径,如果文件存在需要先删除。
-
mode:和open()中的参数相同。
-
-
-
消息队列
相比于 FIFO,消息队列具有以下优点:
- 消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难;
- 避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
- 读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
共享内存
进程可以将同一段共享内存连接到它们自己的地址空间,所有进程都可以访问共享内存中的地址,如果某个进程向共享内存内写入数据,所做的改动将立即影响到可以访问该共享内存的其他所有进程。
-
相关接口
-
创建共享内存:int shmget(key_t key, int size, int flag);
成功时返回一个和key相关的共享内存标识符,失败范湖范围-1。
-
key:为共享内存段命名,多个共享同一片内存的进程使用同一个key。
-
size:共享内存容量。
-
flag:权限标志位,和open的mode参数一样。
-
-
连接到共享内存地址空间:void *shmat(int shmid, void *addr, int flag);
返回值即共享内存实际地址。
-
shmid:shmget()返回的标识。
-
addr:决定以什么方式连接地址。
-
flag:访问模式。
-
-
从共享内存分离:int shmdt(const void *shmaddr);
调用成功返回0,失败返回-1。
- shmaddr:是shmat()返回的地址指针。
-
-
其他补充
共享内存的方式像极了多线程中线程对全局变量的访问,大家都对等地有权去修改这块内存的值,这就导致在多进程并发下,最终结果是不可预期的。所以对这块临界区的访问需要通过信号量来进行进程同步。
但共享内存的优势也很明显,首先可以通过共享内存进行通信的进程不需要像无名管道一样需要通信的进程间有亲缘关系。其次内存共享的速度也比较快,不存在读取文件、消息传递等过程,只需要到相应映射到的内存地址直接读写数据即可。
信号量
在提到共享内存方式时也提到,进程共享内存和多线程共享全局变量非常相似。所以在使用内存共享的方式是也需要通过信号量来完成进程间同步。多线程同步的信号量是POSIX信号量,而在进程里使用SYSTEM V信号量。
-
相关接口
-
创建信号量:int semget(key_t key, int nsems, int semflag);
创建成功返回信号量标识符,失败返回-1。
-
key:进程pid。
-
nsems:创建信号量的个数。
-
semflag:指定信号量读写权限。
-
-
改变信号量值:int semop(int semid, struct sembuf *sops, unsigned nsops);
我们所需要做的主要工作就是串讲sembuf变量并设置其值,然后调用semop,把设置好的sembuf变量传递进去。
struct sembuf结构体定义如下:
struct sembuf{ short sem_num; short sem_op; short sem_flg; };成功返回信号量标识符,失败返回-1。
-
semid:信号量集标识符,由semget()函数返回。
-
sops:指向struct sembuf结构的指针,先设置好sembuf值再通过指针传递。
-
nsops:进行操作信号量的个数,即sops结构变量的个数,需大于或等于1。最常见设置此值等于1,只完成对一个信号量的操作。
-
-
直接控制信号量信息:int semctl(int semid, int semnum, int cmd, union semun arg);
-
semid:信号量集标识符。
-
semnum:信号量集数组上的下标,表示某一个信号量。
-
arg:union semun类型。
-
-
辅助命令
ipcs命令用于报告共享内存、信号量和消息队列信息。
-
ipcs -a:列出共享内存、信号量和消息队列信息。
-
ipcs -l:列出系统限额。
-
ipcs -u:列出当前使用情况。
套接字
与其它通信机制不同的是,它可用于不同机器间的进程通信。
20、虚拟内存的目的是什么?
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。
这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。
例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
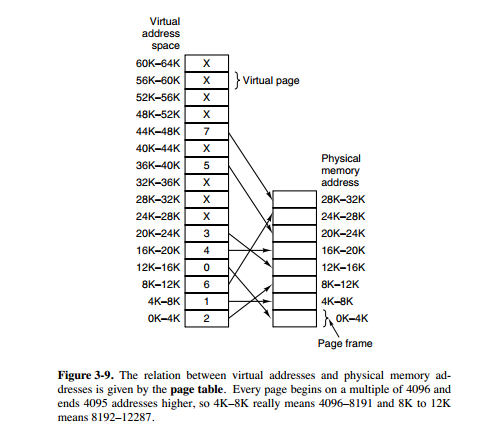
21、说一下你理解中的内存?他有什么作用呢?
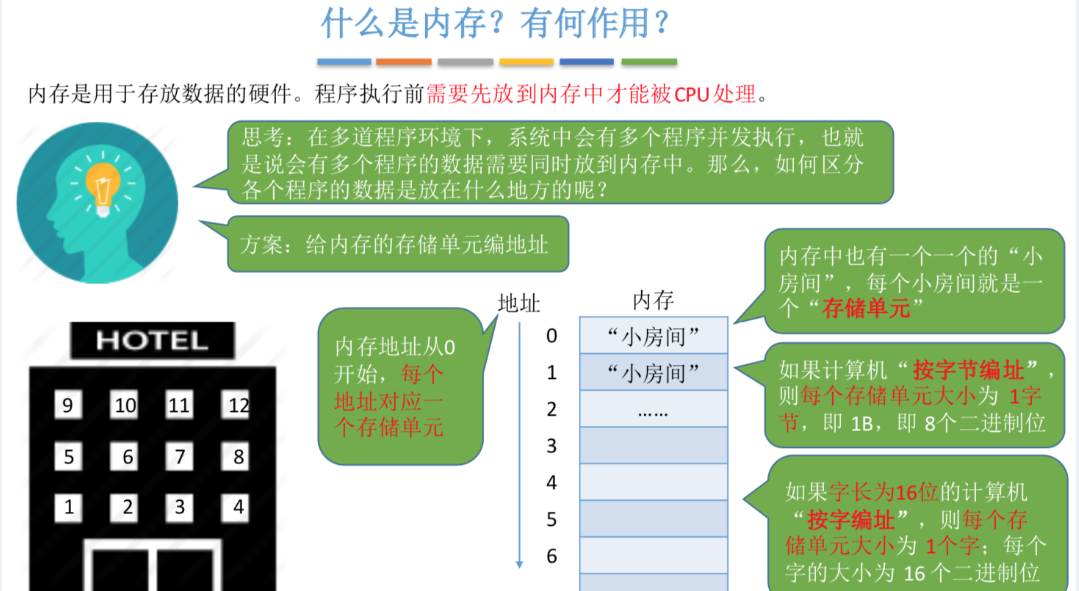
22、操作系统经典问题之哲学家进餐问题

五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
#define N 5
void philosopher(int i) {
while(TRUE) {
think();
take(i); // 拿起左边的筷子
take((i+1)%N); // 拿起右边的筷子
eat();
put(i);
put((i+1)%N);
}
}
为了防止死锁的发生,可以设置两个条件:
- 必须同时拿起左右两根筷子;
- 只有在两个邻居都没有进餐的情况下才允许进餐。
#define N 5
#define LEFT (i + N - 1) % N // 左邻居
#define RIGHT (i + 1) % N // 右邻居
#define THINKING 0
#define HUNGRY 1
#define EATING 2
typedef int semaphore;
int state[N]; // 跟踪每个哲学家的状态
semaphore mutex = 1; // 临界区的互斥,临界区是 state 数组,对其修改需要互斥
semaphore s[N]; // 每个哲学家一个信号量
void philosopher(int i) {
while(TRUE) {
think(i);
take_two(i);
eat(i);
put_two(i);
}
}
void take_two(int i) {
down(&mutex);
state[i] = HUNGRY;
check(i);
up(&mutex);
down(&s[i]); // 只有收到通知之后才可以开始吃,否则会一直等下去
}
void put_two(i) {
down(&mutex);
state[i] = THINKING;
check(LEFT); // 尝试通知左右邻居,自己吃完了,你们可以开始吃了
check(RIGHT);
up(&mutex);
}
void eat(int i) {
down(&mutex);
state[i] = EATING;
up(&mutex);
}
// 检查两个邻居是否都没有用餐,如果是的话,就 up(&s[i]),使得 down(&s[i]) 能够得到通知并继续执行
void check(i) {
if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {
state[i] = EATING;
up(&s[i]);
}
}
23、操作系统经典问题之读者-写者问题
允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
typedef int semaphore;
semaphore count_mutex = 1;
semaphore data_mutex = 1;
int count = 0;
void reader() {
while(TRUE) {
down(&count_mutex);
count++;
if(count == 1) down(&data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问
up(&count_mutex);
read();
down(&count_mutex);
count--;
if(count == 0) up(&data_mutex);//最后一个读者要对数据进行解锁,防止写进程无法访问
up(&count_mutex);
}
}
void writer() {
while(TRUE) {
down(&data_mutex);
write();
up(&data_mutex);
}
}
24、介绍一下几种典型的锁
读写锁
- 多个读者可以同时进行读
- 写者必须互斥(只允许一个写者写,也不能读者写者同时进行)
- 写者优先于读者(一旦有写者,则后续读者必须等待,唤醒时优先考虑写者)
互斥锁
一次只能一个线程拥有互斥锁,其他线程只有等待
互斥锁是在抢锁失败的情况下主动放弃CPU进入睡眠状态直到锁的状态改变时再唤醒,而操作系统负责线程调度,为了实现锁的状态发生改变时唤醒阻塞的线程或者进程,需要把锁交给操作系统管理,所以互斥锁在加锁操作时涉及上下文的切换。互斥锁实际的效率还是可以让人接受的,加锁的时间大概100ns左右,而实际上互斥锁的一种可能的实现是先自旋一段时间,当自旋的时间超过阀值之后再将线程投入睡眠中,因此在并发运算中使用互斥锁(每次占用锁的时间很短)的效果可能不亚于使用自旋锁
条件变量
互斥锁一个明显的缺点是他只有两种状态:锁定和非锁定。而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,他常和互斥锁一起使用,以免出现竞态条件。当条件不满足时,线程往往解开相应的互斥锁并阻塞线程然后等待条件发生变化。一旦其他的某个线程改变了条件变量,他将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。总的来说互斥锁是线程间互斥的机制,条件变量则是同步机制。
自旋锁
如果进线程无法取得锁,进线程不会立刻放弃CPU时间片,而是一直循环尝试获取锁,直到获取为止。如果别的线程长时期占有锁,那么自旋就是在浪费CPU做无用功,但是自旋锁一般应用于加锁时间很短的场景,这个时候效率比较高。
《互斥锁、读写锁、自旋锁、条件变量的特点总结》:https://blog.csdn.net/RUN32875094/article/details/80169978
-
线程(POSIX)锁有哪些?
-
互斥锁(mutex)
- 互斥锁属于sleep-waiting类型的锁。例如在一个双核的机器上有两个线程A和B,它们分别运行在core 0和core 1上。假设线程A想要通过pthread_mutex_lock操作去得到一个临界区的锁,而此时这个锁正被线程B所持有,那么线程A就会被阻塞,此时会通过上下文切换将线程A置于等待队列中,此时core 0就可以运行其他的任务(如线程C)。
-
条件变量(cond)
-
自旋锁(spin)
-
自旋锁属于busy-waiting类型的锁,如果线程A是使用pthread_spin_lock操作去请求锁,如果自旋锁已经被线程B所持有,那么线程A就会一直在core 0上进行忙等待并不停的进行锁请求,检查该自旋锁是否已经被线程B释放,直到得到这个锁为止。因为自旋锁不会引起调用者睡眠,所以自旋锁的效率远高于互斥锁。
-
虽然它的效率比互斥锁高,但是它也有些不足之处:
-
自旋锁一直占用CPU,在未获得锁的情况下,一直进行自旋,所以占用着CPU,如果不能在很短的时间内获得锁,无疑会使CPU效率降低。
-
在用自旋锁时有可能造成死锁,当递归调用时有可能造成死锁。
-
-
自旋锁只有在内核可抢占式或SMP的情况下才真正需要,在单CPU且不可抢占式的内核下,自旋锁的操作为空操作。自旋锁适用于锁使用者保持锁时间比较短的情况下。
-
-
25、逻辑地址VS物理地址
Eg:编译时只需确定变量x存放的相对地址是100 ( 也就是说相对于进程在内存中的起始地址而言的地址)。CPU想要找到x在内存中的实际存放位置,只需要用进程的起始地址+100即可。 相对地址又称逻辑地址,绝对地址又称物理地址。
26、怎么回收线程?有哪几种方法?
-
等待线程结束:int pthread_join(pthread_t tid, void** retval);
主线程调用,等待子线程退出并回收其资源,类似于进程中wait/waitpid回收僵尸进程,调用pthread_join的线程会被阻塞。
-
tid:创建线程时通过指针得到tid值。
-
retval:指向返回值的指针。
-
-
结束线程:pthread_exit(void *retval);
子线程执行,用来结束当前线程并通过retval传递返回值,该返回值可通过pthread_join获得。
- retval:同上。
-
分离线程:int pthread_detach(pthread_t tid);
主线程、子线程均可调用。主线程中pthread_detach(tid),子线程中pthread_detach(pthread_self()),调用后和主线程分离,子线程结束时自己立即回收资源。
- tid:同上。
27、内存的覆盖是什么?有什么特点?
由于程序运行时并非任何时候都要访问程序及数据的各个部分(尤其是大程序),因此可以把用户空间分成为一个固定区和若干个覆盖区。将经常活跃的部分放在固定区,其余部分按照调用关系分段,首先将那些即将要访问的段放入覆盖区,其他段放在外存中,在需要调用前,系统将其调入覆盖区,替换覆盖区中原有的段。
覆盖技术的特点:是打破了必须将一个进程的全部信息装入内存后才能运行的限制,但当同时运行程序的代码量大于主存时仍不能运行,再而,大家要注意到,内存中能够更新的地方只有覆盖区的段,不在覆盖区的段会常驻内存。
28、内存交换是什么?有什么特点?
交换(对换)技术的设计思想:内存空间紧张时,系统将内存中某些进程暂时换出外存,把外存中某些已具备运行条件的进程换入内存(进程在内存与磁盘间动态调度)
换入:把准备好竞争CPU运行的程序从辅存移到内存。 换出:把处于等待状态(或CPU调度原则下被剥夺运行权力)的程序从内存移到辅存,把内存空间腾出来。
29、什么时候会进行内存的交换?
内存交换通常在许多进程运行且内存吃紧时进行,而系统负荷降低就暂停。例如:在发现许多进程运行时经常发生缺页,就说明内存紧张,此时可以换出一些进程;如果缺页率明显下降,就可以暂停换出。
30、终端退出,终端运行的进程会怎样
终端在退出时会发送SIGHUP给对应的bash进程,bash进程收到这个信号后首先将它发给session下面的进程,如果程序没有对SIGHUP信号做特殊处理,那么进程就会随着终端关闭而退出
《linux终端关闭时为什么会导致在其上启动的进程退出?》:https://blog.csdn.net/QFire/article/details/80112701
31、如何让进程后台运行
(1)命令后面加上&即可,实际上,这样是将命令放入到一个作业队列中了
(2)ctrl + z 挂起进程,使用jobs查看序号,在使用bg %序号后台运行进程
(3)nohup + &,将标准输出和标准错误缺省会被重定向到 nohup.out 文件中,忽略所有挂断(SIGHUP)信号
(4)运行指令前面 + setsid,使其父进程编程init进程,不受HUP信号的影响
(5)将 命令+ &放在()括号中,也可以是进程不受HUP信号的影响
32、什么是快表,你知道多少关于快表的知识?
快表,又称联想寄存器(TLB) ,是一种访问速度比内存快很多的高速缓冲存储器,用来存放当前访问的若干页表项,以加速地址变换的过程。与此对应,内存中的页表常称为慢表。
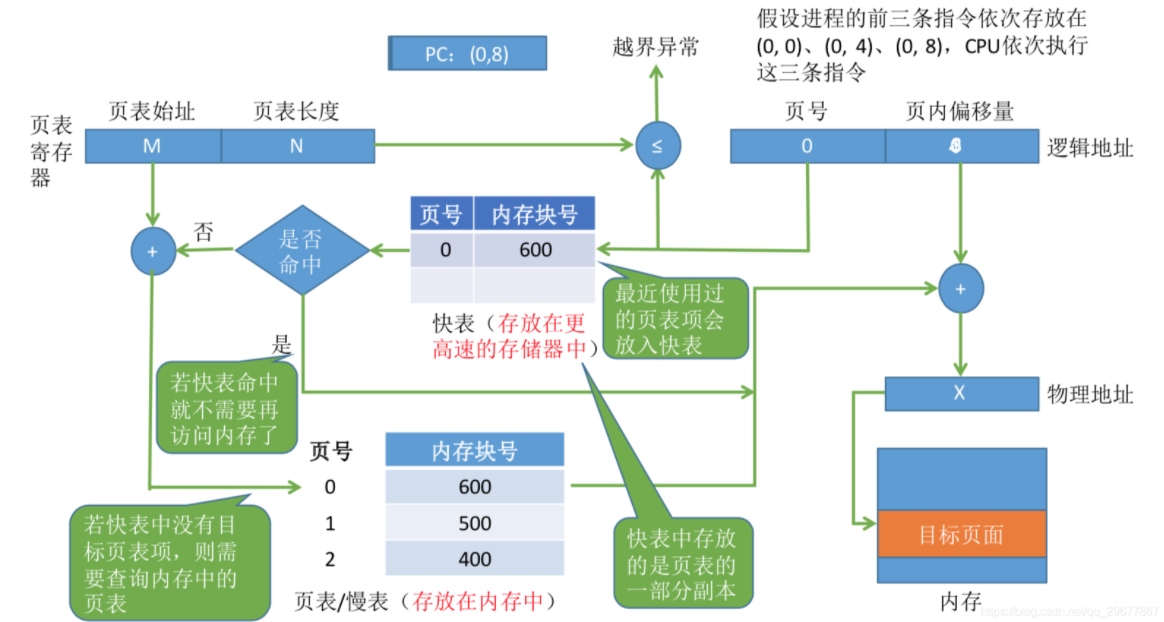
33、地址变换中,有快表和没快表,有什么区别?
| 地址变换过程 | 访问一个逻辑地址的访存次数 | |
|---|---|---|
| 基本地址变换机构 | ①算页号、页内偏移量 ②检查页号合法性 ③查页表,找到页面存放的内存块号 ④根据内存块号与页内偏移量得到物理地址 ⑤访问目标内存单元 | 两次访存 |
| 具有快表的地址变换机构 | ①算页号、页内偏移量 ②检查页号合法性 ③查快表。若命中,即可知道页面存放的内存块号,可直接进行⑤;若未命中则进行④ ④查页表,找到页面存放的内存块号,并且将页表项复制到快表中 ⑤根据内存块号与页内偏移量得到物理地址 ⑥访问目标内存单元 | 快表命中,只需一次访存 快表未命中,需要两次访存 |
35、 守护进程、僵尸进程和孤儿进程
守护进程
指在后台运行的,没有控制终端与之相连的进程。它独立于控制终端,周期性地执行某种任务。Linux的大多数服务器就是用守护进程的方式实现的,如web服务器进程http等
创建守护进程要点:
(1)让程序在后台执行。方法是调用fork()产生一个子进程,然后使父进程退出。
(2)调用setsid()创建一个新对话期。控制终端、登录会话和进程组通常是从父进程继承下来的,守护进程要摆脱它们,不受它们的影响,方法是调用setsid()使进程成为一个会话组长。setsid()调用成功后,进程成为新的会话组长和进程组长,并与原来的登录会话、进程组和控制终端脱离。
(3)禁止进程重新打开控制终端。经过以上步骤,进程已经成为一个无终端的会话组长,但是它可以重新申请打开一个终端。为了避免这种情况发生,可以通过使进程不再是会话组长来实现。再一次通过fork()创建新的子进程,使调用fork的进程退出。
(4)关闭不再需要的文件描述符。子进程从父进程继承打开的文件描述符。如不关闭,将会浪费系统资源,造成进程所在的文件系统无法卸下以及引起无法预料的错误。首先获得最高文件描述符值,然后用一个循环程序,关闭0到最高文件描述符值的所有文件描述符。
(5)将当前目录更改为根目录。
(6)子进程从父进程继承的文件创建屏蔽字可能会拒绝某些许可权。为防止这一点,使用unmask(0)将屏蔽字清零。
(7)处理SIGCHLD信号。对于服务器进程,在请求到来时往往生成子进程处理请求。如果子进程等待父进程捕获状态,则子进程将成为僵尸进程(zombie),从而占用系统资源。如果父进程等待子进程结束,将增加父进程的负担,影响服务器进程的并发性能。在Linux下可以简单地将SIGCHLD信号的操作设为SIG_IGN。这样,子进程结束时不会产生僵尸进程。
孤儿进程
如果父进程先退出,子进程还没退出,那么子进程的父进程将变为init进程。(注:任何一个进程都必须有父进程)。
一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程
如果子进程先退出,父进程还没退出,那么子进程必须等到父进程捕获到了子进程的退出状态才真正结束,否则这个时候子进程就成为僵尸进程。
设置僵尸进程的目的是维护子进程的信息,以便父进程在以后某个时候获取。这些信息至少包括进程ID,进程的终止状态,以及该进程使用的CPU时间,所以当终止子进程的父进程调用wait或waitpid时就可以得到这些信息。如果一个进程终止,而该进程有子进程处于僵尸状态,那么它的所有僵尸子进程的父进程ID将被重置为1(init进程)。继承这些子进程的init进程将清理它们(也就是说init进程将wait它们,从而去除它们的僵尸状态)。
36、如何避免僵尸进程?
-
通过signal(SIGCHLD, SIG_IGN)通知内核对子进程的结束不关心,由内核回收。如果不想让父进程挂起,可以在父进程中加入一条语句:signal(SIGCHLD,SIG_IGN);表示父进程忽略SIGCHLD信号,该信号是子进程退出的时候向父进程发送的。
-
父进程调用wait/waitpid等函数等待子进程结束,如果尚无子进程退出wait会导致父进程阻塞。waitpid可以通过传递WNOHANG使父进程不阻塞立即返回。
-
如果父进程很忙可以用signal注册信号处理函数,在信号处理函数调用wait/waitpid等待子进程退出。
-
通过两次调用fork。父进程首先调用fork创建一个子进程然后waitpid等待子进程退出,子进程再fork一个孙进程后退出。这样子进程退出后会被父进程等待回收,而对于孙子进程其父进程已经退出所以孙进程成为一个孤儿进程,孤儿进程由init进程接管,孙进程结束后,init会等待回收。
第一种方法忽略SIGCHLD信号,这常用于并发服务器的性能的一个技巧因为并发服务器常常fork很多子进程,子进程终结之后需要服务器进程去wait清理资源。如果将此信号的处理方式设为忽略,可让内核把僵尸子进程转交给init进程去处理,省去了大量僵尸进程占用系统资源。
《Linux系统下创建守护进程(Daemon)》:https://blog.csdn.net/linkedin_35878439/article/details/81288889
《01_fork()的使用》:https://blog.csdn.net/WUZHU2017/article/details/81636851
37、局部性原理你知道吗?主要有哪两大局部性原理?各自是什么?
主要分为时间局部性和空间局部性。
时间局部性:如果执行了程序中的某条指令,那么不久后这条指令很有可能再次执行;如果某个数据被访问过,不久之后该数据很可能再次被访问。(因为程序中存在大量的循环) 空间局部性:一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的,并且程序的指令也是顺序地在内存中存放的)

38、父进程、子进程、进程组、作业和会话
父进程
已创建一个或多个子进程的进程
子进程
由fork创建的新进程被称为子进程(child process)。该函数被调用一次,但返回两次。两次返回的区别是子进程的返回值是0,而父进程的返回值则是新进程(子进程)的进程 id。将子进程id返回给父进程的理由是:因为一个进程的子进程可以多于一个,没有一个函数使一个进程可以获得其所有子进程的进程id。对子进程来说,之所以fork返回0给它,是因为它随时可以调用getpid()来获取自己的pid;也可以调用getppid()来获取父进程的id。(进程id 0总是由交换进程使用,所以一个子进程的进程id不可能为0 )。
fork之后,操作系统会复制一个与父进程完全相同的子进程,虽说是父子关系,但是在操作系统看来,他们更像兄弟关系,这2个进程共享代码空间,但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,子进程拥有父进程当前运行到的位置(两进程的程序计数器pc值相同,也就是说,子进程是从fork返回处开始执行的),但有一点不同,如果fork成功,子进程中fork的返回值是0,父进程中fork的返回值是子进程的进程号,如果fork不成功,父进程会返回错误。
子进程从父进程继承的有:1.进程的资格(真实(real)/有效(effective)/已保存(saved)用户号(UIDs)和组号(GIDs))2.环境(environment)3.堆栈4.内存5.进程组号
独有:1.进程号;2.不同的父进程号(译者注:即子进程的父进程号与父进程的父进程号不同, 父进程号可由getppid函数得到);3.资源使用(resource utilizations)设定为0
进程组
进程组就是多个进程的集合,其中肯定有一个组长,其进程PID等于进程组的PGID。只要在某个进程组中一个进程存在,该进程组就存在,这与其组长进程是否终止无关。
作业
shell分前后台来控制的不是进程而是作业(job)或者进程组(Process Group)。
一个前台作业可以由多个进程组成,一个后台也可以由多个进程组成,shell可以运行一个前台作业和任意多个后台作业,这称为作业控制
为什么只能运行一个前台作业? 答:当我们在前台新起了一个作业,shell就被提到了后台,因此shell就没有办法再继续接受我们的指令并且解析运行了。 但是如果前台进程退出了,shell就会有被提到前台来,就可以继续接受我们的命令并且解析运行。
作业与进程组的区别:如果作业中的某个进程有创建了子进程,则该子进程是不属于该作业的。 一旦作业运行结束,shell就把自己提到前台(子进程还存在,但是子进程不属于作业),如果原来的前台进程还存在(这个子进程还没有终止),他将自动变为后台进程组
会话
会话(Session)是一个或多个进程组的集合。一个会话可以有一个控制终端。在xshell或者WinSCP中打开一个窗口就是新建一个会话。
39、进程终止的几种方式
1、main函数的自然返回,return
2、调用exit函数,属于c的函数库
3、调用_exit函数,属于系统调用
4、调用abort函数,异常程序终止,同时发送SIGABRT信号给调用进程。
5、接受能导致进程终止的信号:ctrl+c (^C)、SIGINT(SIGINT中断进程)
exit和_exit的区别
《学习笔记]进程终止的5种方式》:https://www.cnblogs.com/shichuan/p/4432503.html
40、Linux中异常和中断的区别
中断
大家都知道,当我们在敲击键盘的同时就会产生中断,当硬盘读写完数据之后也会产生中断,所以,我们需要知道,中断是由硬件设备产生的,而它们从物理上说就是电信号,之后,它们通过中断控制器发送给CPU,接着CPU判断收到的中断来自于哪个硬件设备(这定义在内核中),最后,由CPU发送给内核,有内核处理中断。下面这张图显示了中断处理的流程:
异常
我们在学习《计算机组成原理》的时候会知道两个概念,CPU处理程序的时候一旦程序不在内存中,会产生缺页异常;当运行除法程序时,当除数为0时,又会产生除0异常。所以,大家也需要记住的是,异常是由CPU产生的,同时,它会发送给内核,要求内核处理这些异常,下面这张图显示了异常处理的流程:
相同点
-
最后都是由CPU发送给内核,由内核去处理
-
处理程序的流程设计上是相似的
不同点
- 产生源不相同,异常是由CPU产生的,而中断是由硬件设备产生的
- 内核需要根据是异常还是中断调用不同的处理程序
- 中断不是时钟同步的,这意味着中断可能随时到来;异常由于是CPU产生的,所以它是时钟同步的
- 当处理中断时,处于中断上下文中;处理异常时,处于进程上下文中
《Linux内核--异常和中断的区别》:https://blog.csdn.net/u011068464/article/details/10284741
41、Windows和Linux环境下内存分布情况
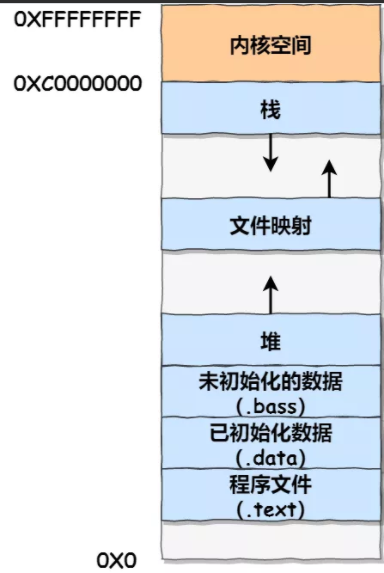
通过这张图你可以看到,用户空间内存,从低到高分别是 7 种不同的内存段:
- 程序文件段,包括二进制可执行代码;
- 已初始化数据段,包括静态常量;
- 未初始化数据段,包括未初始化的静态变量;
- 堆段,包括动态分配的内存,从低地址开始向上增长;
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增长(跟硬件和内核版本有关)
- 栈段,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是
8 MB。当然系统也提供了参数,以便我们自定义大小;
42、一个由C/C++编译的程序占用的内存分为哪几个部分?
1、栈区(stack)— 地址向下增长,由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的队列,先进后出。
2、堆区(heap)— 地址向上增长,一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区)(static)—全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。程序结束后由系统释放
5、程序代码区(text)—存放函数体的二进制代码。
43、一般情况下在Linux/windows平台下栈空间的大小
Linux环境下有操作系统决定,一般是8KB,8192kbytes,通过ulimit命令查看以及修改
Windows环境下由编译器决定,VC++6.0一般是1M
Linux
linux下非编译器决定栈大小,而是由操作系统环境决定,默认是8192KB(8M);而在Windows平台下栈的大小是被记录在可执行文件中的(由编译器来设置),即:windows下可以由编译器决定栈大小,而在Linux下是由系统环境变量来控制栈的大小的。
在Linux下通过如下命令可查看和设置栈的大小:
$ ulimit -a # 显示当前栈的大小 (ulimit为系统命令,非编译器命令)
$ ulimit -s 32768 # 设置当前栈的大小为32M
Windows
下程序栈空间的大小,VC++ 6.0 默认的栈空间是1M。
VC6.0中修改堆栈大小的方法:
- 选择 "Project->Setting"
- 选择 "Link"
- 选择 "Category"中的 "Output"
- 在 "Stack allocations"中的"Reserve:"中输栈的大小
《Linux/windows栈大小》:https://blog.csdn.net/HQ354974212/article/details/76087676
44、程序从堆中动态分配内存时,虚拟内存上怎么操作的
页表:是一个存放在物理内存中的数据结构,它记录了虚拟页与物理页的映射关系
在进行动态内存分配时,例如malloc()函数或者其他高级语言中的new关键字,操作系统会在硬盘中创建或申请一段虚拟内存空间,并更新到页表(分配一个页表条目(PTE),使该PTE指向硬盘上这个新创建的虚拟页),通过PTE建立虚拟页和物理页的映射关系。
45、常见的几种磁盘调度算法
读写一个磁盘块的时间的影响因素有:
- 旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上)
- 寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)
- 实际的数据传输时间
其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。
1. 先来先服务
按照磁盘请求的顺序进行调度。
优点是公平和简单。缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
2. 最短寻道时间优先
优先调度与当前磁头所在磁道距离最近的磁道。
虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两端的磁道请求更容易出现饥饿现象。
3. 电梯扫描算法
电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘请求,然后改变方向。
因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。
46、交换空间与虚拟内存的关系
交换空间 Linux 中的交换空间(Swap space)在物理内存(RAM)被充满时被使用。如果系统需要更多的内存资源,而物理内存已经充满,内存中不活跃的页就会被移到交换空间去。虽然交换空间可以为带有少量内存的机器提供帮助,但是这种方法不应该被当做是对内存的取代。交换空间位于硬盘驱动器上,它比进入物理内存要慢。 交换空间可以是一个专用的交换分区(推荐的方法),交换文件,或两者的组合。 交换空间的总大小应该相当于你的计算机内存的两倍和 32 MB这两个值中较大的一个,但是它不能超过 2048MB(2 GB)。 虚拟内存 虚拟内存是文件数据交叉链接的活动文件。是WINDOWS目录下的一个"WIN386.SWP"文件,这个文件会不断地扩大和自动缩小。 就速度方面而言,CPU的L1和L2缓存速度最快,内存次之,硬盘再次之。但是虚拟内存使用的是硬盘的空间,为什么我们要使用速度最慢的硬盘来做 为虚拟内存呢?因为电脑中所有运行的程序都需要经过内存来执行,如果执行的程序很大或很多,就会导致我们只有可怜的256M/512M内存消耗殆尽。而硬盘空间动辄几十G上百G,为了解决这个问题,Windows中运用了虚拟内存技术,即拿出一部分硬盘空间来充当内存使用。
《交换空间和虚拟内存的区别》:https://blog.csdn.net/qsd007/article/details/1567955
47、抖动你知道是什么吗?它也叫颠簸现象
刚刚换出的页面马上又要换入内存,刚刚换入的页面马上又要换出外存,这种频繁的页面调度行为称为抖动,或颠簸。产生抖动的主要原因是进程频繁访问的页面数目高于可用的物理块数(分配给进程的物理块不够)
为进程分配的物理块太少,会使进程发生抖动现象。为进程分配的物理块太多,又会降低系统整体的并发度,降低某些资源的利用率 为了研究为应该为每个进程分配多少个物理块,Denning 提出了进程工作集” 的概念
48、从堆和栈上建立对象哪个快?(考察堆和栈的分配效率比较)
从两方面来考虑:
-
分配和释放,堆在分配和释放时都要调用函数(malloc,free),比如分配时会到堆空间去寻找足够大小的空间(因为多次分配释放后会造成内存碎片),这些都会花费一定的时间,具体可以看看malloc和free的源代码,函数做了很多额外的工作,而栈却不需要这些。
-
访问时间,访问堆的一个具体单元,需要两次访问内存,第一次得取得指针,第二次才是真正的数据,而栈只需访问一次。另外,堆的内容被操作系统交换到外存的概率比栈大,栈一般是不会被交换出去的。
49、常见内存分配方式有哪些?
内存分配方式
(1) 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
(2) 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3) 从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
50、常见内存分配内存错误
(1)内存分配未成功,却使用了它。
编程新手常犯这种错误,因为他们没有意识到内存分配会不成功。常用解决办法是,在使用内存之前检查指针是否为NULL。如果指针p是函数的参数,那么在函数的入口处用assert(p!=NULL)进行检查。如果是用malloc或new来申请内存,应该用if(p==NULL) 或if(p!=NULL)进行防错处理。
(2)内存分配虽然成功,但是尚未初始化就引用它。
犯这种错误主要有两个起因:一是没有初始化的观念;二是误以为内存的缺省初值全为零,导致引用初值错误(例如数组)。内存的缺省初值究竟是什么并没有统一的标准,尽管有些时候为零值,我们宁可信其无不可信其有。所以无论用何种方式创建数组,都别忘了赋初值,即便是赋零值也不可省略,不要嫌麻烦。
(3)内存分配成功并且已经初始化,但操作越过了内存的边界。
例如在使用数组时经常发生下标“多1”或者“少1”的操作。特别是在for循环语句中,循环次数很容易搞错,导致数组操作越界。
(4)忘记了释放内存,造成内存泄露。
含有这种错误的函数每被调用一次就丢失一块内存。刚开始时系统的内存充足,你看不到错误。终有一次程序突然挂掉,系统出现提示:内存耗尽。动态内存的申请与释放必须配对,程序中malloc与free的使用次数一定要相同,否则肯定有错误(new/delete同理)。
(5)释放了内存却继续使用它。常见于以下有三种情况:
-
程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。
-
函数的return语句写错了,注意不要返回指向“栈内存”的“指针”或者“引用”,因为该内存在函数体结束时被自动销毁。
-
使用free或delete释放了内存后,没有将指针设置为NULL。导致产生“野指针”。
《内存分配方式及常见错误》:https://www.cnblogs.com/skynet/archive/2010/12/03/1895045.html
应该在外存(磁盘)的什么位置保存被换出的进程?
51、内存交换中,被换出的进程保存在哪里?
保存在磁盘中,也就是外存中。具有对换功能的操作系统中,通常把磁盘空间分为文件区和对换区两部分。文件区主要用于存放文件,主要追求存储空间的利用率,因此对文件区空间的管理采用离散分配方式;对换区空间只占磁盘空间的小部分,被换出的进程数据就存放在对换区。由于对换的速度直接影响到系统的整体速度,因此对换区空间的管理主要追求换入换出速度,因此通常对换区采用连续分配方式(学过文件管理章节后即可理解)。总之,对换区的I/O速度比文件区的更快。
52、在发生内存交换时,有些进程是被优先考虑的?你可以说一说吗?
可优先换出阻塞进程;可换出优先级低的进程;为了防止优先级低的进程在被调入内存后很快又被换出,有的系统还会考虑进程在内存的驻留时间… (注意: PCB 会常驻内存,不会被换出外存)
53、ASCII、Unicode和UTF-8编码的区别?
ASCII
ASCII 只有127个字符,表示英文字母的大小写、数字和一些符号,但由于其他语言用ASCII 编码表示字节不够,例如:常用中文需要两个字节,且不能和ASCII冲突,中国定制了GB2312编码格式,相同的,其他国家的语言也有属于自己的编码格式
Unicode
由于每个国家的语言都有属于自己的编码格式,在多语言编辑文本中会出现乱码,这样Unicode应运而生,Unicode就是将这些语言统一到一套编码格式中,通常两个字节表示一个字符,而ASCII是一个字节表示一个字符,这样如果你编译的文本是全英文的,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算
UTF-8
为了解决上述问题,又出现了把Unicode编码转化为“可变长编码”UTF-8编码,UTF-8编码将Unicode字符按数字大小编码为1-6个字节,英文字母被编码成一个字节,常用汉字被编码成三个字节,如果你编译的文本是纯英文的,那么用UTF-8就会非常节省空间,并且ASCII码也是UTF-8的一部分
三者之间的联系
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
(1) 在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码
(2)用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。如下图(截取他人图片)
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
《字符编码中ASCII、Unicode和UTF-8的区别》:https://www.cnblogs.com/moumoon/p/10988234.html
54、原子操作的是如何实现的
**处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作。**首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。Pentium 6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器是不能自动保证其原子性的,比如跨总线宽度、跨多个缓存行和跨页表的访问。但是,处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
(1)使用总线锁保证原子性 第一个机制是通过总线锁保证原子性。如果多个处理器同时对共享变量进行读改写操作(i++就是经典的读改写操作),那么共享变量就会被多个处理器同时进行操作,这样读改写操作就不是原子的,操作完之后共享变量的值会和期望的不一致。举个例子,如果i=1,我们进行两次i++操作,我们期望的结果是3,但是有可能结果是2,如图下图所示。
CPU1 CPU2
i=1 i=1
i+1 i+1
i=2 i=2
原因可能是多个处理器同时从各自的缓存中读取变量i,分别进行加1操作,然后分别写入系统内存中。那么,想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
处理器使用总线锁就是来解决这个问题的。所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
(2)使用缓存锁保证原子性 第二个机制是通过缓存锁定来保证原子性。在同一时刻,我们只需保证对某个内存地址的操作是原子性即可,但总线锁定把CPU和内存之间的通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,目前处理器在某些场合下使用缓存锁定代替总线锁定来进行优化。
频繁使用的内存会缓存在处理器的L1、L2和L3高速缓存里,那么原子操作就可以直接在处理器内部缓存中进行,并不需要声明总线锁,在Pentium 6和目前的处理器中可以使用“缓存锁定”的方式来实现复杂的原子性。所谓“缓存锁定”是指内存区域如果被缓存在处理器的缓存行中,并且在Lock操作期间被锁定,那么当它执行锁操作回写到内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时,会使缓存行无效,在如上图所示的例子中,当CPU1修改缓存行中的i时使用了缓存锁定,那么CPU2就不能使用同时缓存i的缓存行。
但是有两种情况下处理器不会使用缓存锁定。 第一种情况是:当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行(cache line)时,则处理器会调用总线锁定。 第二种情况是:有些处理器不支持缓存锁定。对于Intel 486和Pentium处理器,就算锁定的内存区域在处理器的缓存行中也会调用总线锁定。
《原子操作的实现原理》:https://blog.csdn.net/zxx901221/article/details/83033998
55、内存交换你知道有哪些需要注意的关键点吗?
- 交换需要备份存储,通常是快速磁盘,它必须足够大,并且提供对这些内存映像的直接访问。
- 为了有效使用CPU,需要每个进程的执行时间比交换时间长,而影响交换时间的主要是转移时间,转移时间与所交换的空间内存成正比。
- 如果换出进程,比如确保该进程的内存空间成正比。
- 交换空间通常作为磁盘的一整块,且独立于文件系统,因此使用就可能很快。
- 交换通常在有许多进程运行且内存空间吃紧时开始启动,而系统负荷降低就暂停。
- 普通交换使用不多,但交换的策略的某些变种在许多系统中(如UNIX系统)仍然发挥作用。
56、系统并发和并行,分得清吗?
并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。
并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。
操作系统通过引入进程和线程,使得程序能够并发运行。
57、可能是最全的页面置换算法总结了
1、最佳置换法(OPT)
最佳置换算法(OPT,Optimal) :每次选择淘汰的页面将是以后永不使用,或者在最长时间内不再被访问的页面,这样可以保证最低的缺页率。
 最佳置换算法可以保证最低的缺页率,但实际上,只有在进程执行的过程中才能知道接下来会访问到的是哪个页面。操作系统无法提前预判页面访问序列。因此,最佳置换算法是无法实现的
最佳置换算法可以保证最低的缺页率,但实际上,只有在进程执行的过程中才能知道接下来会访问到的是哪个页面。操作系统无法提前预判页面访问序列。因此,最佳置换算法是无法实现的
2、先进先出置换算法(FIFO)
先进先出置换算法(FIFO) :每次选择淘汰的页面是最早进入内存的页面
实现方法:把调入内存的页面根据调入的先后顺序排成一个队列,需要换出页面时选择队头页面队列的最大长度取决于系统为进程分配了多少个内存块。
 Belady异常—当为进程分配的物理块数增大时,缺页次数不减反增的异常现象。
Belady异常—当为进程分配的物理块数增大时,缺页次数不减反增的异常现象。
只有FIFO算法会产生Belady异常,而LRU和OPT算法永远不会出现Belady异常。另外,FIFO算法虽然实现简单,但是该算法与进程实际运行时的规律不适应,因为先进入的页面也有可能最经常被访问。因此,算法性能差
FIFO的性能较差,因为较早调入的页往往是经常被访问的页,这些页在FIFO算法下被反复调入和调出,并且有Belady现象。所谓Belady现象是指:采用FIFO算法时,如果对—个进程未分配它所要求的全部页面,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。
3、最近最久未使用置换算法(LRU)
最近最久未使用置换算法(LRU,least recently used) :每次淘汰的页面是最近最久未使用的页面 实现方法:赋予每个页面对应的页表项中,用访问字段记录该页面自.上次被访问以来所经历的时间t(该算法的实现需要专门的硬件支持,虽然算法性能好,但是实现困难,开销大)。当需要淘汰一个页面时,选择现有页面中t值最大的,即最近最久未使用的页面。
LRU性能较好,但需要寄存器和栈的硬件支持。LRU是堆栈类算法,理论上可以证明,堆栈类算法不可能出现Belady异常。
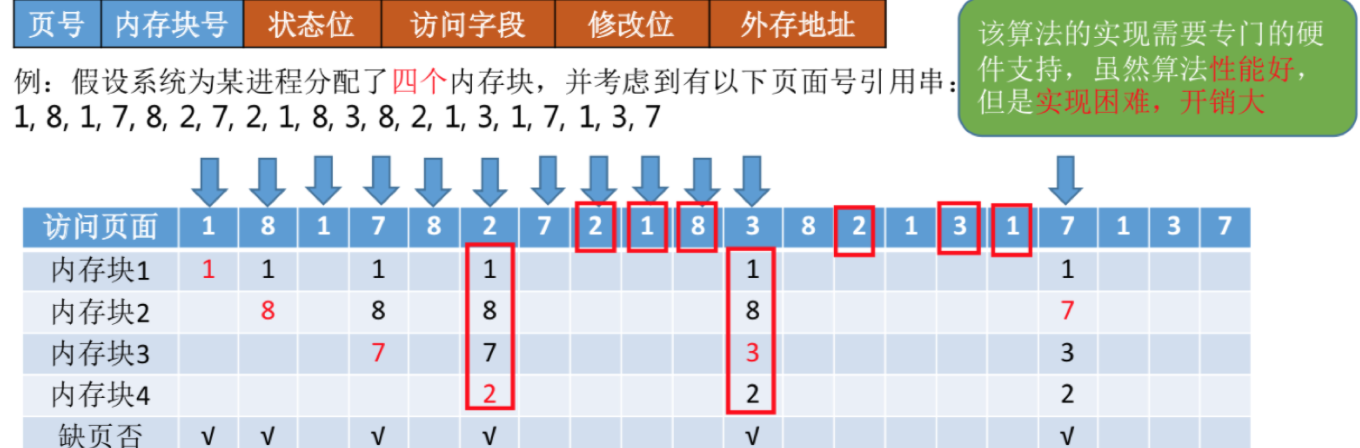 在手动做题时,若需要淘汰页面,可以逆向检查此时在内存中的几个页面号。在逆向扫描过程中最后一个出现的页号就是要淘汰的页面。
在手动做题时,若需要淘汰页面,可以逆向检查此时在内存中的几个页面号。在逆向扫描过程中最后一个出现的页号就是要淘汰的页面。
4、时钟置换算法(CLOCK)
最佳置换算法性OPT能最好,但无法实现;先进先出置换算法实现简单,但算法性能差;最近最久未使用置换算法性能好,是最接近OPT算法性能的,但是实现起来需要专门的硬件支持,算法开销大。
所以操作系统的设计者尝试了很多算法,试图用比较小的开销接近LRU的性能,这类算法都是CLOCK算法的变体,因为算法要循环扫描缓冲区像时钟一样转动。所以叫clock算法。
时钟置换算法是一种性能和开销较均衡的算法,又称CLOCK算法,或最近未用算法(NRU,Not Recently Used)
简单的CLOCK算法实现方法:为每个页面设置一个访问位,再将内存中的页面都通过链接指针链接成一个循环队列。当某页被访问时,其访问位置为1。当需要淘汰-一个页面时,只需检查页的访问位。如果是0,就选择该页换出;如果是1,则将它置为0,暂不换出,继续检查下一个页面,若第- - ~轮扫描中所有页面都是1,则将这些页面的访问位依次置为0后,再进行第二轮扫描(第二轮扫描中一定会有访问位为0的页面,因此简单的CLOCK算法选择–个淘汰页面最多会经过两轮扫描)
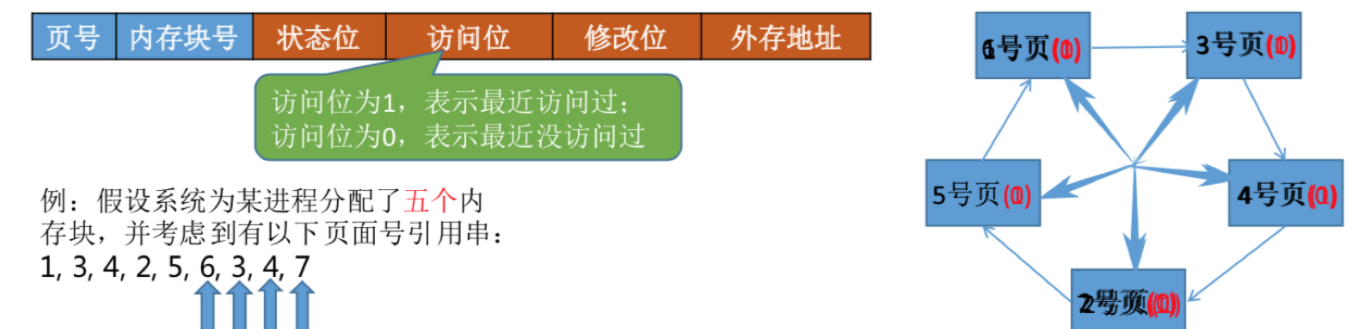
5、改进型的时钟置换算法
简单的时钟置换算法仅考虑到一个页面最近是否被访问过。事实上,如果被淘汰的页面没有被修改过,就不需要执行I/O操作写回外存。只有被淘汰的页面被修改过时,才需要写回外存。
因此,除了考虑一个页面最近有没有被访问过之外,操作系统还应考虑页面有没有被修改过。在其他条件都相同时,应优先淘汰没有修改过的页面,避免I/O操作。这就是改进型的时钟置换算法的思想。修改位=0,表示页面没有被修改过;修改位=1,表示页面被修改过。
为方便讨论,用(访问位,修改位)的形式表示各页面状态。如(1, 1)表示一个页面近期被访问过,且被修改过。
改进型的Clock算法需要综合考虑某一内存页面的访问位和修改位来判断是否置换该页面。在实际编写算法过程中,同样可以用一个等长的整型数组来标识每个内存块的修改状态。访问位A和修改位M可以组成一下四种类型的页面。
算法规则:将所有可能被置换的页面排成–个循环队列
第一轮:从当前位置开始扫描到第一个(A =0, M = 0)的帧用于替换。表示该页面最近既未被访问,又未被修改,是最佳淘汰页 第二轮:若第一轮扫描失败,则重新扫描,查找第一个(A =0, M = 1)的帧用于替换。本轮将所有扫描过的帧访问位设为0。表示该页面最近未被访问,但已被修改,并不是很好的淘汰页。 第三轮:若第二轮扫描失败,则重新扫描,查找第一个(A =1, M = 0)的帧用于替换。本轮扫描不修改任何标志位。表示该页面最近已被访问,但未被修改,该页有可能再被访问。 第四轮:若第三轮扫描失败,则重新扫描,查找第一个A =1, M = 1)的帧用于替换。表示该页最近已被访问且被修改,该页可能再被访问。
由于第二轮已将所有帧的访问位设为0,因此经过第三轮、第四轮扫描一定会有一个帧被选中,因此改进型CLOCK置换算法选择- -个淘汰页面最多会进行四轮扫描
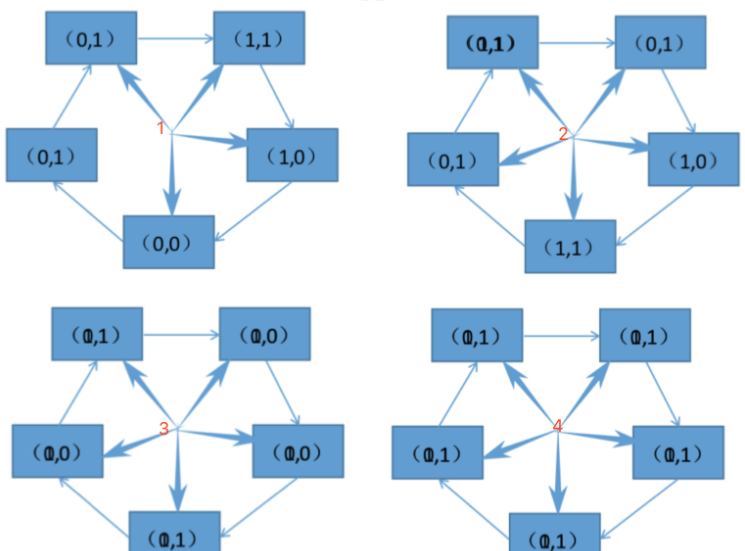 算法规则:将所有可能被置换的页面排成一个循环队列
第一轮:从当前位置开始扫描到第-一个(0, 0)的帧用于替换。本轮扫描不修改任何标志位。(第一优先级:最近没访问,且没修改的页面)
第二轮:若第一轮扫描失败,则重新扫描,查找第一个(0, 1)的帧用于替换。本轮将所有扫描过的帧访问位设为0
(第二优先级: 最近没访问,但修改过的页面)
第三轮:若第二轮扫描失败,则重新扫描,查找第一个(0, 0)的帧用于替换。本轮扫描不修改任何标志位(第三优先级:最近访问过,但没修改的页面)
第四轮:若第三轮扫描失败,则重新扫描,查找第一个(0, 1)的帧用于替换。(第四优先级:最近访问过,且修改过的页面)
由于第二轮已将所有帧的访问位设为0,因此经过第三轮、第四轮扫描一定会有一个帧被选中,因此改进型CLOCK置换算法选择一个淘汰页面最多会进行四轮扫描
算法规则:将所有可能被置换的页面排成一个循环队列
第一轮:从当前位置开始扫描到第-一个(0, 0)的帧用于替换。本轮扫描不修改任何标志位。(第一优先级:最近没访问,且没修改的页面)
第二轮:若第一轮扫描失败,则重新扫描,查找第一个(0, 1)的帧用于替换。本轮将所有扫描过的帧访问位设为0
(第二优先级: 最近没访问,但修改过的页面)
第三轮:若第二轮扫描失败,则重新扫描,查找第一个(0, 0)的帧用于替换。本轮扫描不修改任何标志位(第三优先级:最近访问过,但没修改的页面)
第四轮:若第三轮扫描失败,则重新扫描,查找第一个(0, 1)的帧用于替换。(第四优先级:最近访问过,且修改过的页面)
由于第二轮已将所有帧的访问位设为0,因此经过第三轮、第四轮扫描一定会有一个帧被选中,因此改进型CLOCK置换算法选择一个淘汰页面最多会进行四轮扫描
6、总结
| 算法规则 | 优缺点 | |
|---|---|---|
| OPT | 优先淘汰最长时间内不会被访问的页面 | 缺页率最小,性能最好;但无法实现 |
| FIFO | 优先淘汰最先进入内存的页面 | 实现简单;但性能很差,可能出现Belady异常 |
| LRU | 优先淘汰最近最久没访问的页面 | 性能很好;但需要硬件支持,算法开销大 |
| CLOCK (NRU) | 循环扫描各页面 第一轮淘汰访问位=0的,并将扫描过的页面访问位改为1。若第-轮没选中,则进行第二轮扫描。 | 实现简单,算法开销小;但未考虑页面是否被修改过。 |
| 改进型CLOCK (改进型NRU) | 若用(访问位,修改位)的形式表述,则 第一轮:淘汰(0,0) 第二轮:淘汰(O,1),并将扫描过的页面访问位都置为0 第三轮:淘汰(O, 0) 第四轮:淘汰(0, 1) | 算法开销较小,性能也不错 |
58、共享是什么?
共享是指系统中的资源可以被多个并发进程共同使用。
有两种共享方式:互斥共享和同时共享。
互斥共享的资源称为临界资源,例如打印机等,在同一时刻只允许一个进程访问,需要用同步机制来实现互斥访问。
59、死锁相关问题大总结,超全!
死锁是指两个(多个)线程相互等待对方数据的过程,死锁的产生会导致程序卡死,不解锁程序将永远无法进行下去。
1、死锁产生原因
举个例子:两个线程A和B,两个数据1和2。线程A在执行过程中,首先对资源1加锁,然后再去给资源2加锁,但是由于线程的切换,导致线程A没能给资源2加锁。线程切换到B后,线程B先对资源2加锁,然后再去给资源1加锁,由于资源1已经被线程A加锁,因此线程B无法加锁成功,当线程切换为A时,A也无法成功对资源2加锁,由此就造成了线程AB双方相互对一个已加锁资源的等待,死锁产生。
理论上认为死锁产生有以下四个必要条件,缺一不可:
-
互斥条件:进程对所需求的资源具有排他性,若有其他进程请求该资源,请求进程只能等待。
-
不剥夺条件:进程在所获得的资源未释放前,不能被其他进程强行夺走,只能自己释放。
-
请求和保持条件:进程当前所拥有的资源在进程请求其他新资源时,由该进程继续占有。
-
循环等待条件:存在一种进程资源循环等待链,链中每个进程已获得的资源同时被链中下一个进程所请求。
2、死锁演示
通过代码的形式进行演示,需要两个线程和两个互斥量。
#include <iostream>
#include <vector>
#include <list>
#include <thread>
#include <mutex> //引入互斥量头文件
using namespace std;
class A {
public:
//插入消息,模拟消息不断产生
void insertMsg() {
for (int i = 0; i < 100; i++) {
cout << "插入一条消息:" << i << endl;
my_mutex1.lock(); //语句1
my_mutex2.lock(); //语句2
Msg.push_back(i);
my_mutex2.unlock();
my_mutex1.unlock();
}
}
//读取消息
void readMsg() {
int MsgCom;
for (int i = 0; i < 100; i++) {
MsgCom = MsgLULProc(i);
if (MsgLULProc(MsgCom)) {
//读出消息了
cout << "消息已读出" << MsgCom << endl;
}
else {
//消息暂时为空
cout << "消息为空" << endl;
}
}
}
//加解锁代码
bool MsgLULProc(int &command) {
int curMsg;
my_mutex2.lock(); //语句3
my_mutex1.lock(); //语句4
if (!Msg.empty()) {
//读取消息,读完删除
command = Msg.front();
Msg.pop_front();
my_mutex1.unlock();
my_mutex2.unlock();
return true;
}
my_mutex1.unlock();
my_mutex2.unlock();
return false;
}
private:
std::list<int> Msg; //消息变量
std::mutex my_mutex1; //互斥量对象1
std::mutex my_mutex2; //互斥量对象2
};
int main() {
A a;
//创建一个插入消息线程
std::thread insertTd(&A::insertMsg, &a); //这里要传入引用保证是同一个对象
//创建一个读取消息线程
std::thread readTd(&A::readMsg, &a); //这里要传入引用保证是同一个对象
insertTd.join();
readTd.join();
return 0;
}
语句1和语句2表示线程A先锁资源1,再锁资源2,语句3和语句4表示线程B先锁资源2再锁资源1,具备死锁产生的条件。
3、死锁的解决方案
保证上锁的顺序一致。
4、死锁必要条件
- 互斥条件:进程对所需求的资源具有排他性,若有其他进程请求该资源,请求进程只能等待。
- 不剥夺条件:进程在所获得的资源未释放前,不能被其他进程强行夺走,只能自己释放
- 请求和保持条件:进程当前所拥有的资源在进程请求其他新资源时,由该进程继续占有。
- 循环等待条件:存在一种进程资源循环等待链,链中每个进程已获得的资源同时被链中下一个进程所请求。
5、处理方法
主要有以下四种方法:
- 鸵鸟策略
- 死锁检测与死锁恢复
- 死锁预防
- 死锁避免
鸵鸟策略
把头埋在沙子里,假装根本没发生问题。
因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。
当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。
大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
死锁检测与死锁恢复
不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
1、每种类型一个资源的死锁检测
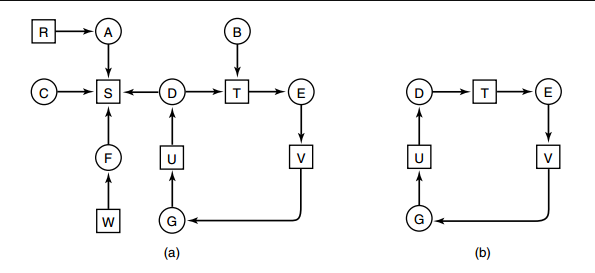
上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
2、每种类型多个资源的死锁检测

上图中,有三个进程四个资源,每个数据代表的含义如下:
- E 向量:资源总量
- A 向量:资源剩余量
- C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
- R 矩阵:每个进程请求的资源数量
进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
算法总结如下:
每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
- 寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。
- 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
- 如果没有这样一个进程,算法终止。
6、死锁恢复
- 利用抢占恢复
- 利用回滚恢复
- 通过杀死进程恢复
7、死锁预防
在程序运行之前预防发生死锁。
- 破坏互斥条件
例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
- 破坏请求和保持条件
一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
- 破坏不剥夺条件
允许抢占资源
- 破坏循环请求等待
给资源统一编号,进程只能按编号顺序来请求资源。
8、死锁避免
在程序运行时避免发生死锁。
- 安全状态
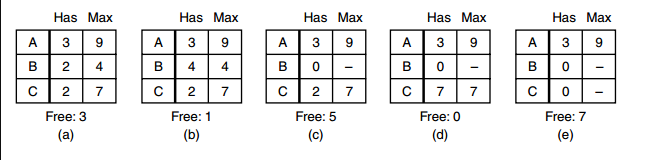
图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比。
- 单个资源的银行家算法
一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
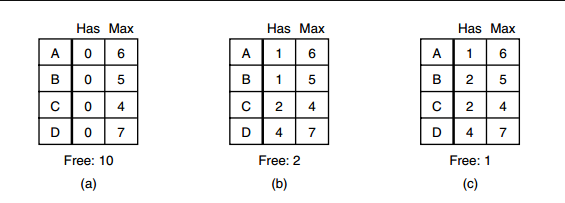
上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
- 多个资源的银行家算法
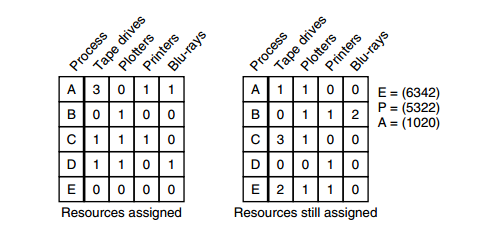
上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
4、检查一个状态是否安全的算法如下:
- 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
- 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
- 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
如果一个状态不是安全的,需要拒绝进入这个状态。
60、为什么分段式存储管理有外部碎片而无内部碎片?为什么固定分区分配有内部碎片而不会有外部碎片?
分段式分配是按需分配,而固定式分配是固定分配的方式
61、内部碎片与外部碎片
内碎片:分配给某些进程的内存区域中有些部分没用上,常见于固定分配方式
内存总量相同,100M
固定分配,将100M分割成10块,每块10M,一个程序需要45M,那么需要分配5块,第五块只用了5M,剩下的5M就是内部碎片;
分段式分配,按需分配,一个程序需要45M,就给分片45MB,剩下的55M供其它程序使用,不存在内部碎片。
外碎片:内存中某些空闲区因为比较小,而难以利用上,一般出现在内存动态分配方式中
分段式分配:内存总量相同,100M,比如,内存分配依次5M,15M,50M,25M,程序运行一段时间之后,5M,15M的程序运行完毕,释放内存,其他程序还在运行,再次分配一个10M的内存供其它程序使用,只能从头开始分片,这样,就会存在10M+5M的外部碎片
62、如何消除碎片文件
对于外部碎片,通过紧凑技术消除,就是操作系统不时地对进程进行移动和整理。但是这需要动态重定位寄存器地支持,且相对费时。紧凑地过程实际上类似于Windows系统中地磁盘整理程序,只不过后者是对外存空间地紧凑
解决外部内存碎片的问题就是内存交换。
可以把音乐程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里。不过再读回的时候,我们不能装载回原来的位置,而是紧紧跟着那已经被占用了的 512MB 内存后面。这样就能空缺出连续的 256MB 空间,于是新的 200MB 程序就可以装载进来。
回收内存时要尽可能地将相邻的空闲空间合并。
😭 计算机网络
1、OSI 的七层模型分别是?各自的功能是什么?
简要概括
-
物理层:底层数据传输,如网线;网卡标准。
-
数据链路层:定义数据的基本格式,如何传输,如何标识;如网卡MAC地址。
-
网络层:定义IP编址,定义路由功能;如不同设备的数据转发。
-
传输层:端到端传输数据的基本功能;如 TCP、UDP。
-
会话层:控制应用程序之间会话能力;如不同软件数据分发给不同软件。
-
标识层:数据格式标识,基本压缩加密功能。
-
应用层:各种应用软件,包括 Web 应用。
说明:
- 在四层,既传输层数据被称作段(Segments);
- 三层网络层数据被称做包(Packages);
- 二层数据链路层时数据被称为帧(Frames);
- 一层物理层时数据被称为比特流(Bits)。
总结
- 网络七层模型是一个标准,而非实现。
- 网络四层模型是一个实现的应用模型。
- 网络四层模型由七层模型简化合并而来。
2、说一下一次完整的HTTP请求过程包括哪些内容?
第一种回答
- 建立起客户机和服务器连接。
- 建立连接后,客户机发送一个请求给服务器。
- 服务器收到请求给予响应信息。
- 客户端浏览器将返回的内容解析并呈现,断开连接。
第二种回答
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户。
3、你知道DNS是什么?
官方解释:DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。
通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。
通俗的讲,我们更习惯于记住一个网站的名字,比如www.baidu.com,而不是记住它的ip地址,比如:167.23.10.2。
4、DNS的工作原理?
将主机域名转换为ip地址,属于应用层协议,使用UDP传输。(DNS应用层协议,以前有个考官问过)
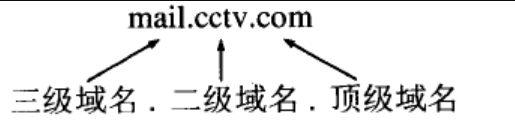 过程:
总结: 浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
一、主机向本地域名服务器的查询一般都是采用递归查询。
二、本地域名服务器向根域名服务器的查询的迭代查询。
1)当用户输入域名时,浏览器先检查自己的缓存中是否 这个域名映射的ip地址,有解析结束。
2)若没命中,则检查操作系统缓存(如Windows的hosts)中有没有解析过的结果,有解析结束。
3)若无命中,则请求本地域名服务器解析( LDNS)。
4)若LDNS没有命中就直接跳到根域名服务器请求解析。根域名服务器返回给LDNS一个 主域名服务器地址。
5) 此时LDNS再发送请求给上一步返回的gTLD( 通用顶级域), 接受请求的gTLD查找并返回这个域名对应的Name Server的地址
6) Name Server根据映射关系表找到目标ip,返回给LDNS
7) LDNS缓存这个域名和对应的ip, 把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束
过程:
总结: 浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
一、主机向本地域名服务器的查询一般都是采用递归查询。
二、本地域名服务器向根域名服务器的查询的迭代查询。
1)当用户输入域名时,浏览器先检查自己的缓存中是否 这个域名映射的ip地址,有解析结束。
2)若没命中,则检查操作系统缓存(如Windows的hosts)中有没有解析过的结果,有解析结束。
3)若无命中,则请求本地域名服务器解析( LDNS)。
4)若LDNS没有命中就直接跳到根域名服务器请求解析。根域名服务器返回给LDNS一个 主域名服务器地址。
5) 此时LDNS再发送请求给上一步返回的gTLD( 通用顶级域), 接受请求的gTLD查找并返回这个域名对应的Name Server的地址
6) Name Server根据映射关系表找到目标ip,返回给LDNS
7) LDNS缓存这个域名和对应的ip, 把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束
5、为什么域名解析用UDP协议?
因为UDP快啊!UDP的DNS协议只要一个请求、一个应答就好了。
而使用基于TCP的DNS协议要三次握手、发送数据以及应答、四次挥手,但是UDP协议传输内容不能超过512字节。
不过客户端向DNS服务器查询域名,一般返回的内容都不超过512字节,用UDP传输即可。
6、为什么区域传送用TCP协议?
因为TCP协议可靠性好啊!
你要从主DNS上复制内容啊,你用不可靠的UDP? 因为TCP协议传输的内容大啊,你用最大只能传512字节的UDP协议?万一同步的数据大于512字节,你怎么办?所以用TCP协议比较好!
7、HTTP长连接和短连接的区别
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。
8、什么是TCP粘包/拆包?发生的原因?
一个完整的业务可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这个就是TCP的拆包和粘包问题。
原因
1、应用程序写入数据的字节大小大于套接字发送缓冲区的大小.
2、进行MSS大小的TCP分段。( MSS=TCP报文段长度-TCP首部长度)
3、以太网的payload大于MTU进行IP分片。( MTU指:一种通信协议的某一层上面所能通过的最大数据包大小。)
解决方案
1、消息定长。
2、在包尾部增加回车或者空格符等特殊字符进行分割3. 将消息分为消息头和消息尾。4. 使用其它复杂的协议,如RTMP协议等。
9、为什么服务器会缓存这一项功能?如何实现的?
原因
- 缓解服务器压力;
- 降低客户端获取资源的延迟:缓存通常位于内存中,读取缓存的速度更快。并且缓存服务器在地理位置上也有可能比源服务器来得近,例如浏览器缓存。
实现方法
- 让代理服务器进行缓存;
- 让客户端浏览器进行缓存。
10、HTTP请求方法你知道多少?
客户端发送的 请求报文 第一行为请求行,包含了方法字段。
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
| 序 号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
11、GET 和 POST 的区别,你知道哪些?
-
get是获取数据,post是修改数据
-
get把请求的数据放在url上, 以?分割URL和传输数据,参数之间以&相连,所以get不太安全。而post把数据放在HTTP的包体内(requrest body)
-
get提交的数据最大是2k( 限制实际上取决于浏览器), post理论上没有限制。
-
GET产生一个TCP数据包,浏览器会把http header和data一并发送出去,服务器响应200(返回数据); POST产生两个TCP数据包,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
-
GET请求会被浏览器主动缓存,而POST不会,除非手动设置。
-
本质区别:GET是幂等的,而POST不是幂等的
这里的幂等性:幂等性是指一次和多次请求某一个资源应该具有同样的副作用。简单来说意味着对同一URL的多个请求应该返回同样的结果。
正因为它们有这样的区别,所以不应该且不能用get请求做数据的增删改这些有副作用的操作。因为get请求是幂等的,在网络不好的隧道中会尝试重试。如果用get请求增数据,会有重复操作的风险,而这种重复操作可能会导致副作用(浏览器和操作系统并不知道你会用get请求去做增操作)。
12、一个TCP连接可以对应几个HTTP请求?
如果维持连接,一个 TCP 连接是可以发送多个 HTTP 请求的。
13、一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
HTTP/1.1 存在一个问题,单个 TCP 连接在同一时刻只能处理一个请求,意思是说:两个请求的生命周期不能重叠,任意两个 HTTP 请求从开始到结束的时间在同一个 TCP 连接里不能重叠。
在 HTTP/1.1 存在 Pipelining 技术可以完成这个多个请求同时发送,但是由于浏览器默认关闭,所以可以认为这是不可行的。在 HTTP2 中由于 Multiplexing 特点的存在,多个 HTTP 请求可以在同一个 TCP 连接中并行进行。
那么在 HTTP/1.1 时代,浏览器是如何提高页面加载效率的呢?主要有下面两点:
- 维持和服务器已经建立的 TCP 连接,在同一连接上顺序处理多个请求。
- 和服务器建立多个 TCP 连接。
14、浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
假设我们还处在 HTTP/1.1 时代,那个时候没有多路传输,当浏览器拿到一个有几十张图片的网页该怎么办呢?肯定不能只开一个 TCP 连接顺序下载,那样用户肯定等的很难受,但是如果每个图片都开一个 TCP 连接发 HTTP 请求,那电脑或者服务器都可能受不了,要是有 1000 张图片的话总不能开 1000 个TCP 连接吧,你的电脑同意 NAT 也不一定会同意。
有。Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
如果图片都是 HTTPS 连接并且在同一个域名下,那么浏览器在 SSL 握手之后会和服务器商量能不能用 HTTP2,如果能的话就使用 Multiplexing 功能在这个连接上进行多路传输。不过也未必会所有挂在这个域名的资源都会使用一个 TCP 连接去获取,但是可以确定的是 Multiplexing 很可能会被用到。
如果发现用不了 HTTP2 呢?或者用不了 HTTPS(现实中的 HTTP2 都是在 HTTPS 上实现的,所以也就是只能使用 HTTP/1.1)。那浏览器就会在一个 HOST 上建立多个 TCP 连接,连接数量的最大限制取决于浏览器设置,这些连接会在空闲的时候被浏览器用来发送新的请求,如果所有的连接都正在发送请求呢?那其他的请求就只能等等了。
15、在浏览器中输入url地址后显示主页的过程?
- 根据域名,进行DNS域名解析;
- 拿到解析的IP地址,建立TCP连接;
- 向IP地址,发送HTTP请求;
- 服务器处理请求;
- 返回响应结果;
- 关闭TCP连接;
- 浏览器解析HTML;
- 浏览器布局渲染;
16、在浏览器地址栏输入一个URL后回车,背后会进行哪些技术步骤?
第一种回答
1、查浏览器缓存,看看有没有已经缓存好的,如果没有
2 、检查本机host文件,
3、调用API,Linux下Scoket函数 gethostbyname
4、向DNS服务器发送DNS请求,查询本地DNS服务器,这其中用的是UDP的协议
6、如果在一个子网内采用ARP地址解析协议进行ARP查询如果不在一个子网那就需要对默认网关进行DNS查询,如果还找不到会一直向上找根DNS服务器,直到最终拿到IP地址(全球好像一共有13台根服务器)
7、这个时候我们就有了服务器的IP地址 以及默认的端口号了,http默认是80 https是 443 端口号,会,首先尝试http然后调用Socket建立TCP连接,
8、经过三次握手成功建立连接后,开始传送数据,如果正是http协议的话,就返回就完事了,
9、如果不是http协议,服务器会返回一个5开头的的重定向消息,告诉我们用的是https,那就是说IP没变,但是端口号从80变成443了,好了,再四次挥手,完事,
10、再来一遍,这次除了上述的端口号从80变成443之外,还会采用SSL的加密技术来保证传输数据的安全性,保证数据传输过程中不被修改或者替换之类的,
11、这次依然是三次握手,沟通好双方使用的认证算法,加密和检验算法,在此过程中也会检验对方的CA安全证书。
12、确认无误后,开始通信,然后服务器就会返回你所要访问的网址的一些数据,在此过程中会将界面进行渲染,牵涉到ajax技术之类的,直到最后我们看到色彩斑斓的网页
第二种回答
浏览器检查域名是否在缓存当中(要查看 Chrome 当中的缓存, 打开 chrome://net-internals/#dns)。
如果缓存中没有,就去调用 gethostbyname 库函数(操作系统不同函数也不同)进行查询。
gethostbyname函数在试图进行DNS解析之前首先检查域名是否在本地 Hosts 里,Hosts 的位置 [不同的操作系统有所不同](https://en.wikipedia.org/wiki/Hosts_(file)#Location_in_the_file_system)
如果gethostbyname没有这个域名的缓存记录,也没有在hosts` 里找到,它将会向 DNS 服务器发送一条 DNS 查询请求。DNS 服务器是由网络通信栈提供的,通常是本地路由器或者 ISP 的缓存 DNS 服务器。
查询本地 DNS 服务器
如果 DNS 服务器和我们的主机在同一个子网内,系统会按照下面的 ARP 过程对 DNS 服务器进行 ARP查询
如果 DNS 服务器和我们的主机在不同的子网,系统会按照下面的 ARP 过程对默认网关进行查询
17、谈谈DNS解析过程,具体一点

- 请求一旦发起,若是chrome浏览器,先在浏览器找之前有没有缓存过的域名所对应的ip地址,有的话,直接跳过dns解析了,若是没有,就会找硬盘的hosts文件,看看有没有,有的话,直接找到hosts文件里面的ip
- 如果本地的hosts文件没有能的到对应的ip地址,浏览器会发出一个dns请求到本地dns服务器,本地dns服务器一般都是你的网络接入服务器商提供,比如中国电信,中国移动等。
- 查询你输入的网址的DNS请求到达本地DNS服务器之后,本地DNS服务器会首先查询它的缓存记录,如果缓存中有此条记录,就可以直接返回结果,此过程是递归的方式进行查询。如果没有,本地DNS服务器还要向DNS根服务器进行查询。
- 本地DNS服务器继续向域服务器发出请求,在这个例子中,请求的对象是.com域服务器。.com域服务器收到请求之后,也不会直接返回域名和IP地址的对应关系,而是告诉本地DNS服务器,你的域名的解析服务器的地址。
- 最后,本地DNS服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP地址对应关系,本地DNS服务器不仅要把IP地址返回给用户电脑,还要把这个对应关系保存在缓存中,以备下次别的用户查询时,可以直接返回结果,加快网络访问。
18、DNS负载均衡是什么策略?
当一个网站有足够多的用户的时候,假如每次请求的资源都位于同一台机器上面,那么这台机器随时可能会蹦掉。处理办法就是用DNS负载均衡技术,它的原理是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问引导到不同的机器上去,使得不同的客户端访问不同的服务器,从而达到负载均衡的目的。例如可以根据每台机器的负载量,该机器离用户地理位置的距离等等。
19、HTTPS和HTTP的区别
1、HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全, HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
2、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。 3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
20、什么是SSL/TLS ?
SSL代表安全套接字层。它是一种用于加密和验证应用程序(如浏览器)和Web服务器之间发送的数据的协议。 身份验证 , 加密Https的加密机制是一种共享密钥加密和公开密钥加密并用的混合加密机制。
SSL/TLS协议作用:认证用户和服务,加密数据,维护数据的完整性的应用层协议加密和解密需要两个不同的密钥,故被称为非对称加密;加密和解密都使用同一个密钥的
对称加密:优点在于加密、解密效率通常比较高 ,HTTPS 是基于非对称加密的, 公钥是公开的,
21、HTTPS是如何保证数据传输的安全,整体的流程是什么?(SSL是怎么工作保证安全的)
(1)客户端向服务器端发起SSL连接请求; (2) 服务器把公钥发送给客户端,并且服务器端保存着唯一的私钥 (3)客户端用公钥对双方通信的对称秘钥进行加密,并发送给服务器端 (4)服务器利用自己唯一的私钥对客户端发来的对称秘钥进行解密, (5)进行数据传输,服务器和客户端双方用公有的相同的对称秘钥对数据进行加密解密,可以保证在数据收发过程中的安全,即是第三方获得数据包,也无法对其进行加密,解密和篡改。
因为数字签名、摘要是证书防伪非常关键的武器。 “摘要”就是对传输的内容,通过hash算法计算出一段固定长度的串。然后,在通过CA的私钥对这段摘要进行加密,加密后得到的结果就是“数字签名”
SSL/TLS协议的基本思路是采用公钥加密法,也就是说,客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
22、如何保证公钥不被篡改?
将公钥放在数字证书中。只要证书是可信的,公钥就是可信的。 公钥加密计算量太大,如何减少耗用的时间? 每一次对话(session),客户端和服务器端都生成一个"对话密钥"(session key),用它来加密信息。由于"对话密钥"是对称加密,所以运算速度非常快,而服务器公钥只用于加密"对话密钥"本身,这样就减少了加密运算的消耗时间。 (1) 客户端向服务器端索要并验证公钥。 (2) 双方协商生成"对话密钥"。 (3) 双方采用"对话密钥"进行加密通信。上面过程的前两步,又称为"握手阶段"(handshake)。
23、HTTP请求和响应报文有哪些主要字段?
请求报文
简单来说:
- 请求行:Request Line
- 请求头:Request Headers
- 请求体:Request Body
响应报文
简单来说:
- 状态行:Status Line
- 响应头:Response Headers
- 响应体:Response Body
24、Cookie是什么?
HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务,HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。
新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API(本地存储和会话存储)或 IndexedDB。
cookie 的出现是因为 HTTP 是无状态的一种协议,换句话说,服务器记不住你,可能你每刷新一次网页,就要重新输入一次账号密码进行登录。这显然是让人无法接受的,cookie 的作用就好比服务器给你贴个标签,然后你每次向服务器再发请求时,服务器就能够 cookie 认出你。
抽象地概括一下:一个 cookie 可以认为是一个「变量」,形如 name=value,存储在浏览器;一个 session 可以理解为一种数据结构,多数情况是「映射」(键值对),存储在服务器上。
25、Cookie有什么用途?用途
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
26、Session知识大总结
除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session 存储在服务器端,存储在服务器端的信息更加安全。
Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在 Redis 这种内存型数据库中,效率会更高。
使用 Session 维护用户登录状态的过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
- 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
注意:Session ID 的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的 Session ID 值。此外,还需要经常重新生成 Session ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session 管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
27、Session 的工作原理是什么?
session 的工作原理是客户端登录完成之后,服务器会创建对应的 session,session 创建完之后,会把 session 的 id 发送给客户端,客户端再存储到浏览器中。这样客户端每次访问服务器时,都会带着 sessionid,服务器拿到 sessionid 之后,在内存找到与之对应的 session 这样就可以正常工作了。
28、Cookie与Session的对比
HTTP作为无状态协议,必然需要在某种方式保持连接状态。这里简要介绍一下Cookie和Session。
-
Cookie
Cookie是客户端保持状态的方法。
Cookie简单的理解就是存储由服务器发至客户端并由客户端保存的一段字符串。为了保持会话,服务器可以在响应客户端请求时将Cookie字符串放在Set-Cookie下,客户机收到Cookie之后保存这段字符串,之后再请求时候带上Cookie就可以被识别。
除了上面提到的这些,Cookie在客户端的保存形式可以有两种,一种是会话Cookie一种是持久Cookie,会话Cookie就是将服务器返回的Cookie字符串保持在内存中,关闭浏览器之后自动销毁,持久Cookie则是存储在客户端磁盘上,其有效时间在服务器响应头中被指定,在有效期内,客户端再次请求服务器时都可以直接从本地取出。需要说明的是,存储在磁盘中的Cookie是可以被多个浏览器代理所共享的。
-
Session
Session是服务器保持状态的方法。
首先需要明确的是,Session保存在服务器上,可以保存在数据库、文件或内存中,每个用户有独立的Session用户在客户端上记录用户的操作。我们可以理解为每个用户有一个独一无二的Session ID作为Session文件的Hash键,通过这个值可以锁定具体的Session结构的数据,这个Session结构中存储了用户操作行为。
当服务器需要识别客户端时就需要结合Cookie了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用Cookie来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在Cookie里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。如果客户端的浏览器禁用了Cookie,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如sid=xxxxx这样的参数,服务端据此来识别用户,这样就可以帮用户完成诸如用户名等信息自动填入的操作了。
29、SQL注入攻击了解吗?
攻击者在HTTP请求中注入恶意的SQL代码,服务器使用参数构建数据库SQL命令时,恶意SQL被一起构造,并在数据库中执行。 用户登录,输入用户名 lianggzone,密码 ‘ or ‘1’=’1 ,如果此时使用参数构造的方式,就会出现 select * from user where name = ‘lianggzone’ and password = ‘’ or ‘1’=‘1’ 不管用户名和密码是什么内容,使查询出来的用户列表不为空。如何防范SQL注入攻击使用预编译的PrepareStatement是必须的,但是一般我们会从两个方面同时入手。 Web端 1)有效性检验。 2)限制字符串输入的长度。 服务端 1)不用拼接SQL字符串。 2)使用预编译的PrepareStatement。 3)有效性检验。(为什么服务端还要做有效性检验?第一准则,外部都是不可信的,防止攻击者绕过Web端请求) 4)过滤SQL需要的参数中的特殊字符。比如单引号、双引号。
30、网络的七层模型与各自的功能(图片版)


31、什么是RARP?工作原理
概括: 反向地址转换协议,网络层协议,RARP与ARP工作方式相反。 RARP使只知道自己硬件地址的主机能够知道其IP地址。RARP发出要反向解释的物理地址并希望返回其IP地址,应答包括能够提供所需信息的RARP服务器发出的IP地址。 原理: (1)网络上的每台设备都会有一个独一无二的硬件地址,通常是由设备厂商分配的MAC地址。主机从网卡上读取MAC地址,然后在网络上发送一个RARP请求的广播数据包,请求RARP服务器回复该主机的IP地址。
(2)RARP服务器收到了RARP请求数据包,为其分配IP地址,并将RARP回应发送给主机。
(3)PC1收到RARP回应后,就使用得到的IP地址进行通讯。
32、端口有效范围是多少到多少?
0-1023为知名端口号,比如其中HTTP是80,FTP是20(数据端口)、21(控制端口)
UDP和TCP报头使用两个字节存放端口号,所以端口号的有效范围是从0到65535。动态端口的范围是从1024到65535
33、为何需要把 TCP/IP 协议栈分成 5 层(或7层)?开放式回答。
答:ARPANET 的研制经验表明,对于复杂的计算机网络协议,其结构应该是层次式的。
分层的好处:
①隔层之间是独立的
②灵活性好
③结构上可以分隔开
④易于实现和维护
⑤能促进标准化工作。
😱 数据结构与算法
正在整理ing,敬请期待
😫数据库(MySQL、Redis)
MySQL
正在整理ing,敬请期待
Redis
正在整理ing,敬请期待
😓 常见智力题、情景题
正在整理ing,敬请期待
😁 常见非技术性问题(比如你最大的缺点是什么)
正在整理ing,敬请期待