wqh0109663 / Jobspiders
Licence: apache-2.0
scrapy框架爬取51job(scrapy.Spider),智联招聘(扒接口),拉勾网(CrawlSpider)
Stars: ✭ 144
Programming Languages
Labels
Projects that are alternatives of or similar to Jobspiders
Wswp
Code for the second edition Web Scraping with Python book by Packt Publications
Stars: ✭ 112 (-22.22%)
Mutual labels: scrapy
Seleniumcrawler
An example using Selenium webdrivers for python and Scrapy framework to create a web scraper to crawl an ASP site
Stars: ✭ 117 (-18.75%)
Mutual labels: scrapy
Scrala
Unmaintained 🐳 ☕️ 🕷 Scala crawler(spider) framework, inspired by scrapy, created by @gaocegege
Stars: ✭ 113 (-21.53%)
Mutual labels: scrapy
Cnkispider
a spider for cnki patent content, just for study and commucation, no use for business.
Stars: ✭ 117 (-18.75%)
Mutual labels: scrapy
Maria Quiteria
Backend para coleta e disponibilização dos dados 📜
Stars: ✭ 115 (-20.14%)
Mutual labels: scrapy
Qqmusicspider
基于Scrapy的QQ音乐爬虫(QQ Music Spider),爬取歌曲信息、歌词、精彩评论等,并且分享了QQ音乐中排名前6400名的内地和港台歌手的49万+的音乐语料
Stars: ✭ 120 (-16.67%)
Mutual labels: scrapy
Docs
《数据采集从入门到放弃》源码。内容简介:爬虫介绍、就业情况、爬虫工程师面试题 ;HTTP协议介绍; Requests使用 ;解析器Xpath介绍; MongoDB与MySQL; 多线程爬虫; Scrapy介绍 ;Scrapy-redis介绍; 使用docker部署; 使用nomad管理docker集群; 使用EFK查询docker日志
Stars: ✭ 118 (-18.06%)
Mutual labels: scrapy
Pigat
pigat ( Passive Intelligence Gathering Aggregation Tool ) 被动信息收集聚合工具
Stars: ✭ 140 (-2.78%)
Mutual labels: scrapy
Python Tutorial
🏃 Some of the python tutorial - 《Python学习笔记》
Stars: ✭ 122 (-15.28%)
Mutual labels: scrapy
基于Scrapy框架的Python3就业信息Jobspiders爬虫
- Items.py : 定义爬取的数据
- pipelines.py : 管道文件,异步存储爬取的数据
- spiders文件夹 : 爬虫程序
- settings.py : Srapy设定,请参考 官方文档
- scrapy spider
- 爬取三大知名网站,使用三种技术手段
- 第一种直接从网页中获取数据,采用的是scrapy的基础爬虫模块,爬的是51job
- 第二种采用扒接口,从接口中获取数据,爬的是智联招聘
- 第三种采用的是整站的爬取,爬的是拉钩网
- 获取想要的数据并将数据存入mysql数据库中,方便以后的就业趋势分析
实现功能:
- 从三大知名网站上爬取就业信息,爬取发布工作的日期,薪资,城市,岗位有那些福利,要求,分类等等,并将爬到的数据存到mysql数据库中
使用教程:
运行前需要安装的环境
-
Python3 Ubantu16.04自带,
sudo apt-get install python3.5 -
mysql :
sudo apt-get install mysql-server -
安装虚拟环境和虚拟环境的wrapper
sudo apt-get install python-pip python-dev build-essential sudo pip install --upgrade pip sudo pip install --upgrade virtualenv sudo pip install virtualenvwrapper-
配置virtualenvwrapper的工作空间
cd ~mkdir .virtualenvssudo find / -name virtualenvwrapper.sh-
vim ~/.zshrc注意vim自己当前所用的shell,$SHELL查看,用的是bash就vim ~/.bashrc,末行加上
export WORKON_HOME=$HOME/.virtualenvs source /usr/local/bin/virtualenvwrapper.sh注意替换自己find到的virtualenvwrapper.sh位置
-
-
其次就是安装一些模块,提供三种
- 最简单的方法 pip install -r requirements.txt

- 第2种方式如果安装了virtualenv和virtualenvwrapper就直接运行以下命令安装
mkvirtualenv --python=/usr/bin/python3 py3scrapy workon py3scrapy 安装好scrapy框架: pip install scrapy - 安装时遇到一个错误twisted/test/raiser.c:4:20: fatal error: Python.h: No such file or directory,解决办法:先安装 **python-dev,python3-dev**,再安装 - 可以使用豆瓣源加速安装 pip install -i https://pypi.douban.com/simple scrapy pip install fake-useragent sudo apt-get install libmysqlclient-dev pip install mysqlclient -i https://pypi.douban.com/simple 其余的在pycharm中alt enter安装- 如果没有安装虚拟环境可以在pycharm中进行安装,alt+enter选择,如果没有正确的模块,就在setting中的project中的解释器Interpreter,再点击+号在里面搜索
- 2019-3-10更新 发现一个问题环境问题,就是现在的Scrapy版本最新的1.6的,但是一点六的移除了一些组件导致安装的时候会报一个 "ImportError: No module named 'scrapy.contrib' ",所以自己去github上搜索scrapy通过源码编译安装1.5.1
- 最简单的方法 pip install -r requirements.txt
运行项目
- git clone https://github.com/wqh0109663/JobSpiders.git
- 把下好的项目在pycharm中打开
- 新建一个数据库叫jobspider,编码用utf-8 ,运行jobspider.sql文件
- create database jobspider charset utf8;
- use jobspider;
- source sql路径;
- 运行main文件,打开注释内容,运行需要的spider即可,运行拉勾网的时候要改动谷歌浏览器的驱动chromedriver位置
- 或者直接在命令行中运行scrapy runspider XX某某spider
- 使用拉钩网模块的时候注意改成自己的拉钩网账号(我的已经改密码了,老是提示我的异地登陆),还有就是更改chromedriver的位置
下面是一条爬到的数据

下面是博客地址
- 里面包含一些简要的说明
- 博客戳这里
数据分析
爬虫只是为了获得数据,重要的还是如何做数据分析
生成词云
- 连接数据库,取出其中的10000条数据,使用结巴分词,将中文进行拆分,手动去掉没有意义的词
连接数据库,取出其中的10000条数据,使用pkuseg-python分词(最近才出的新的分词),将中文进行拆分,手动去掉没有意义的词,分词准确率提高了但是貌似性能不高,慢的要死- 效果图,待完善





















TODO
2019-3-11更新
发现一个问题:就是使用驱动获取cookie,与使用浏览器自己打开,所弹出的登录页面有所不同,手动打开的网页中没有图片验证码,而使用驱动(无论是谷歌浏览器驱动还是火狐的浏览器驱动均没有用,亲测),根据相关文档查看到根据驱动是可以获取到指纹特征,所以拉钩也可能在这方面做过手脚,也看到使用驱动下面的一行代码会为true,‘window.navigator.webdriver’,所以应该还是挺多的方法可以检测是不是机器人在操作。
2019-3-14更新
拉钩网两处需要验证码的地方
-
登录(Fixed)

-
302重定向(Fixed)
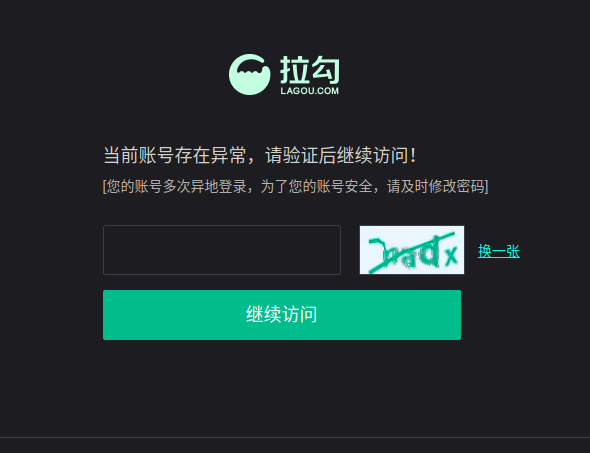
拉钩网验证

引进图片识别
2019-3-23更新
修改spider下的lagou.py,修改为自己的若快账号和拉钩账号
项目已不再更新,想要拉钩网数据参考testlagou.py
动态更新cookie值就可以了,全站难度有点大,直接请求接口比较简单
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].