Passenger Screening Challenge Solution
tldr: The model is defined in mvcnn.py.
Slides: https://docs.google.com/presentation/d/1TeUD7tV-E87hngcgv7rmmHRDJN8M3HCIwlIw_beWsis/edit?usp=sharing
This repository contains my solution to the $1.5 million Passenger Screening Challenge on Kaggle sponsored by the Department of Homeland Security.
It won 10th place (originally 9th place) with no ensembling, segmentation, or other bells and whistles. All training and testing was done on a single GTX 1080 ti and the model gives top-10 results in less than a day of training.
My philosophy is to keep things simple and fast and to avoid overengineering.
Description from the competition page (https://www.kaggle.com/c/passenger-screening-algorithm-challenge):
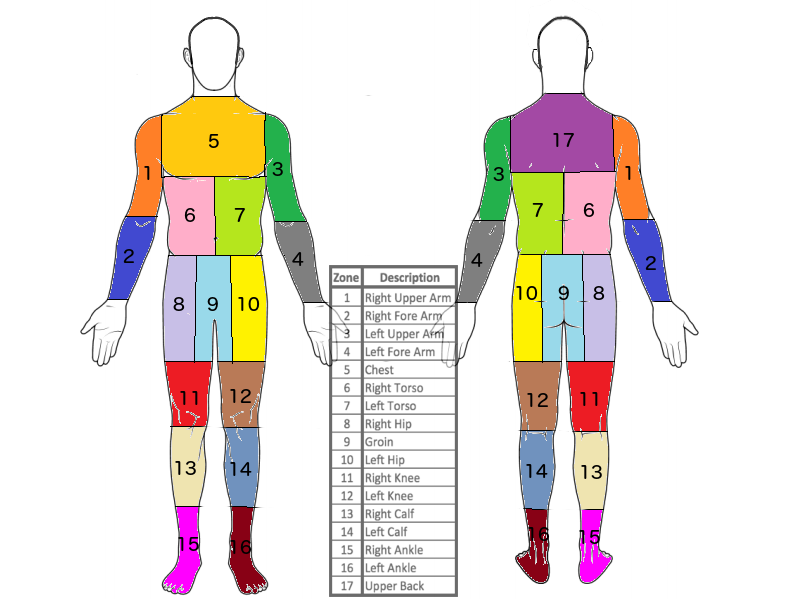
This dataset contains a large number of body scans acquired by a new generation of millimeter wave scanner called the High Definition-Advanced Imaging Technology (HD-AIT) system. The competition task is to predict the probability that a given body zone (out of 17 total body zones) has a threat present.
The images in the dataset are designed to capture real scanning conditions. They are comprised of volunteers wearing different clothing types (from light summer clothes to heavy winter clothes), different body mass indices, different genders, different numbers of threats, and different types of threats. Due to restrictions on revealing the types of threats for which the TSA screens, the threats in the competition images are "inert" objects with varying material properties. These materials were carefully chosen to simulate real threats.
The volunteers used in the first and second stage of the competition will be different (i.e. your algorithm should generalize to unseen people). In addition, you should not make assumptions about the number, distribution, or location of threats in the second stage.
We are provided with .aps files from a millimeter wave scanner. Each file contains 16 different images depicting 16 different views of a subject. We are also provided with full 3D scans of the subject but they are not used in this solution.
For the targets we are provided 17 yes/no binary values for each file indicating whether a threat is present in each region.
Each view is fed to a pretrained ResNet-50 CNN. A form of attention is applied to the final feature maps. The feature maps are then pyramid pooled with CNN layers of differing strides and kernel sizes and also a regular average pooling layer. These outputs are then fed to a LSTM layer with attention applied. After each of the 16 views is processed, the result of the LSTM is fed through a final fully connected layer which outputs a probability for each of the 17 threat zones.
The model performs no segmentation and uses no data other than what's provided by Kaggle and the DHS (the dataset does not provide pixel-level information about where the object is located, only a yes/no binary value of whether a threat is present in a zone). The model learns without human intervention which threat zones correspond to which labels.
My setup / requirements:
- Ubuntu 16.04
- Python 3
- 32 GB system RAM, GTX 1080 ti.
- Anaconda (should install most of the libraries you need).
- Pytorch 0.20
- torchsample (for data augmentations)
Run with
python main.py
It takes roughly 12-16 hours to train on a single GTX 1080 ti. It converges to a very low loss in just hours but I found leaving it running for some time improves test time results.
Training files go in aps/
Test files to make predictions on go in test/
Predictions will be generated in predictions/
All training / testing data had to be deleted after the competition due to NDA.
This is a remake of the body zones reference file (thanks to Shiv Gowda).