breandan / Kotlingrad
Projects that are alternatives of or similar to Kotlingrad
Kotlin∇: Type-safe Symbolic Differentiation for Kotlin
![]()

![]()
![]()
Kotlin∇ is a type-safe automatic differentiation framework in Kotlin. It allows users to express differentiable programs with higher-dimensional data structures and operators. We attempt to restrict syntactically valid constructions to those which are algebraically valid and can be checked at compile-time. By enforcing these constraints in the type system, it eliminates certain classes of runtime errors that may occur during the execution of a differentiable program. Due to type-inference, most type declarations may be safely omitted by the end-user. Kotlin∇ strives to be expressive, safe, and notationally similar to mathematics. It is currently pre-release and offers no stability guarantees at this time.
Table of contents
- Introduction
- Supported features
- Usage
- Visualization
- Testing and gradient checking
- How does it work?
- Formal grammar
- UML diagram
- Comparison to other frameworks
- Citation
- References
- Acknowledgements
Introduction
Inspired by Stalin∇, Autograd, DiffSharp, Myia, Nexus, Tangent, Lantern et al., Kotlin∇ attempts to port recent advancements in automatic differentiation (AD) to the Kotlin language. AD is useful for gradient descent and has a variety of applications in numerical optimization and machine learning. Our implementation adds a number of experimental ideas, including compile-time shape-safety, algebraic simplification and numerical stability checking with property-based testing. We aim to provide an algebraically-grounded implementation of AD for shape-safe tensor operations. Tensors in Kotlin∇ are represented as multidimensional arrays.
Features
Kotlin∇ currently supports the following features:
- Arithmetical operations on scalars, vectors and matrices
- Shape-safe vector and matrix algebra
- Partial and higher-order differentiation on scalars
- Property-based testing for numerical gradient checking
- Recovery of symbolic derivatives from AD
Additionally, it aims to support:
- PyTorch-style define-by-run semantics
- N-dimensional tensors and higher-order tensor operators
- Fully-general AD over control flow, variable reassignment (via delegation), and array programming, possibly using a typed IR such as Myia
All of these features are implemented without access to bytecode or special compiler tricks - just using higher-order functions and lambdas as shown in Lambda the Ultimate Backpropogator, embedded DSLs a la Lightweight Modular Staging, and ordinary generics. Please see below for a more detailed feature comparison.
Usage
Installation
Kotlin∇ is hosted on JitPack.
Gradle
repositories {
maven("https://jitpack.io")
}
dependencies {
implementation("com.github.breandan:kotlingrad:0.4.2")
}
Maven
<project>
<repositories>
<repository>
<id>jitpack.io</id>
<url>https://jitpack.io</url>
</repository>
</repositories>
<dependency>
<groupId>com.github.breandan</groupId>
<artifactId>kotlingrad</artifactId>
<version>0.4.2</version>
</dependency>
</project>
Jupyter Notebook
To access Kotlin∇'s notebook support, use the following line magic:
@file:Repository("https://jitpack.io")
@file:DependsOn("com.github.breandan:kotlingrad:0.4.2")
For more information, explore the tutorial.
Notation
Kotlin∇ operators are higher-order functions, which take at most two inputs and return a single output, all of which are functions with the same numerical type, and whose shape is denoted using superscript in the rightmost column below.
| Math | Infix † | Prefix | Postfix‡ | Operator Type Signature |
|---|---|---|---|---|
|
|
a(b)a of b
|
(a: ℝτ→ℝπ, b: ℝλ → ℝτ) → (ℝλ→ℝπ) |
||
a + ba - b
|
plus(a, b)minus(a, b)
|
(a: ℝτ→ℝπ, b: ℝλ → ℝπ) → (ℝ?→ℝπ) |
||
a * ba.times(b)
|
times(a, b) |
(a: ℝτ→ℝm×n, b: ℝλ→ℝn×p) → (ℝ?→ℝm×p) |
||
|
|
a / ba.div(b)
|
div(a, b) |
(a: ℝτ→ℝm×n, b: ℝλ→ℝp×n) → (ℝ?→ℝm×p) |
|
-a+a
|
a.unaryMinus()a.unaryPlus()
|
(a: ℝτ→ℝπ) → (ℝτ→ℝπ) |
||
|
|
sin(a)cos(a)tan(a)
|
a.sin()a.cos()a.tan()
|
(a: ℝ→ℝ) → (ℝ→ℝ) |
|
ln(a)log(a)
|
a.ln()a.log()
|
(a: ℝτ→ℝm×m) → (ℝτ→ℝm×m) |
||
a.log(b) |
log(a, b) |
(a: ℝτ→ℝm×m, b: ℝλ→ℝm×m) → (ℝ?→ℝ) |
||
a.pow(b) |
pow(a, b) |
(a: ℝτ→ℝm×m, b: ℝλ→ℝ) → (ℝ?→ℝm×m) |
||
|
|
a.pow(1.0/2)a.root(3)
|
sqrt(a)cbrt(a)
|
a.sqrt()a.cbrt()
|
(a: ℝτ→ℝm×m) → (ℝτ→ℝm×m) |
|
|
a.d(b)d(a) / d(b)
|
grad(a)[b] |
(a: C(ℝτ→ℝ)*, b: C(ℝλ→ℝ)) → (ℝ?→ℝ) |
|
grad(a) |
a.grad() |
(a: C(ℝτ→ℝ)) → (ℝτ→ℝτ) |
||
a.d(b)a.grad(b)
|
grad(a, b)grad(a)[b]
|
(a: C(ℝτ→ℝπ), b: C(ℝλ→ℝω)) → (ℝ?→ℝπ×ω) |
||
divg(a) |
a.divg() |
(a: C(ℝτ→ℝm)) → (ℝτ→ℝ) |
||
curl(a) |
a.curl() |
(a: C(ℝ3→ℝ3)) → (ℝ3→ℝ3) |
||
grad(a) |
a.grad() |
(a: C(ℝτ→ℝm)) → (ℝτ→ℝm×τ) |
||
hess(a) |
a.hess() |
(a: C(ℝτ→ℝ)) → (ℝτ→ℝτ×τ) |
||
lapl(a) |
a.lapl() |
(a: C(ℝτ→ℝ)) → (ℝτ→ℝτ) |
ℝ can be a Double, Float or BigDecimal. Specialized operators are defined for subsets of ℝ, e.g. Int, Short or BigInteger for subsets of ℤ, however differentiation is only defined for continuously differentiable functions on ℝ.
† a and b are higher-order functions. These may be constants (e.g. 0, 1.0), variables (e.g. Var()) or expressions (e.g. x + 1, 2 * x + y).
‡ For infix notation, . is optional. Parentheses are also optional depending on precedence.
§ Matrix division is defined iff B is invertible, although it could be possible to redefine this operator using the Moore-Penrose inverse.
∗ Where C(ℝm) is the space of all continuous functions over ℝ. If the function is not over ℝ, it will fail at compile-time. If the function is over ℝ but not continuous differentiable at the point under consideration, it will fail at runtime.
? The input shape is tracked at runtime, but not at the type level. While it would be nice to infer a union type bound over the inputs of binary functions, it is likely impossible using the Kotlin type system without great effort. If the user desires type checking when invoking higher order functions with literal values, they will need to specify the combined input type explicitly or do so at runtime.
τ, λ, π, ω Arbitrary products.
Higher-Rank Derivatives
Kotlin∇ supports derivatives between tensors of up to rank 2. The shape of a tensor derivative depends on (1) the shape of the function under differentiation and (2) the shape of the variable with respect to which we are differentiating.
| I/O Shape | ℝ?→ℝ | ℝ?→ℝm | ℝ?→ℝj×k |
|---|---|---|---|
| ℝ?→ℝ | ℝ?→ℝ | ℝ?→ℝm | ℝ?→ℝj×k |
| ℝ?→ℝn | ℝ?→ℝn | ℝ?→ℝm×n | ❌ |
| ℝ?→ℝh×i | ℝ?→ℝh×i | ❌ | ❌ |
Matrix-by-vector, vector-by-matrix, and matrix-by-matrix derivatives require rank 3+ tensors and are currently unsupported.
Higher-Order Derivatives
Kotlin∇ supports arbitrary order derivatives on scalar functions, and up to 2nd order derivatives on vector functions. Higher-order derivatives on matrix functions are unsupported.
Shape Safety
Shape safety is an important concept in Kotlin∇. There are three broad strategies for handling shape errors:
- Hide the error somehow by implicitly reshaping or broadcasting arrays
- Announce the error at runtime, with a relevant message, e.g.
InvalidArgumentError - Do not allow programs which can result in a shape error to compile
In Kotlin∇, we use the last strategy to check the shape of tensor operations. Consider the following program:
// Inferred type: Vec<Double, D2>
val a = Vec(1.0, 2.0)
// Inferred type: Vec<Double, D3>
val b = Vec(1.0, 2.0, 3.0)
val c = b + b
// Does not compile, shape mismatch
// a + b
Attempting to sum two vectors whose shapes do not match will fail to compile, and they must be explicitly resized.
// Inferred type: Mat<Double, D1, D4>
val a = Mat1x4(1.0, 2.0, 3.0, 4.0)
// Inferred type: Mat<Double, D4, D1>
val b = Mat4x1(1.0, 2.0, 3.0, 4.0)
val c = a * b
// Does not compile, inner dimension mismatch
// a * a
// b * b
Similarly, attempting to multiply two matrices whose inner dimensions do not match will fail to compile.
val a = Mat2x4(
1.0, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0
)
val b = Mat4x2(
1.0, 2.0,
3.0, 4.0,
5.0, 6.0,
7.0, 8.0
)
// Types are optional, but encouraged
val c: Mat<Double, D2, D2> = a * b
val d = Mat2x1(1.0, 2.0)
val e = c * d
val f = Mat3x1(1.0, 2.0, 3.0)
// Does not compile, inner dimension mismatch
// e * f
Explicit types are optional but encouraged. Type inference helps preserve shape information over long programs.
fun someMatFun(m: Mat<Double, D3, D1>): Mat<Double, D3, D3> = ...
fun someMatFun(m: Mat<Double, D2, D2>) = ...
When writing a function, it is mandatory to declare the input type(s), but the return type may be omitted. Shape-safety is currently supported up to rank-2 tensors, i.e. matrices.
Variable Capture
Kotlin∇ provides a DSL for type-safe variable capture with variadic currying. Consider the following example:
val q = X + Y * Z + Y + 0.0
val p0 = q(X to 1.0, Y to 2.0, Z to 3.0) // Name resolution
val p1 = q(X to 1.0, Y to 1.0)(Z to 1.0) // Variadic currying
val p3 = q(Z to 1.0)(X to 1.0, Y to 1.0) // Any order is possible
val p4 = q(Z to 1.0)(X to 1.0)(Y to 1.0) // Proper currying
val p5 = q(Z to 1.0)(X to 1.0) // Returns a partially applied function
val p6 = (X + Z + 0)(Y to 1.0) // Does not compile
For further details, please refer to the implementation.
Example
The following example shows how to derive higher-order partials of a function z of type ℝ²→ℝ:
val z = x * (-sin(x * y) + y) * 4 // Infix notation
val `∂z∕∂x` = d(z) / d(x) // Leibniz notation [Christianson, 2012]
val `∂z∕∂y` = d(z) / d(y) // Partial derivatives
val `∂²z∕∂x²` = d(`∂z∕∂x`) / d(x) // Higher-order derivatives
val `∂²z∕∂x∂y` = d(`∂z∕∂x`) / d(y) // Higher-order partials
val `∇z` = z.grad() // Gradient operator
val values = arrayOf(x to 0, y to 1)
println("z(x, y) \t= $z\n" +
"z(${values.map { it.second }.joinToString()}) \t\t= ${z(*values)}\n" +
"∂z/∂x \t\t= $`∂z∕∂x` \n\t\t= " + `∂z∕∂x`(*values) + "\n" +
"∂z/∂y \t\t= $`∂z∕∂y` \n\t\t= " + `∂z∕∂y`(*values) + "\n" +
"∂²z/∂x² \t= $`∂z∕∂y` \n\t\t= " + `∂²z∕∂x²`(*values) + "\n" +
"∂²z/∂x∂y \t= $`∂²z∕∂x∂y` \n\t\t= " + `∂²z∕∂x∂y`(*values) + "\n" +
"∇z \t\t= $`∇z` \n\t\t= [${`∇z`[x]!!(*values)}, ${`∇z`[y]!!(*values)}]ᵀ")
Any backticks and unicode characters above are simply for readability and have no effect on the behavior. Running this program via ./gradlew HelloKotlingrad should produce the following output:
z(x, y) = ((x) * ((- (sin((x) * (y)))) + (y))) * (4.0)
z(0, 1) = 0.0
∂z/∂x = d(((x) * ((- (sin((x) * (y)))) + (y))) * (4.0)) / d(x)
= 4.0
∂z/∂y = d(((x) * ((- (sin((x) * (y)))) + (y))) * (4.0)) / d(y)
= 0.0
∂²z/∂x² = d(((x) * ((- (sin((x) * (y)))) + (y))) * (4.0)) / d(y)
= 4.0
∂²z/∂x∂y = d(d(((x) * ((- (sin((x) * (y)))) + (y))) * (4.0)) / d(x)) / d(y)
= 4.0
∇z = {y=d(((x) * ((- (sin((x) * (y)))) + (y))) * (4.0)) / d(y), x=d(((x) * ((- (sin((x) * (y)))) + (y))) * (4.0)) / d(x)}
= [4.0, 0.0]ᵀ
Visualization tools
Kotlin∇ provides various graphical tools that can be used for visual debugging.
Dataflow graphs
Kotlin∇ functions are a type of directed acyclic graph, called dataflow graphs (DFGs). For example, running the expression ((1 + x * 2 - 3 + y + z / y).d(y).d(x) + z / y * 3 - 2).render() will display the following DFG:

Red and blue edges indicate the right and left inputs to a binary operator, respectively. Consider the DFG for a batch of stochastic gradients on linear regression, which can be written in matrix form as :

Thetas represent the hidden parameters under differentiation and the constants are the batch inputs (X) and targets (Y). When all the free variables are bound to numerical values, the graph collapses into a single node, which can be unwrapped into a Kotlin Number.
Plotting
To generate the sample 2D plots below, run ./gradlew Plot2D.


Plotting is also possible in higher dimensions, for example in 3D via ./gradlew Plot3D:




Loss curves
Gradient descent is one application for Kotlin∇. Below, is a typical loss curve of SGD on a multilayer perceptron:

To train the model, execute ./gradlew MLP from within the parent directory.
Testing
To run the tests, execute: ./gradlew test
Kotlin∇ claims to eliminate certain runtime errors, but how do we know the proposed implementation is not incorrect? One method, borrowed from the Haskell community, is called property-based testing (PBT), closely related to metamorphic testing. Notable implementations include QuickCheck, Hypothesis and ScalaTest (ported to Kotlin in KotlinTest). PBT uses algebraic properties to verify the result of an operation by constructing semantically equivalent but syntactically distinct expressions, which should produce the same answer. Kotlin∇ uses two such equivalences to validate its AD implementation:
- Analytic differentiation: manually differentiate and compare the values returned on a subset of the domain with AD.
- Finite difference approximation: sample space of symbolic (differentiable) functions, comparing results of AD to FD.
For example, consider the following test, which checks whether the analytical derivative and the automatic derivative, when evaluated at a given point, are equal to each other within the limits of numerical precision:
val x by Var()
val y by Var()
val z = y * (sin(x * y) - x) // Function under test
val `∂z∕∂x` = d(z) / d(x) // Automatic derivative
val manualDx = y * (cos(x * y) * y - 1) // Analytical derivative
"∂z/∂x should be y * (cos(x * y) * y - 1)" {
NumericalGenerator.assertAll { ẋ, ẏ ->
// Evaluate the results at a given seed
val autoEval = `∂z∕∂x`(x to ẋ, y to ẏ)
val manualEval = manualDx(x to ẋ, y to ẏ)
// Should pass iff Δ(adEval, manualEval) < Ɛ
autoEval shouldBeApproximately manualEval
}
}
PBT will search the input space for two numerical values ẋ and ẏ, which violate the specification, then "shrink" them to discover pass-fail boundary values. We can construct a similar test using finite differences:
"d(sin x)/dx should be equal to (sin(x + dx) - sin(x)) / dx" {
NumericalGenerator.assertAll { ẋ ->
val f = sin(x)
val `df∕dx` = d(f) / d(x)
val adEval = `df∕dx`(ẋ)
val dx = 1E-8
// Since ẋ is a raw numeric type, sin => kotlin.math.sin
val fdEval = (sin(ẋ + dx) - sin(ẋ)) / dx
adEval shouldBeApproximately fdEval
}
}

Above, we compare numerical errors for three types of computational differentiation against infinite precision symbolic differentiation (IP):
- Finite precision automatic differentiation (AD)
- Finite precision symbolic differentiation (SD)
- Finite precision finite differences (FD)
AD and SD both exhibit relative errors (i.e. with respect to each other) several orders of magnitude lower than their absolute errors (i.e. with respect to IP), which roughly agree to within numerical precision. As expected, FD exhibits numerical error significantly higher than AD and SD due to the inaccuracy of floating-point division.
There are many other ways to independently verify the numerical gradient, such as dual numbers or the complex step derivative. Another method is to compare the numerical output against a well-known implementation, such as TensorFlow. We plan to conduct a more thorough comparison of numerical accuracy and performance.
How?
To understand the core of Kotlin∇'s AD implementation, please refer to the scalar example.
This project relies on a few Kotlin-specific language features, which together enable a concise, flexible and type-safe user interface. The following features have proven beneficial to the development of Kotlin∇:
Operator overloading
Operator overloading enables concise notation for arithmetic on abstract types, where the types encode algebraic structures, e.g. Group, Ring, and Field. These abstractions are extensible to other kinds of mathematical structures, such as complex numbers and quaternions.
For example, suppose we have an interface Group, which overloads the operators + and *, and is defined like so:
interface Group<T: Group<T>> {
operator fun plus(addend: T): T
operator fun times(multiplicand: T): T
}
Here, we specify a recursive type bound using a method known as F-bounded quantification to ensure that operations return the concrete type variable T, rather than something more abstract like Group. Imagine a class Fun which has implemented Group. It can be used as follows:
fun <T: Group<T>> cubed(t: T): T = t * t * t
fun <T: Group<T>> twiceCubed(t: T): T = cubed(t) + cubed(t)
Like Python, Kotlin supports overloading a limited set of operators, which are evaluated using a fixed precedence. In the current version of Kotlin∇, operators do not perform any computation, they simply construct a directed acyclic graph representing the symbolic expression. Expressions are only evaluated when invoked as a function.
First-class functions
With higher-order functions and lambdas, Kotlin treats functions as first-class citizens. This allows us to represent mathematical functions and programming functions with the same underlying abstractions (typed FP). A number of recent papers have demonstrated the expressiveness of this paradigm for automatic differentiation.
In Kotlin∇, all expressions can be treated as functions. For example:
fun <T: Group<T>> makePoly(x: Var<T>, y: Var<T>) = x * y + y * y + x * x
val x by Var()
val y by Var()
val f = makePoly(x, y)
val z = f(1.0, 2.0) // Returns a value
println(z) // Prints: 7
Additionally, it is possible to build functions consisting of varying dimensional inputs:
fun <T: Fun<T>> mlp(p1: VFun<T, D3>, p2: MFun<T, D3, D3>, p3: T) =
((p1 * p2 + p1 * p2 * p2 dot p1 + p1) - p3) pow p3
Multi-stage programming
Kotlin∇ uses operator overloading in the host language to first construct a dataflow graph, but evaluates the graph lazily. Called "multi-stage programming", or staging, this is a metaprogramming technique from the ML community which enables type-safe runtime code translation and compilation. More recently, staging has been put to effective use for compiling embedded DSLs similar to Kotlin∇.
In its current form, Kotlin∇ takes a "shallow embedding" approach. Similar to an interpreter, it adheres closely to the user-defined program and does not perform much code specialization or rewriting for optimization purposes. Unlike an interpreter, it postpones evaluation until all free variables in an expression have been bound. Consider the following snippet, which decides when to evaluate an expression:
var EAGER = false
operator fun invoke(newBindings: Bindings<X>): Fun<X> =
Composition(this, newBindings).run { if (bindings.complete || EAGER) evaluate() else this }
If bindings are complete, this means there are no unbound variables remaining (implementation omitted for brevity), and we can evaluate the expression to obtain a numerical result. Suppose we have the following user code:
val x = Var()
val y = Var()
val z = Var()
val f0 = x + y * z
var f1 = f0(x to 1).also { println(it) } // Prints: (x + y * z)(x=1)
var f2 = f1(y to 2).also { println(it) } // Prints: (x + y * z)(x=1)(y=2)
var f3 = f2(z to 3).also { println(it) } // Prints: 7
Once the last line is reached, all variables are bound, and instead of returning a Composition, Kotlin∇ evaluates the function, returning a constant. Alternatively, if EAGER mode is enabled, each invocation is applied as early as possible:
EAGER = true
f1 = f0(x to 1).also { println(it) } // Prints: 1 + y * z
f2 = f1(y to 2).also { println(it) } // Prints: 1 + 2 * z
f3 = f2(z to 3).also { println(it) } // Prints: 7
In the following section, we describe how evaluation works.
Algebraic data types
Algebraic data types (ADTs) in the form of sealed classes (a.k.a. sum types) facilitate a limited form of pattern matching over a closed set of subclasses. By using these, the compiler forces us to provide an exhaustive control flow when type checking a sealed class. Consider the following classes:
class Const<T: Fun<T>>(val number: Number) : Fun<T>()
class Sum<T: Fun<T>>(val left: Fun<T>, val right: Fun<T>) : Fun<T>()
class Prod<T: Fun<T>>(val left: Fun<T>, val right: Fun<T>) : Fun<T>()
class Var<T: Fun<T>>: Fun<T>() { override val variables: Set<Var<X>> = setOf(this) }
class Zero<T: Fun<T>>: Const<T>(0.0)
class One<T: Fun<T>>: Const<T>(1.0)
When checking the type of a sealed class, consumers must explicitly handle every case, since incomplete control flow will not compile rather than fail silently at runtime. Let us now consider a simplified definition of the superclass Fun, which defines the behavior invocation and differentiation, using a restricted form of pattern matching:
sealed class Fun<X: Fun<X>>(open val variables: Set<Var<X>> = emptySet()): Group<Fun<X>> {
constructor(vararg fns: Fun<X>): this(fns.flatMap { it.variables }.toSet())
// Since the subclasses of Fun are a closed set, no `else ...` is required.
operator fun invoke(map: Bindings<X>): Fun<X> = when (this) {
is Const -> this
is Var -> map.getOrElse(this) { this } // Partial application is permitted
is Prod -> left(map) * right(map) // Smart casting implicitly casts after checking
is Sum -> left(map) + right(map)
}
fun d(variable: Var<X>): Fun<X> = when(this) {
is Const -> Zero
is Var -> if (variable == this) One else Zero
// Product rule: d(u*v)/dx = du/dx * v + u * dv/dx
is Prod -> left.d(variable) * right + left * right.d(variable)
is Sum -> left.d(variable) + right.d(variable)
}
operator fun plus(addend: Fun<T>) = Sum(this, addend)
operator fun times(multiplicand: Fun<T>) = Prod(this, multiplicand)
}
Symbolic differentiation as implemented by Kotlin∇ has two distinct passes, one for differentiation and one for evaluation. Differentiation constitutes a top-down substitution process on the computation graph and evaluation propagates the values from the bottom, up.
Kotlin∇ functions are not only data structures, but Kotlin functions which can be invoked by passing a Bindings instance (effectively, a Map<Fun<X>, Fun<X>>). To enable this functionality, we overload the invoke operator, then recurse over the graph, using Bindings as a lookup table. If a matching subexpression is found, we propagate the bound value instead of the matching function. This is known as the interpreter pattern.
Kotlin's smart casting is an example of flow-sensitive type analysis where the abstract type Fun can be treated as Sum after performing an is Sum check. Without smart casting, we would need to write (this as Sum).left to access the member, left, causing a potential ClassCastException if the cast were mistaken.
Extension Functions
By using extension functions, users can convert between numerical types in the host language and our eDSL, by augmenting classes with additional operators. Context-oriented programming, allows users to define custom extensions without requiring subclasses or inheritance.
data class Const<T: Group<T>>(val number: Double) : Fun()
data class Sum<T: Group<T>>(val e1: Fun, val e2: Fun) : Fun()
data class Prod<T: Group<T>>(val e1: Fun, val e2: Fun) : Fun()
class Fun<T: Group<T>>: Group<Fun<T>> {
operator fun plus(addend: Fun<T>) = Sum(this, addend)
operator fun times(multiplicand: Fun<T>) = Prod(this, multiplicand)
}
object DoubleContext {
operator fun Number.times(expr: Fun<Double>) = Const(toDouble()) * expr
}
Now, we can use the context to define another extension, Fun.multiplyByTwo, which computes the product inside a DoubleContext, using the operator overload we defined above:
fun Fun<Double>.multiplyByTwo() = with(DoubleContext) { 2 * this } // Uses `*` operator in DoubleContext
Extensions can also be defined in another file or context and imported on demand. For example, Kotlin∇ also uses extensions to define shape-safe constructors and operators for vector and matrix arithmetic.
Multiple Dispatch
In conjunction with ADTs, Kotlin∇ also uses multiple dispatch to instantiate the most specific result type of applying an operator based on the type of its operands. While multiple dispatch is not an explicit language feature, it can be emulated using inheritance.
Building on the previous example, a common task in AD is to simplify a graph. This is useful in order to minimize the total number of calculations required, improving numerical stability. We can eagerly simplify expressions based on algebraic rules of replacement. Smart casting allows us to access members of a class after checking its type, without explicitly casting it:
override fun times(multiplicand: Function<X>): Function<X> = when {
this == zero -> this
this == one -> multiplicand
multiplicand == one -> this
multiplicand == zero -> multiplicand
this == multiplicand -> pow(two)
this is Const && multiplicand is Const -> const(value * multiplicand.value)
// Further simplification is possible using rules of replacement
else -> Prod(this, multiplicand)
}
val result = Const(2.0) * Sum(Var(2.0), Const(3.0)) // Sum(Prod(Const(2.0), Var(2.0)), Const(6.0))
This allows us to put all related control flow on a single abstract class which is inherited by subclasses, simplifying readability, debugging and refactoring.
Shape-safe Tensor Operations
While first-class dependent types are useful for ensuring arbitrary shape safety (e.g. when concatenating and reshaping matrices), they are unnecessary for simple equality checking (such as when multiplying two matrices). When the shape of a tensor is known at compile-time, it is possible to encode this information using a less powerful type system*, as long as it supports subtyping and parametric polymorphism (a.k.a. generics). In practice, we can implement a shape-checked tensor arithmetic in languages like Java, Kotlin, C++, C# or Typescript, which accept generic type parameters. In Kotlin, whose type system is less expressive than Java, we use the following strategy.
Shape safety is currently supported up to rank-2 tensors, i.e. matrices. To perform dimension checking in our type system, first we enumerate a list of integer type literals as a chain of subtypes, C <: C - 1 <: C - 2 <: ... <: 1 <: 0, where C is the largest fixed-length dimension we wish to represent, which can be specified by the user prior to compilation. This guarantees linear space and time complexity for subtype checking, with a constant upper bound.
@file:Suppress("ClassName")
interface Nat<T: D0> { val i: Int } // Used for certain type bounds
sealed class D0(open val i: Int = 0) { companion object: D0(), Nat<D0> }
sealed class D1(override val i: Int = 1): D0(i) { companion object: D1(), Nat<D1> }
sealed class D2(override val i: Int = 2): D1(i) { companion object: D2(), Nat<D2> }
sealed class D3(override val i: Int = 3): D2(i) { companion object: D3(), Nat<D3> }
//... † Automatically generated
Next, we overload the call operator to emulate instantiating a collection literal, using arity to infer its dimensionality. Consider the rank-1 case for length inference on vector literals:
open class Vec<E, Len: D1>(val contents: List<E>)
fun <T> Vec(t1: T): Vec<T, D1> = Vec(listOf(t1))
fun <T> Vec(t1: T, t2: T): Vec<T, D2> = Vec(listOf(t1, t2))
fun <T> Vec(t1: T, t2: T, t3: T): Vec<T, D3> = Vec(listOf(t1, t2, t3))
//... † Automatically generated
Finally, we encode length as a parameter of the operand type. Since integer literals are a chain of subtypes, we need only define one operator using the highest literal, and can rely on Liskov substitution to preserve shape safety for all subtypes.
infix operator fun <C: D1, V: Vec<Int, C>> V.plus(v: V): Vec<Int, C> =
Vec(contents.zip(v.contents).map { it.first + it.second })
The operator + can now be used like so. Incompatible operands will cause a type error:
val one = Vec(1, 2, 3) + Vec(1, 2, 3) // Always runs safely
val add = Vec(1, 2, 3) + Vec(listOf(...)) // May fail at runtime
val sum = Vec(1, 2) + add // Does not compile
A similar syntax is available for matrices and higher-rank tensors. For example, Kotlin∇ can infer the shape of multiplying two matrices, and will not compile if their inner dimensions do not match:
open class Mat<X, R: D1, C: D1>(vararg val rows: Vec<X, C>)
fun <X> Mat1x2(d0: X, d1: X): Mat<X, D1, D2> = Mat(Vec(d0, d1))
fun <X> Mat2x1(d0: X, d1: X): Mat<X, D2, D1> = Mat(Vec(d0), Vec(d1))
//... † Automatically generated
operator fun <Q: D1, R: D1, S: D1> Mat<Int, Q, R>.times(m: Mat<Int, R, S>): Mat<Int, Q, S> = TODO()
// Inferred type: Mat<Int, D4, D4>
val l = Mat4x4(
1, 2, 3, 4,
5, 6, 7, 8,
9, 0, 0, 0,
9, 0, 0, 0
)
// Inferred type: Mat<Int, D4, D3>
val m = Mat4x3(
1, 1, 1,
2, 2, 2,
3, 3, 3,
4, 4, 4
)
// Inferred type: Mat<Int, D4, D3>
val lm = l * m
// m * m // Compile error: Expected Mat<3, *>, found Mat<4, 3>
Further examples are provided for shape-safe matrix operations such as addition, subtraction and transposition.
A similar technique is possible in Haskell, which is capable of a more powerful form of type-level computation, type arithmetic. Type arithmetic makes it easy to express convolutional arithmetic and other arithmetic operations on shape variables (say, splitting a vector in half), which is currently not possible, or would require enumerating every possible combination of type literals.
∗ Many type systems are still capable of performing arbitrary computation in the type checker. As specified, Java's type system is known to be Turing Complete. It may be possible to emulate a limited form of dependent types in Java by exploiting this property, although this may not computationally tractable due to the practical limitations noted by Grigore.
† Statically generated code, shipped within the library. To regenerate these methods (e.g. using larger dimensions), a code generator is provided.
Intermediate representation
Kotlin∇ programs are staged into Kaliningraph, an experimental IR for graph computation. As written by the user, many graphs are computationally suboptimal due to expression swell and parameter sharing. To accelerate forward- and backpropagation, it is often advantageous to simplify the graph by applying the reduction semantics in a process known as graph canonicalization. Kaliningraph enables compiler-like optimizations over the graph such as expression simplification and analytic root-finding, and supports features for visualization and debugging, e.g. in computational notebooks.
Property Delegation
Property delegation is a reflection feature in the Kotlin language which lets us access properties to which an instance is bound. For example, we can read the property name like so:
class Var(val name: String?) {
operator fun getValue(thisRef: Any?, property: KProperty<*>) = Var(name ?: property.name)
}
This feature allows consumers to instantiate variables e.g. in an embedded DSL without redeclaring their names:
val x by Var() // With property delegation
val x = Var("x") // Without property delegation
Without property delegation, users would need to repeat the property name in the constructor.
Coroutines
Coroutines are a generalization of subroutines for non-preemptive multitasking, typically implemented using continuations. One form of continuation, known as shift-reset a.k.a. delimited continuations, are sufficient for implementing reverse mode AD with operator overloading alone (without any additional data structures) as described by Wang et al. in Shift/Reset the Penultimate Backpropagator and later in Backpropagation with Continuation Callbacks. While Kotlin callbacks are single-shot by default, delimited continuations and reentrant or "multi-shot" delimited continuations can also be implemented using Kotlin coroutines and would be an interesting extension to this work. Please stay tuned!
Ideal API (WIP)
The current API is stable, but can be improved in many ways. Currently, Kotlin∇ does not infer a function's input dimensionality (i.e. free variables and their corresponding shape). While it is possible to perform variable capture over a small alphabet using type safe currying, this technique incurs a large source code overhead. It may be possible to reduce the footprint using phantom types or some form of union type bound (cf. Kotlin, Java).
When the shape of an N-dimensional array is known at compile-time, we can use type-level integers to ensure shape conforming tensor operations (inspired by Nexus and others).
Allowing users to specify a matrix's structure in its type signature, (e.g. Singular, Symmetric, Orthogonal, Unitary, Hermitian, Toeplitz) would allows us to specialize derivation over such matrices (cf. section 2.8 of The Matrix Cookbook).
Scalar functions
A function's type would ideally encode arity, based on the number of unique variables:
val f = x * y + sin(2 * x + 3 * y) // f: BinaryFunction<Double> "
val g = f(x to -1.0) // g: UnaryFunction<Double> == -y + sin(-2 + 3 * y)
val h = f(x to 0.0, y to 0.0) // h: Const<Double> == 0 + sin(0 + 0) == 0
However inferring arity for arbitrary expressions at compile-time would be difficult in the Kotlin type system. Instead, we could let the user specify it directly.
val x by Var() // x: Variable<Double> inferred type
val y by Var() // x: Variable<Double> "
val f = Fun(D2) { x * y + sin(2 * x + 3 * y) } // f: BinaryFunction<Double> "
val g = f(x to -1.0) // g: UnaryFunction<Double> == -y + sin(-2 + 3 * y)
val h = f(x to 0.0, y to 0.0) // h: Const<Double> == 0 + sin(0 + 0) == 0
Grammar
For a detailed grammar and reduction semantics, please see the specification.
UML Diagram

Comparison
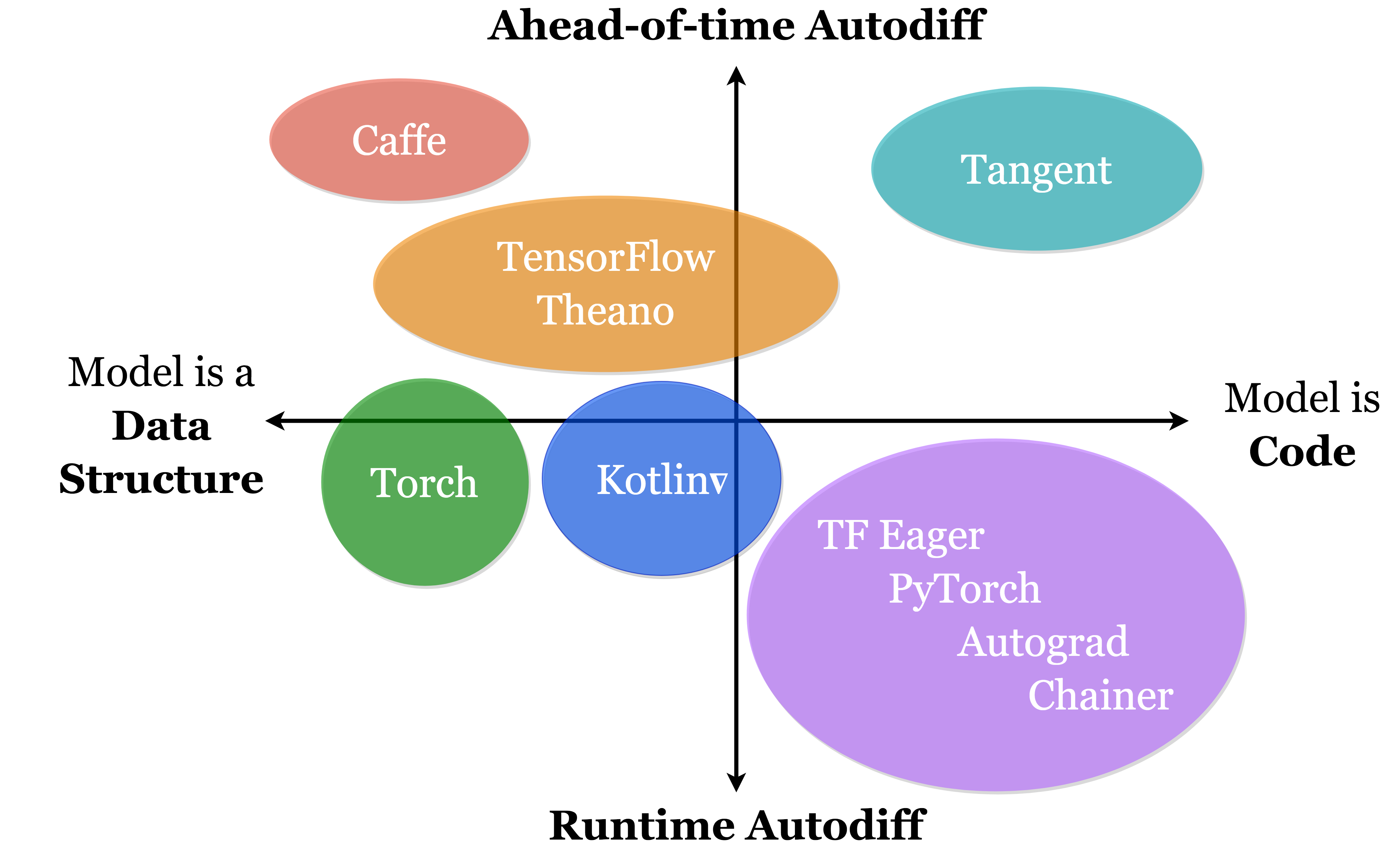
Unlike certain frameworks which simply wrap an existing AD library in a type-safe DSL, Kotlin∇ contains a fully shape-safe implementation of algorithmic differentiation, written in pure Kotlin. By doing so, it can leverage Kotlin language features such as typed functional programming, as well as interoperability with other languages on the JVM platform. Furthermore, it implements symbolic differentiation, which unlike Wengert tape or dual-number based ADs, allows it to calculate derivatives of arbitrarily high order with zero extra engineering required. Further details can be found below.
| Framework | Language | SD¹ | AD² | HD³ | DP⁴ | FP⁵ | TS⁶ | SS⁷ | DT⁸ | MP⁹ |
|---|---|---|---|---|---|---|---|---|---|---|
| Kotlin∇ | Kotlin | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | 🚧 |
| DiffSharp | F# | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| TensorFlow.FSharp | F# | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ❌ |
| Nexus | Scala | ❌ | ✔️ | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ❌ |
| Lantern | Scala | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| Hipparchus | Java | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ |
| JAutoDiff | Java | ✔️ | ✔️ | ❌ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ |
| Eclipse DL4J | Java | ❌ | 🚧 | ❌ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ |
| SICMUtils | Clojure | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ | ❌ |
| Halide | C++ | ❌ | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ❌ | ❌ | ❌ |
| Tensor Safe | Haskell | ❌ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| HaskTorch | Haskell | ❌ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ❌ | ❌ |
| Dex | Haskell | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | 🚧 | ❌ |
| Grenade | Haskell | ❌ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ❌ | ❌ |
| Stalin∇ | Scheme | ❌ | ✔️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ |
| Myia | Python | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ | 🚧 |
| Autograd | Python | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| JAX | Python | ❌ | ✔️ | ❌ | ✔️ | ✔️ | ❌ | ❌ | ❌ | 🚧 |
| Tangent | Python | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Analitik | Analitik | ✔️ | ❌ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ |
¹ Symbolic differentiation*, ² Automatic differentiation*, ³ Higher-order/rank differentiation, ⁴ Differentiable programming*, ⁵ Functional programming, ⁶ Compile-time type safety, ⁷ Compile-time shape safety, ⁸ Dependently Typed, ⁹ Multiplatform
∗ Although we do not distinguish between AD and SD, here we adopt the authors' preferred nomenclature. We do make a distinction between differentiable programming libraries and those which simply construct neural networks. The 🚧 symbol indicates work in progress.
Citation
If you would like to cite Kotlin∇, please use the following bibtex entry:
@software{considine2019kotlingrad,
author = {Considine, Breandan and Famelis, Michalis and Paull, Liam},
title = {Kotlin$\nabla$: A Shape-Safe e{DSL} for Differentiable Programming},
url = {https://github.com/breandan/kotlingrad},
version = {0.4.2},
year = {2019},
}
References
To the author's knowledge, Kotlin∇ is the first AD implementation in native Kotlin. While the particular synthesis of these ideas (i.e. shape-safe, functional AD, using generic types) is unique, it has been influenced by a long list of prior work in AD. Below is a list of projects and publications that helped inspire this work.
Automatic Differentiation
- The Simple Essence of Automatic Differentiation
- Reverse-Mode AD in a Functional Framework: Lambda the Ultimate Backpropagator
- Automatic differentiation in ML: Where we are and where we should be going
- A Leibniz Notation for Automatic Differentiation
- First-Class Automatic Differentiation in Swift: A Manifesto
- The (JAX) Autodiff Cookbook
- Automatic Differentiation in PyTorch
- Automatic Differentiation in Machine Learning: a Survey
- Complexity of Derivatives Generated by Symbolic Differentiation
- Eigen-AD: Algorithmic Differentiation of the Eigen Library
Complexity
- Fast parallel computation of polynomials using few processors, Valiant and Skyum (1983)
- The complexity of partial derivatives, Baur and Strassen (1983)
- Lower Bounds on Arithmetic Circuits via Partial Derivatives
- Learning Restricted Models of Arithmetic Circuits
Differentiable Programming
- Neural Networks, Types, and Functional Programming
- Backpropagation with Continuation Callbacks: Foundations for Efficient and Expressive Differentiable Programming
- Backprop as Functor: A compositional perspective on supervised learning
- Demystifying Differentiable Programming: Shift/Reset the Penultimate Backpropagator
- Efficient Differentiable Programming in a Functional Array-Processing Language
- Operational Calculus for Differentiable Programming
- Differentiable Functional Programming
- Differentiable Programming for Image Processing and Deep Learning in Halide
- Software 2.0
Calculus
- The Matrix Calculus You Need For Deep Learning, Parr and Howard (2018)
- Backpropagation in matrix notation, Mishachev (2017)
- Matrix derivatives, from the Matrix Cookbook
- Div, Grad, Curl and All That, Petersen and Pedersen (2012)
- Matrix Differentiation (and some other stuff), Barnes (2006)
- Symbolic Matrix Derivatives, Dwyer and Macphail (1948)
Computer Algebra
- Towards an API for the real numbers, Boehm (2020)
- miniKanren as a Tool for Symbolic Computation in Python, Willard (2020)
- A Design Proposal for an Object Oriented Algebraic Library, Niculescu (2003)
- On Using Generics for Implementing Algebraic Structures, Niculescu (2011)
- How to turn a scripting language into a domain-specific language for computer algebra, Jolly and Kredel (2008)
- Evaluation of a Java Computer Algebra System, Kredel (2007)
- Typesafe Abstractions for Tensor Operations, Chen (2017)
- Einstein Summation in Numpy, Bilaniuk (2016)
- Issues in Computer Algebra, Nunes-Harwitt
- Term Rewriting and All That, Baader and Nipkow (1998)
- Describing the syntax of programming languages using conjunctive and Boolean grammars, Okhotin (2016)
- Formal languages over GF(2), Okhotin (2019)
Symbolic Mathematics
- KMath - Kotlin mathematics extensions library
- SymJa - Computer algebra language & symbolic math library for Android
- tensor - Linear algebra for tensors with symbolic and numeric scalars
- Hipparchus - An efficient, general-purpose mathematics components library in the Java programming language
- miniKanren - A tool for symbolic computation and logic programming
- SymJava - A Java library for fast symbolic-numeric computation
- JAS - Java Algebra System
- jalgebra - An abstract algebra library for Java
- COJAC - Numerical sniffing tool and Enriching number wrapper for Java
- chebfun - Allows representing functions as Chebyshev polynomials, for easy symbolic differentiation (or integration)
- horeilly1101/deriv - Open source derivative calculator REST API (and Java library)
Neural Networks
- Hacker's Guide to Neural Networks, Karpathy (2014)
- Tricks from Deep Learning, Baydin et al. (2016)
- Practical Dependent Types in Haskell: Type-Safe Neural Networks, Le (2016)
- A guide to convolutional arithmetic for deep learning, Dumoulin and Visin (2018)
Type Systems
- Generalized Algebraic Data Types and Object-Oriented Programming, Kennedy and Russo (2005)
- Java Generics are Turing Complete, Grigore (2016)
- Dimension Types, Kennedy (2004)
- An algebraic view of dimension types, Kennedy (1996)
- Type Inference and Unification
- Constructive mathematics and computer programming, Martin-Lof (1984)
- Programming in Martin-Löf's Type Theory, Nordstrom et al. (1990)
Domain-Specific Languages
- Compiling Embedded Languages, Elliott et al. (2003)
- Implicit Staging of EDSL Expressions: A Bridge between Shallow and Deep Embedding, Scherr and Chiba (2014)
- DSL Implementation Using Staging and Monads Sheard et al. (1999)
- Deeply Reifying Running Code for Constructing a Domain-Specific Language, Chiba et al. (2016)
- Staged Abstract Interpreters, Wei et al. (2019)
- Generating Fluent Embedded Domain-Specific Languages with Subchaining, Nakamaru et al. (2019)
- Generating a Generic Fluent API in Java, Nakamarua and Chiba (2020)
- Fling – A Fluent API Generator, Gil and Roth (2019)
- Scripting an IDE for EDSL awareness, Sergey et al. (2011)
Automated Testing
- DeepTest: Automated Testing of Deep-Neural-Network-driven Autonomous Cars, Tian et al. (2018)
- QuickCheck: A Lightweight Tool for Random Testing of Haskell Programs, Claessen and Hughes (2000)
- Learning to Discover Efficient Mathematical Identities, Zaremba et al. (2014)
AD Libraries
- TensorFlow.FSharp: An eDSL for writing numerical models in F# with support for interactive tensor shape-checking
- Stalin∇, a brutally optimizing compiler for the VLAD language, a pure dialect of Scheme with first-class automatic differentiation operators
- Autograd - Efficiently computes derivatives of NumPy code
- Myia - SCT based AD, adapted from Pearlmutter & Siskind's "Reverse Mode AD in a functional framework"
- JAX - Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more
- Dex - Research language for array processing in the Haskell/ML family
- Nexus - Type-safe tensors, deep learning and probabilistic programming in Scala
- Tangent - "Source-to-Source Debuggable Derivatives in Pure Python"
- Grenade - composable, dependently typed, practical, and fast RNNs in Haskell
- Lantern - a framework in Scala, based on delimited continuations and multi-stage programming
- JAutoDiff - An Automatic Differentiation Library
- DiffSharp, a functional AD library implemented in the F# language
- Analitik - Algebraic language for the description of computing processes using analytical transformations
Special Thanks
The following individuals have helped shape this project through their enthusiasm and thoughtful feedback. Please check out their work.