Machine-learning-toolkits-with-python
Practical machine learning toolkits with Python
Assessing performance of a regression model (MAE vs MSE)
- In general, MSE or RMSE is employed to not only as a loss function of a regression model, but also to assess the performance of such model. Nevertheless, some claim that MSE is not an appropriate measure of average model performance.
- "Our findings indicate that MAE is a more natural measure of average error, and (unlike RMSE) is unambiguous" (Willmott and Matsuura 2005)
- "Instead, a combination of metrics, including but certainly not limited to RMSEs and MAEs, are often required to assess model performance" (Chai and Draxler 2014) -Related papers
- Willmott, C. J., & Matsuura, K. (2005). Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Climate research, 30(1), 79-82.
- Chai, T., & Draxler, R. R. (2014). Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geoscientific Model Development, 7(3), 1247-1250.
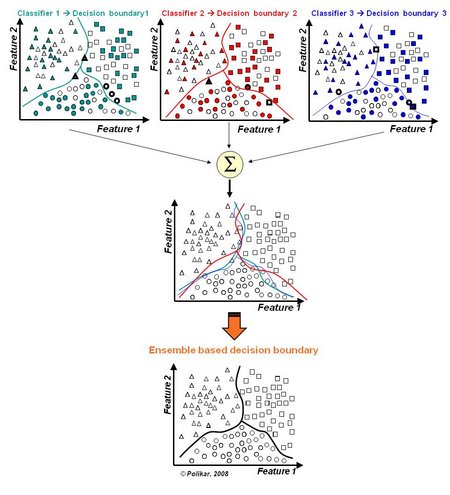
Ensemble methods (Bagging classifiers vs. Voting classifiers)
- Bagging & voting classifiers with Scikit-learn
- "Ensembles are well established as a method for obtaining highly accurate classiers by combining less accurate ones." (Dietterich 2000)
- Related papers
- Dietterich, T. G. (2000). Ensemble methods in machine learning. Multiple classifier systems, 1857, 1-15.
- Breiman, L. (1996). Bagging predictors. Machine learning, 24(2), 123-140.
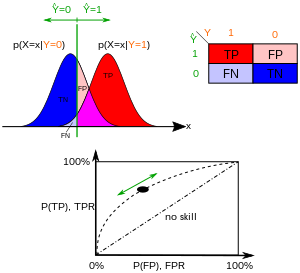
Evaluation metrics for unbalanced data (ROC vs Informedness)
- ROC curve & Bookmakers' informedness/markedness with Scikit-learn
- "ROC graphs are a very useful tool for visualizing and evaluating classifiers. They are able to provide a richer measure of classification performance than scalar measures such as accuracy, error rate or error cost." (Fawcett 2006)
- "Note that while Informedness is a deep measure of how consistently the Predictor predicts the Outcome by combining surface measures about what proportion of Outcomes are correctly predicted, Markedness is a deep measure of how consistently the Outcome has the Predictor as a Marker by combining surface measures about what proportion of Predictions are correct. " (Powers 2011)
- Related papers
- Fawcett, T. (2006). An introduction to ROC analysis. Pattern recognition letters, 27(8), 861-874.
- Powers, D. M. (2011). Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation.
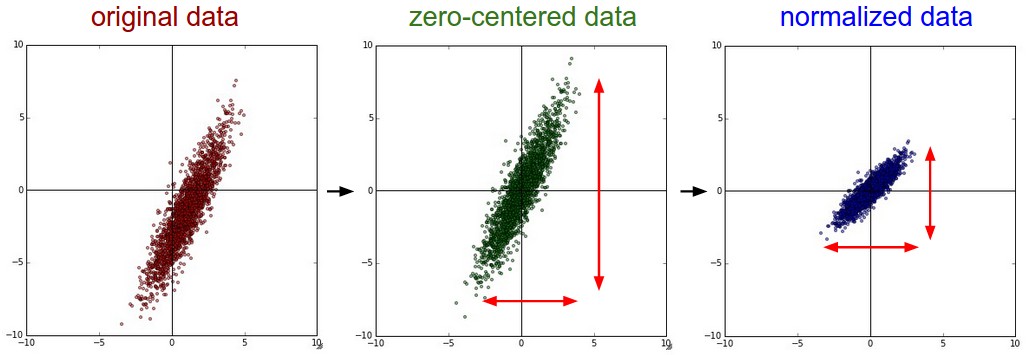
Feature scaling (mean substraction vs normalization)
- Feature scaling with NumPy
- Related material: Lecture note from cs231n (lecture 6 - Training neural networks)
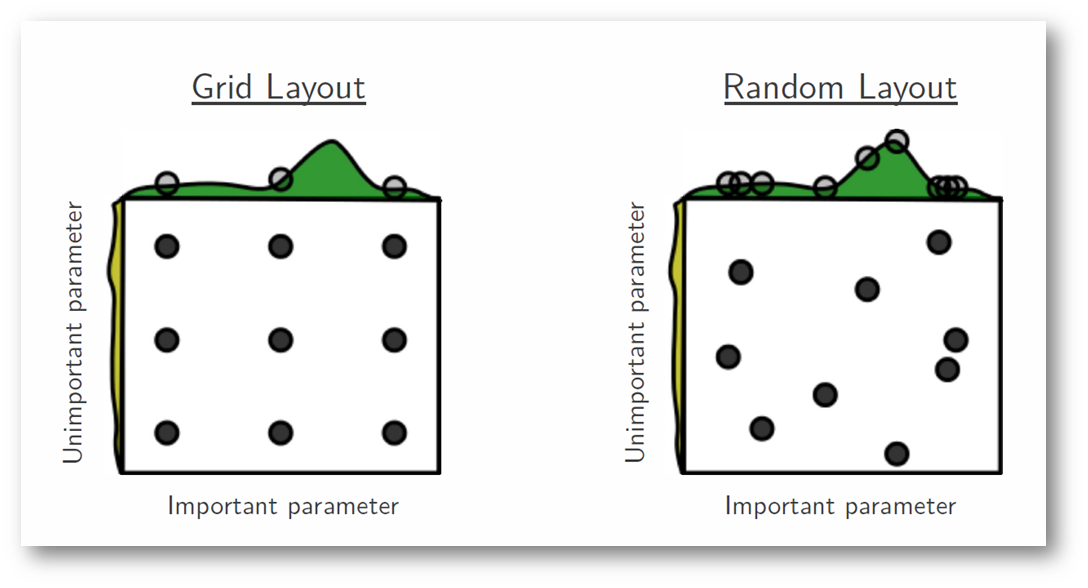
Hyperparmeter tuning (Grid search vs. Random search)
- Grid search & random search with Scikit-learn
- "Compared with neural networks configured by a pure grid search, we find that random search over the same domain is able to find models that are as good or better within a small fraction of the computation time." (Bergstra and Bengio 2012)
- Related paper: Bergstra, J., & Bengio, Y. (2012). Random search for hyper-parameter optimization. Journal of Machine Learning Research, 13(Feb), 281-305.
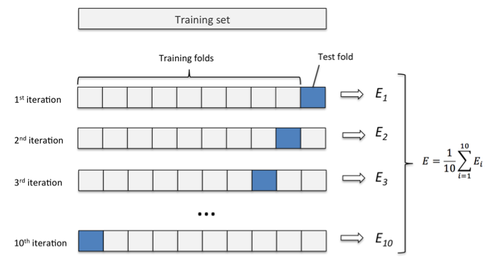
Model selection (Bootstrap vs. Cross-validation)
- Bootstrap & cross-validation with Scikit-learn
- "Our results indicate that for real-world datasets similar to ours, the best method to use for model selection is ten-fold stratified cross validation, even if computation power allows using more folds
- Related paper: Kohavi, R. (1995, August). A study of cross-validation and bootstrap for accuracy estimation and model selection. In Ijcai (Vol. 14, No. 2, pp. 1137-1145).
Optimization methods (first-order vs second-order)
- Adam & L-bfgs optimization for neural networks
- "The method is straightforward to implement, is computationally efficient, has little memory requirements, is invariant to diagonal rescaling of the gradients, and is well suited for problems that are large in terms of data and/or parameters" (Kingma and Ba 2015)
- "Our numerical tests indicate that the L-BFGS method is faster than the method of Buckley and LeNir, and is better able to use additional storage to accelerate convergence" (Liu and Nocedal 1989)

Regularization and feature selection (L1 vs L2 regularization)
- L1 & L2 regularization
- "unless the training set size is large relative to the dimension of the input, some special mechanism - such as regularization, which encourages the fitted parameters to be small - is usually needed to prevent overfitting" (Ng 2004)
- "It has frequently been observed that L1 regularization in many models causes many parameters equal to zero, so that the parameter vector is sparse. This makes it a natural candidate in feature selection settings, where we believe that many features should be ignored." (Ng 2004)
- Related paper: Ng, A. Y. (2004, July). Feature selection, L 1 vs. L 2 regularization, and rotational invariance. In Proceedings of the twenty-first international conference on Machine learning (p. 78). ACM.

Tradeoff when using SGD (batch_size and learning_rate)
- It is widely acknowledged that learning rate should be lessened when using small batch SGD compared to when using large batch SGD. In other words, as the variance of each batch is reduced when using large batch SGD, bigger steps are allowed.
- "one must leverage certain computational tools to benefit from mini-batching in practice." (Bottou et al 2017)
