DwangoMediaVillage / Pqkmeans
Projects that are alternatives of or similar to Pqkmeans
PQk-means
| A 2D example using both k-means and PQk-means | Large-scale evaluation |
|---|---|
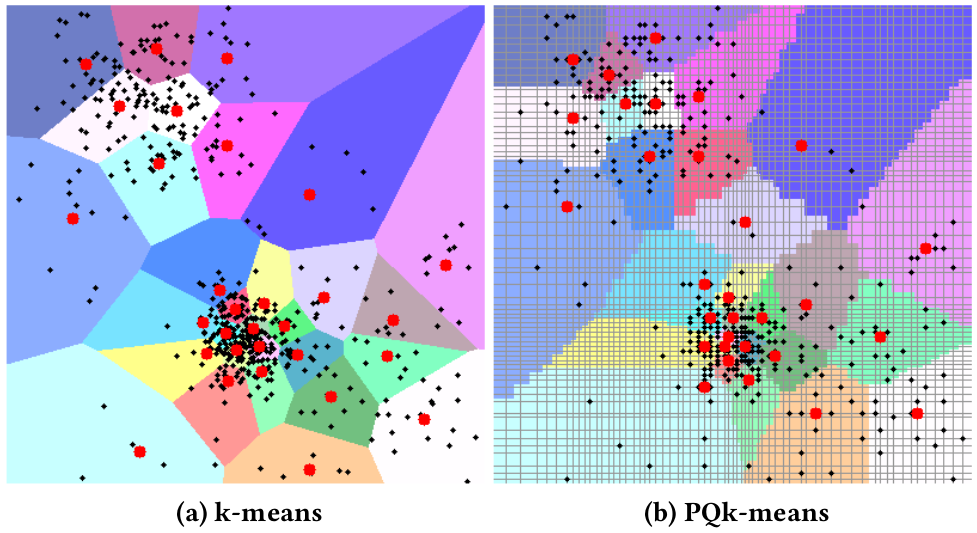 |
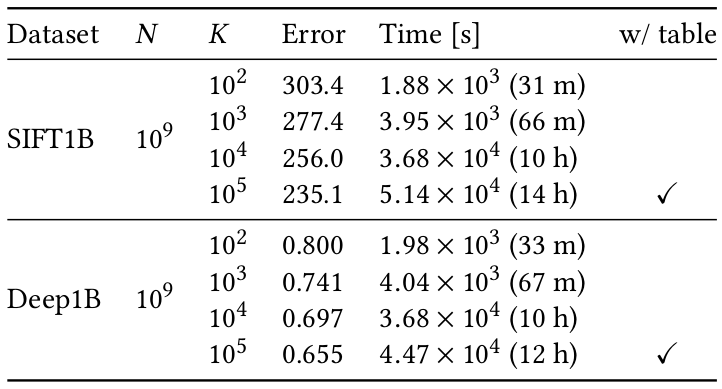 |
PQk-means [Matsui, Ogaki, Yamasaki, and Aizawa, ACMMM 17] is a Python library for efficient clustering of large-scale data. By first compressing input vectors into short product-quantized (PQ) codes, PQk-means achieves fast and memory-efficient clustering, even for high-dimensional vectors. Similar to k-means, PQk-means repeats the assignment and update steps, both of which can be performed in the PQ-code domain.
For a comparison, we provide the ITQ encoding for the binary conversion and Binary k-means [Gong+, CVPR 15] for the clustering of binary codes.
The library is written in C++ for the main algorithm with wrappers for Python. All encoding/clustering codes are compatible with scikit-learn.
Summary of features
- Approximation of k-means
- Tens to hundreds of times faster than k-means
- Tens to hundreds of times more memory efficient than k-means
- Compatible with scikit-learn
- Portable; one-line installation
Installation
Requisites
- CMake
-
brew install cmakefor OS X -
sudo apt install cmakefor Ubuntu
-
- OpenMP (Optional)
- If openmp is installed, it will be automatically used to parallelize the algorithm for faster calculation.
Build & install
You can install the library from PyPI:
pip install pqkmeans
Or, if you would like to use the current master version, you can manually build and install the library by:
git clone --recursive https://github.com/DwangoMediaVillage/pqkmeans.git
cd pqkmeans
python setup.py install
Run samples
# with artificial data
python bin/run_experiment.py --dataset artificial --algorithm bkmeans pqkmeans --k 100
# with texmex dataset (http://corpus-texmex.irisa.fr/)
python bin/run_experiment.py --dataset siftsmall --algorithm bkmeans pqkmeans --k 100
Test
python setup.py test
Usage
For PQk-means
import pqkmeans
import numpy as np
X = np.random.random((100000, 128)) # 128 dimensional 100,000 samples
# Train a PQ encoder.
# Each vector is divided into 4 parts and each part is
# encoded with log256 = 8 bit, resulting in a 32 bit PQ code.
encoder = pqkmeans.encoder.PQEncoder(num_subdim=4, Ks=256)
encoder.fit(X[:1000]) # Use a subset of X for training
# Convert input vectors to 32-bit PQ codes, where each PQ code consists of four uint8.
# You can train the encoder and transform the input vectors to PQ codes preliminary.
X_pqcode = encoder.transform(X)
# Run clustering with k=5 clusters.
kmeans = pqkmeans.clustering.PQKMeans(encoder=encoder, k=5)
clustered = kmeans.fit_predict(X_pqcode)
# Then, clustered[0] is the id of assigned center for the first input PQ code (X_pqcode[0]).
Note that an instance of PQ-encoder (encoder) and an instance of clustering (kmeans) can be pickled and reused later.
import pickle
# An instance of PQ-encoder.
pickle.dump(encoder, open('encoder.pkl', 'wb'))
encoder_dumped = pickle.load(open('encoder.pkl', 'rb'))
# An instance of clustering. This can be reused as a vector quantizer later.
pickle.dump(kmeans, open('kmeans.pkl', 'wb'))
kmeans_dumped = pickle.load(open('kmeans.pkl', 'rb'))
For Bk-means
In almost the same manner as for PQk-means,
import pqkmeans
import numpy as np
X = np.random.random((100000, 128)) # 128 dimensional 100,000 samples
# Train an ITQ binary encoder
encoder = pqkmeans.encoder.ITQEncoder(num_bit=32)
encoder.fit(X[:1000]) # Use a subset of X for training
# Convert input vectors to binary codes
X_itq = encoder.transform(X)
# Run clustering
kmeans = pqkmeans.clustering.BKMeans(k=5, input_dim=32)
clustered = kmeans.fit_predict(X_itq)
Please see more examples on a tutorial
Note
- This repository contains the re-implemented version of the PQk-means with the Python interface. There can be the difference between this repository and the pure c++ implementation used in the paper.
- We tested this library with Python3, on OS X and Ubuntu 16.04.
Authors
- Keisuke Ogaki designed the whole structure of the library, and implemented most of the Bk-means clustering
- Yusuke Matsui implemented most of the PQk-means clustering
Reference
@inproceedings{pqkmeans,
author = {Yusuke Matsui and Keisuke Ogaki and Toshihiko Yamasaki and Kiyoharu Aizawa},
title = {PQk-means: Billion-scale Clustering for Product-quantized Codes},
booktitle = {ACM International Conference on Multimedia (ACMMM)},
year = {2017},
}
Todo
- Evaluation script for billion-scale data
- Nearest neighbor search with PQTable
- Documentation