lyeoni / Prenlp
Licence: apache-2.0
Preprocessing Library for Natural Language Processing
Stars: ✭ 130
Programming Languages
python
139335 projects - #7 most used programming language
Projects that are alternatives of or similar to Prenlp
Textvec
Text vectorization tool to outperform TFIDF for classification tasks
Stars: ✭ 167 (+28.46%)
Mutual labels: natural-language-processing, text-processing
Konoha
🌿 An easy-to-use Japanese Text Processing tool, which makes it possible to switch tokenizers with small changes of code.
Stars: ✭ 130 (+0%)
Mutual labels: natural-language-processing, text-processing
Stanza Old
Stanford NLP group's shared Python tools.
Stars: ✭ 142 (+9.23%)
Mutual labels: natural-language-processing, text-processing
Lingua Franca
Mycroft's multilingual text parsing and formatting library
Stars: ✭ 51 (-60.77%)
Mutual labels: natural-language-processing, text-processing
Pynlpl
PyNLPl, pronounced as 'pineapple', is a Python library for Natural Language Processing. It contains various modules useful for common, and less common, NLP tasks. PyNLPl can be used for basic tasks such as the extraction of n-grams and frequency lists, and to build simple language model. There are also more complex data types and algorithms. Moreover, there are parsers for file formats common in NLP (e.g. FoLiA/Giza/Moses/ARPA/Timbl/CQL). There are also clients to interface with various NLP specific servers. PyNLPl most notably features a very extensive library for working with FoLiA XML (Format for Linguistic Annotation).
Stars: ✭ 426 (+227.69%)
Mutual labels: natural-language-processing, text-processing
Fastnlp
fastNLP: A Modularized and Extensible NLP Framework. Currently still in incubation.
Stars: ✭ 2,441 (+1777.69%)
Mutual labels: natural-language-processing, text-processing
Nlpre
Python library for Natural Language Preprocessing (NLPre)
Stars: ✭ 158 (+21.54%)
Mutual labels: natural-language-processing, text-processing
Stringi
THE String Processing Package for R (with ICU)
Stars: ✭ 204 (+56.92%)
Mutual labels: natural-language-processing, text-processing
Open Korean Text
Open Korean Text Processor - An Open-source Korean Text Processor
Stars: ✭ 438 (+236.92%)
Mutual labels: natural-language-processing, text-processing
Cogcomp Nlpy
CogComp's light-weight Python NLP annotators
Stars: ✭ 115 (-11.54%)
Mutual labels: natural-language-processing, text-processing
Awesome Hungarian Nlp
A curated list of NLP resources for Hungarian
Stars: ✭ 121 (-6.92%)
Mutual labels: natural-language-processing
Fnc 1 Baseline
A baseline implementation for FNC-1
Stars: ✭ 123 (-5.38%)
Mutual labels: natural-language-processing
Neuraldialog Larl
PyTorch implementation of latent space reinforcement learning for E2E dialog published at NAACL 2019. It is released by Tiancheng Zhao (Tony) from Dialog Research Center, LTI, CMU
Stars: ✭ 127 (-2.31%)
Mutual labels: natural-language-processing
Libasciidoc
A Golang library for processing Asciidoc files.
Stars: ✭ 129 (-0.77%)
Mutual labels: text-processing
Clicr
Machine reading comprehension on clinical case reports
Stars: ✭ 123 (-5.38%)
Mutual labels: natural-language-processing
Neuro
🔮 Neuro.js is machine learning library for building AI assistants and chat-bots (WIP).
Stars: ✭ 126 (-3.08%)
Mutual labels: natural-language-processing
Spacy Js
🎀 JavaScript API for spaCy with Python REST API
Stars: ✭ 123 (-5.38%)
Mutual labels: natural-language-processing
Files2rouge
Calculating ROUGE score between two files (line-by-line)
Stars: ✭ 120 (-7.69%)
Mutual labels: natural-language-processing
Nlp Pretrained Model
A collection of Natural language processing pre-trained models.
Stars: ✭ 122 (-6.15%)
Mutual labels: natural-language-processing
Medquad
Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites
Stars: ✭ 129 (-0.77%)
Mutual labels: natural-language-processing
PreNLP




Preprocessing Library for Natural Language Processing
Installation
Requirements
- Python >= 3.6
- Mecab morphological analyzer for Korean
sh scripts/install_mecab.sh # Only for Mac OS users, run the code below before run install_mecab.sh script. # export MACOSX_DEPLOYMENT_TARGET=10.10 # CFLAGS='-stdlib=libc++' pip install konlpy - C++ Build tools for fastText
- g++ >= 4.7.2 or clang >= 3.3
- For Windows, Visual Studio C++ is recommended.
With pip
prenlp can be installed using pip as follows:
pip install prenlp
Usage
Data
Dataset Loading
Popular datasets for NLP tasks are provided in prenlp. All datasets is stored in /.data directory.
- Sentiment Analysis: IMDb, NSMC
- Language Modeling: WikiText-2, WikiText-103, WikiText-ko, NamuWiki-ko
| Dataset | Language | Articles | Sentences | Tokens | Vocab | Size |
|---|---|---|---|---|---|---|
| WikiText-2 | English | 720 | - | 2,551,843 | 33,278 | 13.3MB |
| WikiText-103 | English | 28,595 | - | 103,690,236 | 267,735 | 517.4MB |
| WikiText-ko | Korean | 477,946 | 2,333,930 | 131,184,780 | 662,949 | 667MB |
| NamuWiki-ko | Korean | 661,032 | 16,288,639 | 715,535,778 | 1,130,008 | 3.3GB |
| WikiText-ko+NamuWiki-ko | Korean | 1,138,978 | 18,622,569 | 846,720,558 | 1,360,538 | 3.95GB |
General use cases are as follows:
WikiText-2 / WikiText-103
>>> wikitext2 = prenlp.data.WikiText2()
>>> len(wikitext2)
3
>>> train, valid, test = prenlp.data.WikiText2()
>>> train[0]
'= Valkyria Chronicles III ='
IMDB
>>> imdb_train, imdb_test = prenlp.data.IMDB()
>>> imdb_train[0]
["Minor Spoilers<br /><br />Alison Parker (Cristina Raines) is a successful top model, living with the lawyer Michael Lerman (Chris Sarandon) in his apartment. She tried to commit ...", 'pos']
Normalization
Frequently used normalization functions for text pre-processing are provided in prenlp.
url, HTML tag, emoticon, email, phone number, etc.
General use cases are as follows:
>>> from prenlp.data import Normalizer
>>> normalizer = Normalizer(url_repl='[URL]', tag_repl='[TAG]', emoji_repl='[EMOJI]', email_repl='[EMAIL]', tel_repl='[TEL]', image_repl='[IMG]')
>>> normalizer.normalize('Visit this link for more details: https://github.com/')
'Visit this link for more details: [URL]'
>>> normalizer.normalize('Use HTML with the desired attributes: <img src="cat.jpg" height="100" />')
'Use HTML with the desired attributes: [TAG]'
>>> normalizer.normalize('Hello 🤩, I love you 💓 !')
'Hello [EMOJI], I love you [EMOJI] !'
>>> normalizer.normalize('Contact me at [email protected]')
'Contact me at [EMAIL]'
>>> normalizer.normalize('Call +82 10-1234-5678')
'Call [TEL]'
>>> normalizer.normalize('Download our logo image, logo123.png, with transparent background.')
'Download our logo image, [IMG], with transparent background.'
Tokenizer
Frequently used (subword) tokenizers for text pre-processing are provided in prenlp.
SentencePiece, NLTKMosesTokenizer, Mecab
SentencePiece
>>> from prenlp.tokenizer import SentencePiece
>>> SentencePiece.train(input='corpus.txt', model_prefix='sentencepiece', vocab_size=10000)
>>> tokenizer = SentencePiece.load('sentencepiece.model')
>>> tokenizer('Time is the most valuable thing a man can spend.')
['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.']
>>> tokenizer.tokenize('Time is the most valuable thing a man can spend.')
['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.']
>>> tokenizer.detokenize(['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.'])
Time is the most valuable thing a man can spend.
Moses tokenizer
>>> from prenlp.tokenizer import NLTKMosesTokenizer
>>> tokenizer = NLTKMosesTokenizer()
>>> tokenizer('Time is the most valuable thing a man can spend.')
['Time', 'is', 'the', 'most', 'valuable', 'thing', 'a', 'man', 'can', 'spend', '.']
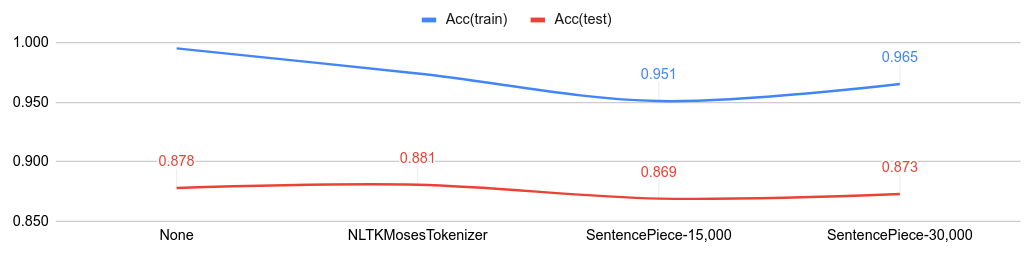
Comparisons with tokenizers on IMDb
Below figure shows the classification accuracy from various tokenizer.
- Code: NLTKMosesTokenizer, SentencePiece
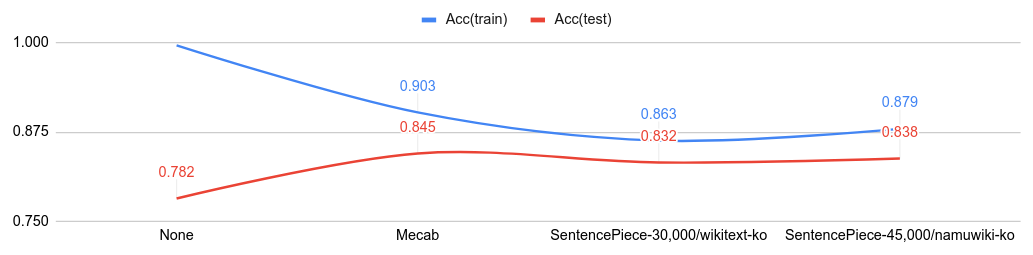
Comparisons with tokenizers on NSMC (Korean IMDb)
Below figure shows the classification accuracy from various tokenizer.
- Code: Mecab, SentencePiece
Author
- Hoyeon Lee @lyeoni
- email : [email protected]
- facebook : https://www.facebook.com/lyeoni.f
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].