wwwpf / Qzoneexporter
Licence: gpl-3.0
QQ空间爬虫,可导出并显示日志、相册、留言板、说说、照片、视频等数据。
Stars: ✭ 386
Programming Languages
python
139335 projects - #7 most used programming language
Labels
Projects that are alternatives of or similar to Qzoneexporter
Elves
🎊 Design and implement of lightweight crawler framework.
Stars: ✭ 315 (-18.39%)
Mutual labels: spider
Ttbot
今日头条机器人,支持用户登陆、关注、取消关注、获取关注粉丝、发文、发悟空问答、点赞、评论、采集各种类型新闻讯息等,使用今日头条网页版API实现
Stars: ✭ 338 (-12.44%)
Mutual labels: spider
Celerystalk
An asynchronous enumeration & vulnerability scanner. Run all the tools on all the hosts.
Stars: ✭ 333 (-13.73%)
Mutual labels: spider
Freshonions Torscraper
Fresh Onions is an open source TOR spider / hidden service onion crawler hosted at zlal32teyptf4tvi.onion
Stars: ✭ 348 (-9.84%)
Mutual labels: spider
Bilili
🍻 bilibili video (including bangumi) and danmaku downloader | B站视频(含番剧)、弹幕下载器
Stars: ✭ 379 (-1.81%)
Mutual labels: spider
Kindlebookmaker
Kindle Book Maker with KindleGen, Make Book from RSS/single URL/directory and so on.
Stars: ✭ 364 (-5.7%)
Mutual labels: spider
Weatherspider
天气爬虫(全国城镇天气自动定时抓取更新,并开放RESTful查询接口),附带代理IP池定时更新并检测其可用性
Stars: ✭ 337 (-12.69%)
Mutual labels: spider
Fictiondown
小说下载|小说爬取|起点|笔趣阁|导出Markdown|导出txt|转换epub|广告过滤|自动校对
Stars: ✭ 362 (-6.22%)
Mutual labels: spider
Spiders
Python爬虫,返回一定格式的信息,下载,使用flask提供简易api。抖音无水印、皮皮虾、快手、网易云音乐、qq音乐、咪咕音乐、荔枝FM音频、知乎视频、最右语音、视频、微博......
Stars: ✭ 372 (-3.63%)
Mutual labels: spider
Signature algorithm
各种App、小程序、网站的请求签名或加密算法。 现已有:自如、小红书、蛋壳公寓、luckin coffee(瑞幸咖啡)、bangkokair(曼谷航空)
Stars: ✭ 380 (-1.55%)
Mutual labels: spider
Webster
a reliable high-level web crawling & scraping framework for Node.js.
Stars: ✭ 364 (-5.7%)
Mutual labels: spider
QzoneExporter
QQ空间数据导出及显示。
- 导出日志、留言板、相册、说说等数据。
- 将说说、相册中的图片及视频下载至本地。
- 以网页形式显示本地数据,可在浏览时自动下载图片及视频。
- 支持 Exif 信息写回照片,时间写入文件名。(由Yang-z及greysign提供)
导出数据
usage: exporter.py [-h] [--blog] [--msgboard] [--photo] [--shuoshuo] [--like]
[--download] [--all]
optional arguments:
-h, --help show this help message and exit
--blog 导出日志数据
--msgboard 导出留言板数据
--photo 导出相册数据
--shuoshuo 导出说说数据
--download 下载图片或视频至本地
--all 导出所有数据
显示数据
usage: displayer.py [-h] [--download]
optional arguments:
-h, --help show this help message and exit
--download 当本地不存在图片、视频时,尝试下载至本地
输入
- target_uin 需要导出数据的QQ号。
- self_uin 用于登录空间的QQ号。
- cookies_value
从浏览器登录QQ空间,按
F12,点击Network选项卡,点击QQ空间“我的主页“,点击XHR,点击main_page_cgi请求,从Header中找出cookie,如图所示。 - g_tk
可通过 cookies_value 中的
p_skey计算,选填。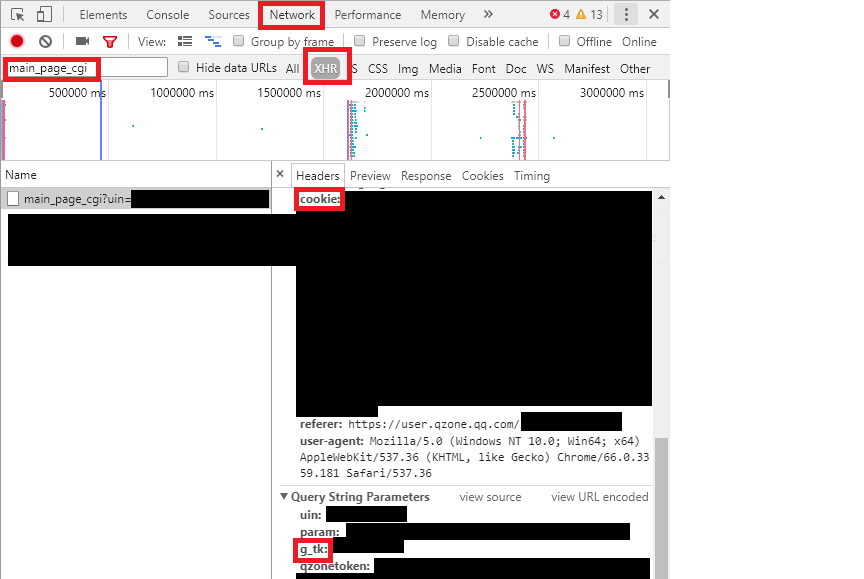

登录QQ需要有访问目标QQ空间的权限。
网页显示效果
预览

日志


留言板

相册



说说

输出文件
target_uin/
blog/
日志分类/ // 譬如:个人日志
日志正文.html
日志评论.json
msg_board/
每20条留言分为1个json文件
photo
相册名_相册id/
downloaded/ // 保存下载的数据
照片数据
评论数据
相册信息.json
downloaded.txt // 已下载的url
to_download.txt // 待下载的url及文件名
shuoshuo/
downloaded/
downloaded.txt
to_download.txt
shuoshuo_tid.txt // 保存说说的tid
每40条说说分为1个json文件
main_page.json // 日志、相册、说说的数量
like_information.json // 保存点赞数据
日志


留言板

相册


说说

说明
- 数据以json格式保存,可通过网页显示主要数据。
- 导出的数据是登录账号可见的数据,“仅主人可见”等数据无法获取。
- 导出的视频链接有时效性,超时无法访问。
- 如果相册图片数量较多并且未下载至本地时,网页显示会比较慢。
依赖
- requests
- bs4
- Python ≥ 3.6
- piexif(Exif 信息写回)
- Flask(网页显示)
使用
# exporter.py
# 根据需要设定以下变量
target_uin = "需要导出数据的QQ号"
self_uin = "登录空间的QQ号"
cookies_value = "从浏览器获取"
g_tk = "从浏览器获取" # 可选,会尝试通过 cookies 计算
q = QzoneExporter(self_uin, g_tk, cookies_value, args, target_uin)
q.export()
示例
导出日志数据
命令行中运行
python exporter.py --blog
下载相册照片
python exporter.py --photo
python exporter.py --download
或
python exporter.py --photo --download
网页显示
python displayer.py [--download]
Exif 信息写回照片
具体使用参考 photo_exif_recover.py 内的说明。
存在的问题
- 某些图片通过sharpP格式传输,无法打开。
- 进度的保存。
- 由于数据未抓取到本地、不想写等原因,网页显示时忽略了一些无关紧要的数据。
- 未能完全测试所有情况,因此网页显示时可能会出现某些错误。
更新记录
- 2019.10.06 新增: 日志增加转载标记(需要额外获取数据,更早版本无法显示)
- 2019.09.22 修复: 长说说未获取全文
- 2019.06.16 修复: 说说第九张之后的图片未处理
- 2019.05.30 修复: 某些情况下说说中的视频被判断为图片。
- 2019.05.10 新增: 网页显示,多线程下载;废弃: 下载超时设置,点赞数据抓取;修复: 文件名可能非法
- 2018.08.04 修复: 无法获取分类视图的相册。
参考
- QQ 空间爬虫之爬取说说 感谢这篇博客提供的思路。
- QQ空间 网页显示本地数据时使用的样式与布局均来自于QQ空间。
LICENSE
GPL-3.0,额外条件:禁止商用。
捐赠
如果您认为该项目在一定程度上帮助了您,可以赞赏我:D

Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].