131250208 / Tplinker Joint Extraction
Labels
Projects that are alternatives of or similar to Tplinker Joint Extraction
TPLinker
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
This repository contains all the code of the official implementation for the paper: TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. The paper has been accepted to appear at COLING 2020. [slides] [poster]
TPLinker is a joint extraction model resolved the issues of relation overlapping and nested entities, immune to the influence of exposure bias, and achieves SOTA performance on NYT (TPLinker: 91.9, TPlinkerPlus: 92.6 (+3.0)) and WebNLG (TPLinker: 91.9, TPlinkerPlus: 92.3 (+0.5)). Note that the details of TPLinkerPlus will be published in the extended paper, which is still in progress.
I am looking for a Ph.D. position! My research insterests are NLP and knowledge graph. If you have any helpful info, please contact me! Thank you very much!
Update
- 2020.11.01: Fixed bugs and added comments in BuildData.ipynb and build_data_config.yaml; TPLinkerPlus can support entity classification now, see build data for the data format; Updated the datasets (added
entity_listfor TPLinkerPlus). - 2020.12.04: The original default parameters in
build_data_config.yamlare all for Chinese datasets. It might be misleading for reproducing the results. I changed back to the ones for English datasets. Note that you must setignore_subwordtotruefor English datasets, or it will hurt the performance and can not reach the scores reported in the paper. - 2020.12.09: We published model states for fast tests. See Super Parameters.
Model
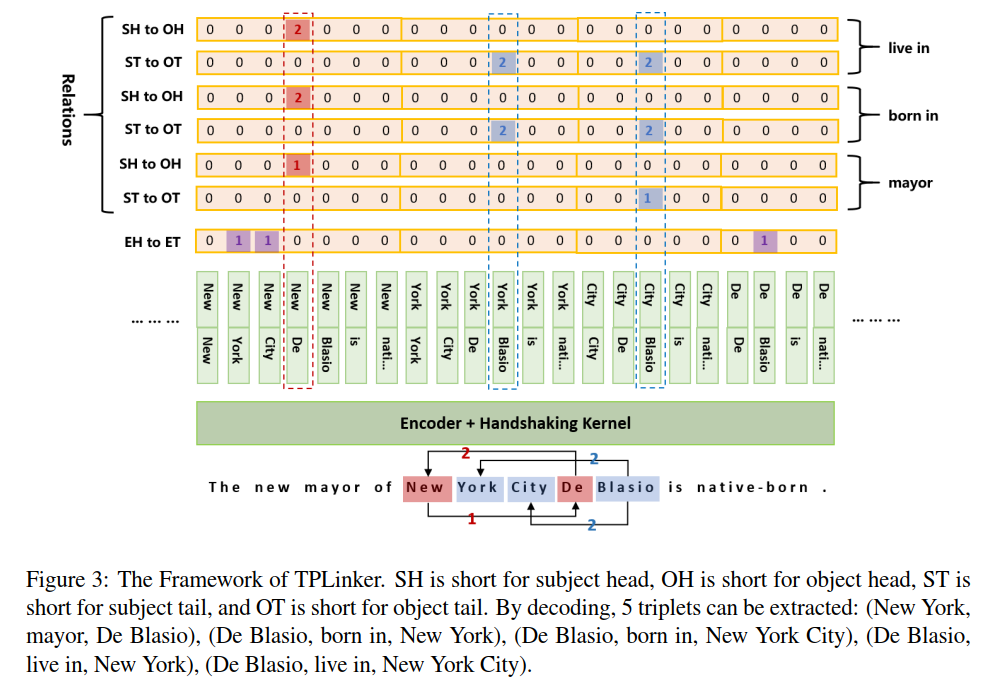
Results

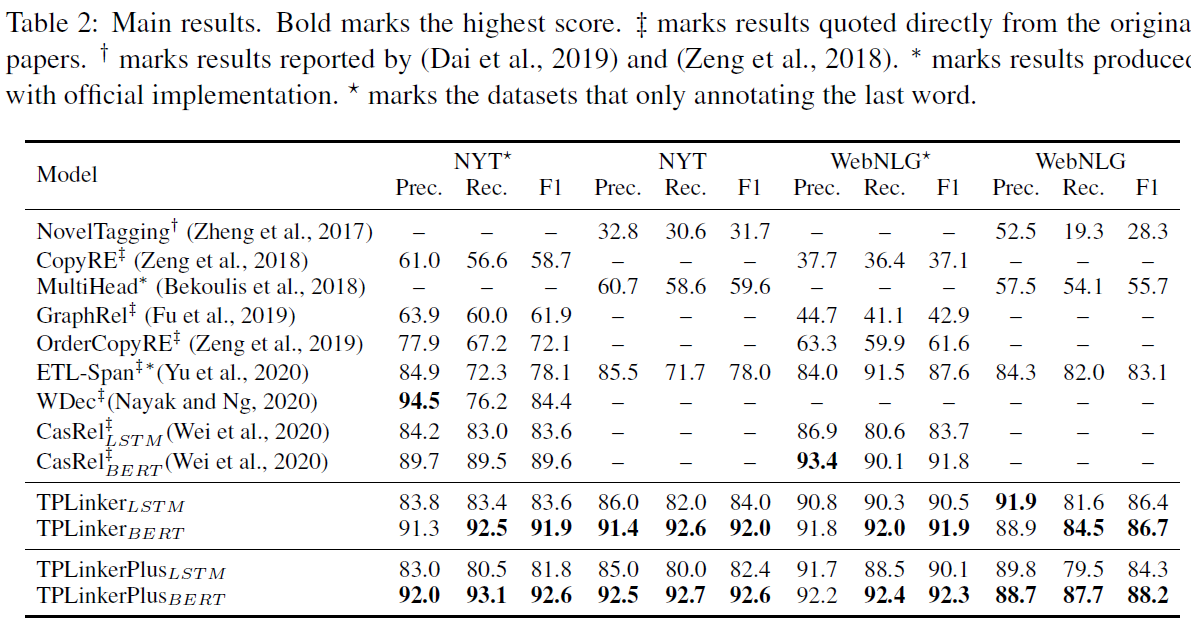

Usage
Prerequisites
Our experiments are conducted on Python 3.6 and Pytorch == 1.6.0. The main requirements are:
- tqdm
- glove-python-binary==0.2.0
- transformers==3.0.2
- wandb # for logging the results
- yaml
In the root directory, run
pip install -e .
Data
download data
Get and preprocess NYT* and WebNLG* following CasRel (note: named NYT and WebNLG by CasRel).
Take NYT* as an example, rename train_triples.json and dev_triples.json to train_data.json and valid_data.json and move them to ori_data/nyt_star, put all test*.json under ori_data/nyt_star/test_data. The same process goes for WebNLG*.
Get raw NYT from CopyRE, rename raw_train.json and raw_valid.json to train_data.json and valid_data.json and move them to ori_data/nyt, rename raw_test.json to test_data.json and put it under ori_data/nyt/test_data.
Get WebNLG from ETL-Span, rename train.json and dev.json to train_data.json and valid_data.json and move them to ori_data/webnlg, rename test.json to test_data.json and put it under ori_data/webnlg/test_data.
If you are bother to prepare data on your own, you could download our preprocessed datasets.
build data
Build data by preprocess/BuildData.ipynb.
Set configuration in preprocess/build_data_config.yaml.
In the configuration file, set exp_name corresponding to the directory name, set ori_data_format corresponding to the source project name of the data.
e.g. To build NYT*, set exp_name to nyt_star and set ori_data_format to casrel. See build_data_config.yaml for more details.
If you want to run on other datasets, transform them into the normal format for TPLinker, then set exp_name to <your folder name> and set ori_data_format to tplinker:
[{
"id": <text_id>,
"text": <text>,
"relation_list": [{
"subject": <subject>,
"subj_char_span": <character level span of the subject>, # e.g [3, 10] This key is optional. If no this key, set "add_char_span" to true in "build_data_config.yaml" when you build the data
"object": <object>,
"obj_char_span": <character level span of the object>, # optional
"predicate": <predicate>,
}],
"entity_list": [{ # This key is optional, only for TPLinkerPlus. If no this key, BuildData.ipynb will auto genrate a entity list based on the relation list.
"text": <entity>,
"type": <entity_type>,
"char_span": <character level span of the object>, # This key relys on subj_char_span and obj_char_span in relation_list, if you do not have, set "add_char_span" to true in "build_data_config.yaml".
}],
}]
Pretrained Model and Word Embeddings
Download BERT-BASE-CASED and put it under ../pretrained_models. Pretrain word embeddings by preprocess/Pretrain_Word_Embedding.ipynb and put models under ../pretrained_emb.
If you are bother to train word embeddings by yourself, use our's directly.
Train
Set configuration in tplinker/config.py as follows:
common["exp_name"] = nyt_star # webnlg_star, nyt, webnlg
common["device_num"] = 0 # 1, 2, 3 ...
common["encoder"] = "BERT" # BiLSTM
train_config["hyper_parameters"]["batch_size"] = 24 # 6 for webnlg and webnlg_star
train_config["hyper_parameters"]["match_pattern"] = "only_head_text" # "only_head_text" for webnlg_star and nyt_star; "whole_text" for webnlg and nyt.
# if the encoder is set to BiLSTM
bilstm_config["pretrained_word_embedding_path"] = ""../pretrained_word_emb/glove_300_nyt.emb""
# Leave the rest as default
Start training
cd tplinker
python train.py
Super Parameters
TPLinker
# NYT*
T_mult: 1
batch_size: 24
dist_emb_size: -1
ent_add_dist: false
epochs: 100
inner_enc_type: lstm
log_interval: 10
loss_weight_recover_steps: 12000
lr: 0.00005
match_pattern: only_head_text
max_seq_len: 100
rel_add_dist: false
rewarm_epoch_num: 2
scheduler: CAWR
seed: 2333
shaking_type: cat
sliding_len: 20
# NYT
match_pattern: whole_text
...(the rest is the same as above)
# WebNLG*
batch_size: 6
loss_weight_recover_steps: 6000
match_pattern: only_head_text
...
# WebNLG
batch_size: 6
loss_weight_recover_steps: 6000
match_pattern: whole_text
...
We also provide model states for fast tests. You can download them here! You can get results as follows:
Before you run, make sure:
1. transformers==3.0.2
2. "max_test_seq_len" is set to 512
3. "match_pattern" should be the same as in the training: `whole_text` for NYT/WebNLG, `only_head_text` for NYT*/WebNLG*.
# The test_triples and the test_data are the complete test datasets. The tuple means (precision, recall, f1).
# In the codes, I did not set the seed in a right way, so you might get different scores (higher or lower). But they should be very close to the results in the paper.
# NYT*
{'2og80ub4': {'test_triples': (0.9118290017002562,
0.9257706535141687,
0.9187469407233642),
'test_triples_1': (0.8641055045871312,
0.929099876695409,
0.8954248365513463),
'test_triples_2': (0.9435444280804642,
0.9196172248803387,
0.9314271867684752),
'test_triples_3': (0.9550056242968554,
0.9070512820511851,
0.9304109588540408),
'test_triples_4': (0.9635099913118189,
0.9527491408933889,
0.9580993520017547),
'test_triples_5': (0.9177877428997133,
0.9082840236685046,
0.9130111523662223),
'test_triples_epo': (0.9497520661156711,
0.932489451476763,
0.9410415983777494),
'test_triples_normal': (0.8659532526048757,
0.9281617869000626,
0.895979020929055),
'test_triples_seo': (0.9476190476190225,
0.9258206254845974,
0.9365930186452366)}}
# NYT
{'y84trnyf': {'test_data': (0.916494217894085,
0.9272167487684615,
0.9218243035924758)}}
# WebNLG*
{'2i4808qi': {'test_triples': (0.921855146124465,
0.91777356103726,
0.919809825623476),
'test_triples_1': (0.8759398496237308,
0.8759398496237308,
0.8759398495737308),
'test_triples_2': (0.9075144508667897,
0.9235294117644343,
0.9154518949934687),
'test_triples_3': (0.9509043927646122,
0.9460154241642813,
0.9484536081971787),
'test_triples_4': (0.9297752808986153,
0.9271708683470793,
0.928471248196584),
'test_triples_5': (0.9360730593603032,
0.8951965065498275,
0.9151785713781879),
'test_triples_epo': (0.9764705882341453,
0.9431818181807463,
0.959537572203241),
'test_triples_normal': (0.8780487804874479,
0.8780487804874479,
0.8780487804374479),
'test_triples_seo': (0.9299698795180023,
0.9250936329587321,
0.9275253473025405)}}
# WebNLG
{'1g7ehpsl': {'test': (0.8862619808306142,
0.8630989421281354,
0.8745271121819839)}}
TPLinkerPlus
# NYT*/NYT
# The best F1: 0.931/0.934 (on validation set), 0.926/0.926 (on test set)
T_mult: 1
batch_size: 24
epochs: 250
log_interval: 10
lr: 0.00001
max_seq_len: 100
rewarm_epoch_num: 2
scheduler: CAWR
seed: 2333
shaking_type: cln
sliding_len: 20
tok_pair_sample_rate: 1
# WebNLG*/WebNLG
# The best F1: 0.934/0.889 (on validation set), 0.923/0.882 (on test set)
T_mult: 1
batch_size: 6
epochs: 250
log_interval: 10
lr: 0.00001
max_seq_len: 100
rewarm_epoch_num: 2
scheduler: CAWR
seed: 2333
shaking_type: cln
sliding_len: 20
tok_pair_sample_rate: 1
Evaluation
Set configuration in tplinker/config.py as follows:
eval_config["model_state_dict_dir"] = "./wandb" # if use wandb, set "./wandb"; if you use default logger, set "./default_log_dir"
eval_config["run_ids"] = ["46qer3r9", ] # If you use default logger, run id is shown in the output and recorded in the log (see train_config["log_path"]); If you use wandb, it is logged on the platform, check the details of the running projects.
eval_config["last_k_model"] = 1 # only use the last k models in to output results
# Leave the rest as the same as the training
Start evaluation by running tplinker/Evaluation.ipynb
Citation
@inproceedings{wang-etal-2020-tplinker,
title = "{TPL}inker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking",
author = "Wang, Yucheng and Yu, Bowen and Zhang, Yueyang and Liu, Tingwen and Zhu, Hongsong and Sun, Limin",
booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
month = dec,
year = "2020",
address = "Barcelona, Spain (Online)",
publisher = "International Committee on Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.coling-main.138",
pages = "1572--1582"
}