Traveling Salesman Problem (TSP)
Travelling salesman problem (TSP) has been already mentioned in one of the previous chapters. To repeat it, there are cities and given distances between them.Travelling salesman has to visit all of them, but he does not to travel very much. Task is to find a sequence of cities to minimize travelled distance. In other words, find a minimal Hamiltonian tour in a complete graph of N nodes.
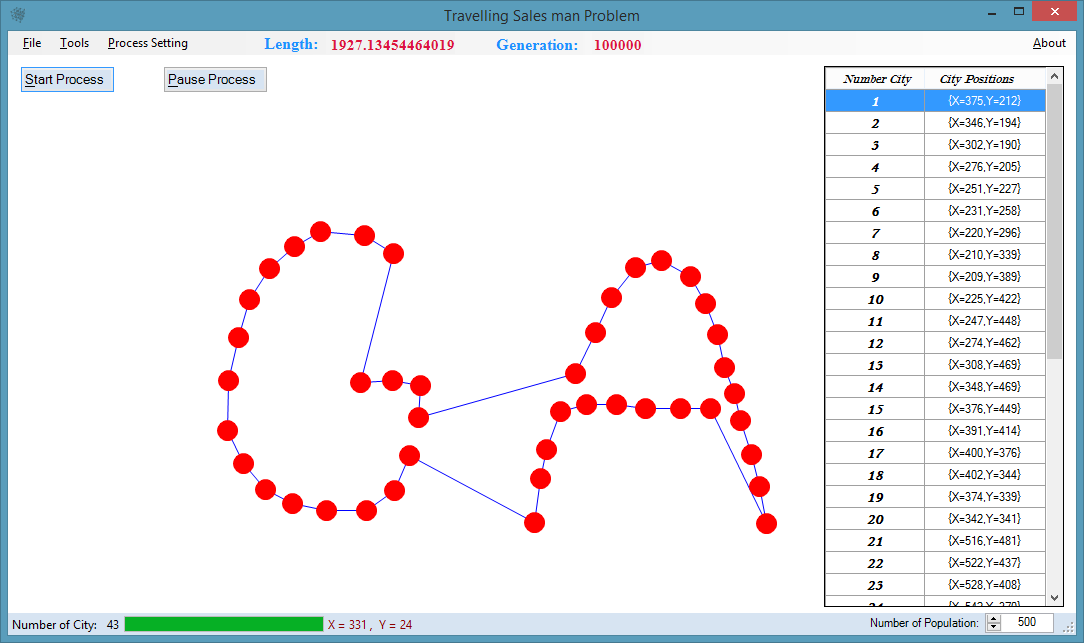
Note:
I do not have any degree in GA so this article can't be used as GA book or GA tutorial. There aren't any mathematics nor logic nor algebra about GA. It's only a programmer's view on Genetic Algorithms and only example of GA coding. Use it carefully! Any comments and criticism are highly appreciated.
Project Purpose
Optimization Single Population Genetic Algorithm in Parallel Computing on TSP Example
Abstract
The article investigates the efficiency of the parallel computation of the single population Genetic Algorithm approach on Travelling Salesman Problem examples and multiprocessing systems. For the parallel algorithm design functional decomposition of the parallel application has been made and the manager/workers paradigm is applied. Performance estimation and parallelism profiling have been made on the basis of multiTasking program implementation.
I. INTRODUCTION
The foundation of Parallel Genetic Algorithm (PGA) is Genetic Algorithm (GA), which is a class of global, adaptable, and probabilistic search optimization and revolution algorithm gleaned from the model of organic evolution and also simulates the genetics and evolution of biologic population in nature. GA adopts naturally evolutionary model such as selection, crossover, mutation, deletion and transference. Mathematically, this evolutionary process is a typical algorithm to find out the optimal solution via iteration search among multi-element in a Non-deterministic Polynomial-time (NP) set. Simple Genetic Algorithm (SGA) can be defined as SGA=(M, C, F, o, Ps, Pc, Pm, T), where C is a fixed bitstring code, F is a fitness evaluation function, M is an initial population of biologic colony and Ps, Pc, Pm are probabilities of selection, crossover and mutation respectively.
In solving NP problems by Series GA, a large sample space will increase the length of chromosomes. And this causes to increase in time complexity of the algorithm. [1]
We've changed the serial genetic algorithm to be processed in Parallel. Finally, the time complexity is reduced.
The PGA uses two major modifications compared to the genetic algorithm. Firstly, selection for mating is distributed. Individuals live in a 2-D world. Selection of a mate is done by each individual independently in its neighborhood (presented in Fig.1). Secondly, each individual may improve its fitness during its lifetime by e.g. local hill-climbing.
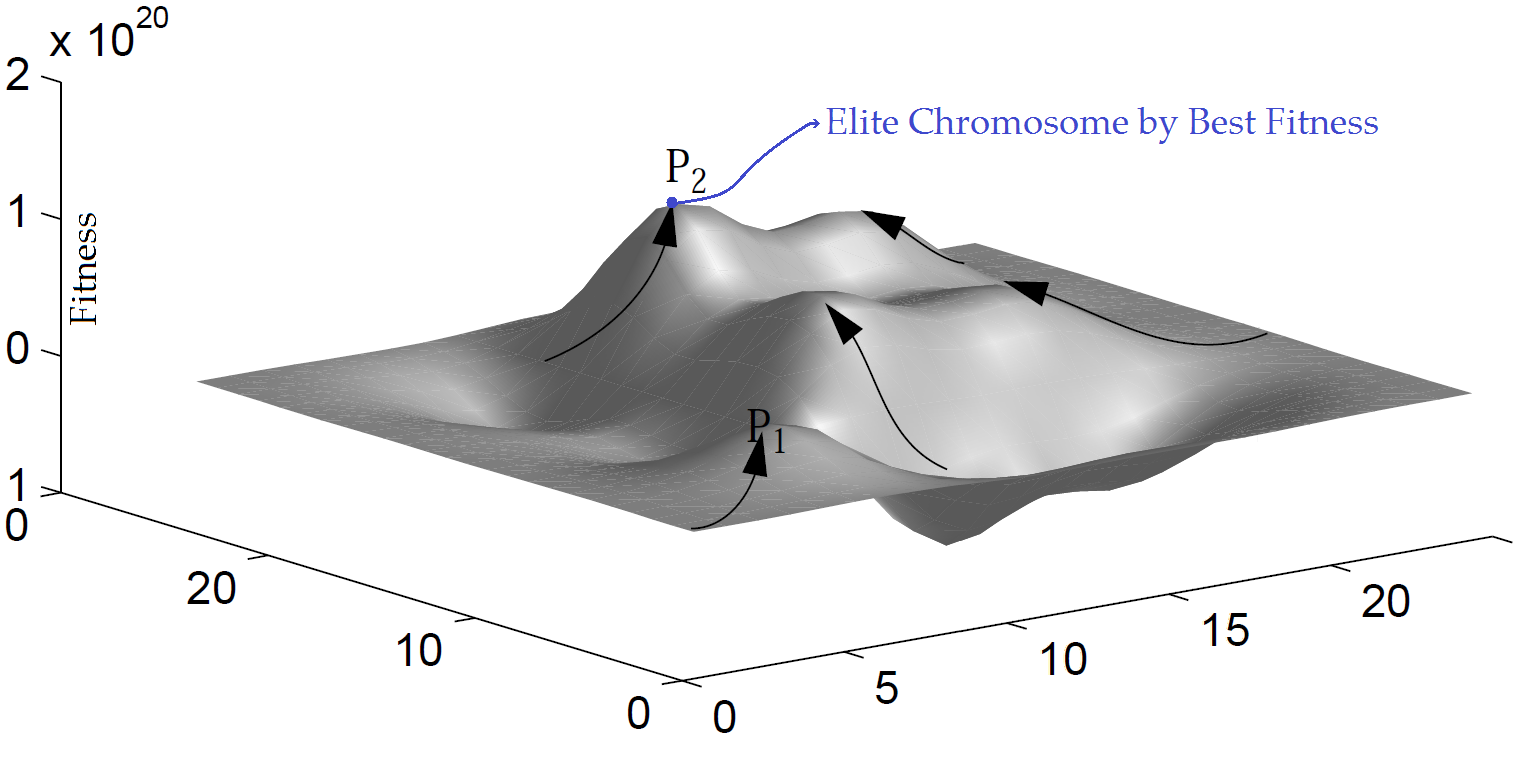 Figure 1. The random search and inherently parallel of genetic algorithm
Figure 1. The random search and inherently parallel of genetic algorithm
The PGA is totally asynchronous, running with maximal efficiency on MIMD (Multiple Instruction, Multiple Data is a technique employed to achieve parallelism in computing) parallel computers. The search strategy of the PGA is based on a small number of active and intelligent individuals, whereas a GA uses a large population of passive individuals. Abstractly, a PGA is a parallel search with information exchange between the individuals in single population. We will investigate the PGA with deceptive problems and for example, implement it on the traveling salesman problem (TSP).
Parallel Computing are widely used nowadays for solving time-consuming problems. The travelling salesman problem is a well known combinatorial problem. [2]
The idea of the TSP is to find the shortest tour of a group of cities without visiting any town twice, but, practically, it implies the construction of a Hamiltonian cycle within a weighted fully connected undirected graph. Therefore, this is a problem of combinatorial graph search. The TSP is maybe one of the most explored problems in computer science. The applications of the TSP problem are numerous – in computer wiring, job scheduling, minimizing fuel consumption in aircraft, vehicle routing problem, robot learning, etc. [3]
The purpose of this paper is to provide a method in which the genetic algorithm into a parallel algorithm and to be of such issues (NP) in the optimal time by use of parallel processing to solve.
II. RESEARCH
Generally 4 models for implementation of parallel genetic algorithms have been proposed:
- Single Population Master / Slave (fitness)
- Single Population Fine-Grained or Cellular PGA
- Multiple Population (with migration rate)
- Hierarchical
In all the above methods of the parallel genetic algorithm, the purpose of design optimization in terms of genetics was considered a better answer, not for the computational speed. Multiple population GAs are also widely used parallel methods, but they are more complex than single population methods. A key characteristic of multiple-population PGAs is the migration of individuals among sub populations. Each sub population is managed by an independent SGA except that the processors periodically exchange individuals. The computational burden in this size and span causes to reduce the speed of the system.
Single-population GAs are generally implemented using a master-slave model. In the master-slave model, a single population resides in the master processor and the master processor does the selection, crossover, and mutation; only evaluation of the fitness function is distributed among slave processors. The global single-population master-slave model that we use is illustrated in Figure 2. A portion of the population is distributed to each slave processor for evaluation of the fitness value of individuals. The master processor also retains a portion of the population so that it can carry out evaluation in parallel with the slave processors. Genetic operations other than evaluation are performed only by the master processor. The master processor assigns a fraction of the population to each slave processor for each generation. [4]
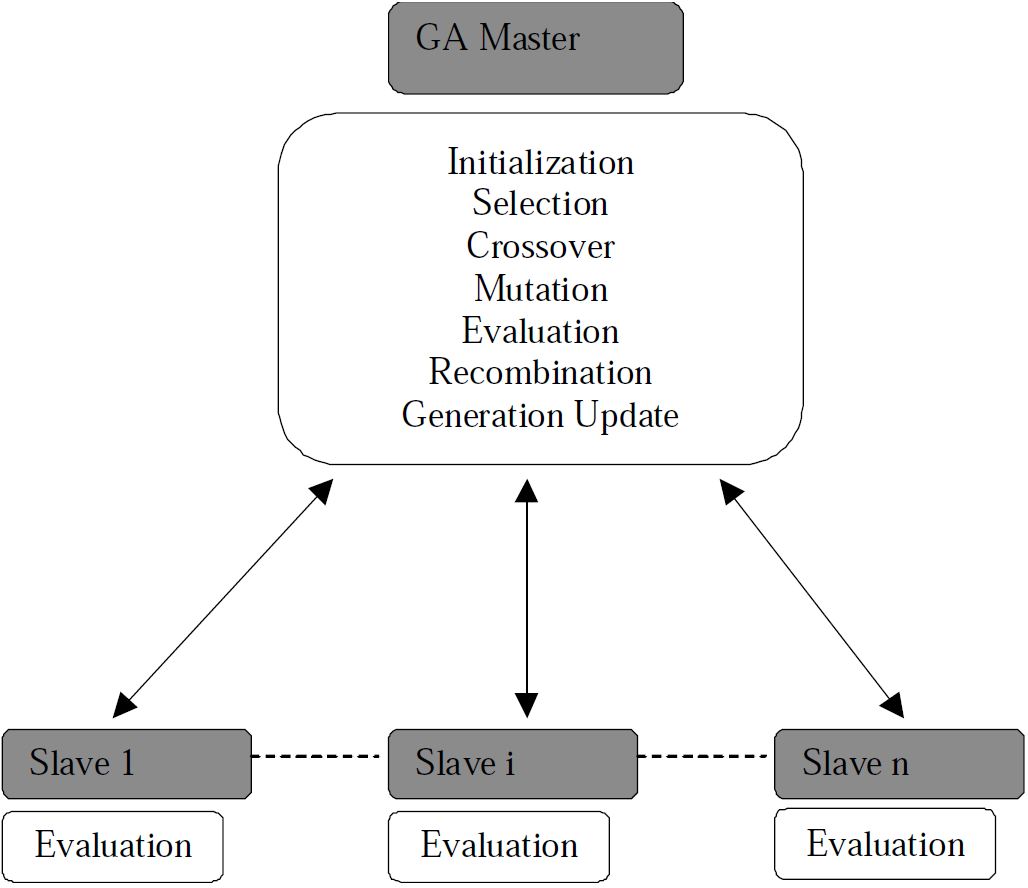 Figure 2. Global single-population master-slave PGA. The master stores the population, executes GA operations, and sends subsets of the population to the slaves. Each slave only evaluates the fitness of the individuals in its subpopulation, and sends the fitness value back to master.
Figure 2. Global single-population master-slave PGA. The master stores the population, executes GA operations, and sends subsets of the population to the slaves. Each slave only evaluates the fitness of the individuals in its subpopulation, and sends the fitness value back to master.
In simpler problems (e.g.: TSP) the division of work between the processors just for evaluation is waste the CPU time and causes to be slower parallel trend of the series it.
In this article, our methodology is so like method of Master/Slave, but with this difference that workers (slaves) in addition to the processing of chromosome fitness, should do the mutation and crossover. Finally new offspring created from worker tasks and put it with a certain formula in manager population array's place. But to compute the genetic operands on the workers, we need an environment in which the genetic operands are able to work independently of other parts of the algorithm. Therefore, the chromosomes array should be stored globally in master until all worker tasks can use it concurrently.
The manager (master) after making the randomize initial population, perform array to sort according to fitness, then the number of worse chromosomes (according by selection rate) in the array is deleted until allow to do their new children Replacement. Before the placement operates, the number of chromosomes that is to new production and placement, was determinate by the selected function; then by divide the replacement counts on the number of the system processors, can know how many offspring each worker must produced and finally this parameter with start index of manager array parameters send to worker tasks.
The most important part of our work was done at this stage, the workers must work independently and without reliance threads. And finally the generation process was done completely independently. So with the mutual exclusivity when parents split between workers and produce offspring, thereby increasing the independence of our processes. And just insertion of the produced children in the Global population array (which is located within the master) is in series state. But it can also be kept array as a sorted at any moment. Finally the array was always sorted and sorting algorithm in the manager is not required.
For the parallel algorithm design functional decomposition of the parallel application has been made and the manager/workers paradigm is applied. Performance estimation and parallelism profiling have been made on the basis of multiTasking program implementation. The experimental parallel computer platform is a computer by multi Processors comprising eight workstations (Processor or Computer) communicating via Parent Task (Manager or Network Switch).
Computation is presented in Fig.3.
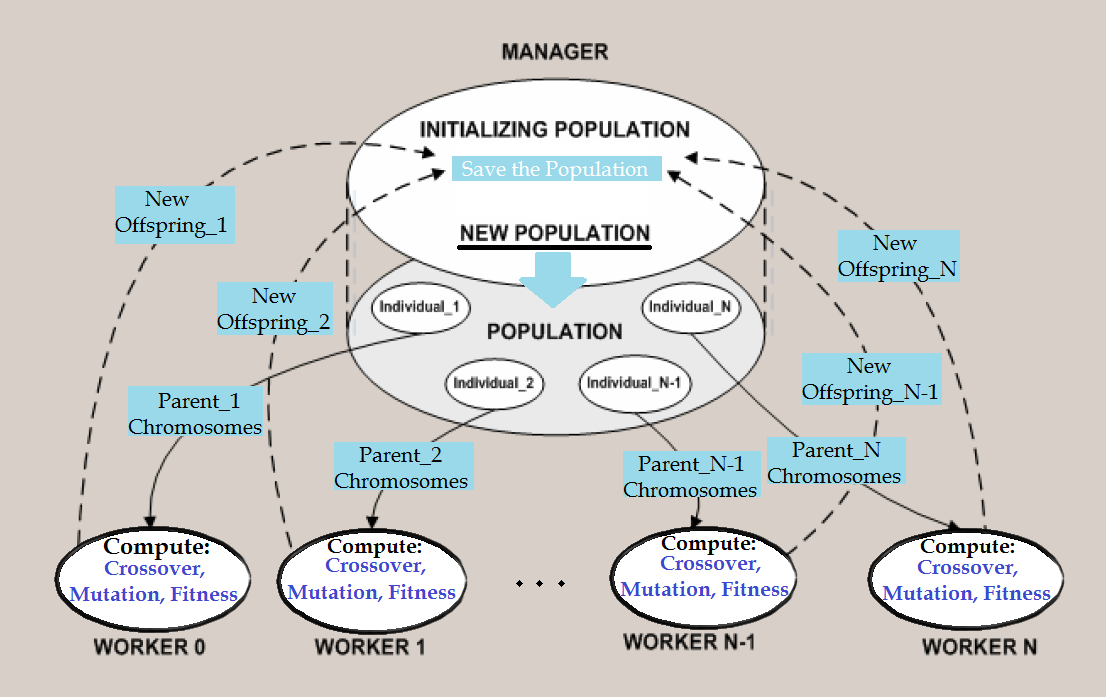 Figure 3. The flat parallel model of computing the TSP by genetic algorithm
Figure 3. The flat parallel model of computing the TSP by genetic algorithm
The manager process (rank 0) performs all genetic operations for first population and distributes the computational load among the worker processes. It performs the following activities:
- Initializes population (randomize)
- Sort chromosomes by fitness value (the chromosome by lowest value is placed on first home of array)
- Chromosomes elitism and select worst chromosome for delete
- Define selection probability according chromosome fitness
- Construction workers to the number of cores for performs the genetic operators the along produce a new generation
- Wait for complete jobs of all workers
- Receives the evaluated offspring from workers and save new chromosomes by formula indexed in array
- Generates new population by combine any received offspring from workers in array
- Check termination conditional for cut the loop
- Prints the computed shortest path
The operations of a worker process are as follows:
- Performs roulette wheel selection
- Performs recombination (select 2 points for crossover)
- Performs normal random mutation (two cities are chosen and exchanged)
- Evaluates the fitness of new chromosome
- Insert offspring from specified start index related
III. PARALLELISM PROFILING AND PERFORMANCE BENCHMARKING
The parallel program (Visual C# + .Net 4 MultiTasking) implementation is run in the programming environment of Visual Studio 2010 Parallelism profiling is made for the case of 500 cities. The results of calculations in parallel and in series of three graphs: time-fitness, time-generation, fitness-generation.
Obviously, that communication is quite intensive among the manager and the workers exchanging data about individuals (chromosomes and fitness). The communication transactions are performed via Task and so, the communication latency is very low. Formerly, the main shortcoming of the parallel genetic approach of computing the TSP with the manager/workers algorithmic paradigm is the sequential computation of the genetic operations – selection, mutation and reproduction – by the manager process. But now this operations run on workers.
In evaluating the proposed parallel algorithm with a series algorithm, according to Figure 4 and Figure 5 can be seen that even the fitness of elite chromosomes in sequential generations have improved faster. Because independence in reproduction processing (parental dissimilarity) the children is the lack of convergence. The result is improved to reach the desired fitness quickly. Of course given the evaluation figures on the TSP example should be consider that the Fitness is the distance between cities, so how much lower, more efficient and better value.
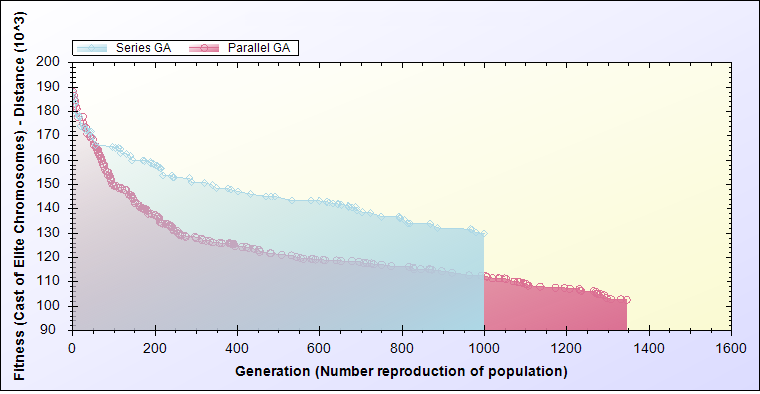 Figure 4. Compare best fitness of any generation in both state of series and parallel processing.
Figure 4. Compare best fitness of any generation in both state of series and parallel processing.
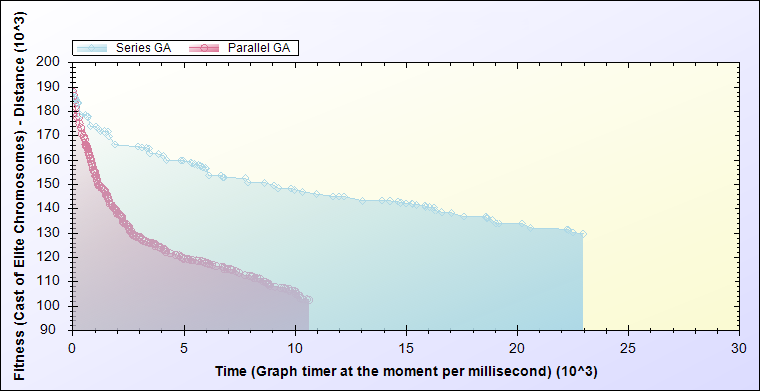 Figure 5. Compare elite chromosome fitness in every moment for both state of series and parallel processing.
Figure 5. Compare elite chromosome fitness in every moment for both state of series and parallel processing.
Next harvest of result evaluations accordance by Figure 6 is that the generation produce rates is much faster than the series state.
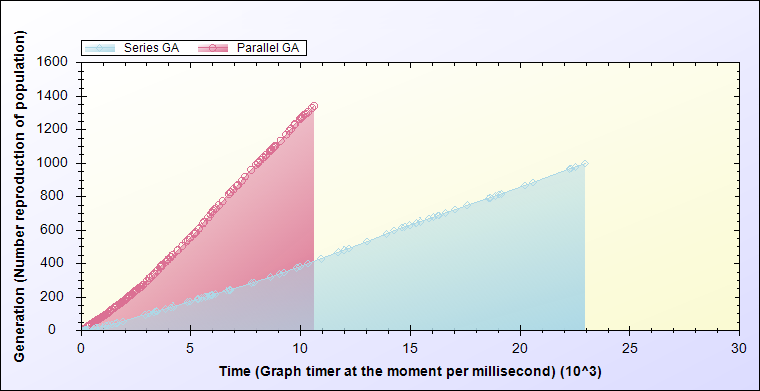 Figure 6. Compare the number of generations produced in every moment of the series and parallel processing.
Figure 6. Compare the number of generations produced in every moment of the series and parallel processing.
IV. CONCLUSIONS
Based on the evaluation and comparison can be proved that the mutual exclusivity and independence of the workers, the children will not converging. And therefore the optimal solution will be faster. And also undertake all tasks (genetic operations) of master by workers is a causes to increasing the speed of parallel processing. This paper attempts until have the present algorithm provides more parallelism, and has not exist any series tasks for master.
REFERENCES
[1] Zh. Shen and Y. Zhao, “Niche Pseudo-Parallel Genetic Algorithms for Path Optimization of Autonomous Mobile Robot - A Specific Application of TSP” unpublished.
[2] J. Hennesy, D. Patterson, Computer Architecture. A Quantative Approach, 3rd
[3] Borovska P., T. Ivanova, H. Salem. Efficient Parallel Computation of the Traveling Salesman Problem on Multicomputer Platform, Proceedings of the International Scientific Conference ‘Computer Science’2004, Sofia, Bulgaria, December 2004, pp. 74-7
[4] Cantú-Paz, Erick. 1998. A survey of parallel genetic algorithms. Calculateurs Paralleles. Vol. 10, No. 2. Paris: Hermes. http://www-illigal.ge.uiuc.edu/publications.php3 (Accessed 18 May 2000).
LICENSE INFORMATION 

This software is open source, licensed under the GNU General Public License, Version 3.0. See GPL-3.0 for details. This Class Library creates a way of handling structured exception handling, inheriting from the Exception class gives us access to many method we wouldn't otherwise have access to
Copyright (C) 2015-2016 Behzad Khosravifar
This program published by the Free Software Foundation, either version 1.0.1 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.