Developing Now......
Motivation
Note: We call the crawler which crawl the entire site: A full-scale crawler.
Firstly, let’s summarize the various types of crawlers, their characteristics and the corresponding open source framework.
| Crawler type | Crawl num | Forbidden risk | Open source framework |
|---|---|---|---|
| Search engine crawler | Unknown | Low | Nutch |
| Vertical crawler | Known | Moderate | WebMagic SpiderMan |
| Full-scale crawler | Unknown | High | None |
- Page number: If you can know what content we want and how much data we need before we crawl it, then it is easy to determine the performance of the crawler; On the contrary, it would get difficult when we do not know that. So it is a big problem for a full-scale crawler which try to crawl more pages.
- Forbidden risk: The search engine crawlers crawl the entire Internet, so it is easy to avoid frequent crawling of a site through choosing different site’s URL each time, thereby reducing the risk of being forbidden. For a full-scale crawler, the risk is higher because it crawled too many pages within this site in a short time.
- Open source framework: In the field of search engine, there is a famous framework called Nutch, and there are more awesome open source frameworks for vertical crawlers, such as WebMagic, SpiderMan and so on. But I have not found any framework for full-scale crawler. Of course, the moderate deformation of the other framework can meet some needs, but the performance is not perfect.
In addition, the daily work of the laboratory need a full-scale crawler and during the work, some workmates who study for data mining always want my help to crawl some websites, but the crawler system is not friendly to a novice. so I came up with the idea of WebHunger.
What's WebHunger
The name of WebHunger is a composition of words web and hunger, means to be hungry for web resources
WebHunger is an extensible, full-scale crawler framework that supports distributed crawling, aiming at getting users focused on parsing web page without concern for the crawling process. To get the result, the user only needs to submit the seed url and the page-parsed Java Class to this framework. After the crawling is completed, the framework would promptly return the crawling result to the user. With this framework, the user can have no idea about distributed programming, neither the knowledge of working mechanism of the crawler, which is greatly making the user easy to use.
In order to making the user easy to monitor, WebHunger provides a web console. Some screenshots as shown below.
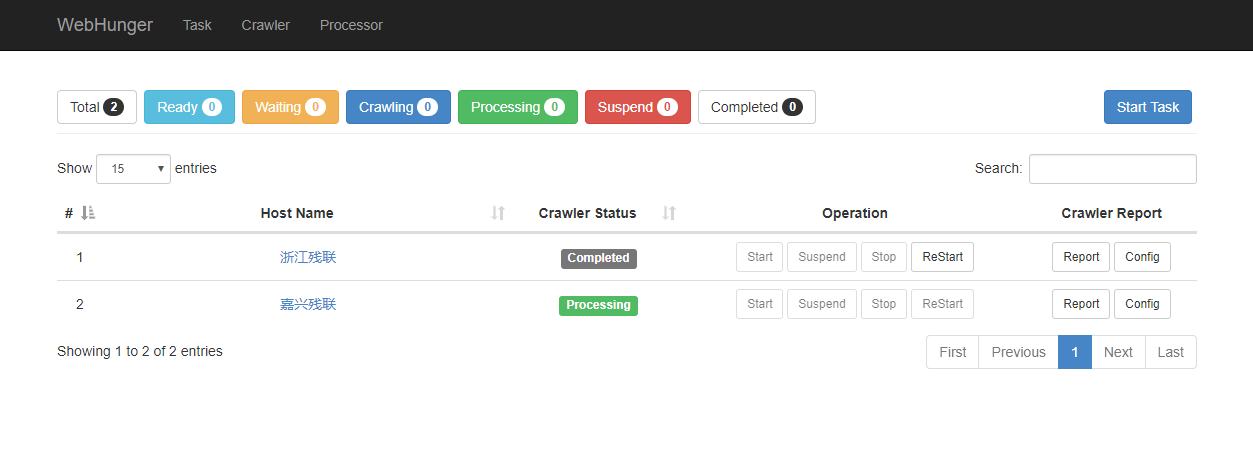
In the page shown above, you can start crawling the site, pause, re-crawl and other operations.
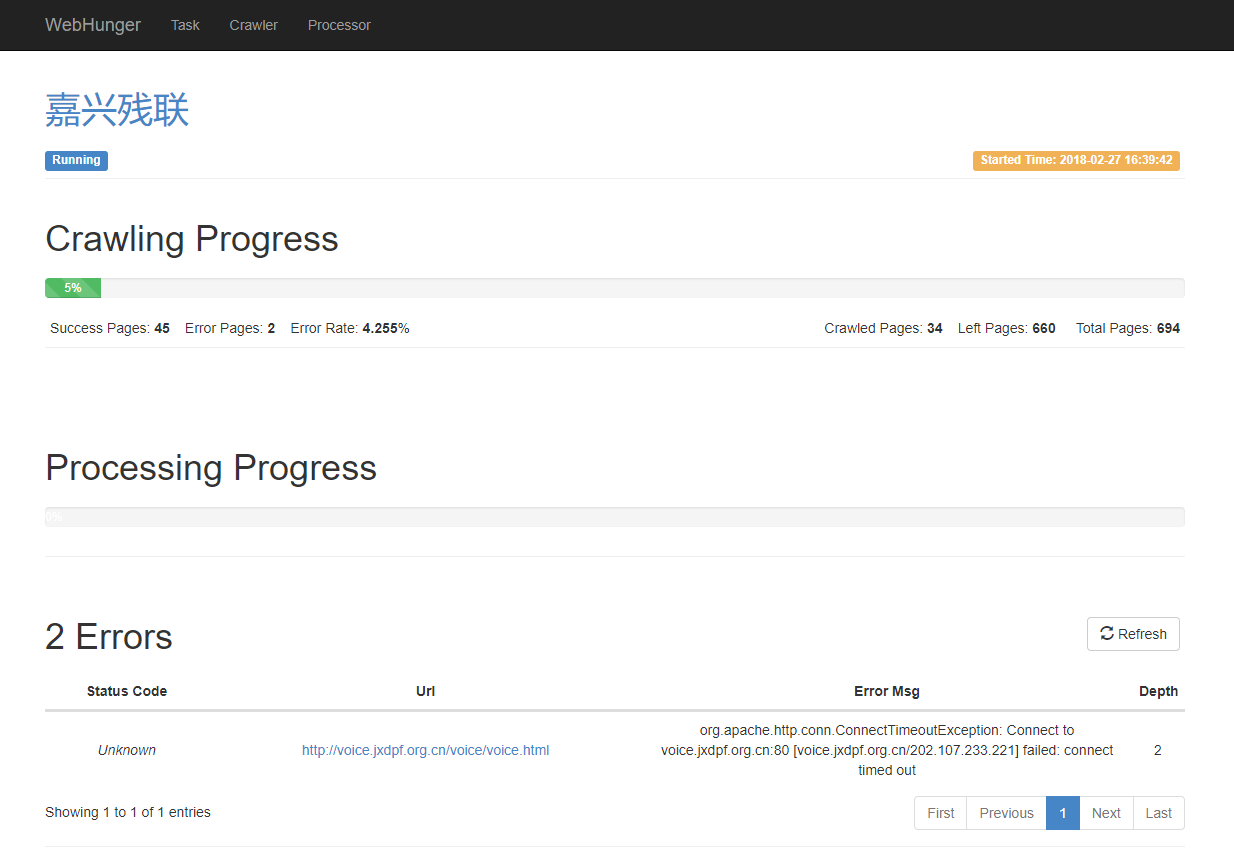
And here you can see the site crawled progress, page parsed progress and the links which crawl failed.
How WebHunger works
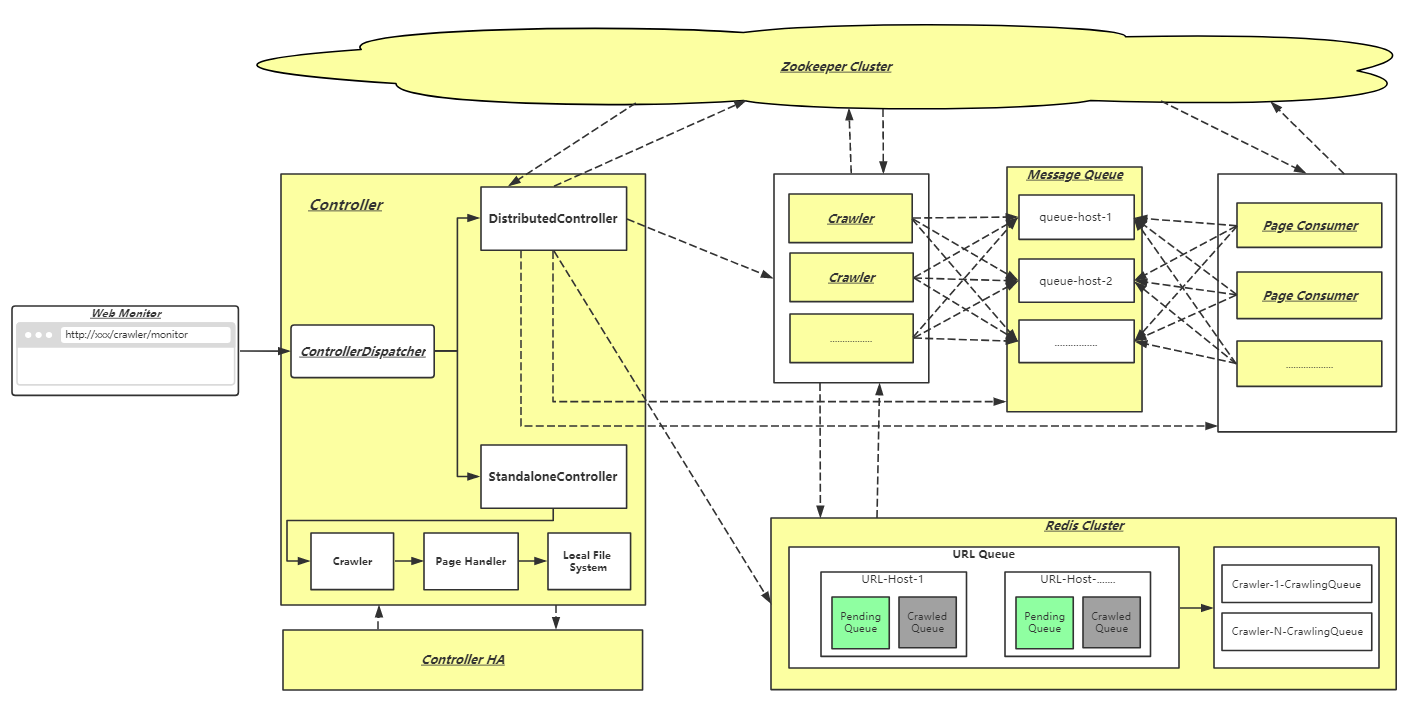
All of the components with a yellow background in the above figure can be independently deployed to run on any server; solid lines indicate local calls; dotted lines indicate remote calls.
WebHunger consists of the following major components:
- Controller: Responsible for the management of the site
- Crawler: According to the Controller specified URL scheduling strategy, fetch URL from Redis to crawl, and seed crawled results to message queue.
- Page Consumer: Pull page message from message queue, and call the user-defined page parsed Java Class
- ZooKeeper Cluster: Do site state storage, service discovery, distributed lock and other work
- RocketMQ: Storage crawled page and page distribution
- Redis Cluster: Responsible for storing the URLs to be crawled and filtering duplicate URLs
- Web Console: A web-based monitor platform.