conan7882 / Adversarial Autoencoders
Licence: mit
Tensorflow implementation of Adversarial Autoencoders
Stars: ✭ 215
Programming Languages
python
139335 projects - #7 most used programming language
Projects that are alternatives of or similar to Adversarial Autoencoders
AdversarialAudioSeparation
Code accompanying the paper "Semi-supervised adversarial audio source separation applied to singing voice extraction"
Stars: ✭ 70 (-67.44%)
Mutual labels: semi-supervised-learning, adversarial-networks
Adversarial-Semisupervised-Semantic-Segmentation
Pytorch Implementation of "Adversarial Learning For Semi-Supervised Semantic Segmentation" for ICLR 2018 Reproducibility Challenge
Stars: ✭ 151 (-29.77%)
Mutual labels: semi-supervised-learning, adversarial-networks
tensorflow-mnist-AAE
Tensorflow implementation of adversarial auto-encoder for MNIST
Stars: ✭ 86 (-60%)
Mutual labels: autoencoder, adversarial-networks
Adversarial Semisupervised Semantic Segmentation
Pytorch Implementation of "Adversarial Learning For Semi-Supervised Semantic Segmentation" for ICLR 2018 Reproducibility Challenge
Stars: ✭ 147 (-31.63%)
Mutual labels: semi-supervised-learning, adversarial-networks
Cct
[CVPR 2020] Semi-Supervised Semantic Segmentation with Cross-Consistency Training.
Stars: ✭ 171 (-20.47%)
Mutual labels: semi-supervised-learning
Latentspacevisualization
Visualization techniques for the latent space of a convolutional autoencoder in Keras
Stars: ✭ 155 (-27.91%)
Mutual labels: autoencoder
Shapegan
Generative Adversarial Networks and Autoencoders for 3D Shapes
Stars: ✭ 151 (-29.77%)
Mutual labels: autoencoder
Tensorflow stacked denoising autoencoder
Implementation of the stacked denoising autoencoder in Tensorflow
Stars: ✭ 151 (-29.77%)
Mutual labels: autoencoder
Triple Gan
See Triple-GAN-V2 in PyTorch: https://github.com/taufikxu/Triple-GAN
Stars: ✭ 203 (-5.58%)
Mutual labels: semi-supervised-learning
Graph Adversarial Learning
A curated collection of adversarial attack and defense on graph data.
Stars: ✭ 188 (-12.56%)
Mutual labels: semi-supervised-learning
Stylealign
[ICCV 2019]Aggregation via Separation: Boosting Facial Landmark Detector with Semi-Supervised Style Transition
Stars: ✭ 172 (-20%)
Mutual labels: semi-supervised-learning
Motion Sense
MotionSense Dataset for Human Activity and Attribute Recognition ( time-series data generated by smartphone's sensors: accelerometer and gyroscope)
Stars: ✭ 159 (-26.05%)
Mutual labels: autoencoder
Tensorflow Tutorials
텐서플로우를 기초부터 응용까지 단계별로 연습할 수 있는 소스 코드를 제공합니다
Stars: ✭ 2,096 (+874.88%)
Mutual labels: autoencoder
Kitnet Py
KitNET is a lightweight online anomaly detection algorithm, which uses an ensemble of autoencoders.
Stars: ✭ 152 (-29.3%)
Mutual labels: autoencoder
Timeseries Clustering Vae
Variational Recurrent Autoencoder for timeseries clustering in pytorch
Stars: ✭ 190 (-11.63%)
Mutual labels: autoencoder
Deep Sad Pytorch
A PyTorch implementation of Deep SAD, a deep Semi-supervised Anomaly Detection method.
Stars: ✭ 152 (-29.3%)
Mutual labels: semi-supervised-learning
Deep image prior
Image reconstruction done with untrained neural networks.
Stars: ✭ 168 (-21.86%)
Mutual labels: autoencoder
Deep white balance
Reference code for the paper: Deep White-Balance Editing, CVPR 2020 (Oral). Our method is a deep learning multi-task framework for white-balance editing.
Stars: ✭ 184 (-14.42%)
Mutual labels: autoencoder
Accel Brain Code
The purpose of this repository is to make prototypes as case study in the context of proof of concept(PoC) and research and development(R&D) that I have written in my website. The main research topics are Auto-Encoders in relation to the representation learning, the statistical machine learning for energy-based models, adversarial generation networks(GANs), Deep Reinforcement Learning such as Deep Q-Networks, semi-supervised learning, and neural network language model for natural language processing.
Stars: ✭ 166 (-22.79%)
Mutual labels: semi-supervised-learning
Sequitur
Library of autoencoders for sequential data
Stars: ✭ 162 (-24.65%)
Mutual labels: autoencoder
Adversarial Autoencoders (AAE)
- Tensorflow implementation of Adversarial Autoencoders (ICLR 2016)
- Similar to variational autoencoder (VAE), AAE imposes a prior on the latent variable z. Howerver, instead of maximizing the evidence lower bound (ELBO) like VAE, AAE utilizes a adversarial network structure to guides the model distribution of z to match the prior distribution.
- This repository contains reproduce of several experiments mentioned in the paper.
Requirements
- Python 3.3+
- TensorFlow 1.9+
- TensorFlow Probability
- Numpy
- Scipy
Implementation details
- All the models of AAE are defined in src/models/aae.py.
- Model corresponds to fig 1 and 3 in the paper can be found here: train and test.
- Model corresponds to fig 6 in the paper can be found here: train and test.
- Model corresponds to fig 8 in the paper can be found here: train and test.
- Examples of how to use AAE models can be found in experiment/aae_mnist.py.
- Encoder, decoder and all discriminators contain two fully connected layers with 1000 hidden units and RelU activation function. Decoder and all discriminators contain an additional fully connected layer for output.
- Images are normalized to [-1, 1] before fed into the encoder and tanh is used as the output nonlinear of decoder.
- All the sub-networks are optimized by Adam optimizer with
beta1 = 0.5.
Preparation
- Download the MNIST dataset from here.
- Setup path in
experiment/aae_mnist.py:DATA_PATHis the path to put MNIST dataset.SAVE_PATHis the path to save output images and trained model.
Usage
The script experiment/aae_mnist.py contains all the experiments shown here. Detailed usage for each experiment will be describe later along with the results.
Argument
-
--train: Train the model of Fig 1 and 3 in the paper. -
--train_supervised: Train the model of Fig 6 in the paper. -
--train_semisupervised: Train the model of Fig 8 in the paper. -
--label: Incorporate label information in the adversarial regularization (Fig 3 in the paper). -
--generate: Randomly sample images from trained model. -
--viz: Visualize latent space and data manifold (only when--ncodeis 2). -
--supervise: Sampling from supervised model (Fig 6 in the paper) when--generateis True. -
--load: The epoch ID of pre-trained model to be restored. -
--ncode: Dimension of code. Default:2 -
--dist_type: Type of the prior distribution used to impose on the hidden codes. Default:gaussian.gmmfor Gaussian mixture distribution. -
--noise: Add noise to encoder input (Gaussian with std=0.6). -
--lr: Initial learning rate. Default:2e-4. -
--dropout: Keep probability for dropout. Default:1.0. -
--bsize: Batch size. Default:128. -
--maxepoch: Max number of epochs. Default:100. -
--encw: Weight of autoencoder loss. Default:1.0. -
--genw: Weight of z generator loss. Default:6.0. -
--disw: Weight of z discriminator loss. Default:6.0. -
--clsw: Weight of semi-supervised loss. Default:1.0. -
--ygenw: Weight of y generator loss. Default:6.0. -
--ydisw: Weight of y discriminator loss. Default:6.0.
1. Adversarial Autoencoder
Architecture
| Architecture | Description |
|---|---|
 |
The top row is an autoencoder. z is sampled through the re-parameterization trick discussed in variational autoencoder paper. The bottom row is a discriminator to separate samples generate from the encoder and samples from the prior distribution p(z). |
Hyperparameters
| name | value |
|---|---|
| Reconstruction Loss Weight | 1.0 |
| Latent z G/D Loss Weight | 6.0 / 6.0 |
| Batch Size | 128 |
| Max Epoch | 400 |
| Learning Rate | 2e-4 (initial) / 2e-5 (100 epochs) / 2e-6 (300 epochs) |
Usage
- Training. Summary, randomly sampled images and latent space during training will be saved in
SAVE_PATH.
python aae_mnist.py --train \
--ncode CODE_DIM \
--dist_type TYPE_OF_PRIOR (`gaussian` or `gmm`)
- Random sample data from trained model. Image will be saved in
SAVE_PATHwith namegenerate_im.png.
python aae_mnist.py --generate \
--ncode CODE_DIM \
--dist_type TYPE_OF_PRIOR (`gaussian` or `gmm`)\
--load RESTORE_MODEL_ID
- Visualize latent space and data manifold (only when code dim = 2). Image will be saved in
SAVE_PATHwith namegenerate_im.pngandlatent.png. For Gaussian distribution, there will be one image for data manifold. For mixture of 10 2D Gaussian, there will be 10 images of data manifold for each component of the distribution.
python aae_mnist.py --viz \
--ncode CODE_DIM \
--dist_type TYPE_OF_PRIOR (`gaussian` or `gmm`)\
--load RESTORE_MODEL_ID
Result
- For 2D Gaussian, we can see sharp transitions (no gaps) as mentioned in the paper. Also, from the learned manifold, we can see almost all the sampled images are readable.
- For mixture of 10 Gaussian, I just uniformly sample images in a 2D square space as I did for 2D Gaussian instead of sampling along the axes of the corresponding mixture component, which will be shown in the next section. We can see in the gap area between two component, it is less likely to generate good samples.
| Prior Distribution | Learned Coding Space | Learned Manifold |
|---|---|---|
 |
 |
 |
 |
 |
 |
2. Incorporating label in the Adversarial Regularization
Architecture
| Architecture | Description |
|---|---|
 |
The only difference from previous model is that the one-hot label is used as input of encoder and there is one extra class for unlabeled data. For mixture of Gaussian prior, real samples are drawn from each components for each labeled class and for unlabeled data, real samples are drawn from the mixture distribution. |
Hyperparameters
Hyperparameters are the same as previous section.
Usage
- Training. Summary, randomly sampled images and latent space will be saved in
SAVE_PATH.
python aae_mnist.py --train --label\
--ncode CODE_DIM \
--dist_type TYPE_OF_PRIOR (`gaussian` or `gmm`)
- Random sample data from trained model. Image will be saved in
SAVE_PATHwith namegenerate_im.png.
python aae_mnist.py --generate --ncode <CODE_DIM> --label --dist_type <TYPE_OF_PRIOR> --load <RESTORE_MODEL_ID>
- Visualize latent space and data manifold (only when code dim = 2). Image will be saved in
SAVE_PATHwith namegenerate_im.pngandlatent.png. For Gaussian distribution, there will be one image for data manifold. For mixture of 10 2D Gaussian, there will be 10 images of data manifold for each component of the distribution.
python aae_mnist.py --viz --label \
--ncode CODE_DIM \
--dist_type TYPE_OF_PRIOR (`gaussian` or `gmm`) \
--load RESTORE_MODEL_ID
Result
- Compare with the result in the previous section, incorporating labeling information provides better fitted distribution for codes.
- The learned manifold images demonstrate that each Gaussian component corresponds to the one class of digit. However, the style representation is not consistently represented within each mixture component as shown in the paper. For example, the right most column of the first row experiment, the lower right of digit 1 tilt to left while the lower right of digit 9 tilt to right.
| Number of Label Used | Learned Coding Space | Learned Manifold |
|---|---|---|
| Use full label |  |
   
|
| 10k labeled data and 40k unlabeled data |  |
   
|
3. Supervised Adversarial Autoencoders
Architecture
| Architecture | Description |
|---|---|
 |
The decoder takes code as well as a one-hot vector encoding the label as input. Then it forces the network learn the code independent of the label. |
Hyperparameters
Usage
- Training. Summary and randomly sampled images will be saved in
SAVE_PATH.
python aae_mnist.py --train_supervised \
--ncode CODE_DIM
- Random sample data from trained model. Image will be saved in
SAVE_PATHwith namesample_style.png.
python aae_mnist.py --generate --supervise\
--ncode CODE_DIM \
--load RESTORE_MODEL_ID
Result
- The result images are generated by using the same code for each column and the same digit label for each row.
- When code dimension is 2, we can see each column consists the same style clearly. But for dimension 10, we can hardly read some digits. Maybe there are some issues of implementation or the hyper-parameters are not properly picked, which makes the code still depend on the label.
| Code Dim=2 | Code Dim=10 |
|---|---|
 |
 |
4. Semi-supervised learning
Architecture
| Architecture | Description |
|---|---|
 |
The encoder outputs code z as well as the estimated label y. Encoder again takes code z and one-hot label y as input. A Gaussian distribution is imposed on code z and a Categorical distribution is imposed on label y. In this implementation, the autoencoder is trained by semi-supervised classification phase every ten training steps when using 1000 label images and the one-hot label y is approximated by output of softmax. |
Hyperparameters
| name | value |
|---|---|
| Dimention of z | 10 |
| Reconstruction Loss Weight | 1.0 |
| Letant z G/D Loss Weight | 6.0 / 6.0 |
| Letant y G/D Loss Weight | 6.0 / 6.0 |
| Batch Size | 128 |
| Max Epoch | 250 |
| Learning Rate | 1e-4 (initial) / 1e-5 (150 epochs) / 1e-6 (200 epochs) |
Usage
- Training. Summary will be saved in
SAVE_PATH.
python aae_mnist.py \
--ncode 10 \
--train_semisupervised \
--lr 2e-4 \
--maxepoch 250
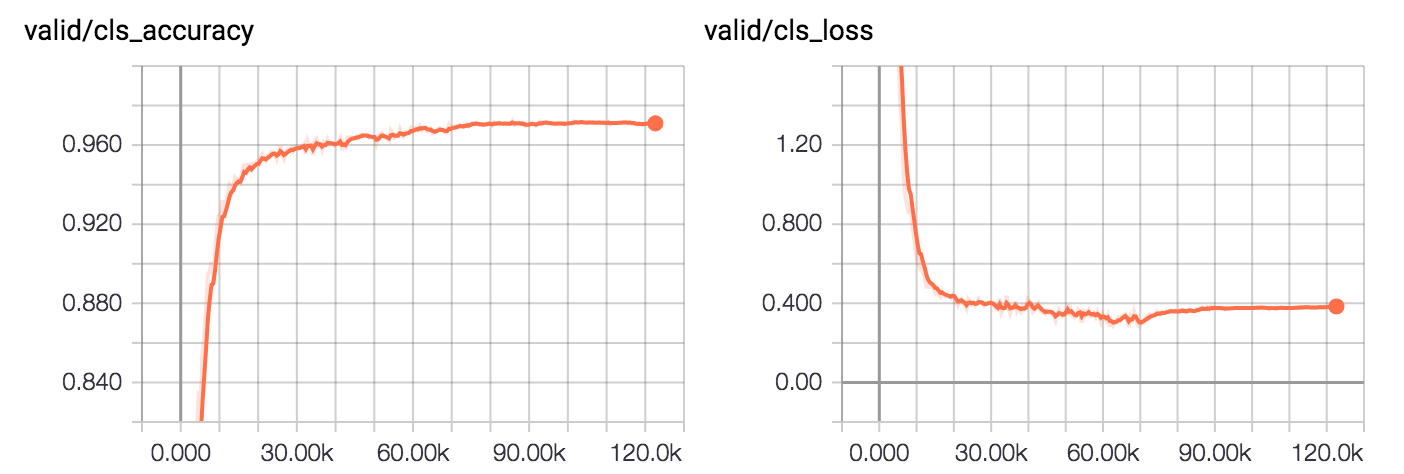
Result
- 1280 labels are used (128 labeled images per class)
learning curve for training set (computed only on the training set with labels)

learning curve for testing set
- The accuracy on testing set is 97.10% around 200 epochs.

Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].